Problem Overview
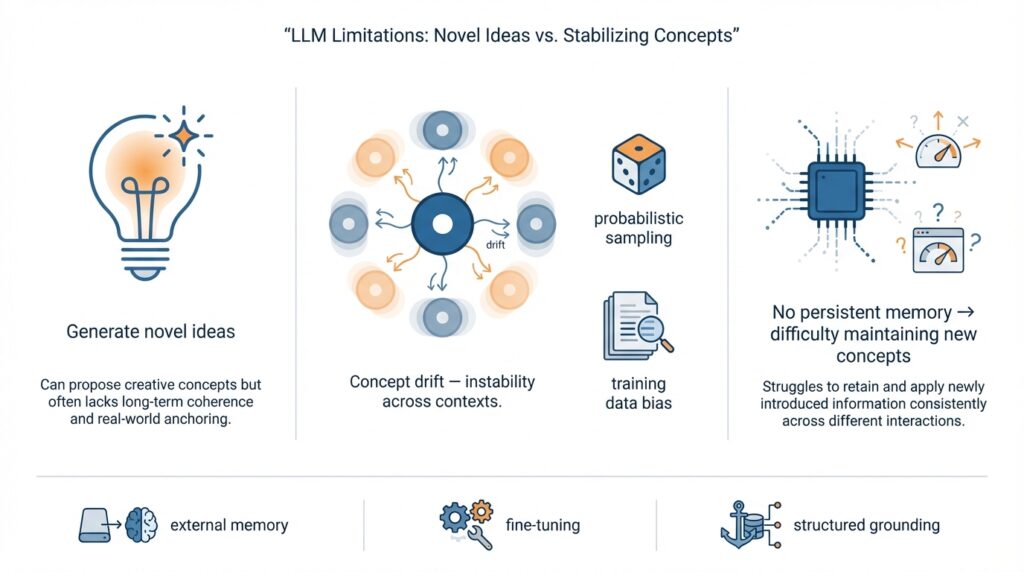
Imagine you’re sitting with a chat window open and the model surprises you with a creative, off-the-wall idea — a new metaphor, a fictional framework, or a fresh naming scheme that feels original. Right away you notice something else: the next time you ask, the phrasing changes, the details drift, and the coherent concept you loved fragments. This tension — that models can spark novel ideas yet struggle to stabilize and maintain new concepts — sits at the heart of many frustrations with LLM limitations and with large language models more broadly. We’ll walk through why that happens and what’s driving the instability you’re seeing.
At its core, the problem is a mismatch between generation and persistence. Here’s what that means: generation is the model’s ability to produce new outputs on demand, while persistence is its ability to keep an invented idea intact across future turns or sessions. An internal representation is the model’s hidden, learned summary of patterns and meanings; think of it like a mental sketch. Models excel at sketching a new idea on the fly, but they weren’t built to save that sketch into a forever memory. That difference explains a lot of the instability you observe.
One major cause is how these models are trained and used. Large language models learn from massive, static datasets and optimize for predicting the next word during training — they don’t update their underlying knowledge after deployment unless a retraining or fine-tuning step happens. The context window, which is the slice of recent conversation the model can “see,” acts like short-term memory: we can keep a thought alive only while it stays inside that window. When you try to introduce a new concept to the model, it can adopt it for the next few responses but can’t truly rewrite its long-term weights, so the concept fades or morphs once it’s outside immediate context.
Another culprit is the probabilistic nature of generation. When a model samples from possible continuations, it trades strict repetition for creativity; settings like temperature control how adventurous the model is. Sampling encourages variety — which fuels novel ideas — but that same variety produces concept slippage: small variations in word choice gradually accumulate until the original meaning shifts. Imagine telling the same story to three different friends: each retelling will be slightly different, and after several retellings the story can feel quite foreign. That’s what happens inside probabilistic decoding.
A third, subtler issue comes from the optimization objective itself. The token-level objective, which pushes the model to predict the next token accurately, rewards local fluency more than long-term conceptual consistency. The model doesn’t have an explicit internal goal to “remember this new rule” across many turns; it only has the goal to sound plausible at each step. So even if you teach a model a crisp new definition in one message, the next outputs will prioritize grammatical coherence and likelihood, not sustained adherence to your freshly minted concept.
