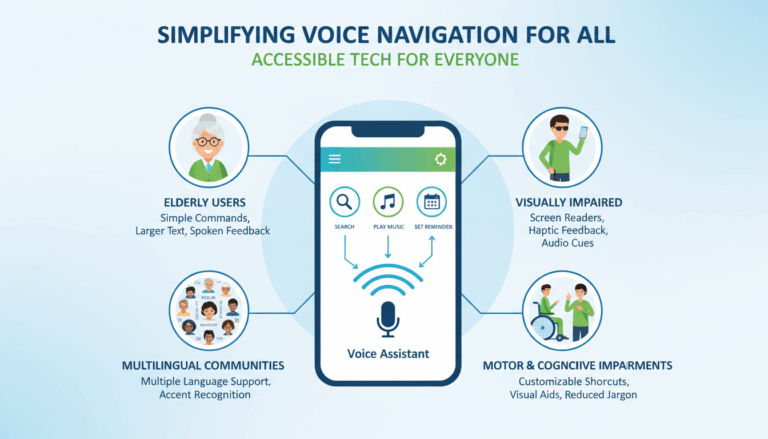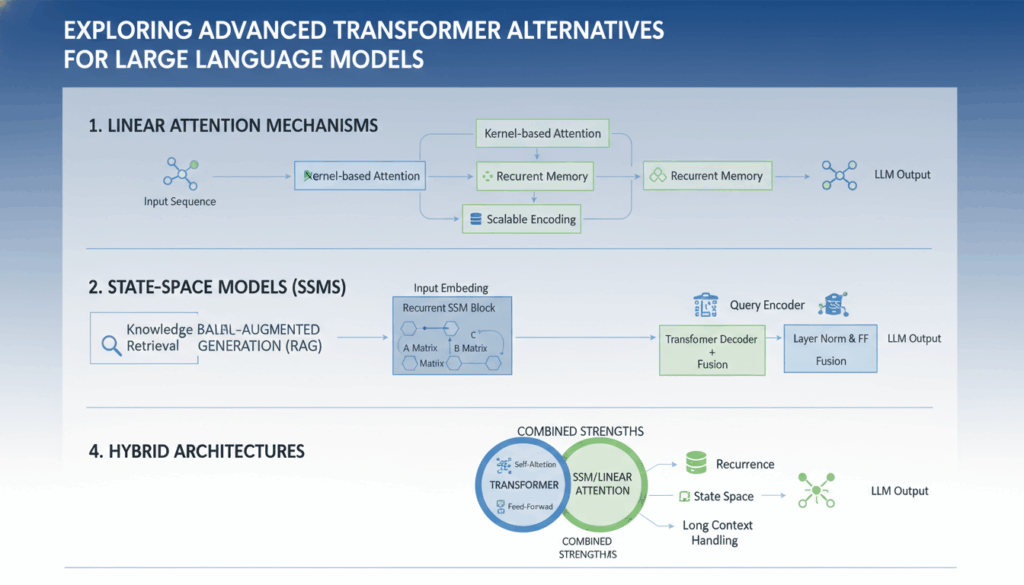
Introduction to Transformer Architectures
Transformers have revolutionized the landscape of natural language processing (NLP) by introducing a model architecture that excels at handling sequence-to-sequence tasks. At its core, the transformative power of this model stems from its ability to handle long-range dependencies and context with remarkable efficiency.
The groundbreaking component of the Transformer model is the self-attention mechanism. Traditional sequence models like RNNs (Recurrent Neural Networks) struggled with processing long sequences due to their sequential nature, resulting in loss of contextual information. Transformers circumvent this limitation by employing self-attention, which allows the model to weigh the significance of different words in the input sentence relative to each other regardless of their positions. This is achieved through scaled dot-product attention, facilitating the model to establish deep contextual relationships without being constrained by sequence length.
