Why detecting AI‑generated code matters: security, licensing, and reliability risks
AI-suggested code often looks correct but can embed insecure defaults, logic flaws, or known CVEs that expand the attack surface and evade casual review. (techradar.com)
Hallucinated or fabricated dependencies are a critical supply‑chain vector: models commonly invent package names that attackers can prepublish and weaponize, turning a believable import into a backdoor. (arstechnica.com)
Training on public repositories also creates licensing and IP exposure—large snippets or verbatim code may carry incompatible open‑source licenses or proprietary content, risking legal and compliance fallout. (techtarget.com)
Beyond security and legal concerns, AI outputs suffer reliability problems (incorrect APIs, fragile edge cases, hallucinated logic) that increase debugging cost and reduce maintainability. (arxiv.org)
Detecting AI‑origin code enables provenance checks, targeted security scans, license enforcement, and prioritized human review—reducing exploit risk and long‑term technical debt.
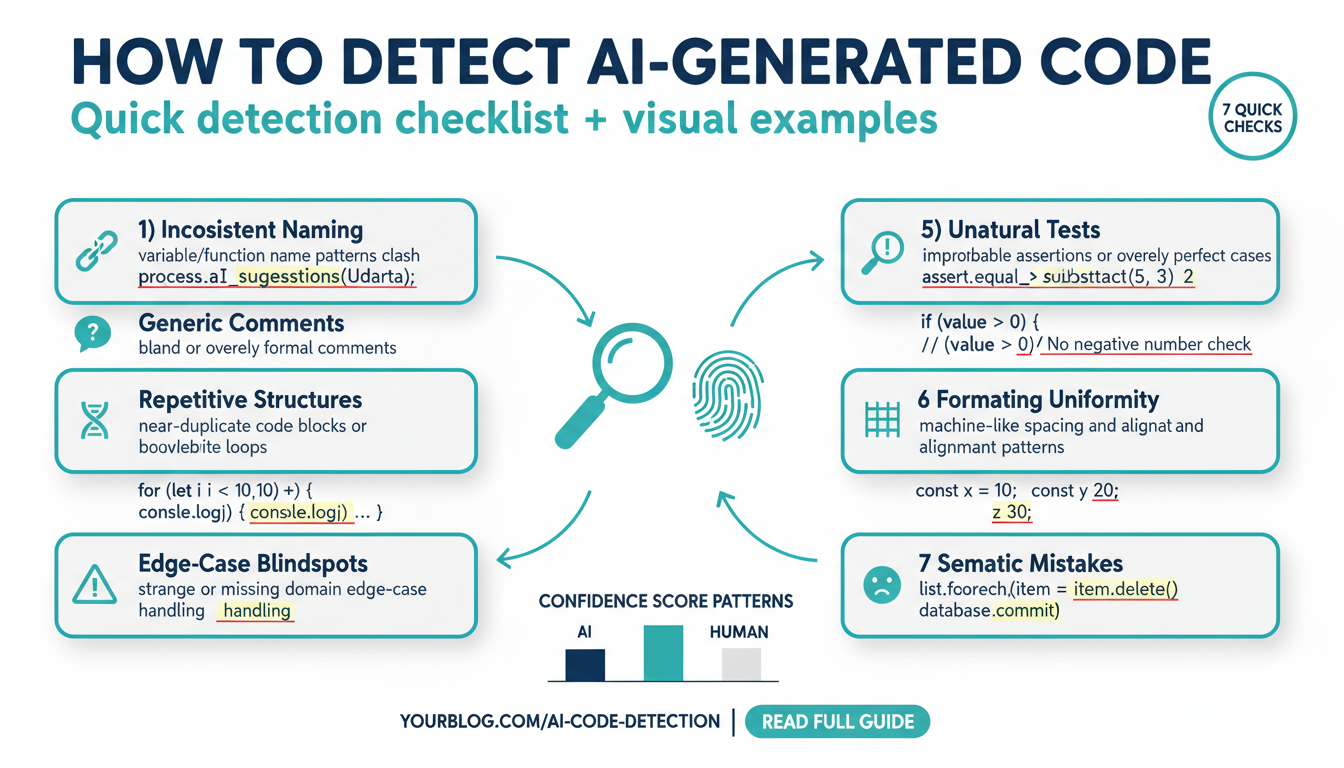
Quick stylistic red flags to spot: naming, comments, repetition, and boilerplate patterns
-
Look for bland or overly consistent identifiers (tmp, temp1, result, FooImpl) or sudden shifts in naming style—models often default to generic names rather than contextual, descriptive ones. (arxiv.org)
-
Inspect comments: absent, tautological, or misplaced comments (e.g., “This sorts the list”) and repeated “TODO”s can signal automated generation or shallow prompting. (texta.ai)
-
Watch for near‑duplicate blocks with tiny edits (copy‑paste clones, repeated error handling, identical helper functions)—AI can replicate patterns instead of abstracting them. (solix.com)
-
Spot boilerplate overreach: full-framework imports for trivial tasks, identical license/README templates, or uniform docstrings across files—these are efficient model outputs but low on project-specific intent. (solix.com)
Quick checks: grep for “tmp|temp|result”, search duplicated code, and run static analyzers to flag inconsistent naming/comments and duplicated logic.