These causes interact in ways that amplify drift. If you introduce a novel idea using a few evocative sentences, the model may generate a strong immediate response (novel ideas shine here), but probabilistic sampling plus limited context can create branching reinterpretations. Small paraphrase differences act like branching paths in a story: one branch stays true, another bends the meaning, and another reinvents the idea entirely. For a person trying to build systems or workflows that rely on stable, invented semantics, this unpredictability becomes a practical limitation.
Understanding these dynamics matters because it reframes what we can reasonably expect from LLMs and how we design around their weaknesses. If models are excellent idea generators but weak long-term keepers, then the engineering focus shifts to techniques that pin ideas into memory — explicit state, fine-tuning, or external knowledge stores — rather than hoping the model will internally stabilize and maintain new concepts on its own. With that in mind, the next part will explore concrete strategies to reduce drift and make invented concepts stick.
How LLMs Generate Novelty
Imagine you’re halfway through a chat and the model hands you a metaphor or a naming idea that feels freshly minted — surprising and oddly perfect. How do LLMs pull out ideas that feel new? Right away: LLMs (large language models) generate novelty by recombining patterns in ways our brains find meaningful. In this paragraph we’ll set that scene and introduce one core term you’ll see often here: latent space, the model’s internal map of learned patterns where similar ideas live near each other, like neighborhoods on a mental atlas.
Think of the model’s knowledge as a vast library of phrases, metaphors, and facts. When you prompt the model you’re asking it to walk through that library and pick out pieces that fit, then glue them together. The mechanism that helps it decide which pieces to pay attention to is called attention — a computation that scores relevance between words and phrases so the model can focus on the right passages the way you skim a book for a quote. Because attention can link unexpectedly distant materials, the model often stitches concepts from different domains into something novel: a culinary metaphor for software, or a poetic turn of phrase for a technical idea.
The way the model turns those internal signals into text is controlled by decoding and sampling choices. Decoding is the process of choosing the next token (a token is a chunk of text, like a word or part of a word) to emit; sampling means we sometimes pick less-likely tokens to be creative instead of always taking the single most probable one. Temperature is a knob that softens or sharpens that probability distribution: low temperature makes the model conservative and repeatable, high temperature makes it adventurous and surprising. Top-k and top-p (also called nucleus) are filters that limit which candidates we consider; they shape whether novelty comes from bold leaps or small, safe variations.
Behind those knobs lies another source of novelty: latent interpolation. In the model’s latent space, internal activation patterns can blend two concepts the way a musician improvises by overlaying motifs. When activations land between two learned poles — say, philosophical rhetoric and software documentation — the generated output can read like a new genre. That blend feels original because it was never a single example in training data; instead it’s a fresh trajectory through the model’s representation space.
Why does this not stick? One reason is probability. Novel outputs often rely on low-probability associations that are accessible but not dominant. Sampling surfaces them temporarily, but every subsequent generation re-evaluates probabilities afresh. Another is representational interference: the same latent regions that can blend concepts also let nearby, slightly different blends arise, producing drift. This is what practitioners mean by concept drift here — the gradual shifting of an invented idea as the model keeps re-sampling and paraphrasing rather than committing to one anchored representation.
Pretraining and scale matter too. Pretraining (the initial large-scale learning phase where the model ingests massive text) populates that latent space with a richer palette, and larger models tend to find more creative interpolations because their internal maps are more detailed. That makes them excellent generators of novelty, but excellent generation is not the same as excellent retention. We get flashes of brilliance: new metaphors, naming schemes, frameworks. Yet without an external way to pin those flashes into durable memory — a saved definition, a retrieval index, or weight updates — the model will keep improvising instead of reproducing the same exact idea every time.
So when you see an LLM invent something delightful, remember what produced it: attention-guided recombination, latent-space blending, and probabilistic decoding that privileges variety. That understanding helps us treat those moments as creative sparks rather than stable artifacts, and it sets the stage for practical ways to capture and preserve the best of those sparks in the next part of our journey.
