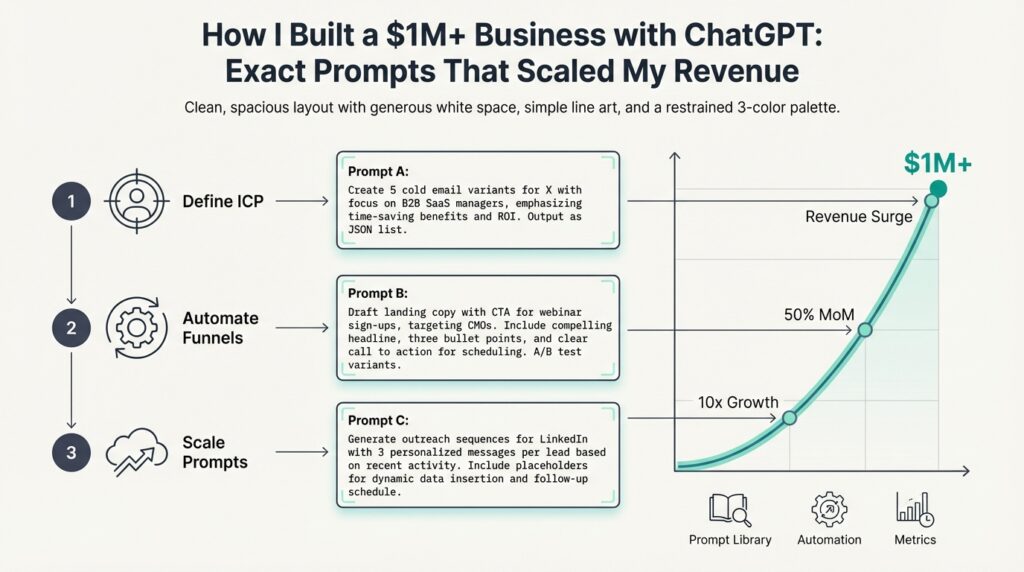
Business model and value proposition
ChatGPT and prompt engineering were the engines we used to convert a technical capability into a predictable commercial engine. In the first product sprint we focused on building AI-driven services that solved a concrete pain: teams needed fast, high-quality content, code scaffolding, and data enrichment without hiring specialized writers or ML engineers. How do you turn reusable prompts into predictable revenue? By treating prompts as productized interfaces to language models, not one-off experiments.
Our core business model combined a subscription SaaS layer with bespoke implementation services and usage-based API access. The subscription tier delivered access to a curated prompt library, versioned templates, and analytics dashboards so customers could standardize outcomes across teams; this created recurring revenue and lowered churn because customers integrated prompts into daily workflows. For higher-value customers we offered managed prompt engineering and integration work—setting up orchestration, authentication, and CI for prompt changes—which commanded professional services fees and brought long-term contracts. This hybrid model balanced predictable recurring revenue with higher-margin services that accelerated enterprise adoption.
We monetized along three levers: seats/tiered SaaS pricing, per-request usage for high-volume API calls, and outcome-based pricing for performance guarantees. For example, a marketing automation customer paid a monthly fee for the prompt library and a per-generated-asset fee for high-volume campaigns; a development team purchased a higher tier that included private prompt namespaces and integration connectors for their CI pipelines. Implementing per-request metering required precise instrumentation—request IDs, prompt fingerprints, and token accounting—so we could reconcile usage, detect prompt drift, and transparency-bill customers accurately.
Unit economics shaped product decisions from day one. Model inference costs and human-in-the-loop review are your two largest operating levers, so we optimized prompt length, used caching for deterministic outputs, and moved heavy context lookups to vector retrieval rather than repeatedly stuffing long documents into prompts. We also A/B tested prompts and tracked lift metrics—conversion-rate delta, time-saved, or content-acceptance rate—to justify price increases. Choosing orchestration and automation over costly fine-tuning often produced better ROI early on; you can iterate prompt chains and retrieval-augmented generation quickly without maintaining custom model checkpoints.