Mathematically, the self-attention mechanism involves three primary matrices for each input token: the Query (Q), the Key (K), and the Value (V). The dot product between the Query and Key matrices calculates the attention scores, which are then scaled and passed through a softmax layer to obtain attention weights. These weights help determine the importance of each word in the context of others, effectively capturing the nuances of language meanings.
Unlike traditional models, the Transformer eliminates the need for recurrence or convolutions, using instead a feedforward network that processes and refines the information extracted via self-attention. This parallel architecture enhances training efficiency as it allows Transformers to leverage modern computing power for handling wider data batches.
Another innovative aspect is the application of positional encodings. Since Transformer models do not process data in a sequential manner like RNNs, they require additional means to capture word order information. Positional encodings are added to the input embeddings, providing the model with insight into the sequence’s structure by assigning different encodings to each position. These encodings are implemented as vectors added directly to input embeddings, which can be derived using sine and cosine functions varying at different frequencies, forming a crucial part of the model’s architecture.
Scaling this architecture led to models like BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer), each utilizing the core principles of the Transformer to tackle specific tasks. BERT made strides with bidirectional training to better understand context from both left and right of a token, massively improving outcomes in language understanding tasks. Meanwhile, GPT focused on unidirectional text generation, excelling in crafting coherent text sequences.
In the realm of large language models, these networks are further enhanced by leveraging massive datasets and advancing compute power, enabling them to fine-tune their precision and performance across myriad applications. Training such expansive models involves strategically incorporating techniques like transfer learning, where models pre-trained on extensive corpora can be fine-tuned on specific tasks with relatively smaller datasets, maintaining efficiency while expanding versatility.
The adaptability of Transformers has inspired the development of various specialized architectures tailored to different applications in language processing, such as T5 (Text-To-Text Transfer Transformer) and Vision Transformers (ViT) for image processing. The innovation embedded in Transformer architectures continues to push the boundaries of AI research, promising advancements that hold the potential to reshape our interactions with technology.
Limitations of Traditional Transformers in Large Language Models
Despite their transformative power, traditional Transformers face several challenges when scaled for large language models. One significant limitation is computational cost. The self-attention mechanism, fundamental to the Transformer architecture, has a quadratic complexity relative to the input sequence length. This means that as sequences grow longer, the resources required to process these sequences increase sharply, making it computationally intensive and expensive, especially when dealing with extensive datasets necessary for training large language models.
To illustrate, consider the task of training models like BERT or GPT on large corpora. With traditional Transformers, the memory and compute requirements scale quadratically with the sequence length. Suppose you aim to process sequences of thousands of tokens, often encountered in tasks like long document summarization or open-domain question answering. In such scenarios, the memory usage for storing the attention scores — which capture the pairwise interactions between all tokens — becomes a bottleneck.
Another limitation lies in the inefficiency of handling very long contexts efficiently. While Transformers excel in capturing global context through self-attention, their lack of inherent locality bias can be problematic. In many language tasks, local interactions are crucial, but traditional Transformers assume equal influence from all tokens irrespective of their distance. This lack of bias towards local structure can result in inefficient learning for tasks dominated by local dependencies.
The static nature of the position encodings also contributes to limitations. Although positional encodings allow Transformers to process non-sequential data, these encodings do not adapt to different contexts or tasks dynamically. For example, adapting a model trained on short-form text like tweets to perform tasks involving long-form articles might require significant architectural changes or retraining due to this static nature.
Furthermore, handling multimodal data with traditional Transformers presents challenges. While these models are highly effective for text-based tasks, integrating non-textual data such as images or audio requires complex alterations to their architectures, often involving separate models for different data types or incorporating new layers altogether.
Lastly, large language models based on traditional Transformers also face issues related to data efficiency. They require extensive pre-training on large datasets to learn effectively, which poses challenges in domains where such large-scale high-quality data is not readily available. Combined with high resource demands, this aspect can hinder the democratization of AI, limiting the accessibility of advanced models to organizations with substantial computational resources.