How LLMs Represent Concepts
Imagine you taught an LLM a tiny, new rule mid-conversation — a playful definition or a branded term — and felt triumphant when the model echoed it back. Building on this foundation, let’s step behind the curtain to see what that moment actually looks like inside the model. At the heart of the model’s momentary agreement are a few key players: embeddings (which are numeric summaries of words or tokens), latent space (the internal map where those embeddings live), and activations (temporary patterns of activity that flow through the network when it processes text). We’ll treat each like a character and watch how they interact so you can see why concept drift often follows creative sparks.
First, picture embeddings as small identity cards the model gives every token — a number list that captures meaning in a compact form. An embedding is a vector, which you can think of as a point on a map; similar words sit near each other on that map. When you introduce a new idea, the model doesn’t insert a new physical card into its library; instead, it composes that idea on the fly by nudging available embeddings and creating transient activations. This is why the model can echo a freshly defined concept within the same chat: the context window (the short-term slice of conversation the model “sees”) keeps those nudges visible, and activations carry the makeshift definition through the immediate responses.
Now let’s talk about latent space and why it both enables novelty and invites drift. Latent space is the model’s internal atlas where concepts form neighborhoods; it’s where attention — the mechanism that scores relevance between words — picks which neighborhoods to walk through. Because neighborhoods overlap and are continuous, the model can interpolate between two nearby ideas, producing creative blends. But that continuity also means there aren’t hard borders: nearby but different meanings can bleed into each other across turns, producing the concept drift you’ve seen. Think of it like watercolor: colors blend beautifully, which creates novel hues, but those hues don’t stay sharply defined unless you fix them.
How do activations and probabilistic decoding produce variation? Activations are ephemeral; they’re the model’s immediate thought patterns when it processes your latest prompt. Probabilistic decoding (the process by which the model samples likely next tokens rather than always choosing the single most probable one) injects diversity into each generation. When you combine shifting activations with sampling, small paraphrase choices snowball: a synonym here, a reordered clause there, and the invented idea slowly skews. That’s exactly how novelty and instability coexist — the same mechanisms that let the model recombine concepts (attention, latent space blending, sampling) also make precise repetition fragile.
There’s a subtler phenomenon at play called representational superposition, which is the model’s habit of packing many concepts into the same dimensions to be parameter-efficient. Superposition means that a single direction in latent space can carry signals for multiple, loosely related ideas. We define superposition here as that multiplexing behavior — it’s efficient, but it raises interference: when you try to pin down one newly invented meaning, other overlapping signals tug at it and nudge it toward existing, stronger concepts in the model’s prior knowledge.
Let’s make this concrete with an example: you invent the term “threadgarden” to mean a lightweight project tracker and explain it in two sentences. In that chat, attention amplifies the explanation, embeddings shift slightly as activations encode the meaning, and the model will happily repeat “threadgarden” for the next several replies. But once the phrase moves outside the context window or you prompt differently, probabilistic decoding and the latent neighborhood’s pull make the model reinterpret the term — maybe as a messaging metaphor or an actual gardening guide. That drift isn’t mysterious; it’s the expected outcome of transient activations meeting continuous latent structure.
So what does this mean for making invented concepts stick? You can think of stabilization as creating stronger anchors: repeated, explicit context; special tokens or phrases that act like labels; external memory stores that record definitions; or fine-tuning that actually changes the model’s embeddings and weights. Each of these techniques trades convenience for permanence in different ways, but they all aim to convert an ephemeral activation into a durable representation.
As we move on to practical techniques, remember the main idea you’ve just seen: LLMs represent concepts as points and patterns in a shared, continuous latent space, and probabilistic decoding plus superposition makes transient creativity likely but long-term stability difficult. That understanding explains both the model’s flashes of invention and the familiar, frustrating drift that follows — and it points clearly at the engineering tools we’ll use next to pin the best ideas in place.
Why New Concepts Are Unstable
You’ve just watched the model hand you a gleaming new idea, and then watched it unravel a few turns later — that tug between spark and slippage is what we call concept drift, and it lives where latent space meets probabilistic decoding. In the first moments after invention the model’s internal activations and the current context window cooperate to present a tight, convincing concept; the trickiness begins as those ephemeral signals leave the immediate conversation and the model must re-create the idea from shaky clues. If you’ve read the earlier sections, you already know the names of these actors; here we’ll follow their interplay to see why novel concepts rarely stay neatly fixed.
