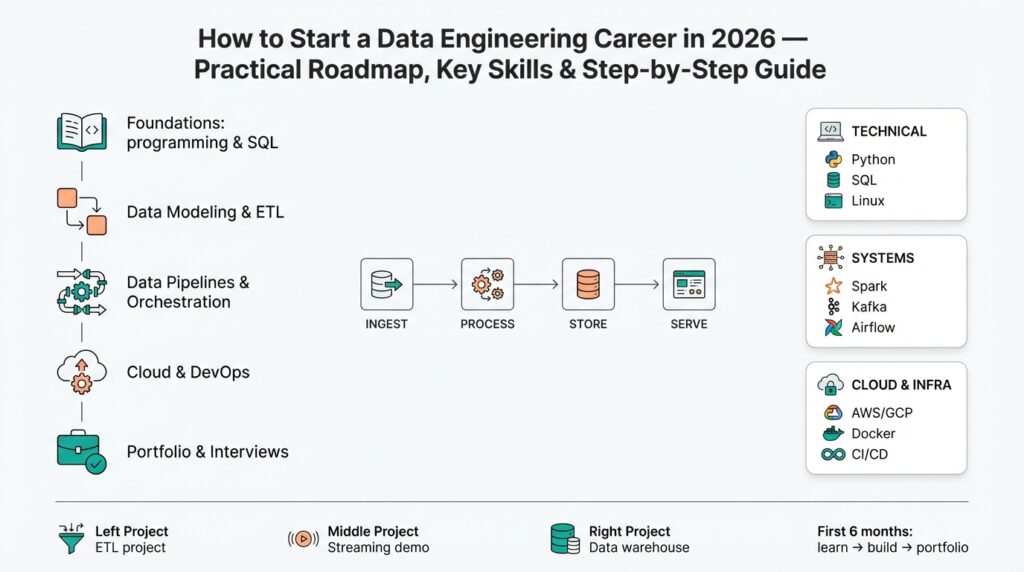
Why Data Engineering in 2026
Imagine you just opened your inbox and your product manager asks, “Can we start making decisions from this new stream of customer events today?” That urgent, hopeful question is exactly where data engineering lives: translating raw, fast-moving information into reliable tools your team can trust. In 2026, data engineering matters because organizations are collecting more data than ever, adopting machine learning across products, and expecting insights with near-zero delay — and you, as a data engineer, are the person who turns that chaos into calm. This is the moment to learn how data engineering shapes value, not just moves bits around.
The first thing to understand is what we mean by a data pipeline: a data pipeline is the sequence of steps that moves and transforms data from where it’s created to where it’s useful, like a kitchen line that turns raw ingredients into a plated dish. Companies rely on these pipelines to feed analytics, power recommendations, and train models. Cloud data platforms (cloud-hosted services that store, process, and analyze data) have made building pipelines faster and cheaper, while modern orchestration tools coordinate complex workflows. As a result, the role of a data engineer has shifted from manual babysitting to designing resilient, observable systems that scale with product demands.
Why does this matter for your career right now? The short answer: impact and opportunity. Organizations want faster answers — not weekly reports but real-time data that lets them personalize experiences, detect fraud, and adapt pricing instantly. Real-time data means streaming technologies and event-driven architectures, which require different patterns than traditional batch jobs. How do you move from curiosity to capability when the world expects instant insights? By learning the mental models that make streaming, batch, and hybrid approaches predictable and maintainable.
Another part of the story is responsibility: as data moves from engineers to analysts and machine learning teams, issues like data quality, lineage, and governance become central. Data quality means the data is accurate and consistent; lineage means you can trace where a value came from; governance means rules are in place to use data safely and compliantly. These concepts turn data engineering work into a bridge between technical systems and business trust — companies pay a premium for engineers who can deliver not only speed, but correctness and auditability.
From a skills perspective, this year rewards breadth plus depth. You’ll combine coding (Python, SQL), system design (how to build scalable storage and compute), and platform fluency (cloud data platforms, container orchestration, and workflow schedulers). Learning core patterns — extraction/transformation/load (ETL/ELT, which are ways to move and modify data), streaming vs batch, and observability (monitoring how data behaves in production) — gives you tools you can apply anywhere. That mix makes your career resilient: vendors change and tools evolve, but the underlying patterns keep you effective.
