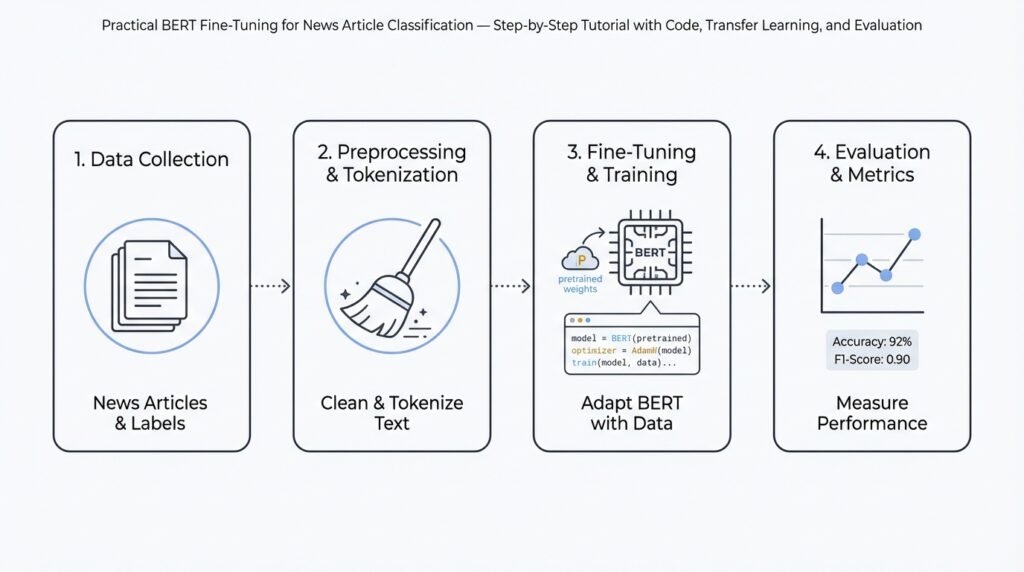
Prerequisites & Environment Setup
Building on the high-level motivation for transfer learning in our previous section, we first make the local or cloud environment predictable so BERT fine-tuning for news article classification behaves the same across machines. Start by choosing a Python runtime that matches the current ecosystem: modern Hugging Face tooling requires Python 3.10 or newer, so pick 3.10–3.12 to avoid subtle compatibility issues when installing transformers and related packages. This upfront decision prevents later dependency conflicts and speeds iteration when you experiment with different pretrained checkpoints and evaluation metrics. (pypi.org)
Decide early whether you’ll run on CPU, a single GPU, or multi-GPU nodes because CUDA, drivers, and PyTorch builds must match. For reliable performance and broad community support, target a recent PyTorch 2.x release (2.7/2.8 or later) with the CUDA toolchain that matches your GPU drivers; these 2.x releases include important compiler and distributed-training improvements we’ll rely on during multi-device fine-tuning. Make sure system GPU drivers and CUDA toolkit versions align with the PyTorch binary you install to avoid runtime errors during torch.cuda initialization. (pytorch.org)
Create an isolated environment to keep experiments reproducible: use virtualenv, venv, or Conda environments and pin dependencies with a requirements.txt or environment.yml file. We recommend creating a new environment per project, installing via pip where possible, and recording exact package versions with pip freeze or poetry lock files; this makes it trivial to reproduce a result months later or on CI. How do you make sure your environment is reproducible and GPU-ready? Automate the build: a small shell script that creates the env, installs the pinned wheel for torch (matching CUDA), then installs transformers and other libs minimizes manual mistakes.
Install the core Python packages next: transformers (we’ll use the v5.x client API), torch (matching your CUDA runtime), datasets (for dataset loading and streaming), accelerate (for simple distributed and mixed-precision workflows), and tokenizers/sentencepiece for some pretrained tokenizer formats. Transformers v5.1.0 is the current stable release at the time of writing, and transformers packages now require Python >=3.10; pinning to the matching release avoids breaking API changes while you follow this tutorial. Also pin sentencepiece to a recent stable wheel (for example, 0.2.1) when you need to train or load sentencepiece-based tokenizers. (pypi.org)
Prepare storage, data access, and credentials before training to avoid mid-run interruptions: allocate fast local NVMe for caching tokenized datasets, or configure a cloud-backed file system when training on ephemeral instances. If you’ll pull models or datasets from the Hugging Face Hub, create and export an HF_TOKEN in your environment so scripts can download models non-interactively and push artifacts after evaluation. For large news corpora, prefer streaming dataset APIs (they minimize RAM usage) and shard your preprocessing so tokenization and augmentation are parallelizable across CPU cores; this reduces wall-clock preprocessing time before each experiment.
