Prepare MovieLens and Metadata
Building on this foundation, the first practical step is getting the MovieLens ratings and movie metadata ready for work. If you have ever opened a dataset and seen rows of numbers, half-finished titles, and missing fields, you already know the feeling: the raw material is there, but it is not yet a clean ingredient list for a movie recommender system. How do you turn MovieLens into something a semantic search pipeline and hybrid ranking model can actually use? We start by separating the signals that matter most: user ratings, movie identities, and descriptive metadata.
The ratings file is the backbone of the whole setup because it tells us what people liked, what they ignored, and what they rated strongly. MovieLens usually gives us a simple pattern: a user ID, a movie ID, a rating, and a timestamp. That may look plain at first, but it is the equivalent of a diary of viewing behavior, and every line helps us understand taste. Before we do anything fancy, we make sure the IDs are consistent, the rating scale is understood, and duplicate or malformed rows are removed so the recommender system is not learning from noise.
Once the ratings are stable, we bring in the movie metadata, which is the descriptive layer that makes semantic search possible. Metadata is the information about the movie rather than the rating itself, such as title, genres, release year, and sometimes plot summaries or tags. Think of ratings as saying, “people reacted this way,” while metadata says, “this is what the movie is about.” In a hybrid ranking setup, both matter: ratings help us learn preference patterns, and metadata helps us understand meaning, similarity, and context.
Now we connect the two worlds. The movie IDs in the ratings table must line up with the movie IDs in the metadata table, or the system ends up like a library with mismatched catalog cards. This is the point where we check joins carefully, confirm that every movie in the ratings file has a matching record in the metadata, and decide what to do with items that do not. Some movies will have rich descriptions, while others may only have a title and a genre list, so we need a strategy for filling gaps without pretending missing data is real data.
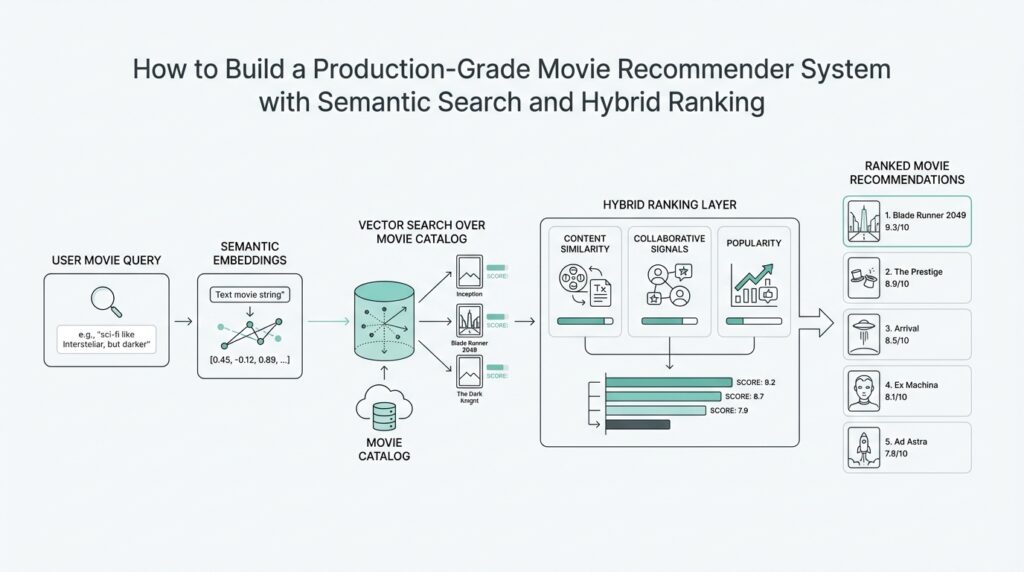
With the join in place, we can start shaping the text that will later feed semantic search. A movie title on its own is usually too thin, so we often combine title, genres, and any available plot or tag information into a single text field. That text becomes the movie’s searchable fingerprint, the kind of description a language model or embedding model can turn into vectors, which are numerical representations of meaning. In plain language, we are teaching the system to recognize that a sci-fi thriller and a space adventure may be close in spirit even if their titles look nothing alike.
At the same time, we keep the ratings data in a format that supports ranking experiments later. That means preserving the user–movie interactions, filtering out extremely sparse users or movies when needed, and making sure timestamps are in a usable format if we want time-aware features. This careful preparation is what lets the MovieLens dataset support both retrieval and ranking: retrieval through metadata-driven semantic search, and ranking through learned preference signals from user behavior.
By the time we finish this stage, the dataset is no longer a messy collection of files. It has become two cooperating views of the same movie universe: one that describes what each film is, and one that records how people responded to it. That is the quiet but essential setup work behind a production-grade movie recommender system, and it gives us a reliable base for the next step, where we start turning clean data into useful recommendations.