Building on this foundation, the practical advantage for newcomers is clear: you can get meaningful wins quickly by constructing one well-designed pipeline and shipping it. Start small, map the data flow end-to-end, add tests, and make the pipeline observable with metrics and logs so failures become less mysterious. That first project—feeding a cleaned dataset into a dashboard or a simple model—demonstrates the exact value data engineering delivers and becomes a story you can tell in interviews and on your resume.
So what should you take with you as we move forward? Data engineering in 2026 is about turning velocity into value while keeping reliability and trust intact. As we continue, we’ll break down the concrete skills and step-by-step roadmap that let you build those first pipelines, learn the cloud platforms that power them, and land your first role as a data engineer.
Core Fundamentals to Learn
Imagine you’ve just read the product request in the previous section and you’re wondering which skills will actually let you build that first reliable data pipeline quickly. Right away, the most important foundation is mastering the core ideas of data engineering: moving data reliably, transforming it correctly, and making it observable so teams trust it. We’ll treat each idea like a character in a story — the extractor, the transformer, the store, and the monitor — so you see how they interact rather than memorizing a checklist.
First, get comfortable with the basic processing patterns that reappear in every real project. Batch processing (processing groups of records at intervals) and streaming (processing individual events as they arrive) are the two big modes you’ll use; both have trade-offs in latency, complexity, and cost. ETL/ELT are simply two ways to move and change data: ETL (extract-transform-load) means you transform before storing, while ELT (extract-load-transform) means you store raw data first and transform later. Understanding when to choose batch versus streaming, and when ETL or ELT fits, is like learning whether to cook a slow braise or a quick stir-fry — the right method depends on the ingredients and timeline.
Next, learn the languages and tools that let you express those patterns. SQL (Structured Query Language), which is used to query and shape tabular data, is non-negotiable — you’ll use it daily to test assumptions and build datasets. Python is the most common programming language for data engineering tasks because it balances readability with strong libraries for data manipulation and automation. Familiarity with both gives you the practical muscles to prototype a pipeline end-to-end, from a SQL query that defines a cleaned dataset to a Python script that orchestrates transformations.
Behind your code lies infrastructure you’ll need to design and use. Cloud data platforms (cloud-hosted services that store and process data) provide scalable storage and compute so you don’t manage physical servers; learn one major cloud provider and its data services to begin. Orchestration tools — workflow schedulers that run jobs in the right order — act like a kitchen manager ensuring steps happen reliably and retries happen when things fail. Container management and basic networking concepts help you understand how jobs execute in production and why a pipeline might slow down during peak traffic.
Quality, lineage, and observability are the glue that turns a running pipeline into a trustworthy asset. Data quality means checks and tests that verify accuracy; lineage means the ability to trace a value back to its source; observability is the practice of collecting metrics, logs, and traces so you can detect and diagnose problems. How do you prove a dataset is correct to an analyst? By pairing automated tests with clear lineage and dashboards that show freshness and error rates. Instrumenting pipelines this way makes failures audible early so they become solvable, not mysterious.
Finally, translate knowledge into small, testable projects: ingest a public dataset into cloud storage, write a SQL transform that produces a dashboard-ready table, and add a simple alert when freshness lags. This sequence — ingest, transform, store, observe — reinforces the mental model and gives you concrete artifacts for interviews. Ask yourself regularly: what did this pipeline guarantee, and how would I prove it? That habit of turning assumptions into checks is what separates hobby projects from production-ready data engineering work and sets us up for the practical roadmap we’ll explore next.
Essential Tools and Platforms
Imagine you’re standing in front of a vast pantry of tools, hungry to build your first reliable data pipeline but not sure which ingredients to pick. Right away, the most useful thing to know is that data engineering is less about memorizing every vendor and more about understanding the roles those tools play in a pipeline: ingestion, storage, processing, orchestration, and observability. We’ll treat each role like a member of a kitchen brigade so you can see how they work together, and why choosing the right platform affects how fast and safely you can deliver data to the team.
