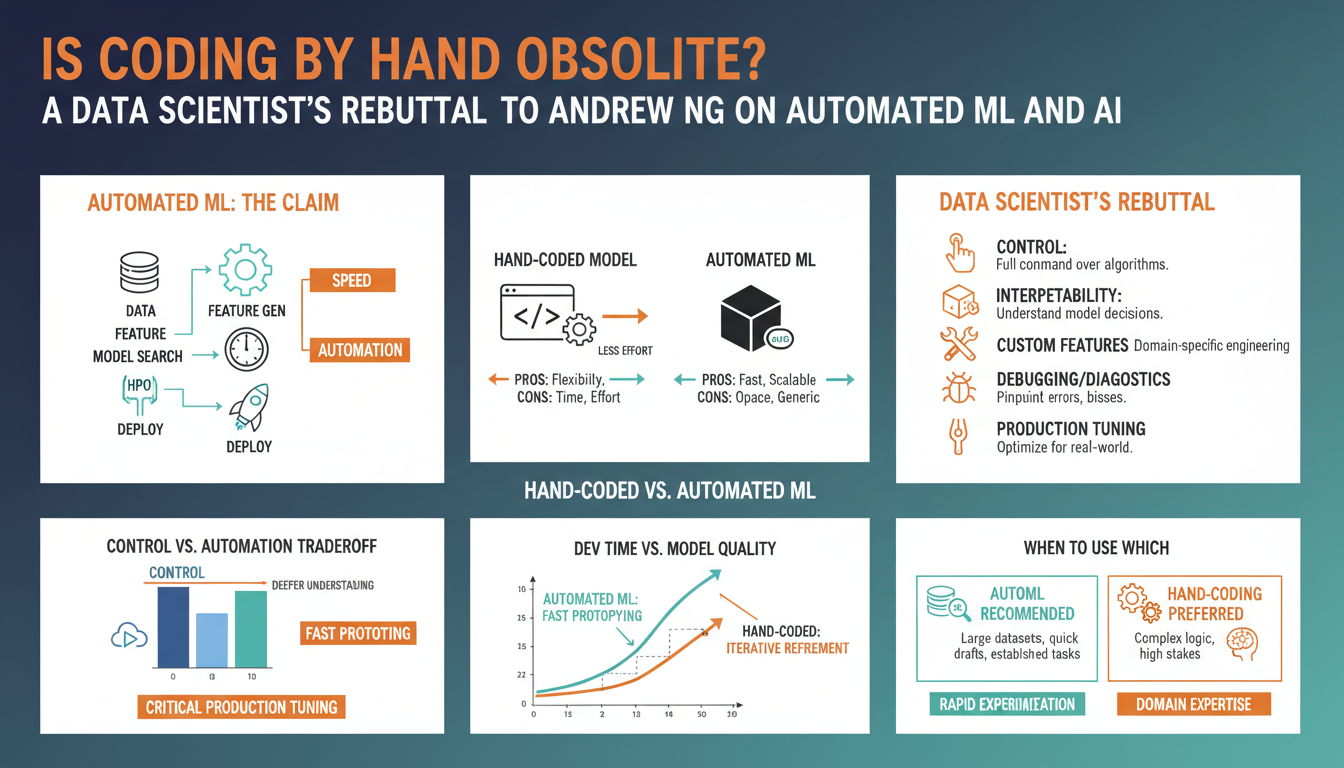
Quick recap: Andrew Ng’s claim and what ‘coding by hand’ means
Andrew Ng’s core point: many routine parts of building ML systems are moving from manual engineering toward automated pipelines — in his words, the machine increasingly “generates” solutions from data rather than a practitioner hand-coding every step. (kognition.info)
By “coding by hand” he means the traditional sequence data scientists and engineers used to do line-by-line: ingesting and cleaning raw files, writing feature transforms, architecting models, implementing training loops, hand-tuning hyperparameters, and wiring deployment scaffolding. These are the exact stages AutoML and no‑/low‑code tools target (automatic preprocessing, feature engineering, model selection, hyperparameter search and evaluation). (en.wikipedia.org)
Practically this looks like: upload a CSV or point an AutoML service at your data, pick the target metric, let the platform run candidate pipelines (feature ops + algorithms + NAS/hyperparameter tuning), then inspect and deploy the best model — you move from typing algorithmic details to specifying objectives, constraints, and tests. That trade‑off is what Ng is highlighting: less hand‑writing of plumbing, more emphasis on problem formulation, data quality, and validation. (infoq.com)
AutoML 101 — what automated pipelines actually do (and don’t)
AutoML systems automate the repetitive, computational parts of model development: they run data preprocessing (imputation, encoding, scaling), try many feature transforms and selectors, search over model families and hyperparameters, build ensembles, and surface ranked candidates with exportable artifacts or deployment hooks. (h2o.ai)
Under the hood different AutoML tools use different search strategies: many use Bayesian optimization and meta‑learning to warm‑start hyperparameter and pipeline search (auto‑sklearn), evolutionary/genetic programming to evolve end‑to‑end pipelines (TPOT), and neural‑architecture or architecture‑search components for deep models; managed services add pipeline orchestration, model distillation, and explainability dashboards. (papers.nips.cc)
What they don’t do is replace core human work: they don’t magically fix bad problem definitions, messy or biased data, domain‑specific feature design, causality needs, or production concerns like monitoring, A/B testing, latency constraints and governance. AutoML speeds hypothesis cycles and baseline productionization, but outputs still require careful validation, test harnesses, and domain oversight. (arxiv.org)
Hands-on comparison: build & benchmark the same model manually vs. with AutoML (code walkthrough)
Start by picking a small tabular benchmark (e.g., UCI Adult). Manually: load the CSV, write a reproducible sklearn pipeline (imputation -> categorical encoding -> scaling -> feature crosses), split with stratified CV, run a tuned estimator (e.g., XGBoost or RandomForest) with GridSearchCV or Optuna, record wall time, CV score, inference latency, and model size. In practice this is ~20–50 lines of code and gives tight control over features, constraints and latency.