In response to these challenges, several innovative modifications and alternatives are being explored. Sparse attention mechanisms, which reduce the number of pairwise comparisons in self-attention, and memory-efficient architectures like the Reformer, which employs locality-sensitive hashing to reduce complexity, are promising directions. These advancements seek to make Transformers more scalable and efficient, addressing their inherent limitations when building large language models.
Exploring Retentive Networks (RetNet) as Transformer Alternatives
Retentive Networks, or RetNet, present a fascinating alternative to Transformers, addressing several limitations inherent in traditional Transformer models. These networks are developed to retain the comprehensive attention capabilities seen in Transformers while minimizing computational costs and improving efficiency in processing longer sequences.
The primary innovation driving RetNet lies in its approach to sequence retention mechanisms. Unlike the self-attention mechanism in Transformers, which requires a quadratic number of operations as sequence length increases, RetNet focuses on optimizing these operations by using a targeted retention mechanism. This allows the network to capture and process relevant contextual information more efficiently with reduced computational overhead. By focusing only on key interactions necessary for given tasks, RetNet can drastically reduce resource consumption without sacrificing performance.
One of the cornerstones of RetNet’s efficiency is its utilization of a memory-efficient design that mimics biological neural processes. These designs leverage recurrent architectures which maintain historical context over long sequences without reevaluating the entirety of a sequence’s pairwise interactions. Such architectures use a form of selective attention over past information, enabling RetNet to maintain a high degree of performance regardless of sequence length.
RetNet’s architecture also incorporates dynamic positional encodings. These encodings are adaptive, allowing the network to adjust its attention based on the given task or dataset, unlike the static encodings in Transformers. This flexibility means RetNet can generalize more effectively across varied contexts, enabling seamless transitions from short-form to long-form content processing and vice versa.
Further advancements in RetNet involve multi-task learning capabilities. RetNet models can efficiently handle different types of data, including textual and multimodal forms such as images or audio, by modularly integrating domain-specific encoders. This capability allows for an adaptable framework that can respond to diverse AI applications without the need for extensive retraining or architectural modifications.
Another significant advantage of RetNet is its ability to facilitate real-time processing. Given the computational efficiency and the designed scalability, RetNet allows for applications in real-time systems, offering near-instantaneous feedback and interaction across various platforms, which is crucial in settings like live translations, interactive user interfaces, and adaptive learning systems.
The novel retention mechanism ensures that RetNet can handle data efficiently, making it a promising option in scenarios with limited computational resources. This democratizes the technology by making advanced language model capabilities more accessible to organizations without extensive hardware and funding.
Overall, Retentive Networks embody a compelling exploration into transformer alternatives, equipping AI practitioners with robust solutions that address the evolving demands of large-scale language models. This exploration not only opens avenues towards more efficient AI, but it also catalyzes the continuous evolution of language modeling technology in the broader field of artificial intelligence.
Understanding Mamba: A State Space Model Approach
Mamba represents an innovative shift in language modeling by introducing a state space model approach to address some limitations of traditional transformer-based models. This method embraces the concept of state space models, known for their efficacy in managing dynamic systems and lending a more mathematically rigorous structure to solve complex sequence modeling challenges.
A state space model essentially comprises a set of equations that describe how the state of a system evolves over time. In the context of Mamba, this approach utilizes latent states that represent the underlying structure of the input data, allowing the model to process sequences in a more efficient manner. By leveraging these states, Mamba can model temporal data more effectively, capturing both short- and long-range dependencies without the computational burden typical of traditional transformers.
State Space Construction
Mamba’s strength lies in its ability to maintain a dynamic representation of sequences through continuous updates of its state space. This is achieved by defining a state transition model, which determines how latent states change over time. The update mechanism allows Mamba to adaptively focus on relevant elements of the input, much like how attention mechanisms operate but with reduced complexity.
The state transition design integrates seamlessly into large language model frameworks, where the transition function is trained to minimize prediction errors across various tasks. This empowers the Mamba model to deliver superior performance in processing extensive textual data, harnessing transitions that reflect contextual changes within the sequence.
