Introduction to Attention Mechanisms in Large Language Models
Large language models have experienced a major transformation with the introduction of attention mechanisms, revolutionizing how these models understand and generate human language. The concept of attention in neural networks fundamentally relates to the way models prioritize different pieces of input data, akin to how a human focuses on certain aspects of a conversation while filtering out other distractions.
The essential trait of attention mechanisms is their ability to dynamically assign varying levels of importance to different words in an input sequence, thus allowing the model to focus on relevant information. This ensures that the model can better understand context and maintain coherence in language tasks like translation, summarization, and question-answering.
One of the core components driving this change is the “scaled dot-product attention,” introduced in the seminal paper “Attention is All You Need” by Vaswani et al. This mechanism computes a weighted sum of values—derived from the input data—where the weights are determined by the relevance of a key to a query. In essence, every word in a sentence interacts with every other word in a weighted manner, determining their significance through dot product scores. These scores are then passed through a softmax function to produce the final weights.
In practice, attention mechanisms enable large language models to handle dependencies in language more flexibly than ever before. For example, when translating a sentence from English to French, the model can dynamically determine which parts of the English sentence are more relevant for each part of the French output, rather than strictly adhering to a fixed sequence.
Beyond traditional sequence models, attention has paved the way for architectures like the Transformer. Unlike recurrent models, Transformers leverage attention to process entire sequences simultaneously, offering unparalleled efficiency and accuracy. This architecture shines in multi-task scenarios, retaining salient information across vast contexts.
Another innovative adaptation is the multi-head attention mechanism, which enhances the model’s comprehension by dividing the attention into multiple, parallel layers or “heads.” Each head learns a different aspect of linguistic information, such as syntax, semantics, or positional context, thereby enriching the overall language representation.
Overall, attention mechanisms have not only contributed to substantial improvements in performance metrics across a variety of language tasks but also provided insights into making neural networks more scalable and adaptable to complex linguistic challenges. As research progresses, further refinements and new configurations of attention are likely to continue transforming how large language models are developed and utilized.
The Evolution of Attention Mechanisms: From Seq2Seq to Transformers
In the realm of neural architectures, attention mechanisms have undergone a significant transformation, evolving from the foundational sequence-to-sequence (Seq2Seq) models to the sophisticated Transformers. This evolution has fundamentally changed how models process and generate language, enabling more nuanced and efficient handling of linguistic data.
Seq2Seq models, initially designed for machine translation tasks, employed a straightforward encoder-decoder structure. The encoder processed an input sequence (e.g., a sentence in English) into a fixed-sized context vector, while the decoder generated an output sequence (e.g., the translated sentence in French) from this vector. Although effective, a major limitation was the bottleneck created by the single context vector, which often struggled with long or complex sentences.
The introduction of attention mechanisms addressed this bottleneck by allowing the model to focus on different parts of the input sequence dynamically. In essence, rather than relying on a fixed vector, an attention mechanism enabled models to create a context vector for each output word by computing a relevance score between input and output sequences. This innovation meant that each word in the output could flexibly consider multiple parts of the input, leading to improvements in translation accuracy and fluency.
However, Seq2Seq models with attention still carried over certain inefficiencies from their use of recurrent neural networks (RNNs). RNNs process inputs sequentially, which becomes a computational bottleneck for long sequences. This limitation gave rise to the Transformer model.
Transformers revolutionized attention by abolishing the need for recurrence altogether. Their architecture relies entirely on self-attention mechanisms to draw global dependencies between input and output. This is achieved through multi-head self-attention, where inputs are processed in parallel, allowing for significantly faster computation. Each head in the self-attention mechanism captures different linguistic features, enriching the model’s understanding of the sequence structure.
The key innovation in Transformers lies in the use of scaled dot-product attention, where the input sequence is linearly transformed into three components: queries, keys, and values. By calculating dot products between the query and keys, the model determines the relevance of each piece of data. The resulting scores are scaled, typically divided by the square root of the dimension size to stabilize gradients, and passed through a softmax operation to ensure they sum to one, creating attention weights.
Moreover, positional encodings are crucial in Transformers, providing information about the order of the sequence, which is otherwise neglected in self-attention computations. This positional information is added to the input embeddings, enabling the model to maintain sequence order without needing recurrent layers.
Thanks to these architectural changes, Transformers have achieved state-of-the-art results across various tasks beyond translation, including text summarization, question answering, and language modeling. Their ability to handle long-range dependencies efficiently has opened new avenues for research and application in artificial intelligence.
Overall, the journey from Seq2Seq models to Transformers underscores a pivotal shift in how attention mechanisms are configured and applied. This evolution reflects a broader trend towards more flexible and powerful neural network designs, pushing the boundaries of what’s possible in natural language understanding and generation.
