Why DuckDB for Local Analytics
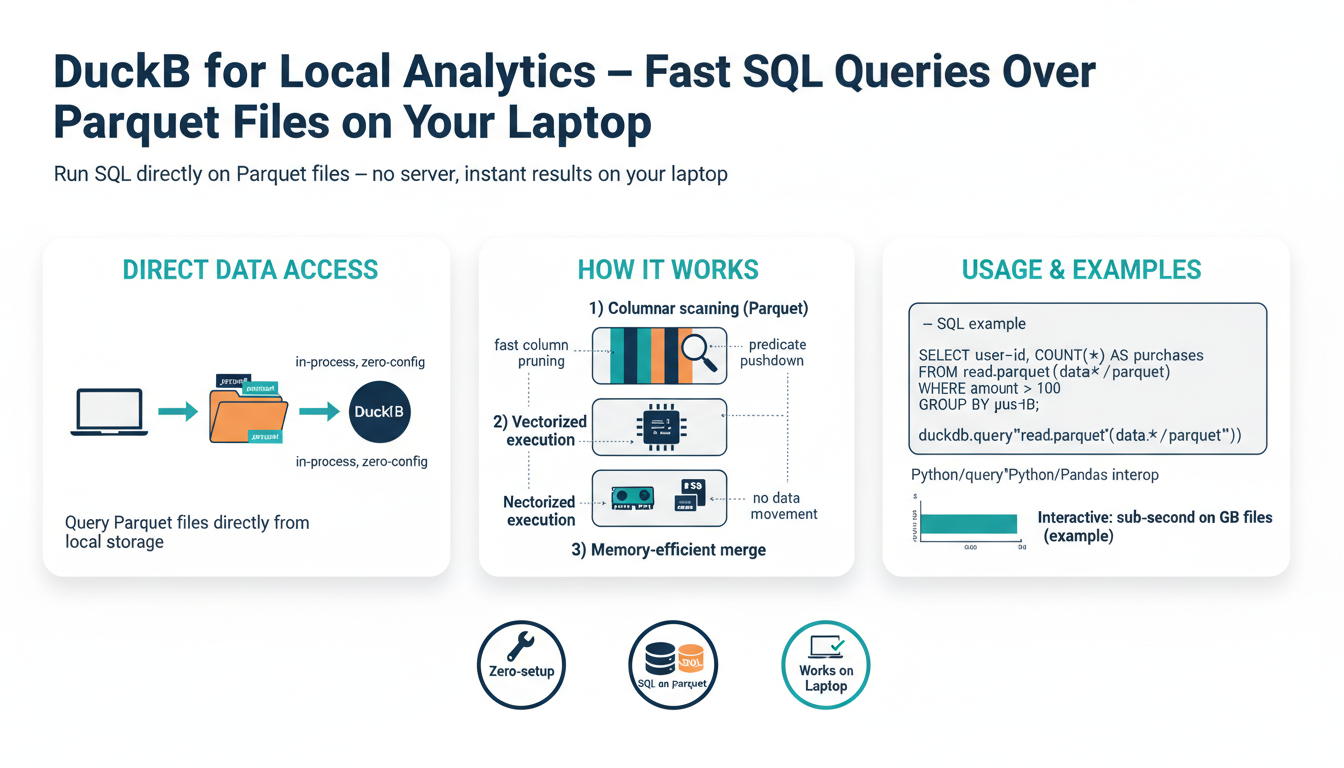
DuckDB brings a desktop-grade analytical engine to your laptop: fast, SQL-first queries directly over Parquet (and other columnar files) with minimal setup.
- Single-process, embeddable engine: no server to run or maintain — use the CLI or embed in Python/R/notebooks with a few lines of code.
- Columnar, vectorized execution: scans and aggregates execute much faster than row-based engines, especially on wide tables and OLAP-style queries.
- Native Parquet support and predicate pushdown: read only needed columns/pages so large datasets on disk become interactively queryable without an ETL step.