Finally, add lightweight tooling for observability and reproducibility: set up a single-run script that seeds torch, numpy, and Python random with logged seed values, enable mixed precision with torch.cuda.amp or accelerate for faster throughput, and capture environment metadata (Python, torch, transformers versions) at the start of each run. These small practices make comparisons between different BERT fine-tuning runs meaningful and let us move cleanly into hyperparameter tuning and evaluation in the next section.
Dataset Selection and Preprocessing
Building on this foundation, the single most important decision before you run BERT fine-tuning for news article classification is which corpus and label schema will actually test the behavior you care about. How do you choose and clean a corpus so the model generalizes to new publishers and later dates? Start by defining the task precisely: are you assigning one topic per article (multi-class), tagging several labels (multi-label), or predicting tone and bias? This framing drives everything downstream — from how you sample examples to which loss function you’ll prefer during training.
Choose datasets that reflect real-world distributional shifts you expect in production. If your product must handle breaking news, include recent articles that capture shifting vocabulary and named entities; if you care about long-tail topics, prioritize sources that expose rare classes instead of oversampling popular outlets. Record metadata for each item (publisher, publish_date, section, author) and preserve it in your dataset schema because these fields enable source-aware splits and targeted error analysis later. We’ll use those metadata fields to prevent label leakage when we split for validation and test.
Source selection and acquisition require pragmatic trade-offs between scale, freshness, and legal risk. Publicly available corpora can bootstrap experiments, but you’ll often augment them with a controlled scraping pipeline or publisher APIs to fill coverage gaps; keep a manifest with provenance and license info for every file. During ingestion, canonicalize HTML to plain text, remove navigation and repeated boilerplate, and deduplicate by canonical URL or content hash to avoid training on near-duplicates. Also shard and stream ingestion so tokenization and preprocessing run in parallel across CPU cores, matching the reproducibility patterns we set up earlier.
The core preprocessing pipeline should normalize text while preserving signals useful to BERT. First, clean HTML and expand common contractions, then collapse excessive whitespace with a simple re.sub(r”\s+”, ” “, text) pass. Decide whether to keep headlines and standfirsts as separate fields; for many classification tasks, concatenating headline + body with a special separator token improves signal without increasing truncation risk. For very long articles, adopt a sliding-window or hierarchical approach: tokenize sentences, encode chunks with overlap, and aggregate chunk embeddings via mean or attention pooling rather than arbitrarily truncating the start of the document.
Tokenization and label handling are where many experiments break reproducibility if not cached and versioned. Initialize your tokenizer with tokenizer = AutoTokenizer.from_pretrained(checkpoint) and fix max_length early (commonly 128–512 depending on corpus). Cache tokenized shards to fast local NVMe and record the tokenizer version and normalization flags in your run metadata. For class imbalance, prefer class-weighted cross-entropy or focal loss over naive upsampling when using BERT fine-tuning; these loss-based approaches avoid duplicating long, expensive examples while still biasing gradients toward minority classes. Maintain stratified sampling for small validation sets so metrics reflect class-wise performance.
Finally, split data to mimic deployment failure modes and to stress-test generalization. Use a chronological holdout when the model will see future events, and use source-aware splits (hold out one or more publishers) if you need robustness to new outlets. Always seed your shuffling and log the split logic so experiments are reproducible across machines. With clean, well-documented data, tokenization cached, and splits that reflect real-world drift, we can move on to architecting the fine-tuning run and selecting hyperparameters that actually improve production accuracy on news article classification.
Tokenization and Input Encoding
Building on this foundation, the first real transformation your raw news text undergoes is tokenization and input encoding; get this stage right and the rest of fine-tuning behaves predictably. Tokenization determines the atomic units the model sees, and input encoding maps those units into the numerical tensors BERT expects. If you treat tokenization as an afterthought you’ll see subtle errors: mismatched normalization across training and inference, inconsistent truncation that biases headlines, or unexpected OOV (out-of-vocabulary) behavior when publishers introduce new named entities. How do you make those choices defensible and reproducible?
Start by selecting a tokenizer that matches the pretrained checkpoint and pin its exact revision in your run metadata. Use the same tokenizer class and vocabulary that the checkpoint was trained with (for BERT-style models that typically means WordPiece vocab), because vocabulary and normalization rules (lowercasing, accent stripping, Unicode NFKC) change model token-ID mappings. Initialize with code patterns like tokenizer = AutoTokenizer.from_pretrained(checkpoint, use_fast=True) and record the tokenizer config file alongside your model checkpoint. This prevents silent drift when you rerun experiments weeks later or share artifacts with colleagues.