Understanding Self-Attention and Multi-Head Attention
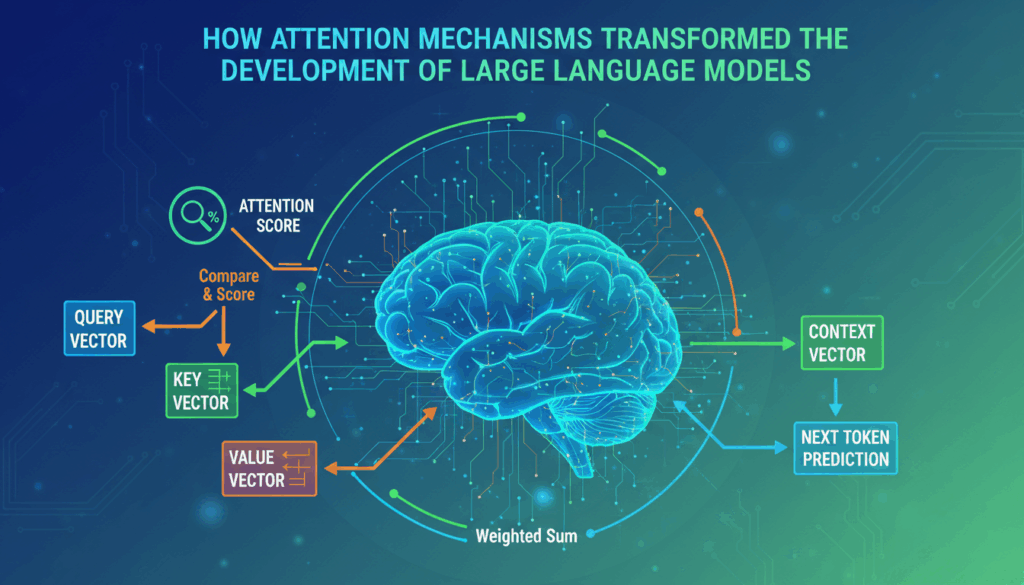
Self-attention is a pivotal mechanism enabling a model to relate different positions of a single sequence efficiently to calculate its output. This mechanism is at the core of many modern natural language processing architectures, allowing each token in the input sequence to interact with all other tokens, providing a global overview that enhances understanding.
The process begins by transforming each token in the input sequence into three vectors: a query vector, a key vector, and a value vector. These vectors are created through linear transformations, each with an assigned matrix. The key insight is that each query is compared against every key to compute a relevance score, typically achieved using a dot product. These relevance scores are crucial as they determine how much focus the model should place on different parts of the sequence when producing a particular output.
Once the relevance scores are calculated, they are scaled to stabilize the gradients during training—often by dividing by the square root of the dimension of the key vectors. This scaling is followed by applying a softmax function, converting relevance scores into a distribution of attention weights. These weights tell the model how much attention to pay to each input token when producing the response for a particular position. The final challenge is to multiply these weights by the corresponding value vectors, summing them up to produce a single output for each token position.
In multi-head attention, this process is replicated multiple times in parallel, each with learned linear projections of queries, keys, and values. By splitting inputs into multiple segments, or “heads,” the model can independently focus on different parts of the sequence. Each head captures various linguistic features or syntactic paths across the sequence, providing diversified attention projections.
To combine the outputs from each head, the model concatenates the individual results, effectively allowing integration across different heads. These concatenated outputs are then passed through another linear transformation. The combination enables the model to glean a more nuanced understanding by leveraging diverse perspectives of the input data, which is essential for comprehending complex language tasks.
Multi-head attention thus extends self-attention in a way that maintains the individual benefits of each head while enriching them with collective insights. This enriches the model’s ability to understand context, capture long-range dependencies, and represent complex relationships within the data more richly than a single attention mechanism could achieve on its own.
These capabilities have contributed significantly to the exceptional performance of Transformers across various natural language processing tasks, from machine translation to text comprehension and beyond. Their ability to manage dependencies within sequences without requiring recurrent layers marks a monumental shift in neural architectures, offering both computational efficiency and enhanced learning capabilities.
Impact of Attention Mechanisms on Model Performance and Scalability
The integration of attention mechanisms into language models has been crucial in enhancing both their performance and scalability. By strategically focusing on relevant pieces of input data, attention allows models to handle complex language tasks with greater precision and efficiency.
An exceptional feature of attention mechanisms is their ability to improve model performance across a variety of tasks such as translation, summarization, and question-answering. At the core of this improvement is the capability to maintain context and coherence, even across lengthy and complex input sequences. Traditional recurrent neural networks often faltered when faced with long-range dependencies due to their sequential processing nature. In contrast, attention mechanisms enable models to process entire sequences simultaneously, allowing each token in a sequence to attend to all others at once. This results in a more comprehensive understanding of the input data’s global context.
