Clarify business objectives
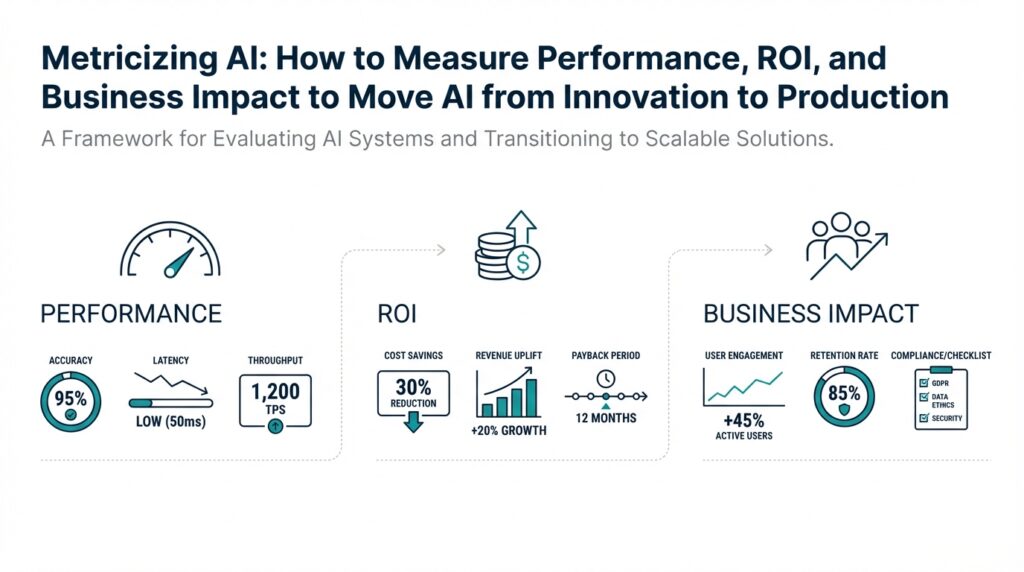
Building on this foundation, the first practical step is turning broad ambitions into concrete, measurable targets that link AI work to business objectives, ROI, and operational performance. If you want your AI project to move from a research proof-of-concept to production, you must define what success looks like in the language of the business: revenue, cost reduction, risk mitigation, or customer experience. That clarity lets you pick the right metrics and design experiments that answer whether the model creates measurable business impact. Without this alignment you’ll optimize the wrong signals and delay realizing ROI from your models.
Start by categorizing objectives into outcome classes: revenue growth, cost avoidance, compliance/risk reduction, and quality-of-experience improvements. For each class, translate the abstract goal into one or two primary KPIs that executives care about — for revenue that might be incremental conversion rate or average order value; for cost it could be full-time-equivalent (FTE) hours saved or per-transaction processing cost. Define time horizons (quarter, year) and acceptable confidence thresholds for each KPI so you can evaluate statistical significance. This makes trade-offs explicit: higher precision might raise conversion but also increase manual review costs, for example.
Next, build a quantitative bridge between model performance and business value so you can ask and answer: How do you tie model metrics to revenue? Use simple, auditable formulas. Example: incremental_revenue = (new_accuracy − baseline_accuracy) × volume_of_events × average_revenue_per_event. If a fraud filter improves true-negative rate from 95% to 98% on 100,000 transactions that average $50 of margin, the expected uplift is (0.03 × 100,000 × $50) = $150,000 before accounting for costs. Framing outcomes this way helps prioritize models by their expected dollar impact instead of abstract metrics alone.
Quantify ROI by including both development and recurring operational costs in your calculation: ROI = (expected_incremental_value_over_period − total_costs_over_period) / total_costs_over_period. Total costs should include data labeling, model training compute, deployment and monitoring engineering time, and ongoing MLOps expenses. Set realistic measurement windows — some models pay back within weeks (recommendation engines), others take quarters (clinical decision support) — and track cumulative ROI over that window. This disciplined accounting prevents optimism bias and surfaces where small model improvements are not worth the ongoing maintenance burden.
Operationalize the success criteria with performance SLOs and guardrails that reflect both model health and user impact. Track latency and throughput when real-time response matters, and monitor concept drift, feature-distribution changes, and data-quality alerts when model decay threatens long-term value. Specify error-cost trade-offs: in a content-moderation system, for instance, a 1% increase in false positives might cost customer goodwill, while a 1% increase in false negatives could create regulatory exposure. Define automated escalation rules so we fix data or model issues before business KPIs degrade.
