Understanding Error-Driven Learning in AI Systems
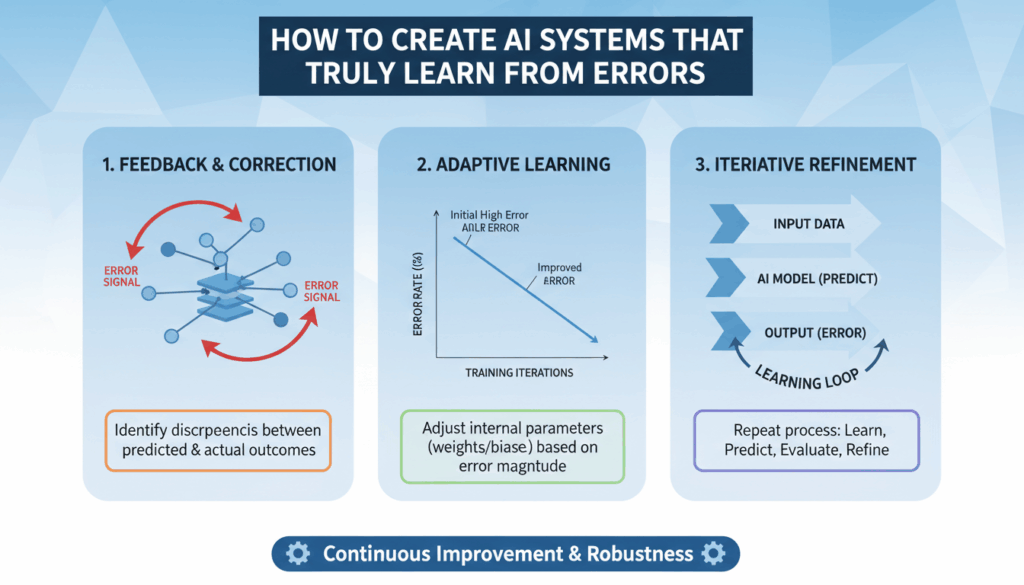
Error-driven learning in AI systems represents a crucial framework for enhancing their performance by using errors as a source of information to refine and improve models. This process begins with an understanding of what constitutes an “error” in the context of machine learning: typically, these are discrepancies between the predicted output of an AI model and the actual results.
In more technical terms, error-driven learning involves iterative model adjustments based on the errors observed during training or operation. The goal is to minimize the error rate by fine-tuning the model’s parameters. Here’s how it works:
Error Identification
The first step in any error-driven learning process is to accurately identify errors. This typically involves evaluating the model’s predictions against a test dataset where the correct outcomes are known. For example, in a supervised learning scenario, each incorrect prediction signals an error. These errors are quantified using a loss function that measures the disparity between predicted and true values.
Error Backpropagation
Once errors are identified, the backpropagation technique is often employed to adjust the network weights. This process involves propagating the error backwards through the network layers to inform weight adjustments. By using derivatives of the loss function concerning each weight, the model learns how changes in weights influence the output error, thus guiding how to tune the weights to minimize errors in future predictions.
Adaptive Learning Rate
An essential component underlining error-driven learning is the adaptive learning rate, which adjusts the extent to which weights are modified in response to detected errors. Too large of a step can overshoot the optimal value, while too small of a step can slow learning. Techniques such as Adam or RMSprop provide strategies for adapting learning rates based on past gradient information.
Real-World Examples
A classic real-world example of error-driven learning is its application in self-driving cars. These systems constantly process sensory data to make driving decisions. When an AI system in a test scenario fails to detect an obstacle, this error is used to adjust the model’s parameters, helping the car distinguish obstacles better in future scenarios. Over time, the system learns through these errors how to navigate varied environments more reliably.
Continuous Feedback Loop
Error-driven learning operates on a continuous feedback loop wherein the system constantly receives data, makes predictions, evaluates success, and refines its approach. This ongoing cycle helps the AI system to adapt to new, unforeseen circumstances and learn dynamically from real-world interactions.
By comprehensively understanding and implementing error-driven learning, AI developers can create systems that not merely react to static data but continuously evolve through interaction with dynamic environments. This capability is especially pivotal in areas requiring high adaptability and precision, such as medical diagnostics or financial modeling.
Implementing Feedback Loops for Continuous Improvement
Implementing feedback loops in AI systems is crucial for fostering continuous improvement, which relies on a structured approach to evolve from detecting errors to making actionable adjustments based on those errors.
A feedback loop involves a cycle where outputs are used as inputs, allowing systems to self-optimize over time. To successfully instill this loop in AI, several components must be fine-tuned:
Data Collection and Management
The foundation of an effective feedback loop begins with data. Continuously collecting data from various sources is essential to provide AI systems with the information needed to learn and adapt. This data needs to be diverse, up-to-date, and accurately labeled to reflect the real-world scenarios the AI will face. Techniques such as streaming data processing allow AI systems to operate on fresh data, maintaining their relevance.
