Introduction to Image Augmentation in Deep Learning
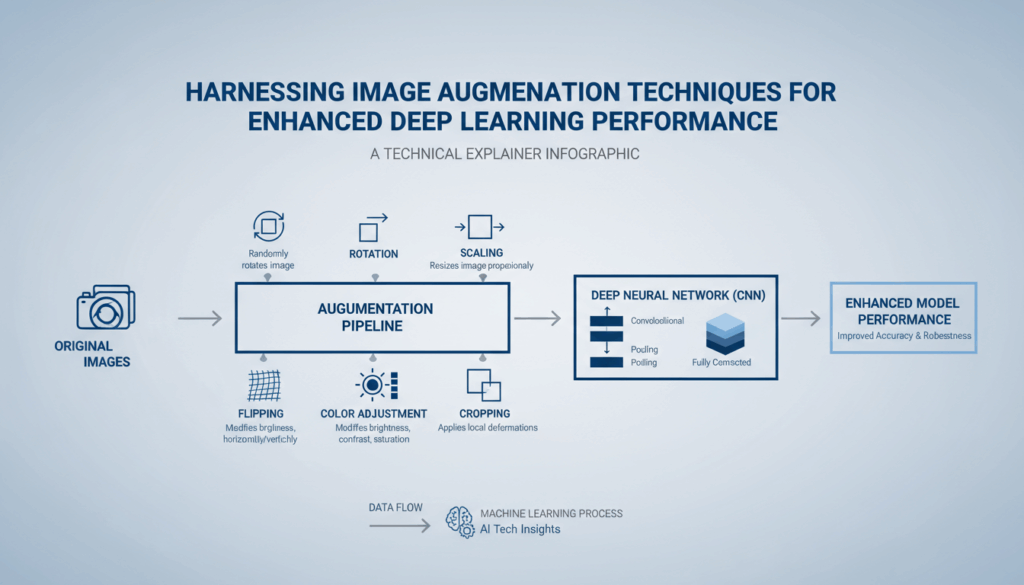
Image augmentation is a vital technique used in deep learning to artificially expand the size and diversity of a dataset. By applying various transformations to existing images, we can generate new, slightly altered training examples, which help to make deep learning models more robust and generalizable to unseen data. This practice is particularly important in situations where obtaining vast amounts of labeled data is challenging or costly.
In deep learning, the quality and quantity of data play a crucial role in model performance. Augmentation techniques such as rotation, scaling, cropping, flipping, and color adjustments can create numerous variations from a single image, thus enhancing the model’s ability to learn intricate patterns and features.
For example, consider a basic set of photographs used to train a model designed for image classification tasks. Simply augmenting these images by rotating them at different angles simulates a model’s exposure to various perspectives, enhancing its ability to recognize objects regardless of orientation. Similarly, flipping images horizontally or vertically ensures the model understands that certain features may appear mirrored in real-world scenarios.
Color augmentation involves altering the brightness, contrast, and saturation of images. This is particularly useful when training models that are intended to perform in different lighting conditions, as it prevents the model from becoming too sensitive to specific color profiles. Scaling and cropping are also employed to ensure that models can focus on relevant object details, even when they appear at varying distances or positions within an image.
Another advanced technique in image augmentation is the use of “Cutout,” which involves adding patches of set color to parts of an image. This technique encourages the model to concentrate on the object’s overall shape and ignore irrelevant features, thus boosting its robustness. Similarly, techniques like “MixUp” and “CutMix” blend pieces of different images together, providing the model with the challenge of learning from a more chaotic, but informative dataset.
Augmentation can be performed on-the-fly during training or pre-processed before training starts. Both approaches have their advantages. Online augmentation provides fresh examples in each epoch, reducing overfitting, while offline processing may lead to faster training times due to the reduced computational load during the epochs.
Libraries such as TensorFlow, Keras, and PyTorch offer extensive support for various augmentation techniques, allowing developers to easily integrate these transformations into their training pipelines. For instance, TensorFlow’s tf.image module includes functions for random cropping, flipping, and adjusting brightness, while Keras provides ImageDataGenerator for seamless preprocessing and augmentation pipeline creation.
