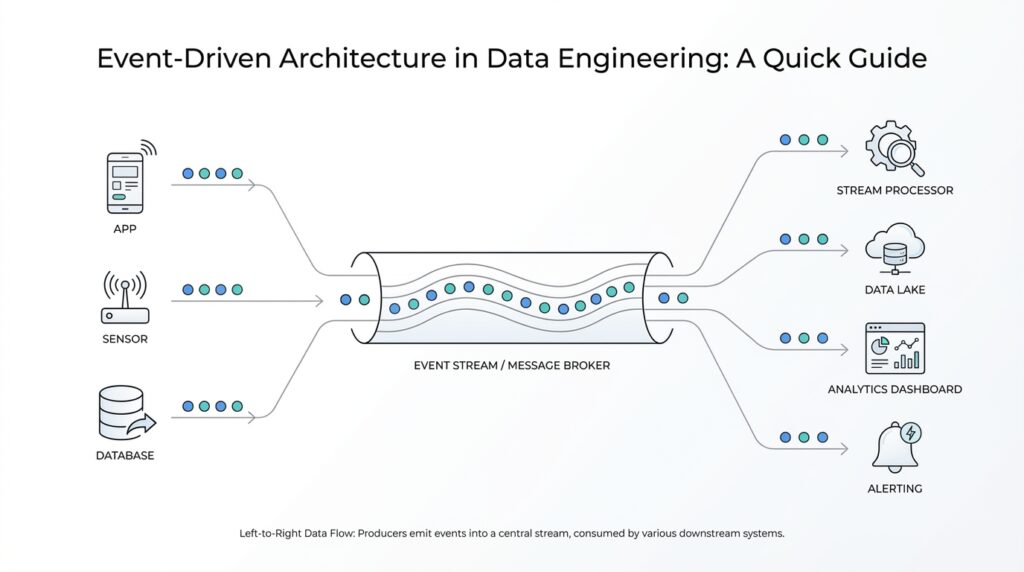
What Event-Driven Architecture Means
Imagine you have a data pipeline that watches a product catalog, a payment system, and a shipping service at the same time. In a traditional setup, those systems often need to ask each other for updates over and over, which can feel like everyone in a room taking turns shouting, “Anything new?” Event-driven architecture changes that rhythm: instead of constantly asking, your systems react when something happens. In data engineering, that means the moment a record changes, a file lands, or an order moves to the next stage, the downstream work can begin right away.
At the center of event-driven architecture is a simple chain of roles. An event producer creates an event, which is a meaningful change in state, such as a new order, a sensor reading, or an updated database row. That event flows through an event channel, often called an event broker, event bus, or ingestion service, and then reaches one or more event consumers that listen for it and act on it. The important idea is decoupling: the producer does not need to know who is listening, and the consumer does not need to know where the event came from.
You can think of it like a restaurant kitchen with a bell instead of a standing line of customers. When a dish is ready, the bell rings, and whoever needs to respond can move. That same idea shows up in event-driven architecture through publish-subscribe systems, where one published event can reach many subscribers, or through event streams, where events arrive continuously for processing over time. For data engineering, this is especially useful when you want multiple systems to react to the same change, such as updating analytics, sending a notification, and refreshing a dashboard without building separate point-to-point connections for each one.
This is where the difference from request-response becomes easier to see. In a request-response model, one system asks for something and waits for an answer, which works well when you need a direct conversation. In event-driven architecture, the systems are more like neighbors who leave notes on a shared board: the note goes up once, and anyone who cares can read it and act. That approach is often a better fit when you want near real-time reactions, independent scaling, and less tight coupling between services, especially in workloads with high volume or frequent changes. How do you know if that matters to you? If one data change needs to trigger several downstream tasks, this model usually starts to feel natural.
Once this clicks, event-driven architecture stops sounding abstract and starts looking like a practical design choice. You are not moving data because you enjoy moving data; you are moving it because a change happened, and that change should ripple outward in a controlled way. For data teams, that can mean fresher insights, fewer brittle integrations, and systems that can grow without rewriting every connection from scratch. Taking this concept further, we can look at how events move through a real pipeline and why that flow matters so much for reliability and speed.