Productization and defensibility came from repeatable artifacts: a canonical prompt library, SDKs for orchestration, a prompt CI workflow, and analytics that surfaced quality regressions. We treated prompts like code—linting, versioning, peer review, and rollback—so customers could adopt governance and compliance standards. Differentiation emerged through proprietary datasets and domain-specific prompt templates that produced consistently better outputs for niche verticals; combined with SLAs and audit logs, that allowed us to sell into regulated industries. Prompt engineering workflows plus clear developer APIs turned an experimental capability into a dependable platform.
Customer acquisition focused on demonstrating measurable outcomes quickly: reduce content production time by X%, increase conversion by Y points, or cut dev onboarding time for scaffolded code. Onboarding emphasized integration—connectors, webhooks, and sample Playbooks—so teams saw value in days, not months, which in turn reduced churn and increased lifetime value. Building on this foundation, we then scaled by documenting exact prompts, automating deployment pipelines for prompt changes, and creating partner channels that embedded our AI-driven services into existing SaaS stacks.
Identifying profitable ChatGPT use-cases and niche
Not every ChatGPT idea translates into a sustainable revenue stream—your challenge is separating delightful demos from repeatable, monetizable workflows. Building on this foundation, we focused on prompt engineering and a curated prompt library as product primitives because they let you measure, iterate, and sell a repeatable interface to language models. Front-load your discovery on value density: how much measurable impact does a single prompt-driven action deliver to a specific buyer? This early focus steers you away from low-margin novelty features and toward propositions customers will pay to operationalize.
Start by defining three investment criteria: frequency, measurability, and defensibility. Frequency asks whether the task happens often enough to generate recurring usage; measurability looks for clear metrics you can instrument—time saved, conversion lift, or defects avoided; defensibility is about whether a prompt plus data or orchestration gives you a reproducible advantage. When a use-case scores high on all three, it’s a candidate for the SaaS tier and inclusion in your prompt library; low-frequency or one-off tasks are better served as professional services or integrations.
Validate demand with lightweight experiments before you build orchestration or APIs. How do you validate demand without building a full product? Run a landing-page test, offer a concierge service for a small fee, or ship a simple email-based workflow and instrument conversion funnels and retention. Use real metrics—percent of users who return, assets generated per user per month, and average time-to-value—to decide whether to productize a prompt as a template, an API, or a managed integration.
Translate validated use-cases into concrete prompt products by capturing intent, constraints, and guardrails explicitly. For example, a marketing automation product becomes a family of templates: brief -> tone -> length -> SEO-constraints -> CTA-variants, plus token budget and post-generation quality checks. You can treat these templates like API contracts: version them, require a minimal schema for inputs, and build server-side validation so that downstream tooling (caching, token accounting, retrieval) can operate deterministically. This pattern allowed us to move fast on content-generation and code-scaffolding while keeping inference costs predictable.
Price according to outcome and usage, not vague access. Unit economics determine whether a use-case scales: model cost per call, human-in-the-loop review fraction, and average tokens consumed map directly to margin. For high-value verticals—enterprise marketing, developer productivity, or sales enablement—we offered outcome-based pricing (per-qualified-lead, per-accepted-asset) layered on top of subscription access to the prompt library. Instrumentation (request IDs, prompt fingerprints, token accounting) lets you reconcile usage, detect prompt drift, and justify higher tiers when customers see measurable lift.
Pick niches where domain data or compliance needs create defensibility. Vertical-specific prompts combined with proprietary datasets or retrieval-augmented generation (RAG) create consistent quality that commodity prompts can’t match. For instance, a legal-contract summarization workflow that enforces jurisdictional clauses and audit logs is easier to sell to law firms or corporate legal teams than a generic summarizer. Similarly, developer onboarding scaffolds that integrate with CI and private prompt namespaces become stickier because they are embedded in team workflows and deployment pipelines.
Ultimately, profitable scaling comes from iterating on a small set of high-value, high-frequency prompts and then building the SaaS plumbing and professional services around them. Focus first on measurable outcomes, instrument everything you can, and productize the templates that show repeatable lift. In the next section we’ll convert those winning templates into deployable prompt CI workflows and analytics that keep quality stable as usage grows.