- Low memory footprint and efficient I/O: smart buffering and streaming reduce RAM pressure; you can query multi-GB Parquet files on typical laptops.
- Full SQL support for analytics: joins, window functions, GROUP BY, CTEs and complex expressions let you use familiar SQL for exploration and reporting.
- Interoperability: seamless integration with pandas, Arrow, R tibbles and visualization tools means results flow directly into analysis notebooks.
- Reproducible, local workflows: keep data as Parquet, version code/notebooks, and get consistent results without central infra.
Example mental model: treat Parquet as the source of truth and run ad-hoc SQL against it—fast aggregation, slicing, and joins—without loading everything into a heavy database.
Install DuckDB on Your Laptop
Pick the install method that matches your workflow and run a quick smoke test.
- Python (fastest for notebooks):
- Create/activate a venv, then install:
pip install duckdb(orpip install 'duckdb[all]'for extras). DuckDB’s Python client requires Python 3.9+. (duckdb.org) -
Quick test in a REPL or notebook:
py import duckdb duckdb.sql("SELECT 42").show() -
CLI (single executable, great for ad-hoc queries):
- Mac / Linux: run the official installer script:
curl https://install.duckdb.org | sh(it installs a binary under~/.duckdb/cli/latest; add that folder to your PATH). (duckdb.org) -
Windows: download the precompiled CLI/Windows assets from the DuckDB releases/downloads page or use the Python wheel (
pip install duckdb) if you prefer. (duckdb.org) -
Homebrew / Conda (optional):
- macOS / Linuxbrew:
brew install duckdb(formula provides bottled binaries). (formulae.brew.sh) - Conda:
conda install python-duckdb -c conda-forgefor conda environments. (duckdb.org)
Tips: add the CLI path to your shell profile for easy duckdb calls, prefer pip inside virtual environments, and verify the install with duckdb --version or the Python quick test above.
Query Parquet Files Directly
DuckDB treats Parquet files as first-class queryable tables so you can run full SQL against on-disk files without an import step. It reads only needed columns and pushes filters down into Parquet pages, making aggregations and scans over multi-GB files interactive on a laptop.
Key patterns and tips
- Query a single file or a glob of files directly:
import duckdb
duckdb.sql("SELECT user_id, COUNT(*) AS cnt FROM 'data/events-*.parquet'\n WHERE event_date >= '2024-01-01'\n GROUP BY user_id\n ORDER BY cnt DESC\n LIMIT 10").show()
-
Use predicate pushdown and column projection to minimize I/O: reference only the columns you need in SELECT and WHERE.
-
Join Parquet files in-place (no load):
SELECT a.user_id, SUM(a.amount) total
FROM 'orders.parquet' AS a
JOIN 'customers.parquet' AS c ON a.customer_id = c.id
WHERE c.country = 'US'
GROUP BY a.user_id;
-
Read partitioned directories or multiple files with globs: point FROM at a folder or pattern to treat many Parquet files as one table.
-
Inspect schema without scanning full data: run LIMIT 0 or use PRAGMA show_tables / DESCRIBE to preview columns.
-
Integration: results return to pandas/Arrow in-memory easily for plotting or downstream processing.
Practical rule: define the smallest SELECT/WHERE needed, leverage globs for partitioned datasets, and let DuckDB’s vectorized engine handle efficient reads—no ETL required.
Basic SQL Queries and Examples
Start with small, focused queries and build complexity. Use explicit column lists and predicates to minimize I/O when querying Parquet files.
