Understanding SQL Data Types and Their Role in Migrations
Understanding the various SQL data types is crucial when handling database migrations, especially as they play a pivotal role in how data is stored and manipulated. Migrations often entail transferring data from one database environment to another, and during this process, ensuring that each piece of data is correctly and efficiently mapped is imperative to maintaining the integrity and functionality of your applications.
SQL databases offer a wide array of data types, each designed to optimize the storage of a particular kind of value. These data types can generally be categorized into numeric, date/time, string, and more complex types like JSON or XML. Properly understanding and utilizing these types during migrations can significantly mitigate common migration issues such as data loss, precision loss, and performance bottlenecks.
Numeric Data Types
Numeric data encompasses both integers and floating-point numbers, which are used to store numerical values in databases. Common numeric data types include INT, FLOAT, DECIMAL, and NUMERIC. Each type has specific capacities and uses:
INT: Generally used for integers. When migrating, ensure that the target data type can handle the range of values in your original database. For example, converting aBIGINTinto a smallerINTtype can lead to data truncation.FLOATandDOUBLE: Employed for storing real numbers. These are approximate types, so during migration, switching from a precise type likeDECIMALcould lead to precision loss.DECIMALandNUMERIC: Designed for high precision calculations, particularly useful in financial and scientific data. Ensure these columns are correctly mapped to maintain precision across systems.
Date and Time Data Types
SQL offers several date and time data types such as DATE, TIME, TIMESTAMP, and DATETIME. When migrating, it is vital to match the granularity of these types:
DATE: Stores year, month, and day. Loss of time components can occur if migrating into less granular types.TIMESTAMPandDATETIME: Store both date and time. Be aware of differences in time zone handling between SQL systems, which can cause discrepancies during migration.
String Data Types
String types, including VARCHAR, CHAR, and TEXT, are used for storing character strings. Migrating between SQL systems may pose challenges like differences in character set support and maximum allowable string lengths:
CHARandVARCHAR: Used for fixed and variable-length strings. Pay attention to length specifications during migration to avoid truncation.- Character Set Considerations: Ensure that character encoding (e.g., UTF-8 vs. ASCII) remains compatible to prevent data corruption.
Complex Data Types
With the rise of modern applications, complex data types such as JSON and XML have become prevalent. When migrating:
JSON: The seamless handling of JSON objects between SQL systems often requires bespoke migration scripts to ensure data fidelity.XML: As XML processing could differ between SQL databases, test the migration process to handle any transformations needed effectively.
General Tips for Data Type Migrations
-
Compatibility Testing: Before fully transitioning, conduct thorough compatibility tests on your data types between old and new systems. This includes understanding how each SQL dialect represents data types.
-
Automated Migration Tools: Utilize tools that can automatically translate SQL scripts, but review them manually since automatic tools may overlook specific nuances in data types.
-
Custom Scripts: Sometimes, the level of complexity in data types requires writing custom scripts to handle transformations accurately, ensuring no data loss or corruption.
Understanding SQL data types during migrations is vital to ensure that data integrity, performance, and functionality are preserved. By recognizing potential pitfalls and intricacies associated with different SQL data types, you can devise a more efficient migration strategy, minimizing the risks of errors that typically occur in this process.