For instance, in neural machine translation, an attention mechanism allows a model to selectively focus on different segments of the source sentence as it generates each target word. This dynamic focusing leads to translations that more accurately preserve the nuance and meaning of the original text. Moreover, attention mechanisms contribute to performance by reducing the model’s overreliance on word order, allowing a better grasp of syntactic and semantic relationships that might not follow a linear path in the input sequence.
Scalability is another significant advantage achieved through attention mechanisms. Prior model architectures often faced scalability issues due to their inability to parallelize processes efficiently. Attention mechanisms, particularly in the Transformer architecture, circumvent this limitation by eschewing recurrent structures in favor of parallelizable, attention-based computation. Multi-head attention, an extension of this concept, processes data through multiple attention layers or “heads.” Each head is capable of capturing distinct linguistic features, such as syntax and word position information, which allows models to scale efficiently with data complexity and size.
Furthermore, the computational efficiency of attention mechanisms enables the handling of extremely large datasets typical in modern language models, such as BERT or GPT-based architectures. As more tokens can be processed in parallel without suffering from gradient instability, models enjoy both faster training times and the ability to scale to unprecedented sizes, accommodating billions of parameters with increased ease.
The impact on model performance and scalability can’t be overstated, especially when considering recent advancements. The introduction of positional encodings in attention-based models addresses the challenge of sequence order recognition without needing recurrent layers. This innovation has paved the way for exploring deeper architectures, allowing researchers to experiment with models that were previously impossible due to computational constraints.
Overall, attention mechanisms not only elevate the precision and fluidity of natural language processing tasks but also foster innovations in model size and complexity management. As a result, they have become a staple in designing modern, high-performing language models capable of operating at scale, greatly influencing the trajectory of research and application in artificial intelligence.
Recent Advances in Efficient Attention Mechanisms
In recent years, significant advancements have been made in efficiently implementing attention mechanisms, primarily driven by the need to scale neural architectures with limited computational resources. These innovations not only optimize the computational requirements but also enhance the effectiveness of attention, meeting the growing demands of real-world applications.
One approach has been the development of sparse attention mechanisms. Traditional attention mechanisms calculate relevance by considering every possible interaction between tokens, which leads to quadratic time complexity with respect to sequence length. Sparse attention reduces this computational burden by limiting the number of token interactions considered. For instance, the Reformer model employs locality-sensitive hashing to efficiently approximate attention scores, ensuring that only the most relevant interactions are computed.
Another noteworthy innovation is Linformer, which approximates the original attention matrix using a lower-dimensional representation. By projecting the key and value matrices into smaller spaces, Linformer maintains a linear complexity in sequence length. This method significantly reduces memory usage and computational requirements while retaining performance accuracy.
Performer models introduce a further simplification with the use of kernelized attention. By leveraging positive orthogonal random features, Performer approximates key-query interactions, allowing for a linear time complexity in computing the attention matrix. This advancement represents a breakthrough in handling long sequences more rapidly without sacrificing precision.
The concept of Long-Short-Term Memory (LSTM) enhancements has been revisited through the lens of attention. Recently, memory-efficient attention layers have been developed to dynamically allocate memory resources based on the attention’s contextual needs. This dynamic memory allocation ensures that only essential computations consume substantial resources, thereby freeing capacity for larger inputs.
Additionally, the integration of low-rank factorization methods in attention matrix computation has gained traction. By decomposing the attention operations into smaller, manageable matrices, models leverage the mathematical properties of low-rank matrices to efficiently capture relevant information. These approaches reduce computational overheads significantly while preserving or even enhancing model performance.
Efficient Transformers like the Longformer and Big Bird have also introduced novel designs for attention. Longformer incorporates a combination of global attention for select tokens and dilated convolutions for local context, ensuring that models can process extended sequences efficiently. Big Bird, on the other hand, uses a sparse block matrix within the attention layer, cleverly mixing global and random tokens to simulate full-attention behaviors but at a fraction of the computational cost.
Moreover, innovative data processing techniques, such as knowledge distillation and model pruning, are applied alongside attention mechanisms to further enhance efficiency. These methods aim to reduce model size and complexity without compromising functionality, making large-scale models more viable for deployment across diverse platforms.
Overall, these advancements in efficient attention mechanisms underscore the dynamic nature of AI research, where the convergence of computational efficiency, resource management, and architectural finesse drives the next wave of breakthroughs in natural language processing and beyond. These methods not only reflect progress in theoretical understanding but also promise widespread applicability in real-world scenarios where efficiency is paramount.