Align stakeholders by naming a single north-star KPI and clear owners for measurement, experimentation, and operational response. Have the product manager own the business KPIs, the data scientist own model evaluation, and SRE/MLOps own deployment and monitoring SLOs to avoid gaps. When objectives conflict, prioritize by expected business impact per unit of engineering effort and time-to-value; this keeps teams focused on high-leverage work and reduces scope creep.
With objectives clarified and tied to measurable value, you can instrument the right metrics, design meaningful A/B tests, and build monitoring that connects technical performance to business outcomes. Taking this step transforms model evaluation from a purely technical exercise into a business discipline that produces repeatable ROI and demonstrable business impact. In the next section we’ll translate these objectives into an instrumentation and monitoring plan that captures both model performance and the downstream indicators your stakeholders actually care about.
Select success metrics
Building on this foundation, start by choosing a single primary outcome that maps directly to the business KPI executives will judge—this becomes the north-star metric for any experiment or launch. The primary metric should be a lagging, dollar-aligned indicator when possible (for example, incremental revenue per active user or cost-per-transaction), because these connect model changes to ROI and prioritization. Then pick two classes of secondary measurements: model metrics that explain technical behavior and operational/guardrail metrics that protect user experience and compliance. By naming one primary business KPI up front, you avoid chasing noisy model metrics that don’t move the needle.
When you translate business KPIs into measurable signals, separate leading indicators from lagging outcomes so you can iterate quickly without losing sight of impact. Leading indicators are short-latency signals—click-through rate, time-to-first-response, or accepted-recommendation rate—that correlate with the primary KPI and enable fast feedback. Lagging outcomes (revenue, churn, cost savings) validate end-to-end value but require larger samples and longer windows. Ask: How do you know a change is real? Use pre-specified minimum detectable effect (MDE), required statistical power, and a fixed significance threshold before you run an A/B test to prevent post-hoc fishing for wins.
Define the right model metrics for diagnosis, not celebration. For classification tasks, precision and recall remain essential, but when class imbalance or business cost asymmetry exists, convert them into cost-weighted measures (expected cost per decision) so the metric reflects real trade-offs. For ranking problems, don’t rely only on aggregate measures like mean reciprocal rank; include top-k metrics (precision@k, NDCG@k) that reflect the user experience on the most-visible items. Use model metrics as inferential tools: they should guide debugging, feature selection, and labeling prioritization rather than replace your business KPI as the decision criterion.
Include guardrails and fairness metrics as first-class signals alongside performance metrics to avoid negative externalities that kill ROI long-term. Track false-positive and false-negative costs separately, monitor demographic performance slices for distributional shifts, and instrument human review rates when automation reduces manual oversight. Operational metrics—latency percentiles, uptime, inference cost per request—must be measured continuously because they directly affect both customer experience and the cost side of your ROI calculation. We recommend setting SLO thresholds for each operational metric and tying alerts to velocity-based response playbooks.
Design experiments and monitoring with practical sample-size thinking and clear ownership. Pre-calculate sample size using expected variance and your MDE, set a fixed experiment duration (no optional stopping), and register the primary metric and hypotheses before rollout. Assign clear metric ownership: product owns the primary business KPI, data science owns model metrics and experiment analysis, and MLOps owns operational metrics and alerting. When an experiment moves to production, convert the A/B measurement into ongoing monitoring with the same metrics so the evaluation framework remains consistent across lifecycle stages.
As you operationalize measurement, prioritize metrics that are auditable and replicable so stakeholders can validate claims without re-running models. Instrument raw-event logging for every decision, persist model version and feature snapshots, and compute both aggregated and user-level metrics so you can perform backtests and root-cause analysis. This approach makes success metrics actionable: we can trace a revenue shift to a model change, quantify its net ROI, and iterate on the specific technical levers that produced it. Next, we’ll translate these metric choices into an instrumentation and alerting plan that ensures the measurements you trust in experiments are the same ones that govern production.