Efficiency and Scalability
One of the prominent advantages of using a state space model in Mamba is the considerable reduction in computational requirements compared to traditional transformers. By abstracting sequence interactions into a compact set of equations, Mamba handles vast input sizes more efficiently. This allows the model to scale with less memory and computational load, addressing one of the core limitations faced by transformers when dealing with long sequences.
In practice, the computational cost does not escalate quadratically with the sequence length, as it does in self-attention mechanisms. Instead, Mamba achieves a linear progression, making it especially adept for applications demanding real-time processing and interactions.
Practical Applications
The ability of Mamba to manage sequences with enhanced efficiency has significant implications across various domains. For example, in natural language processing tasks like real-time translation, sentiment analysis, or document summarization, Mamba offers a nimble solution capable of delivering results promptly without sacrificing accuracy.
In addition to text, the model’s robustness in sequence handling extends to handling multimodal inputs, including audio or even videos. By integrating Mamba’s state space approach with additional sensory processing layers, applications can effectively synthesize diverse data types, opening avenues for more comprehensive AI systems capable of understanding complex interactions in multi-dimensional data.
Integration Into Existing Frameworks
Adopting Mamba into existing language model frameworks involves integrating its state transition components with standard training and optimization protocols. The model leverages classic gradient-based learning techniques while necessitating domain-specific fine-tuning for different applications. This adaptability ensures Mamba’s compatibility with both new projects and established systems requiring next-generation processing capabilities.
The Mamba state space approach represents a pivotal step towards more efficient and scalable AI models, merging foundational machine learning principles with innovative processing strategies. It holds promise not only for revolutionizing state-dependent data processing but also for furthering the state-of-the-art in language modeling technologies.
Perceiver: A Generalist Model for Multimodal Data Processing
The Perceiver model represents a significant advancement in the realm of neural networks by addressing the inherent limitations of traditional models that struggle with diverse multimodal inputs. At its core, the Perceiver is a generalist approach designed to process varied types of data—such as images, video, audio, and more—through a shared architecture, thereby unifying the handling of different modalities within a singular framework.
This model distinguishes itself by adopting a radically different mechanism for attention and encoding, which is crucial for handling the breadth of data it targets. Instead of focusing on a specific area of input, the Perceiver utilizes a cross-attention mechanism that dynamically attends to all input data, regardless of the input type or size. This allows the model to effectively process large inputs without the escalating computational costs associated with traditional Transformer architectures.
Cross-Attention Mechanism
The Perceiver employs a cross-attention layer that selects a smaller, learnable set of latent variables instead of the conventional full input sequence, reducing the number of interactions from quadratic complexity to linear. This efficiently scales the attention mechanism, enabling the model to handle very high-dimensional data, such as video frames or large images. The latent variables are updated through this attention mechanism, which helps in maintaining essential information without the noise and redundancy typical of full data.
The attention is computed between the input data and these latent variables, effectively summarizing input information while enabling the integration of additional data formats. This is particularly advantageous when dealing with multimodal datasets, as it prevents the need for modality-specific networks, thereby streamlining data processing and allowing easier integration of new data types.
Architecture Flexibility
One of the most compelling features of the Perceiver architecture is its ability to adapt dynamically to different data sources. Unlike traditional models that require extensive re-engineering to process new modalities, the Perceiver’s design can accommodate varying types of input by modifying the cross-attention mechanism’s parameters. This adaptability extends to the model’s encoding layers, which can be configured to suit the particular characteristics of the data source, whether temporal or spatial in nature.
Efficient Processing
Perceiver’s efficiency is further enhanced by its use of cascading layers of latent variables. These layers iteratively refine their representations of the input data, focusing on capturing complex relationships and interactions inherent in multimodal inputs. This layered approach ensures computational efficiency, as each layer builds upon the last, minimizing redundant calculations and thereby reducing resource requirements.