Key Producers, Brokers, Consumers
Building on this foundation, let us zoom in on the three roles that make event-driven architecture feel alive: the producer, the broker, and the consumer. If the earlier picture was a room where systems react when something happens, this is the stage crew behind it. The producer creates the event, the broker carries it, and the consumer listens for it and acts. In practice, this split keeps event-driven architecture calm and organized, because each part has one job and does not need to know the full cast of other systems involved.
The producer is the moment where a change becomes a message. In Kafka, for example, the Producer API sends streams of data into topics, and that event might be a new order, a sensor reading, or an updated customer record. You can think of it like writing a note and placing it on a shared board: the producer does not chase down every reader, because it only needs to publish the event clearly and consistently. One useful detail is the event key, which can keep related records together so downstream processing stays in order, much like keeping all receipts for one customer in the same envelope.
Once the producer has done its part, the broker steps in as the shared middle layer. A broker, also called an event bus or message broker, is the place where events land before consumers pick them up. In publish-subscribe systems, the broker keeps track of subscriptions and sends the message to each consumer that cares about it, while Kafka brokers store messages in topics and let consumers read them from the cluster. That is what makes the broker feel like a busy post office: it does not create the mail, and it does not read it, but it makes sure the right messages reach the right places.
The consumer is where the event turns into action. A consumer reads the event and does something useful with it, such as updating a warehouse table, refreshing a dashboard, sending an alert, or starting a fraud check. AWS describes producers and consumers as decoupled, which means they can be scaled, updated, and deployed independently, and AWS also notes that consumers are producer-agnostic, meaning they care about the event itself rather than who created it. That independence is a big reason event-driven architecture feels so flexible in data engineering: when the number of events grows, you can add more consumer capacity without redesigning the producer.
So how do you know when this pattern starts to matter? A good clue is when one change needs to trigger several different tasks. Imagine a checkout event arriving once, then flowing through the broker to one consumer that records revenue, another that reserves inventory, and a third that updates analytics. The producer publishes a single fact, the broker fans it out, and the consumers each take their own path, which is exactly why this model works so well for event-driven architecture in data engineering. It gives us one clean change stream instead of a tangle of point-to-point connections, and that makes the whole pipeline easier to grow and reason about.
Design Clean, Schema-Ready Events
Building on this foundation, we now want the event itself to feel trustworthy the first time a new consumer sees it. A schema-ready event is like a well-packed moving box: the label tells you what is inside, and the contents are arranged so future packing changes do not spill everything out. In event-driven architecture, that means separating a small, stable envelope from the business payload, so the event schema can grow without forcing every reader to guess. CloudEvents exists for exactly this kind of common event description, which is why clean event shape matters so much once data starts flowing across teams and tools.
Before we add clever business details, we need the event to answer the basic human questions: what happened, where did it come from, and when did it occur? Standard event envelopes, such as CloudEvents, use core attributes like id, source, type, and specversion, with time as an optional attribute. That gives each message a shared front door, so consumers can recognize the event before they even inspect the payload. In practice, this is what makes schema-ready events easier to route, audit, and debug.
Once the envelope is clear, the payload should carry only the business facts the downstream systems actually need. Avro is built around schemas, and the schema travels with the data so readers can process it without guessing or hand-rolled code generation, while field names become the way old and new versions find each other. That is a good mental model for event schema design: keep names descriptive, avoid burying meaning in position or hidden conventions, and do not overload one field with several jobs. If an event needs more context, add explicit fields rather than making consumers infer the rest.
Here is where event schema design becomes a little more careful. If you expect the event to change, prefer additions that older consumers can ignore, and make removals safe by using optional fields or default values. Confluent Schema Registry uses compatibility rules to check whether a new version can live alongside the old ones, and its default mode is backward compatibility, which means newer consumers can read data written by the latest earlier schema. If you need to protect more than one previous version, transitive compatibility tightens that safety net. That is the difference between a schema that merely works today and one that stays calm as the pipeline grows.