Exact prompt formulas that convert
Building on this foundation, the quickest way to turn prompts into predictable revenue is to treat each prompt as a product contract rather than an ad-hoc instruction. We call this prompt engineering at the product level: a repeatable, versioned interface that specifies intent, constraints, and measurable outcomes up front. Front-load outputs and success criteria in the prompt so the model knows what “good” looks like, and then enforce those criteria with post-generation checks. What makes a prompt turn a curious user into a paying customer is not clever wording alone but an explicit mapping from input → output → metric that you can instrument and monetize.
A compact, reproducible prompt formula starts with four parts: role and intent, input schema, constraints and quality gates, and the expected output format with examples. For example, represent that as a minimal template:
yaml
system: "You are an expert {persona} writing for {audience}."
prompt: "Input: {brief}
Constraints: tone={tone}, length<={tokens}, include {keywords}
Output: JSON {title, body, CTAs:[...]}"This pattern makes prompts composable, testable, and cacheable; it also lets you compute a prompt fingerprint for metering and drift detection. By treating prompt templates as code artifacts, you can integrate them into CI, roll back changes, and guarantee reproducible outputs for paying customers.
Consider a marketing automation example where conversion is the north star metric: we specify persona, funnel stage, length, SEO constraints, and three CTA variants. A concrete prompt might inject a style guide and an A/B suffix so the model returns two distinct CTAs and a short hypothesis for why each should perform better. Post-process the outputs with lightweight heuristics—keyword presence, CTA readability score, and spam-filter heuristics—then route high-confidence results directly to the campaign and low-confidence ones to a human reviewer. This approach reduced manual review rates in our teams and let us offer outcome-based pricing (per-accepted-asset) because we could prove an acceptance rate and conversion lift.
For developer productivity products, make the prompt guarantee compile-ability and tests rather than vague correctness. Ask the model to generate scaffolded code, a minimal test harness, and a one-line run command; include explicit constraints like target runtime, library versions, and security lint checks. We used a chained prompt where retrieval provided project files and the system prompt asserted a strict schema for responses; the orchestration layer validated the returned JSON and ran the tests in a sandbox before marking the artifact billable. This pattern of prompt templates plus automated verification creates defensibility: customers pay for predictable, deployable outputs integrated into their CI/CD pipelines.
Measurement is non-negotiable: instrument every prompt call with request IDs, prompt fingerprints, token accounting, and outcome tags so you can compute conversion rate, time-saved, and cost-per-accepted-output. How do you decide when to A/B test a template versus iterate on its constraints? Use a triage rule: if initial lift ≥ your minimum detectable effect and frequency is high, run parallel tests with small input slices; otherwise, treat it as a professional-service prototype and harden the template before scaling. Track lift per prompt template and fold that telemetry into pricing decisions—higher lift and frequency justify higher tiers or outcome-based fees.
Operationalizing these formulas requires governance: version prompts, enforce schema validation, roll out changes with canary testing, and surface regressions in an analytics dashboard. We treat prompts like libraries in a private prompt library and gate public changes through PRs, linting, and release notes so customers can rely on SLAs. Taking this concept further, the next step is to convert winning templates into prompt CI workflows and analytics—automated tests, rollout strategies, and quality alerts that keep conversion rates stable as usage scales.
Integrations, automation, and scalable workflows
Integrations, automation, and scalable workflows are the plumbing that turns a set of profitable prompt templates into a dependable product customers can embed in daily operations. If your prompts live in isolation, they remain delightful demos; when you connect them via secure connectors, webhooks, and SDKs, they become part of end-to-end automation that delivers measurable outcomes. How do you stitch prompt engineering into existing systems without breaking auth, billing, or observability? Start by treating integrations as first-class product features: authentication, retry semantics, and contract tests matter as much as the prompt text itself.
Building on this foundation, we design orchestration—the runtime that sequences actions, enforces retries, and applies policy—as the single source of truth for automation. Orchestration here means the coordinator that runs retrieval-augmented generation (RAG) lookups, calls the LLM, applies business logic, and pushes results downstream; it must be idempotent, auditable, and testable. You automate when the task is high-frequency and low-ambiguity (scoring content, scaffolding code, enrichment) and keep a human-in-the-loop for low-frequency, high-risk decisions (legal clauses, compliance sign-offs). These rules decide whether a workflow becomes part of the SaaS tier or remains a professional-services integration.