Decide early on a max sequence length and an encoding strategy that reflects your label signal and compute budget. For short headline+lead pairs, max_length=128 often suffices; for full article classification you’ll commonly choose 256–512 or adopt a chunking approach. Truncation from the start or end matters: headlines usually carry class-discriminative tokens, so prefer keeping the start of the document when classification depends on headline context. If you need to process longer documents, implement a sliding-window tokenization with overlap and aggregate chunk logits or embeddings at inference time rather than truncating arbitrarily.
Concrete input encoding details you must handle in your dataloader: construct input_ids, attention_mask, and—if using pairwise inputs—token_type_ids (segment ids). For single-field classification, token_type_ids can be zeros, but for concatenated headline + body we set token_type_ids to mark the separator boundary so the model can learn cross-segment patterns. Use dynamic padding at batch time with a collator like DataCollatorWithPadding to minimize wasted compute and reduce GPU memory pressure; convert batches to tensors with long dtype and ensure attention_mask uses 1 for real tokens and 0 for padding.
Address rare tokens and domain-specific vocabulary pragmatically. If your news corpus contains frequent publisher-specific terms, named entities, or tokens like ticker symbols, add them to the tokenizer vocabulary and then call model.resize_token_embeddings(len(tokenizer)). That preserves pretrained weights while giving the model capacity to learn new embeddings for those tokens. Be mindful: expanding vocabulary increases the parameter count and requires careful warmup of learning rates for newly initialized embeddings to avoid destabilizing fine-tuning.
Operationalize tokenization by caching tokenized shards and including tokenizer metadata in your experiment artifacts. Persist tokenized datasets as compact binary shards keyed by tokenizer revision and max_length so you can reproduce results exactly and parallelize training across workers without on-the-fly tokenization bottlenecks. When you push models to a hub or store checkpoints, upload the tokenizer config and vocab files together; during inference load the tokenizer first and verify token->id roundtrips on a sample set to catch normalization mismatches early.
Finally, encode your design decisions in experiment metadata and tests so tokenization remains a first-class citizen in reproducibility and evaluation. Add unit tests that assert constant token counts for canonical examples, smoke tests that run your collator end-to-end, and a checklist item: “Did we seed and record tokenizer version?” Taking these steps connects your data split and preprocessing choices from earlier sections to stable model inputs, reduces drift between training and production, and prepares you to tune learning rates and batch sizes in the next stage of fine-tuning.
Load Pretrained BERT Model
Building on the tokenization and environment setup we just covered, the first practical step is to pick and load a pretrained BERT checkpoint that matches your task and compute constraints. We need to be deliberate here because the model checkpoint determines tokenizer compatibility, input normalization, and the embedding space you’ll fine-tune; poor choices cause silent mismatches later. How do you pick the right pretrained checkpoint for a news classification task? Ask whether you need a generic BERT, a domain-adapted news checkpoint, or a multilingual variant, and record that choice in your experiment metadata before you load any weights.
Start by selecting a checkpoint that aligns with your data and performance targets rather than grabbing the largest model you can find. For many news classification workloads, a BERT-base style checkpoint pretrained on web text or an in-domain checkpoint that already saw news-like language often converges faster and needs less training data; if you have publisher-specific jargon, prefer a checkpoint that was further pre-trained on news or financial text. Choose a checkpoint name and optional git-style revision (tag/commit) so you can reproduce the exact weights later, and keep the tokenizer+checkpoint pair together — they are coupled and must be versioned as a unit.
When you load artifacts in code, initialize the tokenizer and model from the same source and map the model to your device immediately to avoid unnecessary memory spikes. For example, call tokenizer = AutoTokenizer.from_pretrained(checkpoint, use_fast=True) and model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=num_labels, torch_dtype=torch.float32, low_cpu_mem_usage=True) (adjust torch_dtype or device_map depending on your hardware). If you’re using the Hugging Face transformers library with limited memory, low_cpu_mem_usage=True and device_map='auto' can reduce peak RAM by streaming layers to devices; record these loader flags in your run metadata so a colleague can reproduce the same loading behavior.
Performance and stability considerations matter during this stage because they shape your fine-tuning loop. For single-GPU runs, move the model with model.to(device) and enable mixed precision with torch.cuda.amp or accelerate for throughput gains; for multi-GPU or memory-constrained instances, prefer device_map and accelerate.launch configurations so layer placement and model parallelism are handled automatically. If you plan to experiment with quantization or 8-bit training to save memory, test a small sample first — quantized weights change numeric behavior and may require smaller learning rates during fine-tuning to avoid divergence.