Define technical performance metrics
Building on this foundation, the first technical deliverable is a compact, actionable metric catalog that maps model behavior to the business KPIs you already named. Start by naming one or two diagnostic metrics per failure mode—these become the signals we monitor continuously and the lenses we use in postmortems. This catalog should include the measurement method, sampling frequency, and the owner responsible for each metric so there’s no ambiguity when an alert fires. By front-loading these choices you convert vague performance debates into repeatable, auditable checks that developers and product owners can rely on.
Translate high-level goals into three metric classes: predictive quality, model health and robustness, and operational metrics that capture runtime cost and user experience. Predictive quality covers familiar measures—precision, recall, F1—and also calibration (how predicted probabilities align with observed frequencies); define calibration as the difference between predicted probability bins and observed event rates and track it with reliability diagrams or Brier score. Model health and robustness include drift detectors, feature-distribution KL divergence, and slice-specific metrics (e.g., precision on a regulatory-sensitive cohort) so you can detect distributional failures early. Operational metrics include latency percentiles, throughput (requests/sec), and inference cost per request; these tie directly to SLOs and the cost side of your ROI calculations.
Convert classification trade-offs into expected-dollar equations so model performance becomes a decision variable, not an abstract number. For example, compute expected_cost_per_decision = FP_rate × cost_FP + FN_rate × cost_FN and compare that to manual-review cost to decide whether to automate. If a fraud model reduces FN_rate by 0.02 on 100,000 transactions where cost_FN = $200, expected_savings = 0.02 × 100,000 × $200 = $400,000 before accounting for inference costs and false-positive fallout. How do you set those cost values? Use historical incident analysis, support-ticket economics, and executive input to make the assumptions auditable and defensible.
Instrumentation design determines whether your metrics are trustworthy and reproducible, so log everything that matters: raw input events, model decisions, model version, feature snapshots, and downstream outcomes. Persist per-request context at write-time and compute both aggregated and user-level metrics so you can re-slice results during debugging; this lets you backtest “what changed” when a business KPI moves. For experiments, precompute sample-size and minimum-detectable-effect (MDE) using observed variance and lock the primary metric and analysis plan before you run the test—then promote the same metric into production monitoring to avoid metric drift between experiment and rollout. For streaming systems, prefer online estimators and exponentially weighted windows for recent performance while keeping long-window baselines for seasonality.
Operationalize the catalog with SLOs, thresholds, and clear escalation playbooks owned by specific teams. Set SLOs that reflect business pain—e.g., 99th-percentile latency < 120 ms for real-time recommendations, or maximum allowed cost_per_decision tied to profit margin—and attach runbooks: who pauses a model, who triages a drift alert, and who communicates to stakeholders. Maintain model performance metrics in dashboards alongside the primary business KPI so teams can trace causality rather than correlation when anomalies appear. Taking this approach turns model evaluation from inference into governance: we can act fast when technical performance diverges and demonstrate the link between model metrics, operational metrics, and business impact as we move toward a production-grade instrumentation and alerting plan.
Quantify ROI and costs
Building on this foundation, the practical step is turning model performance into dollars so you can compare engineering choices against business impact right away. ROI and costs must be front-and-center in that translation: quantify the incremental value your model delivers, then subtract all recurring and one-time expenses so stakeholders can prioritize work by net business impact. How do you structure those calculations so they’re auditable and repeatable? We start by breaking costs into clear buckets and mapping model metrics to unit economics that executives understand.
First, separate one-time development costs from recurring operational costs. One-time costs include labeling, data acquisition, model research and prototyping, and initial training compute; recurring costs cover inference infrastructure, monitoring, MLOps staff time, model retraining, storage, and human-in-the-loop reviews. Express each element as either an upfront expense or an annualized (or per-period) cost so you can amortize investments across the model’s expected lifetime; for example, amortize a $300k model build over three years as $100k/year. That clarity prevents underestimating true TCO and lets you compare apples-to-apples across projects.
Next, convert model performance improvements into dollar value with simple, auditable formulas and a conservative set of assumptions. Define expected_incremental_value = uplift × volume × value_per_event where uplift is the change in the business KPI (e.g., conversion rate delta), volume is the number of decision events, and value_per_event is average revenue or cost avoided. For example, if your recommender increases conversion by 0.3 percentage points on 10M sessions with $60 AOV, expected_incremental_value = 0.003 × 10,000,000 × $60 = $1.8M/year. If annualized total_costs (labeling, training, infra, and 1 FTE MLOps) are $530k, ROI = (1.8M − 530k) / 530k ≈ 2.4 (240%) and payback period ≈ costs / monthly_incremental_cashflow ≈ 3–4 months. Presenting numbers like this, with assumptions exposed, makes trade-offs concrete.