How do you keep related events from drifting apart when the stream gets busy? In Kafka, the producer can use a record key to choose a partition, and Kafka only guarantees total ordering within a partition, not across the whole topic. That means a clean event design usually includes a stable identifier for the thing the event belongs to, such as an order ID or customer ID, so all related updates stay together. When we design schema-ready events this way, we are not only making the payload readable; we are also making the stream easier to process in order.
The practical test is simple to picture. If a new teammate can look at one event and tell what changed, who changed it, and how safely they can add a new field next month, you are close to a healthy design. That is the point of schema-ready events in event-driven architecture: they reduce surprise for consumers, reduce friction for schema evolution, and leave room for the pipeline to grow without rewiring every subscriber. With that shape in place, we can move on to how those events behave once they are in motion through the rest of the system.
Route Events Through Brokers
Building on this foundation, the next question is how the event actually gets from one system to the right listeners without turning the architecture into a web of tangled connections. That is where an event broker, sometimes called an event bus or message broker, steps in: it sits between producers and consumers so they can stay decoupled and evolve on their own. In event-driven architecture, that middle layer is what lets one change ripple outward to many services without each service needing to know the others exist.
Think of it like a shared mailroom for data. A producer drops off an event once, and the broker decides where that event should live until the right consumer is ready to pick it up. In Kafka, that “mailroom” is organized around topics, which are categories of records, and each topic is split into partitions, which are ordered, append-only logs. That structure matters because Kafka only guarantees total order within a partition, not across the whole topic, so routing events through brokers is also about preserving the right kind of order for the right slice of data.
So how do you keep related events together when the stream starts to move quickly? The answer is partitioning by key. Kafka producers choose which partition to send a record to, and the default strategy uses a hash of the key when one is present; that keeps all events for the same entity, such as a customer or order, on the same path. For a data pipeline, this is a powerful detail because it helps downstream jobs read changes in sequence for one business object instead of mixing them with unrelated updates.
Once events land in the broker, consumer groups make the next move feel coordinated instead of chaotic. Kafka assigns partitions so that each partition is read by exactly one consumer within a group, which gives you load balancing while still preserving the order inside that partition. If you add more consumers, Kafka can rebalance the work; if a consumer fails, another one can take over. That is why a brokered event flow feels sturdy in practice: the broker keeps the handoff clean, and the consumer group keeps the work distributed.
This routing model also gives you a quiet but important superpower: replay. Because Kafka retains published records for a configurable period, consumers can read events after the fact instead of losing them the moment they arrive. That means a new analytics job can catch up from the broker, a missed consumer can recover, and multiple downstream systems can subscribe to the same event stream without forcing the producer to resend anything. In practice, the broker becomes both a delivery path and a safety net.
When should you care about routing events through brokers? The moment one event needs to feed several downstream tasks at once, this pattern starts to pay off. A checkout event, for example, can flow through the broker to revenue reporting, inventory updates, and fraud checks without three separate point-to-point integrations. That is the real reason event brokers matter in data engineering: they give you one controlled stream of truth, then let each consumer take its own turn with it.
Handle Retries and Dead Letters
Building on this foundation, the next question is not whether events will fail, but what happens when they do. In event-driven architecture, a consumer may be healthy most of the time and still stumble on a temporary database outage, a slow API, or a malformed record that needs extra care. That is why retries and dead letters matter so much: they give your pipeline a way to recover from small, temporary problems without losing the event or freezing the whole flow. How do you keep one bad message from becoming everyone’s problem? You give the system a patient retry path first, then a safe place to put events that still refuse to process.
A retry is the system’s way of saying, “Let’s try that again in a moment.” This works best for transient failures, which are short-lived problems that often clear up on their own, such as a network hiccup or a downstream service that is briefly overloaded. In practice, retries often use exponential backoff, which means each wait gets longer after a failed attempt, and sometimes jitter, which adds a small random delay so many consumers do not retry at the same instant. That small bit of pacing matters in event-driven architecture because it keeps a rough patch from turning into a traffic jam.
But retries need boundaries, because not every failure is temporary. If a message is missing a required field, or if the event format no longer matches what the consumer expects, trying again and again will not fix the root cause. This is where the consumer needs to tell the difference between a recoverable problem and a permanent one. A useful mental model is a recipe: if the oven is cold, you wait and try again; if the recipe asks for an ingredient that does not exist, repeating the same steps will not help. That same judgment keeps event-driven architecture from wasting time on hopeless work.
