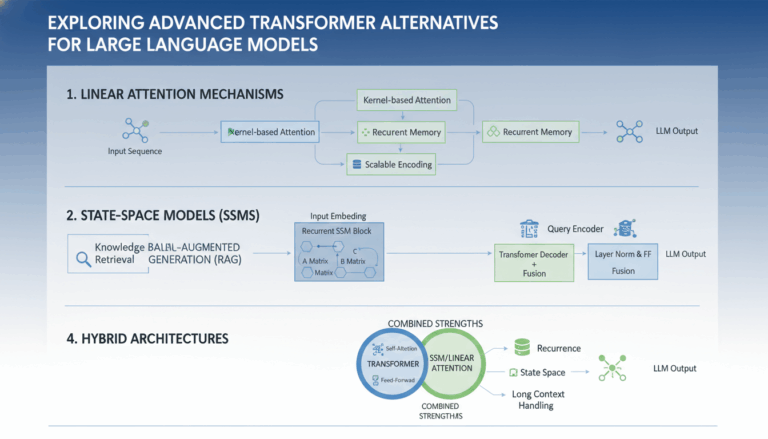
What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) represents one of the most transformative advances in the field of artificial intelligence. At its core, RAG is an AI framework that combines the strengths of information retrieval systems and large language models (LLMs). While traditional language models generate responses based solely on the data they were trained on, RAG enhances them by allowing these models to search external knowledge sources—such as databases, document repositories, or the web—on-the-fly to provide current, factual, and contextually appropriate answers.
In practice, RAG follows a two-step process:
- Retrieval: When presented with a user query, the system first retrieves the most relevant documents or passages from a massive corpus. This is done using highly-efficient retrieval algorithms, often based on techniques like vector similarity search. For example, if asked a question about the latest climate change findings, a RAG model would search scientific databases for the newest studies or summaries from trusted authorities like Nature or the Intergovernmental Panel on Climate Change (IPCC).
- Generation: The retrieved information is then provided as context for the language model to generate a well-informed, coherent response. Unlike classic LLMs, which may “hallucinate” or produce outdated answers, RAG ensures outputs are grounded in up-to-date, real-world information.
RAG’s power comes from this tight integration. For instance, customer support bots powered by RAG can access a company’s entire knowledge base, providing precise answers to user queries without requiring explicit manual training on every new document. Similarly, in academic research, RAG-based assistants can pull the latest peer-reviewed studies to support a thesis or recommend further reading, mirroring the workflows of expert human researchers.
This framework underpins some of today’s most innovative AI applications, including advanced search engines, research assistants, and even creative tools that need to reference external information. Leading technology organizations, such as Meta AI, have discussed the potential of RAG in enabling more robust, explainable, and transparent AI systems that continuously learn from new information, rather than being constrained by static training sets.
If you’re curious about the technical backbone of today’s adaptive AI systems, exploring RAG is essential. It opens up a world where AI moves beyond memorization and becomes a proactive partner in real-time knowledge exploration and problem-solving.
The Evolution of RAG: From NLP to Agentic AI
The journey of Retrieval-Augmented Generation (RAG) is a fascinating chronicle of progress, reflecting the broader transformation of artificial intelligence from narrow, rule-based systems to dynamic, agentic models capable of sophisticated reasoning and autonomy. Early on, RAG emerged as a solution within Natural Language Processing (NLP) to bridge the gap between static language models and the ever-expanding universe of human knowledge.
Roots in Natural Language Processing
Initially, RAG was developed to address the limitations of traditional NLP models, which often “hallucinated” information or lacked the capacity to incorporate up-to-date facts. By combining language generation models with retrieval systems, RAG empowered machines to fetch relevant information from external databases or documents in real time. This hybrid approach, as detailed in research from Facebook AI Research, drastically improved the accuracy and factuality of machine-generated responses.
For example, consider a standard language model asked, “Who won the Nobel Prize in Literature in 2023?” Without retrieval, its answer might be outdated or incorrect. With RAG, the model dynamically queries the most recent information during inference, ensuring its outputs are as current and precise as possible.
The Move Toward Agentic AI
As AI research progressed, the ambition expanded from simply providing better answers to enabling systems to act autonomously, pursue goals, and adapt to ambiguous instructions—hallmarks of agentic AI. Here, RAG’s role became foundational. Stanford HAI describes agentic AI as models imbued with the capacity to reason, plan, and interact with complex digital ecosystems.
In these agentic frameworks, RAG systems don’t just retrieve static references. Instead, they:
- Contextualize Multi-Step Reasoning: RAG enables models to gather information from several sources, synthesize answers, and justify decisions. For instance, in a medical diagnostic setting, an agent might retrieve recent studies, integrate patient data, and suggest actionable recommendations.