Generate Semantic Movie Embeddings
Building on this foundation, we now turn the movie text into semantic movie embeddings, which are the compact numeric representations that let a recommender system understand meaning instead of memorizing exact words. This is where semantic search starts to feel real: a viewer who likes a clever space thriller should not be forced to type the exact title of a similar film before the system can help. The embedding step gives us a way to place movies with related themes, moods, or story shapes close together, which later helps both retrieval and hybrid ranking.
How do you turn a description into something a machine can compare? We feed the text we prepared earlier into an embedding model, which is a model that converts language into a vector, meaning a list of numbers that captures semantic meaning. Think of it like compressing a movie’s personality into a coordinate on a very large map. Two films do not need matching titles to land near each other; if they share atmosphere, genre clues, or narrative patterns, their vectors should end up close together in that map.
The quality of these semantic movie embeddings depends a lot on the text we give them. If the text only says a title and one genre, the model has very little to work with, so the vector may be too vague to separate similar films cleanly. If the text includes title, genres, tags, and a short plot summary, the embedding has richer context and can better distinguish between a light-hearted comedy, a dark psychological drama, and a fast-paced action movie. That is why the text field we built earlier matters so much: it is not just input, it is the raw material that shapes the entire semantic layer.
Taking this concept further, we usually generate embeddings in batches rather than one movie at a time. Batch processing means sending many movie descriptions through the model together, which is faster and easier to manage when you have thousands of records. As we create those vectors, we also keep the movie ID attached to each one so the embedding always points back to the correct film. Without that link, the vector space would be like a library shelf with no call numbers: full of useful material, but hard to navigate.
Once the embeddings exist, we want them stored in a form that supports fast similarity search. In practice, that usually means saving them in a vector store or an indexed table that can quickly find the nearest neighbors of a query. Nearest neighbors are the items closest to a given point in vector space, and that idea is the heart of semantic search for movies. If a user searches for a story about time travel and grief, the system can compare that query embedding against the movie embeddings and surface films with similar emotional and narrative patterns, even if the wording is different.
This is also where the first hints of hybrid ranking appear. On one hand, embeddings help us retrieve candidates by meaning; on the other hand, ratings and behavior data help us judge which candidates are likely to be useful for a particular user. That separation is powerful because semantic search is excellent at finding plausible matches, while interaction data is better at deciding which match should rise to the top. In other words, the embedding layer opens the door, and the ranking layer decides who gets the spotlight.
Before we move on, we also need to think about consistency. If we use one embedding model during preparation and a different one later for live queries, the map can shift under our feet, so the vectors no longer line up cleanly. That is why production-grade systems keep the embedding model versioned, the text format stable, and the update process deliberate. Once that discipline is in place, semantic movie embeddings become a reliable bridge between raw movie descriptions and the recommendation logic that comes next.
Build the Vector Search Index
Building on this foundation, we are ready to turn those movie embeddings into a vector search index, the part of the system that makes semantic search fast enough to use in a real product. Until now, we have been creating a map of movie meaning; now we need a way to walk that map quickly when a user asks for recommendations. How do you find the nearest movies without comparing a query against every single film one by one? That is the job of the vector search index in a movie recommender system.
The first thing to understand is why an index matters at all. If we searched every embedding in plain order, the system would still work, but it would feel like reading every shelf in a library whenever someone asks for one book. A vector index organizes the embeddings so the computer can jump to likely matches much faster, which is essential when the catalog grows beyond a toy dataset. In practice, this means taking each movie vector, pairing it with the correct movie ID and metadata, and loading it into a structure built for similarity search.
Before we build that structure, we need to choose how similarity should be measured. Most movie recommenders use a distance or similarity metric, which is a rule for deciding how close two vectors are; cosine similarity, for example, checks whether two vectors point in a similar direction. That choice matters because it shapes what “related” means in semantic search. If you normalize the vectors first, the index can compare them more consistently, and that consistency becomes especially important when you later mix semantic search with ranking signals from user behavior.
Taking this concept further, the index itself is usually built with approximate nearest neighbor search, a method that finds very close matches without checking every possible item exactly. The word approximate may sound worrying, but it is a practical tradeoff: you give up a tiny bit of precision so the system can answer much faster. For a production-grade movie recommender system, that tradeoff is often worth it because the user experiences speed as quality. The goal is not to prove which movie is mathematically closest; the goal is to surface a strong candidate list before the ranking layer takes over.
As we discussed earlier, the movie embeddings only stay useful if they remain tied to the right records, so the index must store more than numbers alone. Each vector should point back to the movie ID, and the index should carry enough metadata to support filtering later, such as genre, release year, or content type. This is where the vector search index starts to feel less like a raw database and more like a smart map with labels. If a user wants family-friendly sci-fi movies, we can retrieve similar films first and then filter or rerank them using that extra context.