Start by meeting the characters you’ll use most often. Ingestion is how data arrives (connectors, change-data-capture, APIs); storage is where raw and transformed data live (object stores, data warehouses); processing is where transformations happen (SQL jobs, Python ETL, stream processors); orchestration is the scheduler or conductor that runs steps in order; observability is the set of practices that tells you whether the pipeline is healthy (metrics, logs, and lineage). Defining these roles up front makes it easier to map any real tool to a clear purpose, so you won’t be tempted to learn tools in isolation.
Cloud data platforms deserve special attention because they bundle storage, compute, and services you’ll use every day. Think of cloud data platforms as the commercial kitchen you rent: they supply the ovens, refrigeration, and dishwashers so you don’t have to buy them yourself. Picking one major cloud provider to learn first gives you a coherent set of services and reduces context switching; you’ll get practice with provisioning storage, running compute, and understanding costs—all practical skills for a data engineering role in 2026.
When it comes to processing, decide whether your problem needs batch or streaming thinking. Batch processing groups records and runs periodic jobs (like doing a weekly grocery run), while streaming processes each event as it arrives (like grabbing ingredients as guests walk in). Streaming introduces continuous-state challenges but unlocks low-latency features; batch is easier to reason about and often cheaper. Learning one batch engine and one streaming model will cover the mental patterns you’ll reuse across projects.
Orchestration ties the pieces together, and learning it early makes pipelines dependable. Orchestration refers to workflow schedulers and systems that run jobs in order, manage retries, and expose job status—so when something fails you know where to look. Treat orchestration as the kitchen manager: it doesn’t cook, but it ensures every step happens at the right time and that errors trigger visible alerts. Familiarity with a workflow scheduler and basic container management gives you strong leverage when moving from prototypes to production.
Observability and data quality are what transform an implemented flow into a trusted asset. Observability means collecting metrics, logs, and lineage so you can answer questions like “When did this table last update?” or “Which upstream job introduced this null value?” Instrumenting freshness checks, SLA alerts, and simple tests turns guesswork into evidence and makes it easier to prove correctness to analysts and product folks. Lineage tools and data testing frameworks act like labelling and QA in a kitchen: they show what’s inside each container and whether it passed a health check.
If you want a practical starter stack to practice the patterns we’ve discussed, build a small project that mirrors production: ingest data into cloud object storage, load raw tables into a warehouse, transform with SQL-based tools or Python, schedule with a workflow scheduler, and add a few observability checks that alert on freshness and error rates. How do you choose which platform to learn first? Pick the one your target employers use or the one with the best free tier for hands-on practice, and focus on mastering the flow more than every checkbox on a features page.
Building on what we’ve already covered about patterns and roles, the real advantage comes from assembling this small, end-to-end stack and making it observable. When you can point to a working pipeline, describe why you chose each component, and show the tests and alerts that protect it, you’ve captured the practical essence of data engineering and set yourself up to expand into more advanced platforms and architectures.
Build Real-World Projects
Building on this foundation, imagine your portfolio filled with two or three small, well-crafted real-world projects that clearly show a working data pipeline and explainable choices. A data pipeline is the path data travels from creation to use, and cloud data platforms (cloud-hosted services that store and process data) give you the playground to build one without buying servers. Start by choosing a narrow, meaningful problem—answering a product question, powering a basic dashboard, or training a tiny recommendation model—and treat the project as a story you can tell from raw events to the final insight. This first paragraph should make you feel like you can finish one end-to-end project in a week or two rather than a vague someday task.
Begin with a minimal, repeatable architecture so you can iterate quickly and learn patterns rather than tools. Pick an ingestion method (APIs, file drops, or change-data-capture) and decide whether to use ETL/ELT — ETL means extract-transform-load, where you clean before storing; ELT means extract-load-transform, where you keep raw data and transform later — and explain that trade-off in your README. Use object storage (cloud-hosted file storage for raw files) for landing data and a data warehouse (structured storage optimized for analytics) for curated tables; this separation keeps costs low and your experiments replayable. Treat your first project like a recipe: list ingredients, steps, and what success looks like so others (and future you) can reproduce it.