Basic selection and filter (direct Parquet):
SELECT user_id, event_type, event_date
FROM 'data/events-2024-*.parquet'
WHERE event_date >= '2024-01-01' AND event_type = 'purchase'
LIMIT 50;
Aggregation and grouping:
SELECT product_id, COUNT(*) AS purchases, SUM(amount) AS total
FROM 'data/orders.parquet'
WHERE order_date BETWEEN '2024-01-01' AND '2024-12-31'
GROUP BY product_id
ORDER BY total DESC
LIMIT 20;
Joining Parquet files in-place (no import):
SELECT c.country, COUNT(*) AS orders
FROM 'orders.parquet' o
JOIN 'customers.parquet' c ON o.customer_id = c.id
WHERE o.status = 'complete'
GROUP BY c.country;
Window function example (top N per group):
WITH ranked AS (
SELECT user_id, session_id, amount,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY amount DESC) AS rn
FROM 'payments.parquet'
)
SELECT user_id, session_id, amount
FROM ranked
WHERE rn <= 3;
Inspect schema quickly without scanning data:
SELECT * FROM 'data/events.parquet' LIMIT 0;
Tips: prefer globs for partitioned folders, push filters into WHERE, and select only required columns. When using Python or notebooks, return results to pandas/Arrow for downstream analysis (duckdb.sql(…).df()).
Optimize Parquet Reads and Filters
Small changes to how you read Parquet files cut I/O and make queries interactive on a laptop.
- Project columns, not SELECT .* Pick only the columns you need to avoid reading unnecessary row groups or pages.
SELECT user_id, COUNT(*) AS cnt
FROM 'data/events-2024-*.parquet'
WHERE event_date >= '2024-01-01'
GROUP BY user_id;
- Make predicates pushable. Put raw column comparisons in WHERE (column OP constant). Avoid applying functions or complex expressions to columns, which often disables predicate pushdown and forces full reads.
Bad (prevents pushdown):
WHERE SUBSTRING(event_type,1,3) = 'pur'
Good (pushes to Parquet):
WHERE event_type = 'purchase'
-
Leverage partitioned layout and globs. Organize files by partition (year=, country=) and query with a glob or folder path so DuckDB reads only relevant files.
-
Filter before joining. Reduce input size by applying selective WHEREs (or CTEs) to each Parquet source prior to JOINs.
WITH orders_f AS (
SELECT * FROM 'orders/*.parquet' WHERE order_date >= '2024-01-01'
)
SELECT ... FROM orders_f JOIN 'customers.parquet' c ON ...;
- Inspect and iterate cheaply: use LIMIT 0 or a small LIMIT to preview schema and cardinality without scanning full data.
Practical rule: minimize columns, write pushdown-friendly predicates, filter early (and on disk), and use partitioned files/globs — that combination yields the biggest speedups on laptop-scale Parquet analytics.
Integrate DuckDB with Python
Use DuckDB’s Python client to run SQL directly over Parquet, register in-memory pandas objects, and pipe results back into your notebook with a few lines.
import duckdb
# in-memory connection (or 'analytics.duckdb' to persist)
con = duckdb.connect()
# Query Parquet files directly (globs supported)
df = con.execute(
"""
SELECT user_id, COUNT(*) AS cnt
FROM 'data/events-*.parquet'
WHERE event_date >= '2024-01-01'
GROUP BY user_id
ORDER BY cnt DESC
LIMIT 10
"""
).df() # returns a pandas.DataFrame
# Register an existing pandas DataFrame as a table and query it
import pandas as pd
sales = pd.read_parquet('data/sales.parquet')
con.register('sales_tbl', sales)
res = con.execute(
"SELECT customer_id, SUM(amount) total FROM sales_tbl WHERE amount>0 GROUP BY customer_id ORDER BY total DESC LIMIT 20"
).df()
Quick patterns and tips:
- Use with-context for automatic close:
with duckdb.connect() as con:. - Prefer
SELECT col1, col2and pushable WHERE clauses to minimize I/O when querying Parquet globs. - Persist a catalog by connecting to a file:
duckdb.connect('mydb.duckdb')to save temporary tables and metadata. - Export query results back to Parquet:
con.execute("COPY (SELECT ...) TO 'out.parquet' (FORMAT PARQUET)").
These patterns make DuckDB a drop-in SQL engine inside Python notebooks for fast, interactive analytics on local Parquet data.