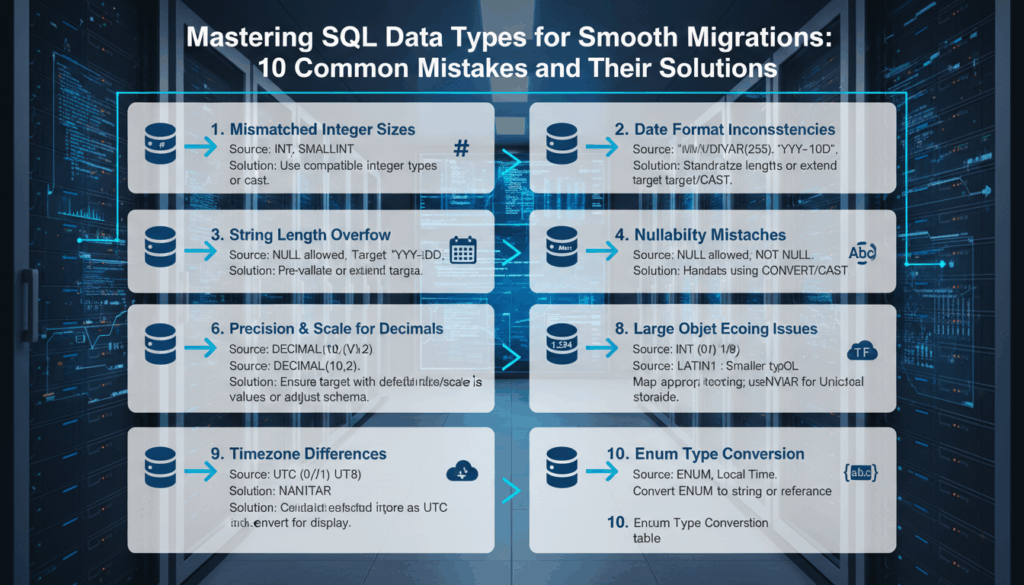
Common Mistake #1: Overlooking Data Type Compatibility
Neglecting to address data type compatibility can lead to significant issues when migrating databases, as mismatched types can cause unexpected behavior, data truncation, or even complete data loss. Such oversights frequently stem from an incomplete understanding of how different SQL systems interpret and store various data types.
When moving data between different database management systems (DBMSs), it is critical to assess the compatibilities of existing data types. Even systems that use SQL standards may implement data types differently. For instance, while both MySQL and PostgreSQL support a VARCHAR type, their approach to maximum length and the handling of that length can differ significantly.
Example: Integer Data Types
One common mistake involves integer types. Consider the scenario where a database uses BIGINT to store large numerical IDs. If the migration target uses a SQL dialect that defaults to INT, the maximum storable number may not suffice, leading to data truncation or overflow errors. Addressing such issues requires mapping BIGINT to an equivalent type able to handle similar value ranges on the target system, such as adjusting to a corresponding BIGINT type if available.
Example: Floating-Point Precision
When dealing with floating-point numbers, precision is a crucial consideration. Suppose the source system uses FLOAT where the destination expects DECIMAL for exact precision. Migrating without handling these differences could introduce rounding errors. The solution is to adjust the data types to maintain precision by recognizing a system that supports arbitrary precision numbers, like NUMERIC.
Example: Character Encoding
String data types often present compatibility challenges, primarily due to varied character set implementations. A database originally using UTF-8 encoding, when migrated to a system with a default ASCII configuration, might result in character corruption or data loss for multilingual strings. Ensuring that both systems align in terms of character set and support similar Unicode encodings can prevent these issues.
Addressing Compatibility Issues
-
Pre-Migration Audit: Start with a comprehensive audit of all data types in use, considering their representations and constraints. This helps identify potential mismatches early in the process.
-
Utilize Compatibility Tables: Many database vendors offer compatibility tables showing equivalent data types across different systems. Reference these tables to ensure a match for both simple and complex data types.
-
Automated Tools and Custom Scripts: Leverage database migration tools that can auto-translate SQL scripts to the target syntax. However, it is essential to validate the results manually since tools may not cover all idiosyncrasies of data type mappings. Sometimes, custom scripts become necessary, especially in cases involving non-standard data types.
-
Testing and Validation: Execute test migrations in a staging environment to verify that all data type conversions operate correctly. This phase should involve querying the new database to check data integrity and performance metrics, confirming that data behaves as expected.
By proactively addressing data type compatibility, the migration process becomes not only smoother but also free from the most common pitfalls, ensuring an efficient and successful data transition without loss or corruption.
Common Mistake #2: Ignoring Precision and Scale Differences
In the realm of database migrations, the failure to consider precision and scale differences in numeric data types can lead to substantial data integrity issues. Precision refers to the total number of significant digits a number can have, whereas scale defines the number of digits that can appear after the decimal point. Mismanagement of these attributes can cause financial or quantitative discrepancies, especially in applications where exactitude is paramount, such as financial calculations or scientific data.
When migrating databases, especially between systems with different SQL dialects, precise management of numeric types like DECIMAL or NUMERIC is critical. These data types are used to store numbers with fixed precision and scale, often employed in situations where small inaccuracies can have significant consequences.