Don’t stop at headline ROI—drill into per-decision economics and sensitivity. Compute cost_per_decision = total_recurring_costs / decision_volume and compare it to expected_value_per_decision = uplift × value_per_event. The break-even volume solves total_recurring_costs = uplift × value_per_event × volume, so volume = total_recurring_costs / (uplift × value_per_event). Run a sensitivity table for uplift ±25% and infra cost ±30% so you can see where the model loses profitability. This analysis tells you whether to invest in model quality, reduce inference cost, or focus on samples and labeling to shift the curve.
Account for hidden and risk-related costs that erode ROI over time. False positives, customer churn from poor UX, regulatory remediation, and technical debt (poorly instrumented features, brittle pipelines) impose real financial and operational burdens; include expected_cost_FP and expected_cost_FN in your equation and factor in monitoring and incident-response overhead. Operational SLOs, automated rollbacks, and guardrails (e.g., hitting a maximum cost_per_decision or human-review threshold) turn these risks into controllable items, keeping ROI durable rather than a one-time spike.
Finally, operationalize these calculations into the measurement system you build next. Persist per-request context, model version, and downstream outcomes so you can recompute ROI after each release; automate periodic TCO refreshes and runbooks that trigger when payback timelines or cost_per_decision drift. By making ROI and costs first-class metrics alongside model metrics and SLOs, we move from anecdote to accountability and enable data-driven decisions about which models to scale, pause, or sunset.
Design A/B tests and baselines
Building on this foundation, the practical question becomes how we actually prove a model moves the needle in production — and that requires well-designed A/B tests and defensible baselines up front. Start experiments by treating the business KPI as the north-star and translate that into a single pre-registered primary metric; doing so prevents chasing transient model metrics that don’t map to ROI. We’ll focus on practical choices—what counts as a baseline, how to randomize, how to size and analyze tests, and the operational steps to move a validated change into running production without losing auditability.
Choosing the right baseline is the first decision and it shapes every downstream calculation. How do you pick the right baseline? Use the current production system as your default control whenever possible because it represents the real-world comparator for stakeholders; when that’s impossible, use a recent, well-instrumented historical period or a synthetic control that matches key covariates. Explicitly document baseline assumptions (time window, seasonality adjustments, and any manual interventions) so stakeholders can audit uplift formulas like incremental_value = uplift × volume × value_per_event. Avoid ad-hoc “best-of” baselines that cherry-pick past peaks or trimmed averages — those inflate apparent gains and break trust.
Define your unit of randomization with intention because unit choice affects interference, statistical power, and business interpretability. Randomize at the user or account level for personalization and retention experiments to avoid treatment contamination across sessions; use cluster randomization (for example, by region or device) when policy, caching, or network effects create interference. Stratify or block on high-variance covariates such as user tenure or pre-period activity to ensure balance and reduce sample size. If interference is unavoidable, include it in the causal model and report cluster-robust standard errors.
Pre-calculate sample size and the minimum detectable effect (MDE) and lock the analysis plan before you start to preserve statistical validity. Use the standard two-sample formula n = ((Z_{1−α/2}+Z_{power})^2 × 2 × σ^2) / MDE^2 to estimate per-arm sample requirements, substituting observed pre-period variance σ^2 and your chosen α and power. Commit to a fixed-horizon test rather than optional stopping, or adopt sequential methods with properly adjusted stopping rules if you must run continuous monitoring. Pre-registration and an immutable experiment manifest prevent post-hoc fishing and keep leadership aligned on what constitutes a win.
Reduce variance and speed learning with covariate adjustment techniques rather than simply increasing sample size. Use CUPED-style adjustments (control variates based on pre-period metrics) or include strong predictors as regression controls in the analysis to shrink confidence intervals and lower required traffic. For ranking or recommendation experiments, consider paired or within-subject designs where each user sees both treatments for comparable items — this often yields substantial variance reduction. Report both unadjusted and adjusted estimates so readers can see raw effects and statistically efficient estimates.