If you extend the tokenizer with domain tokens (tickers, publisher names, named entities), you must resize the model’s token embeddings immediately after loading. Call tokenizer.add_tokens(new_tokens) and then model.resize_token_embeddings(len(tokenizer)) so the model can learn embeddings for the new entries without altering the pretrained portion. Be mindful that newly initialized embeddings start from random initialization; compensate with a slightly higher warmup or a lower initial learning rate for the embedding parameters so the rest of the pretrained weights are not destabilized during early training steps.
Validate checkpoint integrity and tokenizer round-trips before you begin heavy preprocessing or training. Load a handful of representative articles, run tokenizer(text) then tokenizer.decode(token_ids) and assert the decoded text normalizes back in the expected way; verify that tokenizer.convert_tokens_to_ids and convert_ids_to_tokens round-trip for critical tokens. Also keep a local model cache or a pinned artifact (tarball or HF revision) so you’re not vulnerable to remote changes; recording SHA-like revisions and hashing the downloaded checkpoint file in your run logs makes reproducibility and debugging far easier.
With a correctly loaded model and tokenizer, we can now set up the optimizer, learning-rate schedule, and data collator that will drive stable fine-tuning. Prepare parameter groups (separating newly initialized embeddings and classification heads from frozen pretrained layers if you choose a staged fine-tuning strategy), decide on weight decay exclusions, and seed your training harness before running any optimization. In the next section we’ll translate these loading choices into concrete training hyperparameters and an efficient, debuggable fine-tuning loop that reflects the model and tokenizer decisions you made here.
Fine-Tuning and Transfer Tips
Building on the environment, tokenization, and checkpoint choices we already made, the practical art of BERT fine-tuning and transfer learning for news article classification comes down to controlled parameter updates and robust validation. Start by treating the pretrained encoder and the task head differently: they have different signal-to-noise and often need different learning rates and schedules. How do you choose between aggressive updates and conservative transfer? We’ll show pragmatic patterns you can apply immediately and reproduce across runs.
A reliable first strategy is staged fine-tuning: initialize the classification head and freeze the encoder for a handful of epochs, then unfreeze progressively. Freezing lets you validate that your new head learns meaningful class boundaries before it perturbs pretrained weights. When you unfreeze, use parameter groups so the encoder uses a scaled learning rate (for example, encoder_lr = base_lr * 0.1) while the head uses base_lr; in PyTorch that looks like optimizer = AdamW([{“params”: encoder.parameters(), “lr”: encoder_lr}, {“params”: head.parameters(), “lr”: base_lr}]). This staged approach reduces catastrophic forgetting and speeds convergence on small labeled news sets.
When labeled data is scarce or your domain diverges from the base corpus, prefer lightweight transfer adapters or low-rank adaptation (LoRA) and/or continued pretraining on unlabeled in-domain articles before supervised fine-tuning. Adapters and LoRA let you freeze most weights and learn small parameter additions, cutting GPU memory and hyperparameter sensitivity significantly. Continued pretraining on a corpus of publisher feeds or recent headlines helps BERT internalize evolving named entities and journalistic phrasing; after that, fine-tune on your labeled split for best downstream gains. These methods are especially useful for long-tail categories in news article classification where supervision is limited.
Stability during optimization is not optional—it’s the difference between repeatable experiments and flaky results. Use a conservative starting range for full fine-tuning (commonly around 2e-5 to 5e-5), but set higher learning rates for randomly initialized heads and new token embeddings. Combine a short linear warmup (a few percent of total steps) with a cosine or linear decay scheduler, enable weight decay for non-bias parameters, and clip gradients (e.g., max_norm 1.0) to avoid exploding updates on long articles. If you need larger effective batch sizes, prefer gradient accumulation over increasing per-device batch sizes to keep mixed-precision behavior stable.
Evaluate transfer success with diagnostics that reflect production failure modes rather than overall accuracy alone. Use source-aware splits (hold out publishers) and chronological holdouts so you can see whether your transfer strategy generalizes to new outlets and breaking news. Monitor per-class F1, confusion matrices by publisher, and calibration metrics—news classifiers often overconfidently predict common topics while misclassifying emerging events. Save frequent checkpoints and keep a validation-split rollback policy: if a newly un-frozen layer causes a sudden drop, revert to the last stable checkpoint and reduce the encoder LR or reapply stronger regularization.