Consider a scenario where one database uses a DECIMAL(10,2) to store currency values, implying that numbers can have up to ten digits, with two of these after the decimal point. If this data is moved to another database system that defaults to DECIMAL(8,2), the resulting truncation might lead to incorrect calculations and potential financial loss if not addressed in advance.
Ensuring Proper Data Type Mapping
To prevent these issues:
-
Thorough Data Assessment: Begin with a complete audit of all numeric fields, documenting the precision and scale requirements of each. It helps to maintain an inventory of these settings to facilitate accurate transition and alignment.
-
Custom Data Type Mapping: Map each numeric type correctly between systems. If a direct match isn’t available, configure the necessary precision and scale manually before initiating the migration.
-
SQL Scripts Adjustment: Modify SQL scripts to explicitly set the correct precision and scale in the target database creation scripts. Adjustments might include changing columns from
FLOATtoDECIMALwith specified precision and scale to maintain consistency. -
Use of Migration Tools: Utilize specialized database migration tools that handle numeric conversions. Tools can automatically adjust column specifications, ensuring that the new database structure can accommodate all values without loss.
Testing and Validation
It is vital to thoroughly test the migrated data to detect any discrepancies early:
-
Migration Simulations: Perform a mock migration using a subset of the dataset. Analyze the outcome for any precision loss by comparing the pre- and post-migration values.
-
Data Validation Queries: Run validation queries to calculate expected outcomes using the precision-critical data, ensuring that results remain consistent with the original dataset.
-
Exception Handling: Implement procedures for handling exceptions when numerical constraints are breached. This might include setting up alerts or logging to capture any conversion issues during migration.
These steps ensure precision and scale differences are managed effectively, thus safeguarding against errors that could undermine the integrity of the data and the decisions based upon it. Migrating numeric data types with due diligence ensures application functionality remains intact, fostering trust in the migrated system’s reliability.
Common Mistake #3: Neglecting Character Set and Collation Issues
Neglecting to address character set and collation issues during database migrations can lead to significant data integrity problems, especially when dealing with multilingual applications or systems requiring localized data support. A character set is a collection of characters that a system recognizes, while collation determines how data is sorted and compared. Both these settings profoundly impact how text data is stored, queried, and retrieved.
When migrating between databases with different default character sets or collations, data corruption can occur. For example, text in one encoding may not be correctly interpreted in another, leading to garbled or lost information. This issue is particularly prevalent when migrating between systems using different SQL dialects or operating under varying regional settings.
Understanding Character Sets and Collations
-
Character Sets: Common character sets include UTF-8, ASCII, and ISO-8859-1. UTF-8 is widely used today due to its ability to encode all possible characters in Unicode, making it ideal for global applications.
– Example: A database using UTF-8 can adequately handle multilingual text data without risk of corruption. However, if migrated to a system defaulting to ASCII, non-ASCII characters may become unreadable. -
Collation: This governs the rules for comparing and sorting characters. Collations can be case-sensitive (e.g.,
utf8_bin) or case-insensitive (e.g.,utf8_general_ci), which will affect search and sort operations.
– Example: If two databases use different collations, a query comparing"apple"and"Apple"might return inconsistent results depending on the case-sensitivity of the collation.
Steps to Address Character Set and Collation Issues
-
Pre-Migration Assessment:
– Conduct a thorough audit of the existing character sets and collations for all text data in the source database.
– Identify any custom collation settings that may not directly translate to the target database system. -
Character Set Alignment:
– If not aligned, explicitly set the target database to use a character set that supports the broad range of characters needed, typically UTF-8 or another comprehensive Unicode standard. -
Collation Strategy:
– Choose a collation that aligns with the application’s functional requirements, ensuring consistent text ordering and comparisons across the system.
– Implement collation settings at the database, table, or column level as needed to account for any special sorting requirements. -
Conversion Tools and Scripts:
– Utilize automated conversion tools that can handle character set conversions, converting text data without losing information.
– Develop custom scripts if specific text transformations are needed to maintain data fidelity during the conversion process. -
Testing and Validation:
– Run tests to verify that text data retains its integrity after migration, especially for non-ASCII content.
– Perform functional testing for applications relying heavily on text processing to confirm sorting and searching behaviors are consistent post-migration.