Specify guardrail metrics and a disciplined approach to multiple comparisons before rollout. Name one primary business KPI and treat all others as diagnostics; pre-specify secondary metrics for safety (false-positive rates, manual-review volume, latency percentiles) and perform exploratory slice analyses only after the primary test is decided. When you run many subgroup tests, correct for multiplicity or label results exploratory to avoid spurious claims. Provide confidence intervals and treatment-effect heterogeneity summaries rather than relying solely on p-values.
Operate experiments like production systems: instrument every decision, record model version and feature snapshot, and route traffic through feature flags or canary gates for controlled ramps. Monitor leading indicators closely when the primary outcome is lagged — use correlated short-latency proxies during the test and validate with the ultimate lagging metric after sufficient follow-up. Persist per-request logs so you can recompute ROI, run backtests, and perform root-cause analysis if an uplift evaporates after full rollout.
Taking these steps turns experimentation into a reproducible pipeline where we can justify decisions with auditable baselines, robust statistical practice, and clear ownership. When an experiment demonstrates sustainable net value under your pre-registered analysis, transition the same metrics into ongoing monitoring and SLOs so the evaluation framework remains consistent as the model scales.
Build production monitoring loops
Building on this foundation, the hard part isn’t shipping a model — it’s keeping it reliably valuable in production. How do you keep models delivering ROI after launch? Start by treating monitoring as a closed-loop product feature: you must continuously measure technical signals, map them to the business KPI we already selected, and trigger deterministic responses when those signals cross thresholds. Treating production monitoring as part of the product prevents silent decay and preserves the value that justified the model in the first place.
The central mechanism is a compact set of SLOs and guardrails that bridge model monitoring to business outcomes. Define a handful of SLOs that reflect customer impact (for example, 99th-percentile latency < 120 ms, maximum allowed manual-review rate, and a tolerable expected-cost-per-decision); then instrument alerts that trigger specific runbooks rather than vague noise. For each alert, name the owner, the first responder, and the escalation timeline so an alarm becomes an action. This ownership model ensures alerts map to decisions that protect revenue, cost, or compliance rather than creating alert fatigue.
Instrumentation is the foundation of reliable loops: log every decision with immutable context so you can reconstruct causality. Persist at minimum: request inputs, feature snapshot, model version, prediction and score, inference latency, and downstream outcome (if available). For example, write rows like event = {user_id, timestamp, model_version, features_hash, score, predicted_label, outcome} to your analytics store so you can recompute metrics and backfill slices. Balance retention and cost by keeping full per-request logs short-term for debugging and rolling up aggregated metrics for long-term trend analysis.
Detecting problems requires both statistical tests and business-aware signals, not one or the other. Use drift detection (population stability index, KL divergence, or online CUSUM/EWMA on feature distributions) alongside calibration checks and slice-level breakdowns that matter to regulators or high-value cohorts. Monitor expected-cost equations in parallel — e.g., expected_cost_per_decision = FP_rate × cost_FP + FN_rate × cost_FN — so a small shift in recall that looks acceptable technically doesn’t silently create large dollar losses. Operate short-window estimators for fast warning and longer baselines for seasonality to avoid noisy rollbacks on predictable cycles.
The loop completes when detection automatically triggers corrective actions and human workflows. Automate low-risk responses first: route a portion of traffic to a shadow model, reduce automation rate and fall back to the baseline model, or flip a canary flag to throttle inference volume. For higher-risk failures, trigger a human-in-the-loop workflow: create a ticket with recent per-request logs, notify the model owner, and switch to a defined rollback image. Encode rules as executable playbooks (for example, if alert == high_drift and ROI_impact > $X then throttle=50% and notify(team)) so responses are consistent and auditable.
Finally, tie monitoring loops back into ROI measurement and governance so you learn, not just react. When an alert fires, compute the immediate and projected dollar impact using the same incremental-value formulas you used earlier and record that alongside the incident. Automate periodic audits that recompute payback period and cost_per_decision per model version, and maintain a changelog of retrains, feature changes, and drift incidents so root-cause analysis becomes straightforward. Taking these loops live gives you durable model monitoring that preserves business value and prepares us to translate alerts into operational playbooks and continuous improvement.