Here is where things get interesting: building the index is not a one-time event. In a real system, new movies may arrive, metadata may improve, and embeddings may need to be regenerated when the text model changes. That means we need an update strategy, whether we rebuild in batches, upsert new vectors incrementally, or version the index so old and new embeddings do not get mixed by accident. If we skip that discipline, semantic search can drift, and the movie recommender system starts returning results that feel strangely inconsistent.
When the index is ready, we test it the way a reader would test a map: by asking a few natural queries and checking whether the nearest neighbors make sense. A search for “quiet coming-of-age dramas” should return films that feel emotionally close, not just titles with matching words. That validation step tells us whether the embedding model, the index settings, and the metadata all work together cleanly. Once the vector search index is behaving well, we have the retrieval layer we need, and we can move toward the next stage where those candidates are ranked against real user preferences.
Combine Sparse and Dense Signals
Building on this foundation, we now have two very different kinds of clues sitting on the table: sparse signals and dense signals. How do you combine sparse and dense signals without letting one drown out the other? Sparse signals are the crisp, exact clues from behavior and identifiers, while dense signals are the smoother, meaning-based clues from embeddings. In recommender systems, that pairing matters because sparse feature interactions are strong at memorization, while dense embeddings are strong at generalization; the Wide & Deep paper makes that tradeoff explicit and shows why combining the two helps.
Think of the sparse side as the part of the movie recommender system that remembers specific facts: this user liked this franchise, this title was rated highly, this genre shows up again and again. Those signals are often one-hot or ID-based, which means they are sparse because most entries are empty and only a few matter for any given user. That sounds limited, but it is exactly what makes them powerful for memorization and exact preference patterns. The dense side works differently. It turns the movie text we prepared earlier into vectors, so a film about lonely space travel can sit near another film with a similar mood even when the titles share no words at all.
Once both sides exist, the next step is to let them talk to each other instead of forcing one to win. In practice, hybrid search combines lexical precision with vector similarity, which is a useful model for hybrid ranking in a movie recommender system: the sparse branch says, “this matches something the user has shown interest in,” while the dense branch says, “this feels semantically right.” Elastic’s hybrid-search guidance describes this as combining BM25-style lexical scoring with dense-vector retrieval, then merging the results with rank fusion or a ranking API. That is the basic rhythm we want here too: retrieve from both signals, then blend them into one candidate list.
A practical way to think about the merge is that sparse and dense signals speak different scoring languages, so we should compare their ranks, not pretend their raw numbers mean the same thing. This is where a hybrid ranking pipeline becomes valuable. We can pull a sparse candidate set from interaction history or metadata matches, pull a dense candidate set from semantic search over movie embeddings, and then fuse those lists so strong items from either side can survive. Elastic documents reciprocal rank fusion as one way to combine results, and that same idea fits neatly here because it rewards items that appear near the top of more than one retrieval path.
The real win is balance. Sparse signals keep the system grounded in proven taste, while dense signals help it recover when the user’s history is thin, noisy, or hard to interpret. That balance is especially important in a production-grade movie recommender system, because real users do not behave like neat training examples; they search with vague phrases, drift across moods, and surprise us with one-off interests. By combining sparse and dense signals, we get a retrieval layer that is both precise and flexible, which sets us up for the final reranking stage where we can use more context, more features, and a sharper notion of relevance.
Add Learning-to-Rank Reordering
Building on this foundation, we now have a shortlist of movies that already feel promising, but a shortlist is not the same as a final answer. How do you teach a movie recommender system which of ten good candidates should appear first? That is where learning-to-rank reordering comes in: a ranking model looks at the candidates produced by semantic search and hybrid retrieval, then learns how to arrange them in the most useful order for a specific user.
At this stage, we stop thinking like a search engine and start thinking like a movie critic with a very good memory. The retrieval layer says, “these films are relevant enough to consider,” while the reranker says, “this one should probably come first because it fits the user better.” That distinction matters because many movies can look similar at the retrieval stage, yet only a few deserve the top spots. Learning-to-rank gives us a structured way to make that final judgment instead of relying on a hand-tuned score blend.
To build that ranking model, we first need features, which are the clues it uses to make decisions. Some features come from the user, such as past ratings, favorite genres, or how often they watch a certain type of film. Others come from the movie itself, such as embedding similarity, genre overlap, release year, popularity, or whether the title matches the user’s recent viewing pattern. Think of it like assembling the notes a human reviewer would glance at before making a recommendation.