- Facilitate Autonomous Action: Instead of needing explicit, step-by-step user instructions, RAG-powered agents autonomously explore knowledge bases, APIs, or proprietary documents to complete tasks—like planning travel, managing schedules, or researching complex topics, as seen in advanced copilots like Google Gemini.
- Evolve with the Knowledge Landscape: As models interact with their environment, RAG’s retrieval mechanisms adapt, ensuring that agents remain effective even as the underlying data evolves, which is critical in fields with rapidly changing information such as finance or biomedical research.
Practical Examples
Imagine an AI agent tasked with summarizing emerging trends in climate policy for a government report. Using RAG, it would:
- Retrieve the latest policy papers, research articles, and government websites using a search engine or curated database.
- Aggregate and prioritize information, omitting outdated or low-quality sources.
- Generate a summary report, complete with citations and links to original documents for transparency and verification.
This continuous cycle of retrieval and generation, with a strong feedback loop, is rapidly becoming the backbone of agentic AI, taking AI from static response generators to dynamic, task-oriented virtual agents. As organizations increasingly demand AI systems with autonomy, reliability, and adaptability, the RAG paradigm will be essential in powering the next generation of agentic solutions.
How RAG Works: Combining Retrieval and Generation
Retrieval-Augmented Generation, or RAG, is a transformative framework that merges the power of two distinct, yet complementary, approaches in AI: information retrieval and natural language generation. Understanding how RAG operates is key to appreciating its revolutionary impact on agentic AI systems, especially those designed to answer complex queries or assist with decision-making.
In a traditional language model, all answers are generated based on the model’s internal parameters and whatever data it was trained on. This often results in limitations—most notably, outdated or incomplete knowledge. RAG addresses this by integrating dynamic retrieval, where the model actively seeks relevant documents or snippets from external databases or knowledge collections at inference time, before generating a response.
Step 1: Contextual Query Formation
Every RAG process begins with a query—often posed by a user. Instead of relying solely on internal memory, the system converts the user’s request into a search query. This conversion can be simple keyword extraction or more advanced natural language processing to get the most relevant context.
For example, if a user asks, “What are the breakthroughs in quantum computing from 2023?”, a RAG-enabled AI breaks down the question, identifies that it needs up-to-date scientific insights, and prepares a retrieval query for external sources.
Step 2: Intelligent Document Retrieval
After formulating the search query, RAG leverages an information retrieval module—typically leveraging vector space models or dense passage retrieval techniques. These algorithms scour a vast external knowledge pool, such as academic papers, news archives, or proprietary databases, fetching the most relevant documents or passages. Leading frameworks like TensorFlow Ranking and Elasticsearch are frequently employed here to optimize the relevance and accuracy of the retrieved content.
Step 3: Fusion of Retrieved Content and Generation
This is where RAG truly sets itself apart. The retrieved passages are fed into the language model, which uses this fresh, context-rich information to generate highly accurate and specific answers. Essentially, the model isn’t just parroting memorized data; it’s synthesizing new knowledge from authoritative external sources. This has proven indispensable in fields where real-time answers based on the latest research or data are essential, such as medicine, law, or tech research. For more about the fusion process, see academic work from the original RAG paper by Facebook AI.
Step 4: Output Refinement and Delivery
The generated response, now augmented with up-to-the-minute insights, undergoes further refinement—sometimes involving additional filtering for factual accuracy or coherence. The final output, delivered to the user, is significantly more reliable and context-aware than what standard language models could provide on their own.
Example Application
Imagine a RAG-based assistant for a legal professional. When asked about the latest precedent for a specific case, the agent pulls recent court case summaries from databases like CourtListener, scans the contents, and generates a nuanced reply, complete with references. This type of workflow showcases RAG’s ability to provide actionable, timely, and factually grounded intelligence.
By intelligently coupling retrieval and generation, RAG not only fills in the factual gaps of large language models but also marks a foundational advance in creating AI systems that can continuously learn and provide up-to-date, trustworthy answers.
Key Benefits of RAG for Intelligent Agents
Retrieval-Augmented Generation (RAG) represents a breakthrough in how intelligent agents access and use information. By merging cutting-edge retrieval mechanisms with generative AI models, RAG offers a range of advantages that significantly enhance the capabilities of AI-driven systems. Below, we’ll delve into the core benefits and illustrate why RAG is foundational for the next generation of agentic AI.
