Common LLM use cases
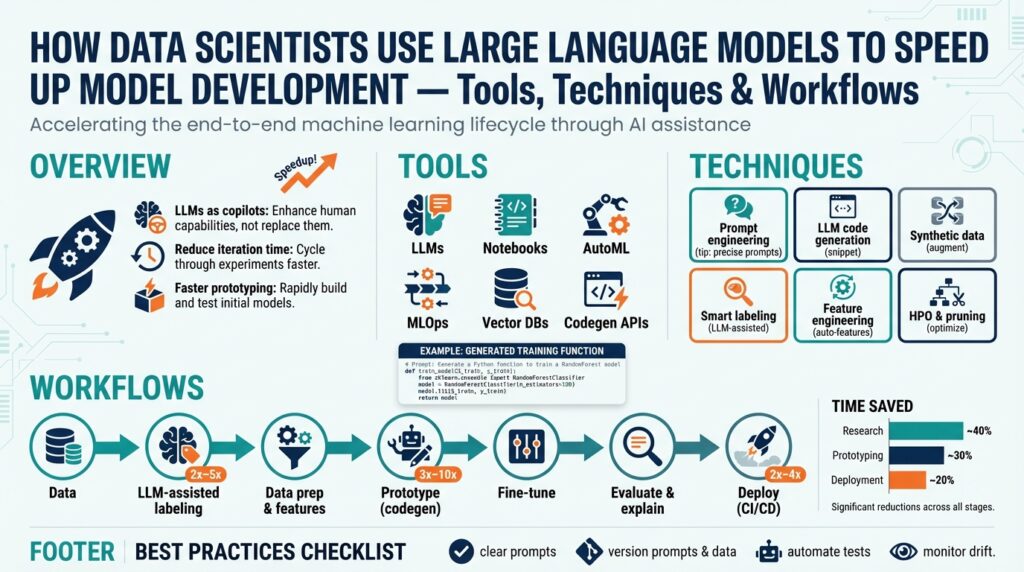
Building on this foundation, many data scientists are using LLMs and large language models to cut weeks of busywork out of the model development lifecycle. We face the same tedious tasks repeatedly—exploratory analysis, feature engineering, documentation, experiment interpretation, and deployment scaffolding—and generative models can accelerate each step without replacing domain expertise. How do you integrate an LLM effectively into your workflow so it helps rather than distracts? We’ll show concrete patterns and examples you can adapt to your pipelines.
One of the highest-leverage uses is exploratory data analysis and feature generation. Instead of writing dozens of ad-hoc scripts, you can prompt an LLM to produce reproducible EDA snippets, suggest candidate features, or generate code to test correlations and missing-value strategies. For example, ask for a Pandas snippet: Create a robust binning strategy for a skewed numeric column and produce a one-hot encoding pipeline with sklearn—the model will return code you can inspect and run, saving initial iteration time. Use the output as scaffolding: validate assumptions with real data, add unit tests, and commit the vetted snippet to your repo.
Automated documentation and metadata production is another practical win for model development. Generate model cards, data sheets, and README content from experiment metadata so your registry entries are consistent and searchable. For instance, feed an LLM your MLflow experiment table and ask it to produce a human-readable summary describing model intent, training dataset characteristics, and known limitations; this reduces manual overhead and improves reproducibility. Keep a standardized prompt template to ensure the generated text includes required fields for governance and compliance.
LLMs speed up prototyping by scaffolding training code, hyperparameter search strategies, and evaluation harnesses. Rather than hand-coding a training loop, prompt the model for a tested PyTorch skeleton: initialize torch.nn.Module, set up torch.optim.Adam, implement a train_epoch function, and include a simple early-stopping callback. Use the generated scaffold to iterate quickly: swap datasets, instrument metrics, and run small experiments to validate performance. This pattern is particularly useful during model architecture exploration when changing many components rapidly.
Interpreting experiment logs and surfacing actionable insights is a recurrent bottleneck that LLMs handle well. Give the model your metric tables, confusion matrices, and hyperparameter grid results and ask for a prioritized explanation of failure modes—e.g., “Why did recall drop when regularization increased?”—and suggested next steps like targeted data augmentation or class-weight adjustments. Integrate this into a CI step that runs after experiments and generates commentary attached to the run, so engineers receive concise, prioritized recommendations alongside raw metrics.