Now we need training labels, which tell the model what “better” looks like. In a movie recommender system, those labels usually come from historical behavior: clicks, watches, saves, strong ratings, or long viewing time. A movie the user clicked and finished is a stronger positive signal than one they ignored, and a highly rated movie is stronger still. This is where the learning-to-rank setup becomes powerful, because it learns from real preference patterns instead of guessing from text similarity alone.
There are a few ways to train this kind of ranking model, and the names sound more intimidating than the ideas really are. A pointwise approach treats each movie almost like a separate yes-or-no prediction, while a pairwise approach learns which of two movies should rank higher, and a listwise approach looks at the whole candidate list together. For a production-grade movie recommender system, the listwise or pairwise style often feels more natural, because the model is not deciding whether a movie is “good” in isolation; it is deciding where it belongs relative to the other options in front of it.
Once the model is trained, it becomes the final sorting layer after hybrid retrieval. The semantic search and sparse signals do the broad matching, and the reranker adds precision by using richer context. This is especially helpful when two movies have similar embedding scores but very different chances of satisfying the user. One may be a better fit because it matches a preferred director, a recent watch pattern, or a strong historical rating from people with similar tastes.
When we test this stage, we want to know more than whether the model is “accurate” in a general sense. We care about whether it places the right movie near the top, because that is what users actually see first. Metrics such as normalized discounted cumulative gain, or NDCG, measure how well a ranking puts the most relevant items near the top of the list, which is exactly the behavior we want. If the model improves the first few positions without hurting the rest of the list, then the reranking layer is doing its job.
The real value of learning-to-rank reordering is that it turns a decent candidate list into a polished recommendation experience. Instead of asking the user to sift through similar-looking results, we let the model do the careful comparison for them. That final pass is where the movie recommender system starts to feel intelligent rather than merely organized, and it prepares us for the next step where ranking quality becomes something we can measure, tune, and trust in production.
Deploy, Test, and Monitor
Building on this foundation, we now have a full recommender pipeline on paper, and the real question is whether it can survive contact with users. How do you know a production-grade movie recommender system is ready when the semantic search layer, hybrid ranking logic, and learning-to-rank model are all working together? The answer is to deploy carefully, test in layers, and monitor the system as if it were a living product rather than a finished artifact. That shift matters because the moment real traffic arrives, small issues in latency, freshness, or ranking quality can become very visible.
Deployment is the first handoff from the lab to the real world. In practice, we package the embedding service, the vector search index, and the ranking model so each piece can run reliably in the same environment every day. Think of it like moving from a recipe card to a kitchen line: every station has to know its job, and the handoffs need to be predictable. Versioning the model, the embeddings, and the index separately is especially important here, because it lets you update one part of the movie recommender system without accidentally breaking the others.
Once the system is deployed, testing becomes our safety net. We start with small checks that prove each part still behaves the way we expect, then we move to end-to-end tests that follow a request from search to retrieval to reranking. A good test might ask for “smart, character-driven sci-fi” and confirm that semantic search returns sensible candidates, the hybrid ranking layer blends sparse and dense signals correctly, and the final list still makes sense for a real user profile. This is where edge cases matter too, because empty histories, rare genres, and short metadata records are exactly the situations that can expose weak spots.
It also helps to test for speed, not only correctness. A recommender can return excellent results and still disappoint users if it takes too long to answer, so we watch response time, throughput, and memory usage alongside relevance scores. That is especially true for a production-grade movie recommender system, where the vector search index and reranker must work within a tight budget. If one stage slows down, the whole experience feels sluggish, even when the recommendations themselves are strong.
Before we trust the new setup with everyone, we usually run a smaller real-world experiment. This might be a canary release, which means sending a small slice of traffic to the new system first, or an A/B test, which compares two versions side by side. These experiments answer a practical question: does the new hybrid ranking pipeline improve behavior that matters, such as clicks, watch starts, or long viewing sessions? Offline metrics are useful, but online behavior tells us whether people actually like what they see.
Monitoring is what keeps the system healthy after launch. We watch service metrics like latency and error rate, but we also watch model metrics that reveal whether the recommender is drifting away from useful behavior. For example, if the distribution of recommended genres suddenly narrows, or if recent releases almost never appear, that may signal a problem in the vector index, the metadata pipeline, or the ranking features. This kind of observability gives us early warning before users start feeling that the movie recommender system has gone stale.
That same idea applies to data freshness. Embeddings, metadata, and interaction signals all age over time, and a model that once felt sharp can slowly lose its edge if it stops seeing new titles or new taste patterns. So we monitor index updates, retraining schedules, and feature drift, which means the input data has changed in ways that may affect performance. When those signals stay healthy, the semantic search layer and hybrid ranking layer keep working together like a well-tuned team, and the recommender stays trustworthy instead of slowly drifting out of sync with what people want.