Now let’s walk through a concrete starter project that showcases the core skills. Imagine ingesting an e-commerce clickstream or public GitHub events into cloud object storage, loading daily raw files into a warehouse, and using SQL (Structured Query Language, used to query and shape tabular data) to build cleaned, analyst-ready tables. Add simple data quality tests that check for nulls, duplicates, or freshness and surface failures in a dashboard—this is observability, the practice of collecting metrics and logs so you can detect and diagnose problems. By the time you have a dashboard that refreshes predictably, you’ll have a demonstrable artifact: a runnable pipeline, clear tests, and a story linking input events to an actionable metric.
Once you’ve shipped a batch pipeline, take one step further with streaming to learn different constraints and benefits. Streaming processes each event as it arrives and is useful when low latency matters; batch groups records and runs periodic jobs when latency can be minutes or hours. When should you pick streaming over batch? Choose streaming if your product needs near-real-time reactions (fraud alerts, live personalization), and choose batch when simplicity, cost, and repeatability matter more. Try a small streaming project using a managed message system and a simple windowed aggregation to observe how state, ordering, and backpressure change the game.
Make projects production-like by adding orchestration (workflow schedulers that run jobs in order and manage retries), container management, and a lightweight CI/CD process so changes deploy reliably. Instrument lineage (the ability to trace a value back to its source) and include a runbook that explains how to recover from common failures; these artifacts show you understand responsibility, not just code. Keep costs and scope realistic: use free tiers or small instances, and document trade-offs in your repo so interviewers see design thinking. This is the difference between a toy script and a credible data engineering portfolio piece.
Finally, package each project so it tells a clear story to anyone reading your resume or GitHub: a short diagram showing flow, a README that states the business question, a couple of runnable scripts or notebooks, and screenshots of metrics and alerts demonstrating observability. Walk interviewers through the choices you made, why you chose batch or streaming, and how tests and monitoring protect data quality—this narrative demonstrates both technical skill and product thinking. As we move on, you’ll see how to use these projects in interviews and expand them into domain-specific case studies that match the roles you’re targeting.
Create a Job-Ready Portfolio
Imagine you’ve just finished a neat, end-to-end data pipeline and you’re wondering how to turn that work into a job-ready data engineering portfolio that actually opens doors. A portfolio here means a curated collection of projects and artifacts that show not just code, but the decisions, tests, and observability that make a pipeline trustworthy. Think of it like a chef’s tasting menu: each dish (project) should highlight a technique, justify an ingredient, and tell a short story about why it matters to users or the business.
Start by framing each project around a single clear question so reviewers immediately grasp its purpose. State the business question in the README (a README is a short document explaining what the project does, how to run it, and why it matters), then sketch a simple architecture diagram that shows sources, the cloud data platform you used, processing steps, storage, and where observability lives. Building on this foundation, explain why you chose batch or streaming and whether you used ETL (extract-transform-load — transform before storing) or ELT (extract-load-transform — store raw data first and transform later); that narrative demonstrates product thinking more than listing technologies ever will.
Show runnable work rather than screenshots alone so reviewers can reproduce your results. Include scripts or lightweight automation that ingests sample data into cloud object storage, runs transformations into a warehouse, and produces the final table or dashboard; provide a small dataset or a script to download public data so the pipeline runs on a reviewer’s laptop or in free-tier cloud accounts. Add a brief walkthrough (a few CLI commands or a tiny notebook) that recreates the main outcome; reproducibility signals you understand operational constraints and makes your portfolio immediately usable in a technical interview.
Make observability and data quality front and center because these aspects separate hobbyist projects from job-ready pipelines. Observability (the practice of collecting metrics, logs, and lineage to understand system health) should be visible in your project: include sample metrics for freshness and throughput, a screenshot or exported CSV of alert history, and simple data tests that check for nulls, duplicates, and schema drift. Describe lineage — how to trace a value from the dashboard back to its raw source — so an interviewer can see you think about auditability and trust. These artifacts answer the common hiring question: “How would you prove this dataset is correct?” before they even ask it.