Data labeling, synthetic example generation, and instruction tuning for annotators are further productive uses. Use LLMs to expand a small labeled set with paraphrases, create edge-case examples for low-frequency classes, or draft clear annotation instructions that reduce inter-annotator disagreement. For sequence-labeling tasks, for instance, generate synthetic sentences containing rare entity patterns to boost recall during training. Always validate synthetic data quality with held-out human review and monitor for amplified biases introduced by generated examples.
Finally, LLMs can help with deployment and MLOps tasks like writing Dockerfiles, Kubernetes manifests, and CI/CD pipelines from templates. Ask for a minimal Dockerfile plus a k8s Deployment manifest that injects model artifacts from your artifact store, then review and harden the output for security and observability. When should you rely on generated manifests? Use them for iteration and prototyping; require human review and automated linting before any production rollout.
Taken together, these patterns make LLMs a practical productivity multiplier across the model development lifecycle. They speed up routine engineering work, improve documentation fidelity, and help translate experimental results into concrete next steps—provided we validate, test, and govern generated outputs. In the next section we’ll examine evaluation and validation strategies that ensure these accelerations don’t introduce risk into your models.
Choosing tools and platforms
When you decide to integrate an LLM (large language model) into an existing pipeline, the choice of tools and platforms shapes whether the integration accelerates or derails model development. You need platforms that support reproducible training, low-latency inference, and governance without forcing constant rework. How do you pick the right hosting, orchestration, and developer tooling so your team moves faster while staying auditable and cost-effective?
Start by mapping requirements to concrete capabilities rather than chasing feature lists. Determine whether you need heavy fine‑tuning or light prompt tuning, strict data residency, or high throughput inference; each constraint pushes you toward different platforms. For example, on-prem or private-cloud deployments give you full control over data governance and model weights, while managed inference services reduce operational burden and accelerate iteration. Weigh latency, cost-per-inference, and model lifecycle support (training, evaluation, deployment, rollback) as primary axes when comparing options.
Consider interoperability with your existing MLOps stack as a non‑negotiable. Choose platforms that integrate with your experiment tracking, model registry, CI/CD pipelines, and feature store so outputs from large language models can be versioned and audited alongside other models. In practice this means exposing LLM prompts and model versions as artifacts in your registry, adding tests to CI that validate prompt outputs against acceptance criteria, and routing generated features through the same validation and drift-detection pipelines you already run for supervised models. That consistency prevents the LLM from becoming an island in your development lifecycle.
Operational patterns matter as much as raw capability. If you expect bursty inference (e.g., real-time code-gen or chat) prioritize horizontal autoscaling and container orchestration that supports GPU scheduling; if batch synthesis is most common, optimized serverless or batch processing can be far cheaper. Wrap the LLM client in a typed interface that centralizes retry logic, rate limits, and token accounting so downstream engineers don’t have to reimplement guards. This pattern reduces accidental cost spikes and makes it straightforward to swap providers or on-prem servers during experiments.
Observability and testing for generative outputs demand different signals than traditional models. Track token consumption, latency percentiles, prompt-response drift, and a measure of semantic correctness such as automated reference checks or human-in-the-loop sampling for hallucination rates (hallucination: when a model asserts false facts). Use canary or shadow deployments to compare a new LLM configuration against production under real traffic, and run A/B tests that measure business metrics tied to generated outputs. Instrumenting these signals early prevents small changes in prompts or model versions from silently degrading downstream metrics.
Security, compliance, and cost-control are practical selectors when you narrow choices. If your data contains PII, prefer platforms that offer private networking, in-transit and at-rest encryption, and fine-grained IAM. Implement prompt sanitization and input filtering at the client boundary to reduce leakage risks. From a cost perspective, benchmark end-to-end cost-per-task (including engineering time) rather than raw per-token price; sometimes a slightly more expensive inference provider is cheaper overall because it reduces development friction and iteration time.
Put the selection process into practice with a short, focused pilot that evaluates integration friction, latency under realistic load, cost projections, and observability. Run the same prompts and workloads across candidate platforms, version everything in your registry, and treat the pilot like an experiment—define success criteria, collect metrics, and iterate. Doing this gives you a defensible choice that supports rapid model development, consistent governance, and smooth handoffs between research and production.
Taking this pragmatic, integration-first approach aligns tooling with the lifecycle patterns we described earlier; next we’ll dig into evaluation and validation strategies that ensure those tools accelerate progress without introducing unacceptable risk.