With AutoML: point the tool at the same training and validation splits, set a runtime budget (e.g., 10–30 minutes), and let it run; AutoML will attempt preprocessing, many model families, HPO and ensembling, and return a ranked leaderboard plus exportable artifacts. This is typically a 5–10 line workflow (plus data typing) and produces strong baselines quickly. (docs.h2o.ai)
Benchmarking checklist: compare best CV metric, wall-clock compute, inference latency, model complexity, reproducibility, and explainability. Expect AutoML to often match or exceed manual baselines under a time budget but produce larger ensembles; careful manual feature work or constraints still win for latency or domain-specific signals. Empirical studies show mixed winners across datasets and budgets. (arxiv.org)
Practical limitations you’ll hit with AutoML — data, interpretability, customization, and deep learning
AutoML frequently trips on data problems most humans spot first: tiny or highly imbalanced datasets, noisy or mislabeled targets, leaked features, and multimodal inputs that weren’t preprocessed. Mitigations: run a label-quality audit (confusion matrix on a human‑review sample), stratified resampling or class‑weighting, feature‑leakage checks (time‑based splits), and if <~1k examples prefer simple models or transfer learning rather than full AutoML runs. (arxiv.org)
Out-of-the-box AutoML often returns ensembles and complex pipelines that hurt interpretability and latency. Practical fixes: limit the search to single-model families, force sparse or monotonic models, use model distillation to compress ensembles, and generate SHAP/PDP reports to validate feature effects before deployment. Expect extra effort to produce human‑readable decision rules. (docs.h2o.ai)
Customization and production constraints matter: you’ll need to constrain search spaces, exclude algorithms that violate latency/memory budgets, and supply domain features the AutoML won’t invent. Export artifacts and test inference in a staging environment early. (docs.h2o.ai)
True end‑to‑end deep‑learning automation (NAS / large multimodal models) is still compute‑hungry and experimental; use NAS as a starting point or prefer transfer/fine‑tuning of prebuilt architectures when GPU budget or latency are limited. (arxiv.org)
Designing hybrid workflows: when to use AutoML, when to hand-code, and how to combine them
Start with a decision checklist: prefer AutoML when you have >5k labeled examples, well‑structured tabular data, and need fast baselines or many experiments under time budgets; prefer hand‑coding when data are tiny/noisy, require domain features or causal reasoning, need tight latency/memory constraints, or must meet strict interpretability/governance requirements. For mixed cases, constrain AutoML (limit families, force single‑model runs, set latency budgets) and supply domain features it can’t invent.
A practical hybrid workflow (step‑by‑step):
1) Define objective, metric, and hard constraints (latency, size, fairness). 2) Run a short AutoML job as a rapid baseline and sanity check (10–60 min). 3) Audit outputs: label quality, leakage, top features (SHAP/PDP). 4) Hand‑implement critical transforms or logic uncovered by the audit (feature crosses, denoising, time bucketing). 5) Re‑run AutoML with constrained search or use it solely for HPO/NAS on your handcrafted pipeline. 6) If AutoML produces ensembles, distill to a deployable model and validate with production‑like latency and fairness tests.
Operational tips: track experiments in version control, automate reproducible pipelines, log candidate models and data lineage, and add monitoring/alerts for data drift before scaling to production.
Skills and practices data scientists must keep (feature engineering, validation, MLOps, domain expertise)
Effective feature design still wins: invest time in domain-driven transforms (aggregations, lag/time-buckets, interaction terms, normalized ratios), build reproducible pipelines (scikit-learn/TF Transform), register features in a feature store, and profile candidate features with held-out cross‑validation and SHAP/PDP checks to confirm signal and stability before deployment. (oreilly.com)
Rigorous validation is non‑negotiable: keep strict train/validation/test splits (time-aware where relevant), perform label‑quality audits and leakage checks, run automated schema/anomaly checks (TFDV or Great Expectations) on train vs. serving, and report expected‑validation performance as a function of compute to avoid selection bias. Concrete steps: infer schema → validate splits → sample human review of 1–2% labels → run CV + calibration. (tensorflow.org)
Operational practices matter: version code, data, features and models (Git + DVC/MLflow), automate pipelines (Kubeflow/CI) with blue/green or canary deploys, monitor drift/latency/metrics and wire automatic retrain or rollback triggers; log lineage and create alerts for model degradation. (palospublishing.com)
Domain expertise is the multiplier: embed SMEs in labeling, create explicit business rules and feature heuristics, prioritize data fixes over complex modeling (data‑centric iterations often yield larger gains), and treat model outputs as hypotheses to be validated with domain tests. (deeplearning.ai)



