Multimodal LLMs Overview
Multimodal LLMs combine language understanding with non-text inputs—images, audio, video, and structured data—so a single model can reason and generate across modalities rather than treating each silo separately. They fuse modality-specific encoders (e.g., vision transformers or audio front-ends) with powerful language decoders or unified transformer backbones, enabling tasks such as image captioning, visual question answering, multimodal summarization, and grounded instruction following. In practice this means the same model can read a diagram, listen to a short clip, and produce a coherent textual explanation or an action plan that references visual and temporal cues.
Training typically mixes large-scale multimodal pretraining (contrastive and generative objectives) with supervised instruction tuning so the model learns alignment and interactive behavior. Key strengths are cross-modal grounding—linking words to pixels or sounds—and improved zero-shot transfer when modalities provide complementary signals. Core challenges are data efficiency, latency, modality imbalance, and ensuring safe, reliable outputs when visual ambiguity exists. For engineers, focus on clear modality prompts, lightweight image/text adapters to reduce compute, and multimodal evaluation (accuracy, faithfulness, and hallucination checks). Small experiments—pairing a frozen vision encoder with an LLM and instruction-tuning on a few hundred aligned examples—often yield practical multimodal capabilities quickly.
Core Architectures and Components
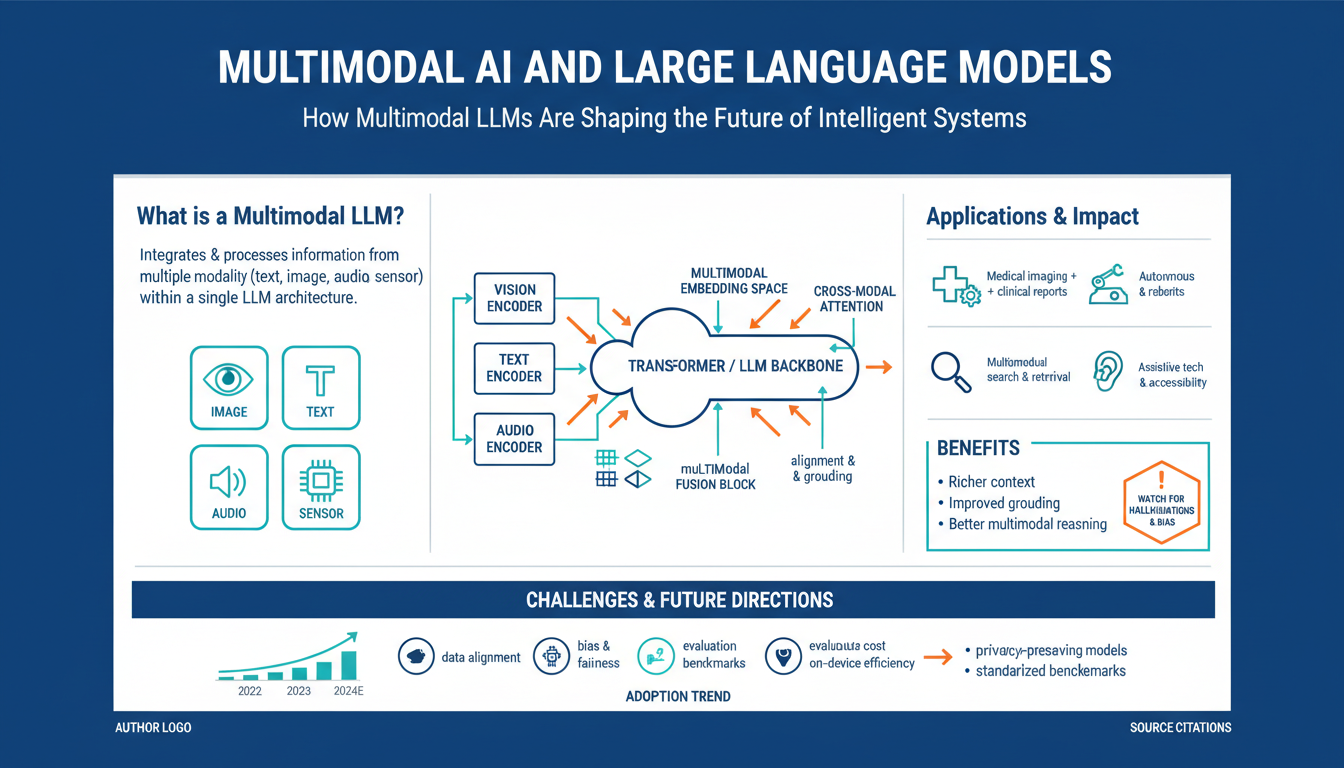
Multimodal systems center on three recurring building blocks: modality encoders, a fusion backbone, and task-specific heads. Images, audio, and structured signals are first converted to embeddings by modality-specific encoders (e.g., vision transformers or CNN front-ends, audio spectrogram encoders, and tabular feature adapters). A lightweight projection or tokenizer maps those embeddings into the model’s shared embedding space so the language model can consume them as “tokens.”