LLM-assisted data cleaning
Building on this foundation, we can treat large language models as accelerators for the repetitive, rule-heavy parts of data cleaning rather than as replacements for domain expertise. In practice you’ll use an LLM to triage messy columns, suggest imputation strategies, and generate reproducible cleaning code that you then validate and harden. Front-load prompts with schema and a few representative rows to get actionable output quickly; this reduces iteration time and surfaces edge cases early in the pipeline. Using an LLM this way speeds up routine data cleaning without surrendering control of correctness or provenance.
A common pattern is to use the model for rapid discovery and categorization before writing permanent scripts. First ask the LLM to infer column types, detect duplicates, and flag likely outliers from a small sample, and then treat its suggestions as hypotheses to verify. How do you make sure those hypotheses are safe to act on? We recommend a human-in-the-loop review for any automatic changes that affect labels or target-dependent features, and automated acceptance criteria for syntactic fixes like normalization or trimming. This hybrid approach keeps the model useful for exploration while preserving accountability.
Next, turn generated suggestions into reproducible code snippets that integrate into your CI pipeline. Prompt for a concrete output—“Produce a pandas function that normalizes postal codes, splits multi-value tags into lists, and records a change log column”—and the model will return scaffolded code you can instrument with unit tests. For example, wrap the generated function with assertions that check schema conformance, null-rate thresholds, and idempotency (running twice yields the same result). Save these artifacts as versioned notebooks or committed modules so the cleaning steps are auditable and testable across experiments.
Validation and guardrails are essential because models can hallucinate plausible-looking but incorrect transformations. Create a small validation suite that includes synthetic edge cases and a stratified sample of real rows to catch semantic errors (e.g., swapping city and state). Use data-contract tools or a rules engine to enforce invariants—unique ID stability, ranges for numeric columns, allowed categorical vocabularies—and run these checks automatically after any LLM-derived transformation. Also capture the prompt, model version, and output diffs as part of the artifact so you can trace why a transformation occurred and roll it back if necessary.
Operational considerations determine whether you run the LLM interactively, in batch, or as a service in your pipeline. For large historical tables do batch prompting against column summaries; for near-real-time ingestion use a lightweight prompt template plus caching to avoid repetitive token costs. When token budget or latency is critical, prefer small specialized models or prompt-compression techniques (summaries, representative sampling) and reserve larger models for complex semantic normalization tasks. Fine-tuning or retrieval-augmented generation can reduce hallucination for domain-specific vocabularies, but weigh that against the cost of maintaining tuned weights and retraining as schemas evolve.
A concrete example we’ve used: cleaning customer support transcripts with messy agent tags and inconsistent intent labels. We asked an LLM to canonicalize agent role names, split combined timestamp+channel strings, and generate candidate intent labels for low-frequency phrases. The model produced a high-quality first pass that reduced manual labeling by roughly half, while our QA workflow caught the remaining ambiguous cases. Routing the ambiguous examples back into the annotation queue created a feedback loop that improved both label quality and subsequent prompt performance.
Taking these practices together, you can use LLMs to compress weeks of data-cleaning busywork into a few review cycles while preserving trust through tests, contracts, and human review. As we move to evaluation and validation strategies, we’ll show how to measure the impact of these automated cleaning steps on downstream model performance and drift detection.
Prompt engineering best practices
LLMs produce useful scaffolding, but inconsistent prompts turn productivity gains into debugging chores. Prompt engineering is the discipline that makes interactions repeatable, auditable, and robust—we treat prompts as code: versioned, tested, and instrumented. Start by treating the first 2–4 lines of your prompt as a strict interface: define role, expected format, and failure modes up front so your model returns parsable, predictable outputs. How do you design prompts that are reliable under data drift? Make that interface explicit and machine-checkable from day one.
A strong prompt template balances context density with token cost, and you should front-load the most relevant information. Provide a one-paragraph schema summary, 2–3 representative rows, and a short acceptance test example rather than dumping an entire dataset; this helps the LLM resolve ambiguities without hitting token limits. Use few-shot examples to demonstrate edge cases—show both a correct transformation and a subtle failure mode—to teach the model the boundary conditions you care about. When you need domain precision, combine concise schema with retrieval-augmented generation (RAG) so factual grounding comes from your canonical documents.