By giving careful consideration to these character set and collation factors during the planning stages, you can avoid common pitfalls that compromise text data integrity. Proper handling ensures smooth, error-free data migrations and maintains both the functionality and usability of text data across different locales and systems.
Common Mistake #4: Failing to Address Date and Time Format Variations
In the realm of database migrations, handling variations in date and time formats across different systems can be a significant challenge. These formats can differ wildly due to regional settings, SQL dialect variations, or even application-specific customizations. Failure to adequately address these differences can lead to data integrity issues, causing incorrect data retrieval, flawed sorting, or erroneous calculations.
Different SQL systems may have varying granularities and handling mechanisms for date and time data. When migrating from one system to another, mismatches can arise if these differences are not respected.
Understanding the Variations
-
Date and Time Representation:
– Systems may store date and time in formats such asYYYY-MM-DDfor dates orHH:MM:SSfor times. Variations likeDD-MM-YYYYorMM/DD/YYYYare also common, especially in databases that have been customized based on locale-specific needs.
– A database using aTIMESTAMPtype may include timezone data, while another might employ aDATETIMEtype which doesn’t account for time zones at all. -
Time Zone Handling:
– Time zone differences are a critical aspect. Many databases default to UTC for storing timestamps but might display or manipulate data in local time.
– When migrating, these defaults can lead to errors if the receiving system doesn’t adjust for time zones appropriately, leading to off-by-several-hours mistakes.
Steps to Manage Date and Time Migrations
-
Initial Assessment:
– Conduct a comprehensive assessment of the existing date and time formats in your source database. Note all regional settings, and whether dates and times are stored with timezone information. -
Mapping to Target Formats:
– Determine the equivalent data types and formats on the target database system. For instance, ensure that fields usingDATE,TIME, orTIMESTAMPare appropriately mapped, considering whether timezone sensitivity should be preserved. -
Pre-Migration Transformations:
– Where necessary, perform preliminary transformations to align date and time data with the expected format on the target system. This might involve convertingMM/DD/YYYYformats toYYYY-MM-DDif required by the target schema.
– Use SQL functions or scripting languages to adjust time zones on data export, ensuring that no offsets cause disrupted schedules or chronological errors. -
Leverage Database Features:
– Modern database management systems often offer built-in functions to assist with date and time conversions. These might include functions for timezone conversions, or string parsing capabilities to restructure date formats.
– Consider utilizing features likeAT TIMEZONEin PostgreSQL to adjust or standardize time zone handling. -
Testing and Validation:
– Execute thorough testing in a staging environment. This includes validating whether data retrieves as expected, checking sorted lists are correct, and ensuring that any arithmetic involving dates (like age calculations or time differences) is accurately represented.
– Use automated testing scripts to compare pre- and post-migration data sets, ensuring that no shifts in date or time values have occurred due to format discrepancies. -
Exception Handling and Logging:
– Implement logging for any date or time conversion errors encountered during migration. This allows for quick troubleshooting and resolution of any unanticipated issues.
By exhaustively addressing date and time format variations, you not only enhance data integrity in the migrated database but also ensure a seamless transition of all time-sensitive functionalities within your applications. This careful planning and rigorous validation are instrumental in achieving a successful migration free from temporal misalignment challenges.
Common Mistake #5: Mismanaging Null and Default Values
Mismanagement of null and default values is a common pitfall during database migrations, often leading to unexpected behaviors and data integrity issues. Both null values and defaults have specific roles in databases, and mishandling them can cause significant problems, especially when converting data between different environments.
Databases use null values to denote the absence of data, which is distinct from zeros, empty strings, or other default values. Meanwhile, default values are used to automatically initialize a column when no explicit value is provided. Understanding how these elements function and ensuring they are accurately translated during migration is crucial.