A practical, production-ready architecture starts with secure connectors and a lightweight job queue. The connector validates incoming webhooks (HMAC), normalizes payloads, and enqueues a job that the orchestration layer consumes. The orchestrator then runs a retrieval step against your vector store, composes a versioned prompt template, fingerprints the prompt for metering, and calls the model. For example, your pipeline can look like this in pseudo-steps: validate -> enrich(retrieval) -> call-model(template:v2) -> validate-schema -> route(result). Implement schema validation server-side so you can run CI on prompt changes and block incompatible updates before customer impact.
Automated quality gates are essential to scale without ballooning human review costs. We used prompt CI: automated tests that run against a corpus of representative inputs, check output schema, assert unit tests (compile, run, pass), and score heuristics like keyword coverage or CTA readability. Route outputs that fail these checks to reviewers and accept high-confidence results automatically. Instrumentation—request IDs, prompt fingerprints, token accounting, and outcome tags—lets you compute acceptance rates and detect prompt drift; those metrics drive rollout decisions and pricing tiers because they map directly to customer value.
Scaling workflows requires thinking about cost and latency as first-order constraints. Cache deterministic outputs for identical fingerprints to avoid repeated inference for the same inputs, batch model calls where latency permits, and shard retrievals for large vector stores. Apply rate limits and backpressure at the connector to protect downstream services and use autoscaling for worker pools to handle spikes. For developer-facing workflows (scaffold generation, test harnesses) we batch small tasks into single model requests and push heavy context to retrieval instead of stuffing long codebases into prompts—this reduces tokens per call and makes margins predictable.
Operationalizing integrations and automation means shipping governance and runbooks alongside features. Version prompts, enforce schema and contract tests, deploy with canary rollouts, and surface regressions in an analytics dashboard that ties output quality to business metrics. Provide client SDKs and webhook hooks so customers can embed your workflows in CI/CD and monitor SLIs themselves. Taking these steps turns prompt templates into stable, auditable services that scale: next we convert winning templates into prompt CI workflows, automated tests, and quality alerts that keep conversion rates steady as usage grows.
Customer acquisition and funnel strategies
Acquiring paying customers for a prompt-driven SaaS starts with measurable value claims and tightly instrumented funnels. We front-load promises you can prove: reduce content time by X%, lift conversion by Y points, or generate deployable code scaffolds that compile on first run. When you present those outcomes in landing pages, demos, and sales scripts, you shorten evaluation cycles and lower CAC because prospects can map benefits to their KPIs. Early messaging should explicitly state the metric you’ll improve and the timeframe for seeing it—this converts curious demos into qualified trials.
Start the top of funnel with lightweight experiments that prove intent and willingness to pay. Run targeted landing pages offering a concrete lead magnet—an automated audit, a three-asset marketing pack, or a code-scaffold preview generated by a prompt template—and measure conversion rate, trial signups, and cost-per-lead. How do you prioritize channels when budget is tight? We prioritize channels by expected signal-to-cost: developer communities for low-cost, high-intent signups; paid search for immediate demand capture; and content/SEO for long-term inbound growth. Use short A/B tests on headlines, hero CTAs, and one-prompt demos to find the highest-leverage levers before scaling spend.
Convert prospects into activated users by making time-to-value measurable and short. Your onboarding must be a productized playbook: connect one repo, run a single prompt that scaffolds a working artifact, and present a dashboard showing acceptance metrics. For example, a prompt template that generates a personalized onboarding checklist might look like system: "You are an onboarding assistant"; prompt: "Given repo X, produce a 5-step plan with commands and expected outputs." Route the generated artifact through automated schema checks and a sandbox run so you can claim “works in 5 minutes” with telemetry to back it up. Activation metrics—first-run success rate, time-to-first-accepted-output, and retention after seven days—become the gating metrics for moving users into paid tiers.
Close and monetize with outcome-based offers and friction-minimized pilots. We layered subscription access to the prompt library with per-accepted-asset billing for high-volume customers, and offered short, results-focused pilots that guaranteed a target lift. For instance, a marketing pilot promised N accepted assets and M% lift in click-throughs over 30 days, with pricing tied to the acceptance rate we instrumented via prompt fingerprints and token accounting. Use canary rollouts for prompt template changes and expose acceptance-rate dashboards to pilot customers so they see the cause-and-effect between prompt iterations and business outcomes.