Fusion occurs in either a unified transformer backbone that jointly processes mixed tokens or via adapter layers that inject cross-modal signals into a frozen LLM using cross-attention. Early fusion feeds aligned modality tokens together; late fusion merges independent stream outputs; cross-attention fusion lets the LLM attend to modality embeddings on demand—this is the common pattern for instruction-following multimodal LLMs.
Training mixes alignment objectives: contrastive losses to learn coarse alignment, generative captioning to teach detailed grounding, and instruction tuning to shape interactive behavior. Practical efficiency comes from freezing large components (e.g., a pretrained vision encoder), inserting small adapters or LoRA-style modules, and using sparse or hierarchical attention to cut latency.
Task heads translate fused representations into outputs: autoregressive text decoders, classification/regression heads, or multimodal grounding modules that return spans or pixel regions. Production systems add retrieval, caching, and safety filters (to detect sensitive visual content) alongside calibrated confidence estimates to reduce hallucination risk.
Design tip: prefer modular encoders plus a single fusion interface—this keeps iteration fast, enables swaps for better modality backbones, and balances compute versus capability.
Data, Alignment, and Training
High-quality multimodal models start with disciplined data strategy: prioritize well-aligned, paired examples (image–caption, audio–transcript, video–annotation) and supplement with carefully curated unpaired corpora. Annotate for grounding (region/span links), temporal alignment, and instruction–response pairs so the model learns both what things are and how to talk about them. Balance modalities during sampling to avoid dominant-text bias; use stratified sampling, upweight low-resource modalities, and include hard negatives for contrastive tasks to improve discriminative alignment.
Training should combine complementary objectives. Contrastive (InfoNCE-style) losses produce coarse alignment and retrieval robustness, while generative captioning and masked-modality modeling teach fine-grained grounding and compositional output. Instruction tuning—supervised examples of multimodal interactions—shapes interactive behavior. For interactive safety and preference alignment, apply human feedback loops or scalable automated feedback (e.g., RLAIF-style pipelines) after supervised tuning to reduce hallucinations and improve response quality.
Practical recipes for efficiency: freeze large pretrained encoders (vision/audio) and inject small adapters or LoRA modules into the fusion layers to enable fast iteration. Train with mixed batches and balanced loss weighting; anneal contrastive temperature and progressively increase generative difficulty (curriculum learning). Use cross-attention fusion when you need the LLM to condition on modality tokens on demand; prefer modular encoders plus a clear projection interface to simplify swaps.
Measure alignment with task-specific and safety metrics: retrieval accuracy, caption faithfulness (precision/recall on referenced entities), grounding IoU for spatial tasks, hallucination rate under adversarial prompts, and calibrated confidence. Operationally enforce dataset provenance checks, bias audits, and red-team evaluations; use automated content filters at inference time and human review for high-risk domains. For fast wins, pair a frozen vision encoder with a lightweight adapter and a few hundred–thousand aligned instruction examples, then iterate on loss weights and human feedback to reduce multimodal misalignment.