Step-by-Step Handling of Null and Default Values
-
Audit of Current Use:
Conduct a thorough audit of the current database to understand where null and default values are being employed. Determine which columns allow nulls and identify those with assigned default values. This audit is essential to know the expected behavior of each column and any dependencies that applications might have on these values. -
Understanding Differences Across Systems:
Different Database Management Systems (DBMS) may handle nulls and defaults differently. For example, some systems might treat empty strings as nulls, or have different methods for applying default values upon record update versus insertion. Familiarize yourself with how each system involved in the migration deals with these situations. -
Mapping Null Values:
During migration, ensure that null values are preserved appropriately. This might involve converting non-standard representations of null (e.g., zero or empty string used as a placeholder) to true null. Be cautious of systems that may convert these values inadvertently. -
Translating Default Values:
Each SQL dialect manages default values in its own way. For instance, a column with aDEFAULT CURRENT_TIMESTAMPin MySQL could have different syntax requirements in PostgreSQL. Explicitly mapping these during schema transformation and ensuring compatibility with the target DBMS is key. -
Pre-Migration Script Adjustments:
Use pre-migration scripts to convert existing values that might cause issues. For instance, changing entries where a default is currently being set to a compatible format recognized by the target system, especially for datetime defaults that may require adjustment to maintain valid entries. -
Database Schema Design Considerations:
Redefine column properties based on the target system’s needs. If a column should still be able to accept nulls or defaults in the target database, you’ll need to explicitly set these properties in the migration script. -
Testing and Validation:
After migration, test thoroughly to validate that all null values and defaults perform as intended. This includes inserting new data to ensure defaults are applied, and querying to confirm that null values are properly handled without causing errors. -
Error Management and Logging:
Implement error-handling mechanisms to capture anomalies that occur due to improper handling of null and default values. This might include logs for when defaults are not applied as expected, or null-related constraints are violated.
By scrupulously managing null and default values throughout the migration process, you can safeguard against common pitfalls that might otherwise lead to data accuracy issues and compromise application functionality. This practice not only ensures a smooth transition but also maintains the reliability and consistency of your database operations.
Best Practices for Ensuring Data Type Consistency During Migrations
Ensuring data type consistency during database migrations is a critical step that underpins the overall success and reliability of the migration process. To achieve this, a strategic and meticulous approach should be adopted at every stage of the migration. Here are some best practices to consider when striving for data type consistency during migrations:
-
Pre-Migration Analysis and Auditing: Before embarking on the migration process, conduct a thorough assessment of the current database schema. This audit should focus on understanding all data types in use, how they interact within the system, and identifying any custom data types or uncommon practices unique to the current environment. Anomalies or non-standard practices should be noted for special attention during migration.
-
Schema Mapping and Planning: Develop a detailed mapping strategy for how each data type in the source database will be translated to the target database. Use compatibility matrices and documentation from both systems to ensure equivalent or compatible data types are chosen. For instance, if moving from a system using the
SMALLINTtype, ensure the target database’sINTor equivalent can accommodate similar values. -
Automated and Manual Tools Integration: Utilize automated tools that facilitate the migration process by providing data type mappings and transformations. However, complement these tools with manual verification to catch any discrepancies or exceptions that might arise due to unique or complex data structures.
-
Custom Scripts for Complex Mappings: Where automated tools fall short, implement custom scripts to handle intricate data type transformations. This is especially important for handling complex types like JSON, where migration scripts must ensure that the nuances of structure and formatting are preserved.
-
Validation and Testing: Conduct exhaustive testing on a smaller, representative subset of data before proceeding with the full migration. This testing should include validation scripts to verify that data types are correctly mapped and function as expected in the new environment. Pay special attention to edge cases that may not be covered by automated tools.
-
Monitoring and Error Handling: Set up monitoring systems to track the migration process in real-time, allowing for immediate identification and rectification of errors related to data type inconsistencies. Establish logging mechanisms to record these events, providing a track record that can be used to refine the migration process.
-
Training and Stakeholder Communication: Equip teams involved in the migration with training on both the source and target systems. Effective communication among stakeholders ensures all aspects of the data migration, including type consistency, are understood and executed properly.
-
Post-Migration Review and Adjustments: After migration, review the database for any issues with data type mapping. Conduct a thorough integrity audit to ensure all data appears as expected. Adjust data type definitions or mappings as necessary to fix any discrepancies found during the post-migration review.
By adhering to these best practices, organizations can seamlessly transition their data between systems with minimal risk of errors or incompatibilities stemming from data type mismatches. This rigorous approach not only safeguards data integrity but also enhances trust in the data migration process and the new system as a whole.