Treat prompts like unit-tested modules in your CI pipeline: give each template a clear success criterion and automate checks against it. For generation that must be syntactically valid, assert parsability (JSON schema, YAML linter) and add semantic tests that run small, deterministic data samples through the generated code. Maintain prompt versioning alongside model versions in your registry so you can reproduce an output by pairing the prompt artifact with the exact model and temperature settings. If a prompt change improves throughput but increases hallucination, quantify the tradeoff with holdout evaluations before rolling it into production.
Use explicit grounding and structured output requirements to reduce hallucinations and increase interpretability. Instead of asking for open prose, require outputs in a compact schema—e.g., response must be a JSON array with fields “action”, “confidence”, and “explanation”—and include an example. For tasks needing chain-of-thought reasoning, prefer internal chain-of-thought only with model types that support it; otherwise, ask for concise reasoning steps and a final decision, then validate the steps against rules or RAG-sourced facts. When you need generative creativity (prompted feature ideas or synthetic examples), mark those prompts as exploratory and put the outputs through human review before trusting them in training data.
Operationalize prompt performance: monitor token usage, latency, and content quality as first-class metrics. Cache deterministic responses and memoize expensive prompts that run on static inputs to avoid repeated token costs. Use smaller specialized models for routine syntactic transformations and reserve larger models for semantic normalization or interpretation tasks; this hybrid approach balances cost against error rates. Also implement client-side sanitization and filtering to protect against PII leakage and to enforce input invariants before they reach the model.
Governance requires logging every prompt, model fingerprint, temperature, and output diff so you can trace downstream changes back to prompt edits. Incorporate human-in-the-loop checkpoints for any prompt that alters labels, model inputs, or production artifacts, and set sampling policies to surface a mix of high- and low-confidence outputs for review. Run A/B tests that measure business metrics (label accuracy, time-to-merge, error-rate reduction) rather than only proxy measures; this ties prompt changes to real impact and guards against optimizing for spurious gains.
Taken together, these practices make prompt engineering a reproducible part of your model lifecycle rather than an ad-hoc activity. We should treat prompts as first-class artifacts: concise interfaces, versioned templates, tested expectations, and monitored production metrics. Doing so lets LLMs accelerate exploration and scaffolding while preserving control and traceability—next we’ll examine evaluation and validation strategies that quantify those benefits and catch regressions early.
Code generation and prototyping
Building on this foundation, you can use LLMs to turn whiteboard ideas into runnable artifacts much faster through targeted code generation and rapid prototyping. How do you trust generated scaffolds enough to iterate on them? We start by treating outputs from the model as executable hypotheses: runnable code that must pass unit tests, static analysis, and a small integration smoke test before it graduates from a notebook into your repository. Front-loading this discipline keeps iteration velocity high while containing the usual risks of hallucinated logic or brittle edge cases.
A high-leverage pattern is to ask the model for minimal, opinionated scaffolding rather than a full production system. Request a concise PyTorch or scikit-learn training loop with explicit hooks—model init, dataset loader, optimizer, a single train_epoch and eval_epoch, and a deterministic checkpoint step—and run that skeleton immediately on a tiny sample to validate assumptions. This focused prompt reduces token waste and makes the generated code easier to review and harden. In practice, LLM-assisted code generation gives you a working baseline for architecture exploration, hyperparameter experiments, and quick ablation studies without locking you into a specific implementation.
Make the review-and-iterate cycle explicit in your workflow so generated code behaves like any other change. After you run the scaffold, add unit tests that assert shape contracts, numeric stability (no NaNs), and model serialization round‑trip. Then instrument the scaffold with logging and a reproducible random seed so results are deterministic for small-scale tests; this lets you compare the LLM scaffold to a hand-written reference and detect semantic drift. We version the prompt alongside these tests so you can reproduce the exact generated artifact by pairing the prompt, model version, and test inputs in the experiment registry.
Use concrete patterns to constrain output format and reduce ambiguity. For example, require the model to return a JSON object with keys files, tests, and run_instructions and include a short code example such as:
# minimal train_epoch contract
def train_epoch(model, loader, optimizer):
model.train()
for x, y in loader:
loss = model.step(x, y)
optimizer.zero_grad(); loss.backward(); optimizer.step()
return float(loss.detach())
This kind of template forces the LLM to produce code that is syntactically valid and aligned to your interface, which you then run through linters and static type checks. Requiring that minimal contract in the prompt dramatically reduces follow-up editing and makes it straightforward to integrate generated snippets into existing modules.