By leveraging image augmentation, developers can dramatically improve the generalization capabilities of deep learning models. This not only enhances model performance but also reduces the risk of overfitting, ensuring that models remain flexible and effective in real-world applications where variability is the norm.
Common Image Augmentation Techniques
In the realm of deep learning, image augmentation represents a cornerstone of preprocessing strategies, allowing for the expansion and diversification of training datasets to enhance model performance. A multitude of techniques fall under this umbrella, each serving distinct purposes to bolster a model’s robustness and generalization capability.
One of the most foundational methods is rotation. By rotating an image at various angles, typically ranging from -45 to 45 degrees, we simulate a myriad of perspectives. This not only helps models recognize object integrity regardless of orientation but also mimics real-world scenarios where objects may not always be perfectly aligned.
Scaling is another critical technique, where images are resized to various degrees. This allows models to learn from objects at different sizes, ensuring they remain effective in identifying objects irrespective of distance. Coupled with scaling is cropping, where portions of an image are selectively cut, focusing on specific segments. Random cropping can make models adept at recognizing objects even when they appear partially in view.
Flipping involves mirroring images horizontally and/or vertically. Horizontal flips can simulate natural scenarios like flipped selfies or symmetrical environments. This technique is especially useful in contexts such as face recognition, ensuring the model confidently identifies features regardless of orientation.
Incorporating color adjustments is pivotal in building models that impartially function across diverse lighting conditions. Adjustments might include changing the brightness, contrast, saturation, and hue of images. For instance, by randomly altering the brightness by a specific factor, models become adaptable to variations like day and night scenes or indoor vs. outdoor lighting.
More advanced techniques like Cutout involve placing patches of uniform color on random sections of an image. This compels models to understand object features even when parts are obscured, fostering reliance on contextual understanding rather than specific details. MixUp and CutMix are innovations where either multiple images are combined via blending or segments of one image replace parts of another. These approaches create hybrid datasets forcing models to operate under complex, compounded conditions.
Affine and perspective transformations allow for subtle or radical changes in the spatial layout of images. By implementing these transformations, developers simulate distortions that could result from camera angles, enhancing a model’s dexterity in interpreting warped or skewed visuals.
Tools such as TensorFlow, OpenCV, and PyTorch offer comprehensive support for these augmentation strategies. TensorFlow, for instance, provides APIs that simplify the implementation of these techniques within a training pipeline. By utilizing packages such as TensorFlow’s tf.image or PyTorch’s torchvision.transforms, users can easily integrate augmentation functions into their model training workflows, benefiting from automated, on-the-fly processing during model training cycles.
Employing a systematic augmentation strategy not only diversifies the dataset but can significantly mitigate overfitting, a common challenge in deep learning. Through intentional application of these augmentation techniques, models become more adept at interpreting unseen data, thus ensuring the accuracy and reliability of AI applications in varied and unpredictable real-world environments.
Implementing Image Augmentation with Albumentations
Albumentations is a powerful and flexible image augmentation library designed to enrich datasets with various complex transformations efficiently. It boasts a simple API that integrates seamlessly with various deep learning frameworks such as PyTorch, TensorFlow, and Keras.
One of the hallmarks of Albumentations is its ability to perform both basic and advanced augmentation techniques at impressive speeds, thanks to its strong internal optimizations. Whether it’s straightforward rotations or intricate combinations of multiple transformations, Albumentations enables developers to diversify their image datasets effectively.
Installing Albumentations
To get started with Albumentations, the first step is to install the library. This can be done using pip, a package manager for Python:
pip install albumentations
Basic Usage
Integrating Albumentations into your workflow begins with crafting an augmentation pipeline. The process involves importing the library and defining a list of desired transformations.
import albumentations as A
from albumentations.pytorch import ToTensorV2
# Define an augmentation pipeline
transform = A.Compose([
A.Rotate(limit=40, p=0.7),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.2),
A.RandomBrightnessContrast(p=0.3),
ToTensorV2()
])
In this example, the pipeline includes several steps:
– Rotation: Images are rotated randomly within a limit of 40 degrees.