A dead-letter queue, often shortened to DLQ, is the safety net for those stubborn events. A DLQ is a separate destination where the system sends messages that have failed too many times or failed in a way that should not be retried automatically. Think of it like a review bin at the edge of the kitchen: the dish is not thrown away, but it is set aside so someone can inspect it carefully instead of blocking the whole service line. In an event-driven architecture, that separation is valuable because the main stream keeps moving while the problematic event waits for human attention or a special repair job.
The real power shows up when you combine retries with a DLQ instead of choosing one or the other. First, the consumer tries to recover from the kind of failure that often clears itself. Then, if the event keeps failing, the broker or processing layer moves it out of the main path and into the dead-letter queue. That pattern protects both reliability and throughput: good events keep flowing, and bad events do not disappear into silence. It also makes debugging easier, because you can inspect the failed payload, the error message, and the retry history instead of guessing what went wrong after the fact.
This is also where data engineering teams can make the system friendlier for the next person who has to investigate. If you attach clear error details, preserve the original event payload, and log how many attempts were made, a dead letter becomes a useful clue instead of a mystery box. And if your consumers are idempotent, meaning they can handle the same event more than once without producing duplicate side effects, retries become much safer because a second attempt will not accidentally create a second charge or a second row. With those guardrails in place, retries and dead letters turn event-driven architecture into something sturdier, and that sturdiness sets us up to think about the wider safety checks that keep the rest of the pipeline calm.
Monitor, Scale, and Tune
Building on this foundation, the real work begins after the first event lands in production. Monitor, scale, and tune is the part where event-driven architecture stops being a neat diagram and becomes a living system that has to keep up with real traffic. The first signal we watch is consumer lag, which is the distance between what the broker has available and what the consumer group has already committed, because that tells us whether the pipeline is keeping pace or falling behind. Kafka’s own guidance is to watch message and byte rate, request rate, request size and time, plus consumer-side lag and fetch rate.
Once you know what to watch, the picture gets easier to read. Think of lag like a line at a coffee counter: a little line is normal, but a line that keeps growing means the barista cannot keep up. In Kafka and Confluent tools, that lag can be tracked with JMX metrics and control-plane dashboards, and Confluent notes that lag combines offset delay with consumer latency, so a slow database call or a stalled downstream service can show up long before a full outage. When lag rises while broker health looks fine, the bottleneck is often inside the consumer path rather than the broker itself.
Scaling in event-driven architecture is mostly about matching parallel work to partition design. Kafka uses partitions to create parallelism, and each partition in a consumer group is owned by exactly one consumer, which means you cannot keep adding consumers forever and expect more throughput if the topic does not have enough partitions. When a new consumer joins, Kafka rebalances the group, and when new partitions are added, the work can spread again. That is why planning for growth means thinking about both sides of the aisle: the topic layout and the consumer pool.
Tuning is where small configuration changes start to pay off. On the producer side, Kafka batches records together, and batch.size and linger.ms control how much data it waits to collect before sending, which can improve throughput at the cost of a small delay. On the consumer side, max.poll.records controls how many records come back in one poll, while fetch.min.bytes and fetch.max.bytes influence how the broker responds to fetch requests. Those settings are a lot like choosing between cooking one plate at a time and preparing a tray: bigger batches reduce overhead, but they can also make latency feel less immediate.
So how do you decide what to change first when the system starts to slow down? Start with the symptom, then move outward: rising lag points to consumer capacity, uneven lag points to partition skew, and rising request time can point to a broker or network limit. Then tune one lever at a time so you can see what actually helped, because event-driven architecture is easiest to trust when each adjustment has a clear effect. If a spike is temporary, a small batch or a few extra consumers may be enough; if it is steady, you may need more partitions, cleaner event payloads, or a consumer that does less work per message. In that sense, monitoring, scaling, and tuning form a feedback loop, not a one-time setup, and that loop is what keeps the stream calm as it grows.