Scale acquisition by aligning channel strategy with product architecture and partner motion. Product-led channels work when onboarding flows are self-serve and the prompt library has clear templates; sales-led channels require outcome decks, SLA language, and professional services to integrate prompts into CI/CD. We expanded reach through integration partners—marketing automation platforms and developer toolchains—by shipping SDKs, webhooks, and contract tests so partners could embed our prompts as native features. That partner distribution both lowers enterprise CAC and creates stickiness because prompts live inside customers’ existing workflows.
Measure, iterate, and let metrics dictate whether a use-case becomes a product or a service. As we discussed earlier, frequency, measurability, and defensibility should determine investment; apply that same triage to funnel experiments. A simple rule: if a template shows repeatable lift and high frequency, A/B test and productize it; otherwise, treat it as a paid professional service and iterate the template in a concierge setting. Taking these acquisition rhythms further, we convert winning templates into CI-backed prompt releases, analytics dashboards, and automated quality gates so acquisition becomes a scalable, repeatable engine rather than a series of ad-hoc demos.
Metrics, experiments, and revenue scaling
If you want predictable growth from prompt-driven products, you must make metrics the operational lingua franca of prompt engineering and revenue scaling from day one. Start with a sharp north-star metric that maps to customer value—accepted assets per user, conversion lift, or time-saved per seat—and instrument everything so that metric is continuously measurable. Front-load analytics into your templates and orchestration so each prompt call emits request IDs, prompt fingerprints, token accounting, and an outcome tag that ties model outputs back to business results.
Building on this foundation, instrumented telemetry should be designed for causal experiments, not just dashboards. Capture both upstream signals (input characteristics, repo size, user tier) and downstream outcomes (acceptance rate, downstream conversion, time-to-deploy) so you can compute true lift per template. Implement lightweight event schemas and immutable prompt fingerprints so you can recompute historical metrics after template changes. With this data you can calculate cost-per-accepted-output and identify which templates produce sustainable unit economics before you double down on scaling.
How do you decide when to run an A/B test versus iterate on constraints? Use a triage rule: if a template has high frequency and initial lift exceeds your minimum detectable effect, run a parallel A/B test; if frequency is low or behavior is brittle, treat it as a concierge experiment and harden the template first. When you A/B test, randomize at the request or user level, keep input slices consistent, and log intent tags so results are attributable. Run short, focused tests that measure both acceptance rate and downstream business KPIs—an A/B that improves acceptance but hurts conversion is a false positive.
Translate measured lift into revenue scaling levers deliberately. We priced high-frequency, high-lift templates with a hybrid model: subscription access to the prompt library plus per-accepted-asset fees for high-volume customers, and outcome-based pilots for enterprise deals. Use measured metrics to justify tiering: if Template A yields a 12% conversion lift and processes 10k assets/month, you can structure a per-accepted-asset surcharge that keeps margin after model and human-review costs. Simultaneously optimize unit costs—cache deterministic outputs, batch calls, and push heavy context to vector retrieval—so your margin expansion scales with usage rather than evaporating under token costs.
Operationalize experiments with prompt CI, canary rollouts, and automated quality gates so scaling doesn’t mean chaos. Treat prompt changes like code: require PRs, run a suite of representative inputs, validate JSON schemas, compile/run generated tests where applicable, and assert heuristics (keyword coverage, CTA readability, security lint). Surface regressions in an analytics dashboard that ties prompt versions to acceptance trends and model-cost anomalies, and alert on prompt drift when acceptance rate or cost-per-accepted-output moves beyond guardrails. These controls let you expand usage and raise prices without increasing customer risk.
Metrics-driven experiments create a repeatable product roadmap: iterate templates in a concierge setting, validate lift with instrumentation, A/B test winners, then productize with pricing and orchestration. As you scale revenue, let telemetry dictate investment—prioritize templates with high frequency and defensive data, automate everything that is high-volume and low-risk, and keep humans in the loop for edge cases. Taking these steps turns isolated prompt wins into predictable revenue engines and sets up the next phase: converting winning templates into prompt CI workflows and automated quality alerts that keep conversion rates stable as usage grows.