Enhanced Contextual Understanding
Traditional language models are often limited by fixed knowledge cutoffs and cannot “know” anything beyond their last training data snapshot. RAG transforms this limitation by allowing agents to dynamically retrieve up-to-date information from vast external sources. For instance, a customer support chatbot powered by RAG can pull the latest help documentation or product FAQs directly from the web, ensuring answers remain current and relevant. This capability is invaluable in industries like healthcare or finance, where real-time accuracy is paramount.
Reduced Hallucination and Increased Reliability
Generative models, while powerful, can sometimes “hallucinate”—generating plausible-sounding but inaccurate information. By incorporating real-time or recent data retrieval, RAG-based agents ground their responses in verifiable sources, significantly reducing this risk. According to Microsoft Research, this approach ensures that users receive reliable, factual answers, backed by references that can be independently verified. This increase in reliability is especially critical for enterprise applications and academic research.
Scalable Knowledge Integration
As knowledge grows across digital repositories, the ability of an agent to integrate information from diverse, continually expanding databases becomes essential. RAG models can seamlessly retrieve and synthesize data from multiple sources—including internal company documents, academic journals, and public datasets—making them ideal for tasks such as legal discovery, technical support, and scientific research. For example, a legal AI assistant using RAG can automatically cite statutes or case law from government databases, as described in detail by Google AI Blog.
Improved Personalization and Adaptability
Intelligent agents often need to tailor their responses based on user preferences, organizational policies, or context-specific data. RAG empowers agents to dynamically fetch and leverage user-specific or context-aware information, enabling more personalized interactions. Imagine an AI tutor drawing relevant examples from recent scientific discoveries or current events, as highlighted by Nature—demonstrating high adaptability across diverse use cases.
Rapid Problem Solving and Efficiency Gains
By bridging retrieval with generation, RAG-powered agents can assemble comprehensive answers in seconds, significantly reducing research and response times. For instance, in customer service, RAG accelerates resolution by fetching top-rated solutions from knowledge bases, guiding users more efficiently. This efficiency translates to cost savings and improved user satisfaction, as described in a comprehensive study from McKinsey & Company.
These multifaceted benefits make RAG not just a useful enhancement, but the backbone of truly intelligent, agentic AI—capable of operating with accuracy, adaptability, and efficiency in real-world environments.
Common Challenges and Solutions in Implementing RAG
Implementing Retrieval-Augmented Generation (RAG) at scale unlocks powerful capabilities for agentic AI, enabling systems to reason, recall, and respond with contextually relevant information. However, adopting RAG isn’t without hurdles. From data pipeline complexities to latency issues and evaluation difficulties, enterprises and developers face a range of technical and operational challenges. Let’s delve into the most common issues you might encounter and actionable solutions to overcome them.
Ensuring Data Quality and Consistency
RAG systems depend heavily on the quality and freshness of the underlying retrieval dataset. Inconsistent, outdated, or biased data can lead to unhelpful or even erroneous generations.
- Step 1: Normalize and Standardize Data
Establish rigorous data cleaning and normalization pipelines. This includes deduplication, language detection, and formatting consistency. Google’s guide to data cleaning provides practical techniques for building robust preprocessing pipelines. - Step 2: Maintain Continuous Data Updates
Automate data ingestion and periodic refreshes so that the retrieval corpus reflects the latest information. Techniques such as scheduled data crawls or integration with live databases can help. - Step 3: Detect and Mitigate Bias
Regularly audit source material for bias and diversify sources to improve fairness and coverage, as discussed in this IBM resource on data bias.
Balancing Latency and Relevance
Agentic AI systems require rapid, high-quality responses. Combining retrieval with generation can hurt performance if not designed efficiently.
- Step 1: Optimize Indexing and Search
Use fast vector databases like Milvus or Pinecone to accelerate similarity searches. Consider sharding or hierarchical indices for large corpora. - Step 2: Precompute and Cache Results
For frequently asked questions or recurring topics, cache the top retrieved documents and their generated responses to minimize retrieval time. - Step 3: Tune Retrieval Granularity
Experiment with chunk sizes (sentences vs. paragraphs) and the number of retrieved documents (k) to balance relevance and speed. Research from Facebook AI Research explores the impact of various retrieval configurations.
Evaluation and Monitoring of Generated Output
Establishing reliable metrics for RAG is tricky. Evaluating both retrieved passages and generated text often involves both automated measures and human judgment.
- Step 1: Use Hybrid Evaluation Metrics
Combine retrieval-specific metrics (like recall@k) with generation metrics (such as BLEU, ROUGE, or BERTScore). Check out this introduction to BERTScore from Google AI for a state-of-the-art approach. - Step 2: Implement Human-in-the-Loop Reviews
Human evaluators should assess fluency, accuracy, and faithfulness. Periodic audits catch subtle errors that escape automatic metrics. - Step 3: Monitor for Drift and Hallucinations
Routinely examine outputs for factual errors, hallucinations, or irrelevant content. Techniques like attribution tracing, where the model links parts of its response to specific sources, are increasingly used (Meta AI).