Error Analysis and Diagnostics
Once the data is collected, it must be used to assess system performance. This involves sophisticated diagnostic tools that leverage analytical methods to identify patterns of error recurrence and root causes. For instance, implementing error heatmaps or confusion matrices can highlight recurring mistakes, enabling developers to pinpoint which areas require attention. Regular diagnostics keep the learning process transparent and measurable.
Automated Response Mechanisms
To create a responsive AI, automated mechanisms must be in place to process feedback and adjust systems accordingly. This involves creating algorithms that can interpret feedback intelligently, deciding whether to alter network architectures, retrain parts of the model, or adjust hyperparameters. Tools like AutoML can be instrumental in this aspect by automating the model tuning process based on input feedback.
Human-in-the-Loop Systems
Despite the automation capabilities, humans play a crucial role in supervising feedback loops. They can provide qualitative insights and ethical guidance absent from raw data patterns. By integrating expert feedback at strategic points within the process, AI systems can benefit from human intuition and creativity, enriching the learning process considerably.
Iterative Model Improvement
Feedback loops are inherently iterative. This means that once an AI system processes feedback and makes adjustments, its performance should be reevaluated to measure improvements or new issues. Such iterative refinement ensures models remain in tune with evolving requirements and external conditions. Techniques like cross-validation can help verify the effectiveness of changes before they are fully implemented.
Case Study: E-commerce Recommender Systems
In practical terms, e-commerce platforms implement feedback loops by using customer feedback and purchase history to refine product recommendations. Initially, a system might present generic recommendations. However, as customer interactions are analyzed, the system learns preferences and adjusts future suggestions, optimizing personal shopping experiences and driving better conversion rates.
Feedback Loop Tools and Technologies
With technological advancements, numerous tools facilitate the creation of feedback loops. Platforms like Apache Kafka and TensorFlow Extended (TFX) help manage continuous data streams, while cloud-based solutions enable scalable and robust model management.
Establishing an effective feedback loop is not just about technological prowess but also about the strategic integration of processes and tools that align closely with the system’s goals and the environment it operates in. Whether enhancing machine learning models for accuracy or ensuring adaptability in rapidly changing domains, feedback loops are indispensable for making AI systems smarter over time.
Techniques for Error Detection and Attribution
In the realm of AI systems, detecting errors effectively is essential for refining models and enhancing AI reliability. Various techniques facilitate error detection and attribution, each offering distinct advantages in understanding why an AI system might fail and how these failures can be corrected.
One fundamental approach involves statistical anomaly detection, where models are trained to identify deviations from expected behavior. This is particularly useful in scenarios where historic data defines a norm. For instance, in fraud detection, deviations in transaction patterns can signal potential fraud, prompting further investigation.
Another important method is the use of confusion matrices, which help visualize the performance of classification models. This matrix lays out true positives, true negatives, false positives, and false negatives, providing a quantitative foundation for understanding where errors occur most frequently. By analyzing this matrix, data scientists can pinpoint where a model misclassifies often and adjust training data or model parameters accordingly.
Error attribution, the process of tracing an error back to its root cause, often leverages more advanced techniques. For example, SHAP (SHapley Additive exPlanations) values provide insights into feature importance and can help attribute predictions or errors to specific features, illuminating how individual data elements influence outcomes. This method aligns well with tree-based models, providing visual clarity on feature impact.
Machine learning practitioners also use gradient checking to verify the correctness of model implementations, particularly in neural networks. By ensuring that gradient calculations during backpropagation are accurate, developers can detect issues early, reducing the incidence of incorrect updates that lead to poor model performance.
In complex systems, Bayesian error analysis can offer insights by incorporating prior knowledge and uncertainties into error detection. This probabilistic approach allows for nuanced understanding of errors within contexts where clear-cut mistakes might not be easily identifiable, especially in decision-making processes reliant on ambiguous data inputs.
Techniques like feature attribution and saliency maps are invaluable for understanding deep learning model errors, facilitating error attribution by visualizing which parts of input data most influence model predictions. They enable developers to diagnose whether a model is focusing on irrelevant inputs for decision-making.
Furthermore, AI-equipped with logging and monitoring frameworks is crucial for real-time error detection and attribution. These systems can track performance and alert developers about anomalies instantly. Tools like TensorBoard and Grafana offer user-friendly visualization capabilities, allowing for continuous assessment and immediate response to emerging issues, minimizing downtime and improving system resilience.
By integrating these techniques, AI systems not only become capable of detecting errors with higher accuracy but also provide actionable insights into error causation, establishing a clearer path for subsequent model refinement. The resultant systems are more robust, adaptable, and efficient in addressing complex real-world challenges.
Retraining Strategies to Address Identified Errors
In machine learning, the retraining of models is essential for addressing identified errors and ensuring continuous improvement. Retraining strategies must be systematically developed and executed to effectively incorporate feedback from error analysis, enhancing the model’s performance and precision.
To begin, it’s crucial to conduct a thorough error diagnosis to understand the types and frequencies of errors your model encounters. This investigation may involve generating confusion matrices, employing feature importance analysis, or utilizing model interpretability techniques like SHAP (SHapley Additive exPlanations) to isolate specific problem areas.