At heart, instability is the result of fragile anchoring. Imagine the new idea as a loose note pinned to a corkboard inside the model’s short-term workspace: the context window. That note is vivid while it’s visible, but it’s not soldered into the model’s long-term map — the latent space where durable meanings live. What makes a freshly invented idea fade from one message to the next? Small changes in wording, different attention focuses, and the model’s sampling choices all nudge the representation, and without a persistent encoding each nudge accumulates into drift.
Think of retelling a story around a campfire to hear how drift works in practice. The first teller invents a memorable phrase and the second echoes it faithfully; by the fifth retelling the phrase has shifted, associations have layered in, and the original meaning is diluted. In models this happens faster because probabilistic decoding intentionally explores alternative continuations: synonyms, reordered clauses, or slightly altered metaphors. Those small paraphrase decisions are innocent on their own, but they compound, creating branching reinterpretations rather than a single, stable thread.
There’s a deeper structural reason too: representational superposition. The model packs many related signals into shared dimensions to be efficient, which means the same latent directions can carry overlapping meanings. When you try to graft a new concept onto that multiplexed space, competing signals tug at it. Instead of a clean new node in the map, you get a watercolor wash that borrows edges from preexisting concepts — and when the context window fades, stronger, prior signals reassert themselves and nudge the invented idea toward familiar territory.
This interaction between sampling noise and overlapping representations also explains why temperature and decoding settings feel like knobs on unpredictability. Higher temperature yields richer novelty but increases drift because generations deviate more from any single anchored phrasing. Lower temperature yields repeatability but can crush the very creative blends you welcomed. For someone designing prompts or workflows, this means a trade-off: maximize novelty for ideation, then switch to conservative decoding or explicit reinforcement when you want stability.
You can detect and quantify instability with simple experiments: create the idea, then prompt the model multiple times with slight variations and measure how definitions diverge. If paraphrases shift meaning across runs, that’s concept drift in action; if variations remain consistent, you’ve found a more robust anchor. These checks turn an abstract complaint into concrete evidence you can reason about, and they give you levers to adjust sampling, context length, or reiteration strategies.
Building on what we’ve explored, the important takeaway is this: novelty and stability are produced by the same machinery and therefore fight each other by default. That tension is not a bug so much as a characteristic of continuous latent representations combined with probabilistic decoding. With that in mind, the next section will walk us through practical ways to convert those fleeting sparks into durable definitions — how to create anchors the model can reliably honor beyond the context window.
Improving Concept Stability
Imagine you just taught an LLM (a large language model — a system that predicts and writes text) a tiny new idea and then watched it slip away two turns later. Right away you’re chasing concept stability: the ability to keep that invented meaning intact across prompts. How do you make a freshly invented concept stick instead of drifting into something else? That question sits at the center of fixing concept drift, and the first step is to treat the moment of invention like a ritual rather than a one-off spark.
Start by creating a canonical anchor for the idea: a short, explicit definition, a fixed label, and a clear example. An anchor is simply a repeatable phrase or mini-paragraph that always accompanies the concept; it acts like a name tag you pin to the idea. For example, when we tried “threadgarden” earlier, writing a one-sentence definition (“threadgarden: a lightweight project tracker that organizes tasks as short, color-coded threads”) and following it with two small examples made the model echo that meaning more reliably. Reiteration matters because the model’s context window — the slice of conversation it can “see” — holds those cues only while they’re present.
Next, manage how the model generates text by adjusting decoding behavior. Probabilistic decoding is the process that samples the next token, and it’s what lets models be creative but also causes drift. Lowering temperature (the knob that controls randomness), using conservative top-k/top-p settings, or switching to deterministic decoding like greedy or beam search reduces paraphrase variety and helps keep wording consistent. Remember this trade-off: the more you clamp down for stability, the less likely you are to get surprising novelty, so pick decoding settings depending on whether you’re in ideation mode or stabilization mode.
Pair in-context anchoring with external memory to buy persistence beyond the context window. Retrieval-augmented generation (RAG) is the pattern where you store canonical definitions in a searchable index and fetch them into the prompt when needed. Embeddings (numeric summaries of text) let you find the closest saved definition for a given query; the retrieved text is then pasted into the model’s context so the model can re-ground itself. Think of RAG like a filing cabinet you consult before every answer: the model doesn’t have to remember everything because you provide the truth each time.