Polish the operational bits that hiring teams expect: a clear runbook, a short section on cost and scaling trade-offs, and a minimal CI/CD pipeline or deployment script that demonstrates how changes get applied safely. Orchestration (workflow schedulers that run jobs in order and manage retries) is worth showing; a small DAG or scheduled job proves you know how to make pipelines reliable. If you used containers, briefly explain why containerization mattered for that project; if not, explain how you would adapt the design when the workload grows — this shows practical foresight without bloating scope or cost.
Package each project so a recruiter or engineer can understand it in under five minutes: a one-paragraph summary, an architecture image, a list of runnable steps, and the key observability screenshots or logs. Consider a short demo video (60–90 seconds) where you narrate the story: business question, pipeline flow, and one failure you fixed — this humanizes technical work and is especially effective when your GitHub repository gets reviewed quickly. How do you talk about trade-offs in an interview? Practice a 2–3 minute explanation that covers why you picked batch vs streaming, why you added particular tests, and what you would change in production.
Taking this approach turns individual projects into a coherent data engineering portfolio that highlights technical skill, product judgment, and operational responsibility. With reproducible pipelines, clear narratives, and visible observability, you’ll give interviewers the concrete artifacts they need to trust you with production systems — and you’ll have stories you can confidently tell in every technical conversation.
Interview Prep and Job Search
Imagine you’ve built a tidy data pipeline in your sandbox and now you’re standing at the doorway to interviews and the job search wondering how to tell a convincing story. In data engineering interviews hiring teams are not just checking boxes on tools — they want to know you can deliver reliable pipelines, reason about trade-offs, and keep data trustworthy. Building on this foundation, your resume and portfolio become the bridge between what you built and the problems employers need solved, so we’ll treat preparation like rehearsing a performance where each artifact has a clear role to play.
First, know the two kinds of technical scenes you’ll face and prepare them both. One scene is hands-on work: live coding with SQL (Structured Query Language, the standard for querying tabular data) or a take-home exercise where you move and shape data; the other is system design where you sketch an architecture for a streaming or batch pipeline. How do you pick what to show? Choose one compact project that highlights a clean ingestion path, a transformation that uses SQL or Python, and observability so you can point to tests and alerts during the conversation. Saying “I built this pipeline” is less convincing than walking an interviewer step-by-step from the raw event to the final table and showing the specific checks that prove it’s correct.
Next, unpack the product and behavioral side like a short story you can tell naturally. Interviewers will ask why you made a choice — why batch instead of streaming, why ELT rather than ETL, or how you would scale the pipeline if traffic doubled. Prepare two or three STAR-style (Situation, Task, Action, Result) stories that emphasize ownership: a time you fixed a data-quality incident, how you traced lineage to find the root cause, or how you added a freshness metric that prevented a production outage. These stories signal that you understand not only how to build systems, but how to keep them trustworthy for analysts and ML teams.
Your portfolio should be organized so a reviewer understands it in under five minutes. Start each project with one clear sentence describing the business question it answers, follow with a compact architecture diagram, and include runnable scripts or a tiny notebook that reproduces the main outcome. Make observability visible: include screenshots or exported CSVs of freshness checks, a brief runbook that shows common recovery steps, and a short demo video (60–90 seconds) where you narrate the flow and one problem you solved. This turns code into a narrative artifact you can draw from during interviews.
When you move into active job search, be intentional about targeting and tailoring. Research companies’ tech stacks and prioritize roles that match the cloud data platform or orchestration tools you know; customize your resume bullets to highlight the project most relevant to their needs. Reach out with warm messages on professional networks, contribute a small improvement to an open-source tool you used in a project, and ask for informational chats with engineers — hiring often starts from curiosity and relationships, not just submitted applications.
Practice under pressure so your explanations become second nature. Do timed SQL problems, sketch pipeline designs on a whiteboard or digital canvas, and rehearse walking through your portfolio while sharing your screen. Simulate interview follow-ups by having a friend ask “What would you change in production?” or “How do you detect schema drift?” and practice answering concisely while referencing concrete artifacts: a test that failed once, a dashboard showing throughput, or a CI/CD step that gated deployments.
Taking these steps turns your projects into interview-ready stories and makes the job search a sequence of approachable actions rather than an overwhelming scramble. As we move on, we’ll use these interview narratives to pick the next technical skills to sharpen and the exact artifacts that will land you that first data engineering offer.