– Horizontal and Vertical Flips: Images are flipped with specified probabilities.
– Brightness/Contrast Adjustments: Random modifications to brightness and contrast.
The ToTensorV2() transformation converts the image to a PyTorch tensor, facilitating seamless integration with deep learning models that expect tensor inputs.
Applying Transformations
To apply the defined transformations, pass images through the pipeline using a simple function. Considering the standard format, images must first be read and converted to NumPy arrays.
import cv2
# Read an image using OpenCV
image = cv2.imread('path/to/image.jpg')
# Apply transformations
augmented = transform(image=image)
augmented_image = augmented["image"]
OpenCV reads the image into a NumPy array, and the transformation pipeline modifies it accordingly. The augmented image is then stored in augmented_image.
Advanced Techniques
Albumentations supports advanced techniques like Cutout, Grid Distortions, and Elastic Transform. These can further enhance data diversity, aiding models in developing robust feature recognition capabilities under varied conditions.
Cutout involves masking random portions of the image, prompting models to focus more on existing features than on missing parts. This can be implemented as:
A.Cutout(num_holes=8, max_h_size=8, max_w_size=8, p=0.5)
Grid Distortion creates grid lines on images that can distort their sections, simulating diverse lighting or angle conditions:
A.GridDistortion(p=0.3)
Another compelling transformation is Elastic Transform, which applies a randomized elastic deformation to images. This mimics the effects of elastic distortions on various surfaces:
A.ElasticTransform(p=0.2)
Considerations and Best Practices
When implementing image augmentation, it is vital to tailor the transformations to the specific task at hand. Over-augmentation may lead to images that are too unrealistic, potentially confusing the model. It is best to start with minor augmentations and gradually increase complexity.
Moreover, Albumentations allows for the setting of probabilities for each transformation, striking a balance between augmentation diversity and training stability.
By using such a versatile library, data scientists and machine learning practitioners can create robust datasets that enhance the generalization of deep learning models, guaranteeing improved performance in real-world settings.
Evaluating the Impact of Augmentation on Model Performance
Evaluating the impact of image augmentation on model performance is an essential aspect of developing robust deep learning systems. By systematically analyzing how various augmentation techniques affect model accuracy, generalization, and overfitting, developers can fine-tune their models for optimal performance in real-world conditions.
Understanding Model Evaluation Metrics
To gauge the impact of augmentation, it’s crucial to employ appropriate evaluation metrics. Common metrics include accuracy, precision, recall, F1-score, and AUC-ROC curve. Each of these provides insights into different aspects of a model’s performance. For classification tasks, precision and recall can measure the balance between true positives and false positives, offering a deeper understanding of how well the model generalizes to new, unseen data.
Experimental Setup
An experimental setup involves training a baseline model without augmentation and comparing its performance against models trained with various augmentation strategies. This approach helps isolate the effect of augmentation from other variables. For instance, in a study of image classification, one might begin by training a convolutional neural network (CNN) without augmentation to establish baseline performance metrics.
Controlled Use of Augmentation Techniques
By introducing augmentation techniques such as rotation, flipping, and scaling individually, one can observe their direct impact on model performance. Suppose the baseline model achieves an accuracy of 85%. By applying augmentation like random flipping or color jitter, you may notice an accuracy increase to 90%, indicating improved generalization. Performing controlled experiments helps identify which transformations contribute the most to performance gains.
Benchmarking and Analysis
Benchmarking involves training models with different combinations of augmentation techniques and comparing their outcomes. Tools such as TensorBoard can visualize metrics over time, highlighting how augmentation influences learning curves. For example, using TensorFlow, one could log validation accuracy and loss to identify trends such as decreased overfitting, which might appear as steadier validation accuracy over epochs when using augmentation.
Assessing Generalization with Validation Errors
Additional insights can be obtained by closely monitoring validation errors. If validation errors decrease more substantially in models trained with augmentation compared to those without, it often indicates that the augmented models generalize better and are less prone to overfitting. This is vital in applications requiring high model reliability under diverse conditions, such as autonomous driving or medical imaging.