Security and Privacy Concerns
Data fed into RAG systems may contain sensitive information, making privacy and security conscientious must-haves.
- Step 1: Anonymize and Redact Sensitive Data
Implement entity recognition and redaction to scrub confidential data before inclusion. - Step 2: Enforce Access Controls
Restrict access to sensitive content in retrieval indices using robust authentication and authorization. - Step 3: Adopt Regulatory Best Practices
Follow guidelines for data privacy compliance, such as GDPR and HIPAA. The NIST Privacy Framework outlines effective privacy controls for AI-driven systems.
Tackling these RAG implementation challenges head-on enables the development of more reliable, responsive, and responsible agentic AI systems. By prioritizing data integrity, optimizing infrastructure, rigorously evaluating outputs, and upholding privacy, organizations can fully capitalize on the promise of retrieval-augmented intelligence.
Real-World Applications of RAG in AI Systems
Retrieval-Augmented Generation (RAG) technology is revolutionizing how AI systems interact with vast repositories of data, providing accurate, context-rich, and up-to-date answers. Here’s a look at some of the most impactful real-world applications of RAG, complete with examples, implementation steps, and authoritative references to deepen your understanding.
1. Enterprise Knowledge Engines
In corporate environments, RAG models enable AI assistants to efficiently sift through internal documents, policy manuals, and knowledge bases. Unlike traditional chatbots limited by their training data, RAG-based systems can fetch the latest company policies and generate comprehensive, contextual answers on-demand.
- Example: An HR chatbot equipped with a RAG system can answer complex questions regarding employee benefits by retrieving and summarizing sections from the latest policy documents.
- Steps:
- Index all internal documents using a semantic search system.
- Integrate a RAG model to pull relevant paragraphs based on user queries.
- Use a generative model (like Meta’s RAG) to generate a human-readable answer.
2. Advanced Customer Support
Customer service bots can be drastically improved with RAG. By connecting to external documentation, FAQ databases, and product manuals, these bots provide precise troubleshooting steps and support in real-time.
- Example: Tech support chatbots for electronics companies leverage RAG to resolve issues by fetching troubleshooting guides and warranty information directly from technical databases.
- Steps:
- Collect and preprocess all customer support documents.
- Deploy a document retriever that uses vector embeddings to rank relevancy.
- Implement an LLM to synthesize retrieved information into user-friendly responses, as explored in this foundational RAG paper by Facebook AI Research.
3. Scientific Research and Education
Researchers and students benefit from RAG-powered search engines that go beyond keyword matching to bring back contextually relevant academic papers, articles, and datasets.
- Example: Platforms like Semantic Scholar are integrating similar retrieval-augmented generative models to help researchers quickly summarize findings from thousands of papers.
- Steps:
- Ingest a corpus of peer-reviewed articles and research datasets.
- Apply transformer-based retrieval algorithms to map queries with precise context.
- Use the generative model to create readable research digests, ensuring users receive accurate, citation-rich responses.
4. Legal and Regulatory Compliance
Legal professionals face an overwhelming amount of documentation, case law, and compliance guidelines. RAG models can swiftly surface the most pertinent regulation or precedent during legal research.
- Example: Law firms employ AI systems powered by RAG to extract court decisions and compliance rules from vast legal databases, such as CourtListener or government repositories.
- Steps:
- Integrate large legal databases using retrieval-capable indexing.
- Enable AI agents with document understanding to pull and assemble case summaries or regulation briefs.
- Apply post-processing routines to format legal citations and ensure answer traceability—a technique outlined in the Nature commentary on trustworthy AI.
5. Healthcare Solutions
In healthcare, the need for timely, evidence-based, and reliable information is critical. RAG-powered virtual assistants can recall and contextualize clinical guidelines, drug interactions, and medical literature for practitioners and patients alike.
- Example: Hospitals deploy RAG-enhanced AI assistants to extract treatment protocols from the latest publications indexed in PubMed and summarize key findings for doctors during their workflow.
- Steps:
- Continuously sync medical literature and clinical guidelines into a retrievable database.
- Integrate retrieval-augmented agents into electronic health record (EHR) systems.
- Use generative models to translate technical findings into actionable recommendations for healthcare professionals and patients.
From transforming customer experiences to advancing research and improving healthcare outcomes, RAG is central to the next generation of agentic AIs. Its ability to ground outputs in verifiable, context-specific information sets a new standard for AI reliability and utility. For continued learning, explore the open-source RAG implementations and community developments on the Hugging Face documentation.