For longer-term, higher-fidelity fixes, consider changing model behavior at the parameter level. Fine-tuning (retraining the model or parts of it on examples that include your new concept) or parameter-efficient techniques like LoRA and soft prompts (learned prompt fragments) actually shift embeddings and activations so the model more deeply internalizes a concept. These are more expensive and permanent than prompt tricks, but they’re powerful when you need reliable concept stability across many sessions. A hybrid approach often works best: use RAG for flexible recall and fine-tuning for the handful of concepts you truly want baked in.
Finally, build a small quality workflow around the concept: write canonical tests (small prompts that should elicit the exact definition), include few-shot examples demonstrating correct usage, and run regular checks to detect drift. Treat stability as an engineering problem with monitoring: log divergences, lower temperature for production paths, and lock definitions behind system messages or retrieved fragments. Building these habits converts ephemeral creativity into repeatable behavior, and with that foundation in place we can take one of these strategies and implement it step-by-step to make your next invented concept persist.
Monitoring and Evaluation
Imagine you’ve taught the model a neat new term and you want to know whether that idea will hold over time. Right away we must name the enemy: concept drift — the gradual change in meaning or usage of an invented idea across subsequent generations. Monitoring and evaluation are the tools we use to detect drift and measure stability, and they should live alongside ideation, not after it. How do you know if a concept is drifting, and what concrete signals should you watch for?
Building on this foundation, start by turning your invention into a set of canonical tests that the model must pass. A canonical test is a short prompt and expected response pair that captures the core definition and one or two typical uses; think of it like a unit test for language behavior. Create several variations of the test — slight rephrasings, different contexts, negative examples — and run them repeatedly. If the model’s outputs diverge from the expected text or meaning across runs, that’s a clear, measurable sign of concept drift.
To make those checks quantitative, use semantic similarity between the model’s response and your canonical definition. Embeddings are numeric summaries of text that let you compare meaning; compute the cosine similarity (a measure of angle between two vectors) between the canonical embedding and a new response’s embedding. Define a threshold for acceptable similarity and treat violations as alerts. This approach captures paraphrase-tolerant drift: the model can reword the idea but still remain “close” in meaning, which is often what we actually want.
Complement semantic checks with classification-style metrics when appropriate. Precision here means how often the model’s claimed usage actually matches your definition; recall measures how often the model, when asked, will produce the concept at all. F1 score is the harmonic mean of precision and recall and gives a single-number snapshot of reliability. These metrics let you compare changes over time or across decoding settings (for example, high temperature versus low temperature) and give you a defensible way to choose production parameters.
Monitoring should be automated and continuous. Log every canonical-test run, store both the raw text and embeddings, and visualize drift trends over time so you can spot slow decay before it becomes a problem. Add human-in-the-loop review for edge cases: when similarity drops near the threshold, a human reviewer inspects whether the change is a harmless paraphrase or a semantic slip. Treat monitoring not as policing but as feedback for the model’s memory strategy: if alerts cluster, that signals you need stronger anchoring techniques like retrieval-augmented generation (RAG) — where you store definitions externally and fetch them into prompts — or targeted fine-tuning.
When you do use RAG (retrieval-augmented generation), monitor retrieval quality as well as generation quality. Retrieval quality means the system finds the correct canonical definition in its index; generation quality means the model uses that retrieved text to produce the right answer. You can test retrieval with top-k recall (does the correct definition appear in the top k results?) and then recompute embedding similarity on the generated output. If retrieval succeeds but generation fails, the problem is decoding; if retrieval fails, the index needs better examples or denser embeddings.
Finally, operationalize evaluation as part of your development lifecycle. Add concept stability checks to CI-like pipelines for prompts, run regression tests after any model or prompt change, and record experiment metadata (temperature, top-p, context length) so you can trace regressions back to configuration changes. By treating stability as measurable engineering work — with canonical tests, embeddings and similarity thresholds, precision/recall tracking, automated logs, and human review — you turn fleeting creative sparks into reliable, repeatable behavior without losing the model’s capacity for novelty.