Real-World Case Studies
Case studies provide a practical perspective on augmentation’s effectiveness. For example, in facial recognition systems, augmentation techniques like alignment shifts and occlusion simulation can significantly improve accuracy rates by over 5% due to the increased variability in training data. Such performance improvements underscore the crucial role of augmentation in crafting models that remain consistent across different lighting, angles, and obstructions.
Conclusion and Next Steps
Understanding the specific contributions of augmentation requires both quantitative and qualitative analysis. As data augmentation evolves with techniques like GAN-based augmentation, continuous evaluation becomes necessary to adapt to innovative strategies. By building on foundational metrics and methodologies, developers can elevate model performance, ensuring solutions are not only theoretically robust but also practical for real-world application.
Advanced Augmentation Strategies and Best Practices
In the realm of deep learning, leveraging advanced augmentation strategies is crucial for enhancing model robustness and performance. These strategies include methods that push beyond basic transformations to introduce variability and complexity, aiding in the development of models that are more adaptable to real-world environments.
One prominent strategy is Stochastic Augmentation, which involves applying a randomized selection of transformations from a predefined set. This approach can blend basic transformations like flipping and rotation with more complex ones, such as perspective transformations, to generate diverse training images. By ensuring that each epoch presents different variations of the dataset, stochastic augmentation reduces overfitting and improves model generalization.
Geometric Transformations offer an advanced layer of complexity. Besides common manipulations like scaling and rotation, incorporating affine and perspective transformations can simulate different viewing angles, tilts, or even lens effects that might occur in real-life scenarios. This helps in training models to recognize objects when faced with distortions or varied camera perspectives.
Photometric Augmentation Techniques like Color Jittering go further than simple brightness and contrast adjustments. These techniques introduce changes in hue, saturation, and even add noise to mimic different lighting environments or sensor outputs. Such approaches are particularly beneficial for models expected to operate across varied lighting conditions, like outdoor surveillance systems.
Domain-Specific Transformations look into the unique challenges faced by particular applications. For instance, in medical imaging, augmentations such as Elastic Deformations mimic tissue distortions, presenting models with more anatomical variations. This approach helps in training models to recognize pathological features across different instances and patient demographics.
Another cutting-edge strategy is the use of Adversarial Augmentation. This involves using adversarial examples—slightly perturbed inputs designed to trick models—during training. These examples make models more robust to adversarial attacks and improve their ability to generalize by focusing on learning core features rather than surface details.
Neural Style Transfer represents another innovative technique. It involves transferring styles between images to simulate various textures, allowing models to focus on content regardless of stylistic changes. This is particularly useful in applications like fashion retail or media, where product visuals can vary greatly in style and presentation.
Incorporating AutoAugment, a recent advancement, uses reinforcement learning to automatically search for optimal augmentation policies tailored to specific datasets. This ensures that the augmentation pipeline is dynamic, continuously learning and adapting to maximize model performance.
Finally, understanding and aligning augmentation strategies with the task’s goal are key. Over-augmentation should be avoided as it might produce unrealistic images that confuse rather than help the model. Careful tuning of parameters and probabilities associated with each augmentation type helps maintain a balance, ensuring images remain realistic and contribute positively to model training.
Best practices in implementing these strategies include:
-
Monitoring Performance Metrics: Regularly evaluate model performance on validation datasets to ensure that augmentations are beneficial. Using metrics such as precision and recall can provide deeper insights into which transformations lead to better generalization.
-
Gradual Complexity Increase: Start with simple augmentations and progressively introduce more complex strategies. This allows for observing incremental improvements and mitigates the risk of overwhelming the model.
-
Domain Expert Consultation: In fields like medical imaging or autonomous driving, consulting with domain experts helps tailor augmentation strategies that are both realistic and challenging, enhancing the model’s relevance and applicability.
These advanced augmentation strategies, when implemented correctly, offer significant long-term benefits, such as improved model robustness and greater adaptability to unseen data. They form a cornerstone in the pursuit of developing deep learning systems capable of functioning reliably in diverse and unpredictable environments.