Operationalize reproducibility and iterate efficiently by tracking experiment metadata: tokenizer revision, checkpoint SHA, device config, optimizer groups, schedule, and random seeds. Cache tokenized shards keyed by tokenizer+max_length, version any added vocabulary, and tag model artifacts with both the fine-tuning run ID and the in-domain-pretraining revision if you used it. When you’ve validated transfer on source-aware and chronological splits, the next step is mapping these choices into concrete hyperparameter sweeps and an efficient training loop—we’ll translate these strategies into actionable tuning recipes and scripts in the following section.
Evaluation and Error Analysis
When you evaluate a BERT fine-tuning run for news article classification, the metric you pick shapes every downstream decision from hyperparameter search to deployment gating. Start by front-loading evaluation with task-relevant metrics—per-class F1, macro F1, and precision/recall trade-offs—because overall accuracy hides failure modes on long-tail topics and emerging events. As we discussed earlier about source-aware splits and chronological holdouts, your evaluation signal must mimic the production distribution so metrics reflect real-world performance rather than optimistic in-sample numbers.
Choose metrics that map to product impact rather than convenience. For single-label topic assignment, report both macro and micro F1 so you can see whether improvements favor common labels or lift minority classes; for multi-label or hierarchical tagging, prefer example-based F1 and subset accuracy alongside per-label scores. When classes are imbalanced, use macro F1 and class-weighted loss during training so evaluation and optimization align; otherwise you’ll tune toward the majority publisher and miss subtle editorial categories important for downstream routing.
How do you decide which metric to optimize? Ask what downstream action follows a prediction: will a misrouted article trigger human review, or will it be surfaced to users immediately? If false positives are costly, emphasize precision and set higher decision thresholds; if missing a breaking-news tag is worse, tune for recall. Use precision-recall curves and area under the PR curve for imbalanced news corpora, and reserve ROC-AUC for binary subproblems where classes are balanced and costs are symmetric.
Concrete diagnostics make evaluation actionable. Produce a confusion matrix by label and by publisher to detect systematic confusions (for example, business vs. finance or politics vs. opinion). In code, a quick pattern is to compute predictions on the validation set and call sklearn.metrics.classification_report and confusion_matrix, then pivot those results by metadata: group_confusion = df.groupby(‘publisher’).apply(lambda g: confusion_matrix(g.true, g.pred)). This lets you spot whether errors concentrate on one outlet, one author, or on short leads where the headline carries the signal.
Slice-based error analysis reveals non-obvious failure modes because errors aren’t uniformly distributed. Create slices for article length, named-entity density, publication date, and headline/body disagreement; evaluate per-slice F1 and calibration. For example, short articles under 150 tokens often lose context when you set max_length too low, while breaking-news slices may contain many out-of-vocabulary named entities that benefit from continued pretraining. These targeted slices tell you whether to increase sequence length, add domain tokens, or expand your in-domain pretraining corpus.
Calibration and confidence analysis matter for operational use. Compute reliability diagrams and expected calibration error (ECE) to see if predicted probabilities are trustworthy; an overconfident model can silently degrade human-in-the-loop workflows. Apply temperature scaling or isotonic regression on a held-out calibration set and re-evaluate expected utility at different thresholds. Also instrument thresholded flows: route low-confidence predictions to human editors and measure the lift in pipeline precision, which gives you a business-aligned way to trade automation for safety.
Root-cause analysis often uncovers label noise, near-duplicates, or ambiguous annotation guidelines rather than pure model failure. When a confusion is persistent across architectures and random seeds, sample the misclassified examples and inspect annotation consistency: are label definitions fuzzy, or did the annotator miss metadata like paywall text? Fixing the data—clarifying guidelines, deduplicating, or adding canonicalization—frequently yields more reliable gains than small model changes.
Turn analysis into targeted remediation: upweight or augment minority classes, add synthetic named-entity variants, apply adversarial augmentation for headline shuffling, or train a small adapter focusing on problematic slices. Use class-specific decision thresholds informed by calibration to balance precision and recall per label. When you need robustness to publisher drift, schedule periodic fine-tuning on recent unlabeled articles or deploy an ensemble that mixes a stable base model with a fast-adapting adapter.
Taking these steps we’ll connect evaluation to tuning and deployment: instrument per-slice monitoring in production, log calibration statistics, and automate rollback triggers based on slice-level degradation. By treating evaluation and error analysis as ongoing observability rather than a single pre-deployment checklist, you keep BERT fine-tuning for news article classification resilient to distributional drift and better aligned with product risk.