Validation and governance must be part of the pipeline, not an afterthought, because generated code can appear plausible but be subtly wrong. Add CI gates that run the provided tests, check for banned operations (e.g., network calls, eval on untrusted data), and compare outputs against a small golden dataset; any divergence should route the artifact to a human reviewer. Track the prompt, model fingerprint, and generated diff as first-class metadata so you can audit who accepted what and rollback quickly if a generated change causes downstream regressions. Treat hallucination as a measurable metric—sample generated logic regularly and score it for factual correctness and safety.
Operationalize cost and latency tradeoffs by delegating tasks by complexity: use small, efficient models for syntactic refactors, template generation, and formatting, and reserve larger, more expensive models for architecture suggestions or semantic transformations that require domain knowledge. Cache deterministic responses, memoize common prompt outputs, and wrap the LLM client with a typed interface that centralizes retries, rate limits, and token accounting so your team doesn’t reinvent orchestration. This hybrid approach accelerates prototyping while keeping inference costs predictable and maintainable.
Taken together, these practices let us convert LLM drafts into production‑grade code faster while preserving control: treat generated code as testable artifacts, enforce minimal contracts, automate CI validation, and log prompt provenance. In the next section we’ll examine how to quantify the correctness and impact of these generated artifacts so you can measure whether rapid iteration actually improves downstream model quality and operational stability.
Integration into ML pipelines
Building on this foundation, integrating an LLM into your ML pipelines is an orchestration problem as much as a modeling one: you need predictable interfaces, observable signals, and CI gates so the model speeds development instead of creating a shadow system. Start by treating the LLM client as a typed service in your MLOps stack—expose a clear API for prompt inputs, expected schema for outputs, and explicit failure modes. How do you make that safe and repeatable across teams? Define the contract up front, version prompts as artifacts, and register the model fingerprint alongside traditional model artifacts in your registry so every generated output is traceable to a specific prompt and model version.
A pragmatic integration pattern is to encapsulate LLM calls behind a service layer that performs sanitization, caching, and retries. This wrapper centralizes rate limiting, token accounting, and input filtering so downstream pipeline steps never reinvent guards, and it exposes deterministic endpoints for batch and real-time workloads in the same ML pipeline. For batch transformations—data cleaning or synthetic example generation—run the LLM step as a scheduled job that writes outputs to a staging table and triggers automated validation. For low-latency tasks like code generation in notebooks or interactive EDA, route requests through the same wrapper but enable aggressive response caching and a shallow model to reduce token cost.
Make generated artifacts testable by design: require the LLM to return a structured payload and wire that payload into your CI validation steps. For example, ask for JSON with keys action, patch, and confidence, then run a deterministic parser and a small unit test suite against the patch before any commit is allowed. In practice we implement a lightweight smoke test that runs transformed rows through schema checks and idempotency assertions, and a second-stage semantic test that samples outputs for human review when confidence is below a threshold. Treat the prompt, returned payload, and test results as one versioned object—this makes rollbacks and audits straightforward when a downstream model behaves unexpectedly.
Don’t assume statistical metrics are sufficient; you need domain-aware acceptance criteria for LLM-derived features and labels. Add semantic checks to the pipeline that validate label distributions, class balance shifts, and feature importance changes immediately after LLM transformations. If the LLM suggests new features, compute correlation and predictive-power baselines on a holdout slice and gate promotion to the feature store based on those results. Use human-in-loop checkpoints for any change that affects labels or target-dependent features: route ambiguous or low-confidence cases to annotators and feed corrected examples back into the prompt-engineering loop to reduce repeated errors.
Observability for generative components requires novel signals in your monitoring stack: track token consumption, per-prompt latency percentiles, and a hallucination sampling rate computed from periodic human audits. Deploy new prompt templates behind canary or shadow modes so you can compare downstream metrics without impacting live predictions, and run A/B experiments that tie prompt variants to business KPIs rather than just proxy metrics. Integrate these signals with your existing tracing and alerting so an increase in hallucination rate, unexpected token costs, or latency spikes triggers the same incident workflows your teams already use for model regressions.
Taking an integration-first approach makes the LLM a reliable building block rather than an exploratory island in your model development pipelines. By wrapping LLM access in a typed service, enforcing structured outputs, automating semantic and syntactic tests, and instrumenting observability for generative signals, we preserve governance while reclaiming development velocity. As we move on, the next concern is how to validate correctness and measure downstream impact so these accelerations translate into measurable improvements in model quality and operational stability.