Applications and Impact
In practical terms, the Perceiver has far-reaching applications in fields requiring robust multimodal data interpretation. For instance, in autonomous driving, it can process visual feeds, LiDAR data, and audio cues to make informed decisions in real-time. In healthcare, the model can analyze patient data across different modalities—such as imaging scans, genetic information, and clinical records—to support comprehensive patient care and diagnostics.
Experimentation has shown that the Perceiver achieves performance parity with more specialized models on benchmark datasets while offering the unparalleled advantage of generality across data forms. This opens new avenues for researchers and industry practitioners to deploy a single model architecture across varied applications, encouraging innovation and reducing the barriers associated with previous multimodal data handling.
The Perceiver model, by virtue of its novel approach and design, exemplifies the push towards more versatile and comprehensive AI systems capable of understanding and processing the complex, multimodal streams of information that characterize real-world environments. This not only enhances the practical applicability of AI models but also fosters new developments in multimodal research, driving technological progress forward.
Implementing Advanced Transformer Alternatives in Practice
Implementing advanced alternatives to traditional Transformers involves understanding and deploying models like RetNet, Mamba, and Perceiver, each offering unique advantages for specific applications.
Begin by evaluating your application needs. Determine whether your task involves processing long sequences efficiently, managing multimodal data, or integrating real-time processing capabilities. Models like RetNet are particularly suited for tasks requiring efficient sequence retention, while Mamba may excel in scenarios benefiting from state space modeling, such as handling dynamic systems with temporal data.
- Deploying RetNet:
- Setup and Environment: Ensure your development environment has access to high-performance computing resources, as RetNet benefits significantly from GPU acceleration. Libraries like TensorFlow or PyTorch provide support for RetNet’s architecture.
- Sequence Retention Configuration: Adjust RetNet’s retention parameters based on your sequence lengths and task requirements. Focus on optimizing the retention mechanism to minimize computational overhead without compromising performance.
- Training and Validation: Utilize a dataset that reflects the diversity and scale your application intends to handle. Monitor training metrics to fine-tune hyperparameters and maintain model efficiency.
- Implementing Mamba:
- Model Initialization: Set up the state transition models by defining the state equations that accurately represent the task’s dynamics. This involves establishing initial latent state values and transition functions.
- Training the State Space Model: Train Mamba using gradient-based optimization, ensuring the model adapts to both short and long-range dependencies effectively.
- Application in Real-Time Environments: Deploy Mamba in applications requiring seamless integration of past and incoming data, such as interactive AI systems or adaptive interfaces.
- Utilizing the Perceiver Model:
- Data Pre-processing: Prepare your multimodal datasets by ensuring compatibility with the Perceiver’s input structure. This may involve normalizing data formats, splitting data into manageable segments, or encoding input more efficiently.
- Cross-Attention Configuration: The Perceiver requires careful configuration of its cross-attention layers. These layers should be tuned to accommodate the input size and modality, ensuring efficient processing of multimodal data.
- Multi-layered Processing: Implement the Perceiver’s cascading latent layer approach for refining input representations. This feature is crucial for maintaining computational efficiency while ensuring robust output quality across varied data types.
- Performance Monitoring and Iteration: Continuously evaluate model outputs against performance benchmarks, adapting model parameters to enhance precision and resilience.
Best Practices:
- Experiment with Hybrid Approaches: Consider combining elements from RetNet, Mamba, and Perceiver to leverage their unique advantages in scenarios requiring versatile AI solutions.
- Incorporate Transfer Learning: Where appropriate, use pre-trained weights from these models for initialization to reduce training time and enhance model accuracy.
- Engage with Community Contributions: Actively participate in relevant forums and repositories. Open-source communities around these models provide valuable insights and updates, facilitating faster code adaptation and problem-solving.
By systematically integrating these advanced models into your AI workflow, you can enhance the capability, scalability, and efficiency of language models, meeting the sophisticated demands of modern NLP applications.