Behavioral tests that reveal AI artifacts: unit tests, edge cases, fuzzing and runtime anomalies
Use behavioral tests that exercise how code actually behaves under realistic and adversarial conditions.
-
Unit assertions: add strict assertions for return types, exact error classes, and side effects (file writes, network calls). Expect concrete API contracts, not “works-ish.”
-
Edge cases: build tests for empty, null, oversized, and boundary values; verify deterministic handling of missing fields and malformed inputs.
-
Property-based tests: fuzz inputs with generators (random strings, extreme numbers, invalid encodings) to expose hallucinated assumptions and fragile parsing.
-
Mutation/fuzz testing: mutate real inputs and assert invariants (no crashes, consistent error messages, no fabricated dependency resolution).
-
Runtime anomaly checks: assert latency, memory growth, exception rates, and nondeterministic outputs across repeated runs; capture stack traces and compare for repetitive template-like code paths.
Quick examples: assertThrows(MyError) for invalid input; snapshot normalized outputs for identical seeds; fail the build on unexpected external resolves or invented package names.
Provenance checks: code search, snippet fingerprinting, commit metadata and license tracing
Combine large-scale code search, fuzzy/AST fingerprinting, commit metadata checks and license scans to prove where a snippet came from.
- Run cross‑repo code search (internal + public) to locate identical or closely matching snippets and pull-request context; prioritize tools that search commits and diffs. (sourcegraph.com)
- Match snippets with clone/fingerprint detectors: token/AST clone tools (SourcererCC-style) for near‑duplicates and fuzzy hashes (ssdeep/CTPH) for edited copies. (arxiv.org)
- Verify author, timestamp and PR metadata with git blame/git log and associated CI/merge records to spot transplanted or orphaned code. (atlassian.com)
- Run license/text detection (ScanCode/SPDX outputs) to surface embedded license texts, copyright notices, and large verbatim blocks needing review. (scancode-toolkit.readthedocs.io)
Fail fast: flag matches above a size or similarity threshold for legal/security triage and human review.
Automated detectors & tools to try: Codequiry, Sonar/ SonarQube features, AI Code Detector and similar services
Treat automated detectors as triage: web‑scale scanners (Codequiry) find matches and AI‑style fingerprints across public repos and LMS submissions using AST/token fingerprints and web indexing, making them popular for academic workflows. (codequiry.com)
Platform static‑analysis suites (SonarQube) add SAST, taint/data‑flow, secrets detection, SCA/SBOM and even AI‑assisted fixes; enterprise editions offer AI‑code autodetection and CI/IDE integration for policy gating. (sonarsource.com)
Dedicated ML detectors (Span’s AI Code Detector and many online “AI code detector” services) classify chunks with probabilistic scores or abstain on low‑signal lines—useful for measuring AI usage but not definitive proof. (span.app)
Practical approach: run detectors in CI, auto‑flag high‑probability chunks, and combine with provenance (repo/commit search), behavioral tests, and manual review—detectors guide investigation, they don’t replace it. (codequiry.com)
Operationalizing detection: CI/CD gates, review checklists, human-in-the-loop verification and handling false positives
Start by gating detection tools in CI as “report-only” on feature branches, then escalate to blocking rules for staging/production (fail builds for high‑confidence security/license flags). (webstacks.com)
Embed automated checks in PRs: provenance (snippet matches, git metadata), SCA/license scans, static/taint analysis, and behavioral test runs (unit + fuzz/property checks) so reviewers see concrete failures, not just probabilistic scores. (speedscale.com)
Use a concise reviewer checklist: source provenance, dependency sanity (no invented packages), strict edge‑case tests, explicit API contracts, and documented rationale for accepting AI‑authored patches. Log reviewer decisions to train thresholds. (webstacks.com)
Human‑in‑the‑loop: triage high‑risk or ambiguous findings, run manual tests or production‑traffic replays for functional parity, and require named sign‑offs for security/licensing exceptions. (arxiv.org)
Manage false positives by tracking noise rate, tuning confidence thresholds/rule packs, and feeding reviewer labels back into detectors; if noise >~25% reduce strictness or route to advisory mode until tuned. (webstacks.com)