Once errors are identified and analyzed, a key strategy is to augment the training dataset with more representative data. This often involves collecting additional data samples that reflect the scenarios where the model failed. For instance, if an AI model used for image classification underperforms with certain lighting conditions, you might capture images with those lighting variations to enrich the dataset.
Another effective approach is bootstrapping, which embraces training on varying subsets of the original data combined with synthetic data generation. Here, techniques like Synthetic Minority Over-sampling Technique (SMOTE) or data augmentation via transformations (e.g., rotations, translations) come into play, creating a more balanced and extensive training set.
The use of transfer learning is invaluable especially in environments constrained by data availability. It involves adapting pre-trained models to new but related tasks. This method not only accelerates the retraining process but enhances the model’s ability to generalize across different contexts. Transfer learning is particularly beneficial in cases with high computational costs associated with training complex models from scratch.
Implementing adaptive learning rate schedules can also significantly refine retraining strategies. By dynamically adjusting learning rates through methods like AdaGrad or Adam during the retraining phase, models can more efficiently converge to optimal solutions, minimizing overfitting or underfitting issues caused by static learning parameters.
Moreover, ensemble methods can be leveraged to tackle diverse error types. Techniques such as bagging and boosting unite multiple model predictions, minimizing error rates and enhancing reliability. Models like Random Forests or Gradient Boosted Trees can be retrained iteratively, gradually improving their accuracy over successive training rounds.
Consider establishing a systematic model evaluation regime post-retraining. Employ cross-validation for reliable performance measurement and model comparison. Techniques such as k-fold cross-validation provide a robust framework for evaluating the model’s ability to generalize from the new training adjustments.
Lastly, integrating a human-in-the-loop approach fortifies retraining strategies. Human expertise can guide the retraining process, especially in scenarios where automated feedback loops might misinterpret nuanced error contexts. Human feedback can refine model parameters or evaluate edge cases that are challenging for AI systems.
In conclusion, retraining strategies should be tailored to address specific errors identified in AI models, leveraging a mix of data-centric and model-centric approaches. Actionable strategies such as data augmentation, adaptive learning parameters, and ensemble techniques ensure AI systems evolve responsively to challenges, augmenting their effectiveness and robustness in dynamic operational environments.
Case Studies: AI Systems Successfully Learning from Mistakes
In the realm of artificial intelligence (AI), learning from mistakes is a pivotal capability that distinguishes truly intelligent systems from basic automation. Several AI systems have demonstrated remarkable success in leveraging errors to evolve and improve, providing insightful case studies across various domains.
One notable example is DeepMind’s AlphaGo, an AI developed to master the ancient board game Go. Unlike traditional strategy games where computational power alone can dominate, Go presents a vast array of possibilities, making brute-force strategies insufficient. AlphaGo’s design incorporated deep reinforcement learning, which enabled the system to learn and strategize by playing games against itself. Analogous to a human player learning from losses to refine tactics, AlphaGo capitalized on its mistakes by analyzing errors in its moves during games. This feedback allowed AlphaGo to improve its gameplay iteratively, leading to it eventually defeating world champion Go players—a feat once thought to be decades away from possibility.
Another compelling case is IBM Watson’s application in the healthcare sector, specifically in oncology treatment recommendations. Initially trained with medical literature, Watson initially faced challenges in accurately interpreting nuanced clinical trials and complex case reports. However, through systematic error analysis and feedback from healthcare professionals, Watson was able to refine its understanding of treatment pathways. Physicians provided critical feedback on retrospective cases where Watson’s suggestions diverged from standard practices, enabling the AI to learn from these discrepancies. Subsequently, Watson’s recommendations aligned more closely with expert analyses, improving its utility as a diagnostic and treatment aid.
In autonomous vehicle technology, Tesla’s Autopilot system exemplifies learning from real-time road experience and mistakes. The system gathers data from onboard sensors and cameras installed in thousands of vehicles, continuously capturing driving conditions and user interactions. When an error occurs—such as incorrect lane positioning or braking errors—the system analyzes these occurrences, feeding the learnings back to neural network models responsible for driving decisions. This continuous updating and retraining mechanism allows Tesla’s AI to refine its behavior, improving safety and reliability over time. Furthermore, this collective learning, aggregated from a vast fleet, significantly accelerates the error correction process compared to isolated trials.
AI applications in e-commerce also showcase the power of learning from errors. Recommendation systems like those implemented by Amazon or Netflix use customer feedback and interaction data to refine their algorithms. Initial suggestions are often broad and less personalized but progressively evolve by incorporating feedback loops that analyze customers’ responses to recommendations. Over time, these systems learn to predict consumer preferences with astonishing accuracy, capitalizing on “errors” or mismatches in prior recommendations to fine-tune and personalize future interactions.
These cases illustrate a common theme: AI systems achieving exceptional improvements by embracing their errors as opportunities to learn. By systematically identifying, analyzing, and rectifying mistakes, AI systems not only enhance their performance but also gain a competitive edge in achieving their operational goals. Each of these systems underscores the need for robust error-driven learning mechanisms in AI, demonstrating that transformative progress frequently stems from effectively harnessing and addressing mistakes.