Instruction Tuning and Fine-tuning
Begin by framing supervised tuning as a behavior-shaping phase: show the model how to accept multimodal inputs, ask clarifying questions, and produce grounded, concise outputs. Use paired instruction–response examples that include modality-specific prompts (e.g., “Inspect the highlighted region and list defects,” image + mask → structured reply). For compute efficiency, freeze large pretrained encoders and fine-tune small projection/adapters or LoRA modules in cross-attention layers so the language backbone learns to condition on visual/audio tokens without costly end-to-end updates.
Mix objectives: continue contrastive or retrieval losses to preserve coarse alignment, and optimize supervised generative loss on instruction pairs for interactive behavior. After supervised tuning, apply preference optimization (human labels or automated raters) to reduce hallucinations and prioritize helpfulness; reward models should evaluate multimodal faithfulness, not just fluency. Curriculum the data: start with single-step captioning and move to complex, multi-turn reasoning across modalities.
Practical knobs: keep adapter learning rates low (e.g., ~1e-4–3e-4), use small LoRA ranks (8–32) to balance capacity and memory, and upweight underrepresented modalities in batches. Augment with synthetic but validated examples for rare scenarios, then verify with human review. Measure success with task-specific metrics (caption faithfulness, grounding IoU, and hallucination rate) plus human preference scores. Instrument safety checks and a small human-in-the-loop review for high-risk classes before deployment.
Prompting and Multimodal Interfaces
Good multimodal prompts tell the model what modality each input is, what part of that input matters, and the exact output format you expect. Lead with context (e.g., “Image + transcript: defect inspection”), then provide the media inline or referenced and a clear grounding cue such as a bounding box, mask, timestamp, or audio segment (for example: “Image [IMG_123] region (x1,y1,x2,y2):”). Constrain outputs with a schema—ask for JSON with named fields, short enumerated labels, or a table—so the model’s responses are easy to parse and validate.
Use few-shot multimodal examples that mirror your real inputs: show an image, the correct region, the prompt, and the desired JSON response. When tasks require reasoning across time or modalities, include explicit temporal markers (“video 00:12–00:18: summarize events”) and cross‑modal anchors (“the red circle in the image corresponds to ‘speaker A’ in the transcript”). If ambiguity is likely, prompt the model to ask one concise clarification question instead of guessing.
Optimize for latency and trust: send downsampled images or cropped regions rather than full-resolution frames, freeze heavy encoders where possible, and require provenance fields (confidence, source snippet). Embed safety and hallucination checks in the prompt by asking the model to flag unsupported claims and return citations to input spans. Iterate prompts with adversarial examples and log failures to refine grounding and reduce hallucination.
Applications, Deployment, and Safety
Real-world use cases range from medical-imaging triage, visual defect inspection, and autonomous-robot perception to AR assistants that combine scene understanding with natural-language guidance, multimodal customer support that ingests screenshots and transcripts, and content moderation that flags unsafe images and contextually harmful language. Because multimodal systems can ground language in pixels and audio, they excel where cross‑modal reasoning or evidence-backed outputs are required—e.g., summarizing a meeting video with slide references or extracting structured findings from inspection photos.
Deployments must balance latency, cost, and trust. Low-latency or privacy-sensitive scenarios favor edge or hybrid edge–cloud inference with quantized/fused encoders and small adapter modules; large-scale inference benefits from model sharding, batching, and asynchronous pipelines. Design APIs to accept modality metadata (bounding boxes, timestamps, source hashes) and return schema-constrained outputs with provenance and calibrated confidence. Use frozen backbones plus lightweight adapters or LoRA for iterative updates, and employ canary releases, A/B testing, and continuous monitoring for performance drift and hallucination rate. Instrument logging, input sampling, and automated replay to reproduce failure cases.
Safety must be engineered end-to-end: filter or redact sensitive inputs, require explicit consent for private media, and block known unsafe content with specialized detectors. Reduce hallucinations by grounding responses in retrieval or input spans, returning uncertainty estimates, and constraining formats (JSON schemas). Add human‑in‑the‑loop review for high‑risk decisions, run adversarial and red‑team evaluations, and maintain audit trails for model outputs and training data provenance. Operationalize access controls, rate limits, and privacy-preserving training/finetuning practices (e.g., dataset curation, differential-privacy techniques) to reduce leakage and align behavior to legal and ethical requirements.



