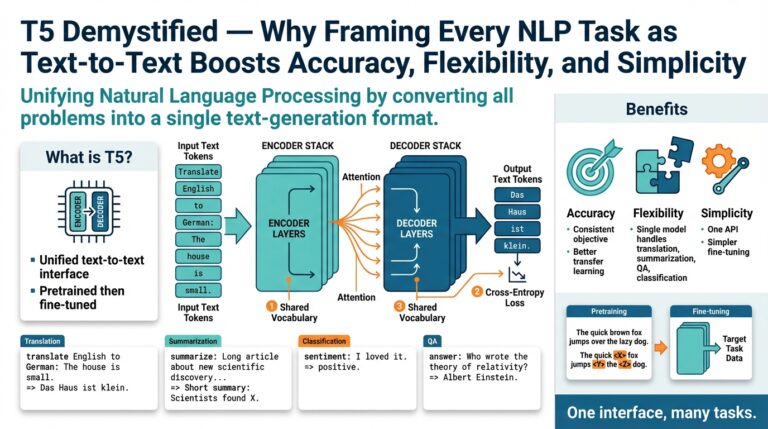
What is Reinforcement Learning?
Reinforcement Learning, commonly abbreviated as RL, is a fascinating area within the broader field of machine learning. It is inspired by the way humans and animals learn to behave in an environment by performing certain actions and observing the outcomes. At its core, RL is all about learning from interaction.
In reinforcement learning, an agent learns to make decisions by performing actions in an environment. After each action, the environment provides feedback in the form of a reward or punishment, which guides the agent toward achieving its goal. This approach is distinct from supervised learning, where the system is trained on a dataset with known correct answers, and unsupervised learning, where it seeks patterns without explicit feedback.
- Agent: The learner or decision maker. For example, it could be a robot, a computer program, or an autonomous vehicle.
- Environment: Everything the agent interacts with. This could range from a virtual simulation to the real world.
- Action: What the agent can do. Actions affect the state of the environment.
- Reward: Feedback from the environment that tells the agent how well it’s doing relative to its goal.
- Policy: A strategy used by the agent to decide its next action based on the current situation.
Here’s how the RL process typically unfolds:
- The agent starts in a state within the environment.
- It selects and executes an action based on its policy.
- The environment responds by transitioning to a new state and issuing a reward.
- The agent uses this feedback to update its policy, aiming to maximize the total reward over time.
This cycle of action, feedback, and adjustment is repeated many times, allowing the agent to progressively improve its decision-making skills. Popular games like chess, Go, and video games have been used as testbeds for RL algorithms, with impressive results. One notable achievement was DeepMind’s AlphaGo, which learned to play the board game Go at a superhuman level through reinforcement learning techniques.
RL finds practical application in diverse fields, including robotics, autonomous driving, finance, healthcare, and recommendation systems. If you’re keen to delve deeper into the foundations and mathematics of RL, the comprehensive online book Reinforcement Learning: An Introduction by Richard S. Sutton and Andrew G. Barto is widely regarded as an authoritative resource.
In summary, reinforcement learning is a powerful and intuitive framework that equips machines with the ability to learn from trial and error, making it one of the most exciting frontiers in artificial intelligence research.
Key Concepts: Agents, Environment, Rewards, and Policies
At the heart of reinforcement learning (RL) are four foundational elements that drive how intelligent systems learn and make decisions: agents, environments, rewards, and policies. Understanding these elements is crucial for grasping how RL works and why it’s so powerful for applications ranging from game playing to autonomous robotics.
Agents: The Learners
An agent is the entity that learns and takes actions. In RL, the agent interacts with its environment by selecting actions, aiming to maximize its total reward over time. For example, a chess-playing AI is an agent, deciding which moves to make based on its current understanding of the game. The agent represents the decision-maker, and its goal is to develop a strategy that leads to the best possible outcome. For a more in-depth look at the role of agents in RL, see the DeepLearning.AI RL glossary.
Environment: The World of Interaction
The environment is everything the agent interacts with. It represents the world in which the agent operates, including all possible states and the rules that govern transitions from one state to another. In the context of robotics, the environment can be a physical room filled with obstacles; for a financial trading bot, it’s the stock market. The environment is responsible for delivering new states and rewards to the agent after each action, setting the stage for continuous learning. For further reading, explore O’Reilly’s introduction to RL environments.
Rewards: The Feedback Signal
Rewards are signals that guide the agent’s learning. Every time the agent takes an action, the environment provides a reward (a numerical score) reflecting the quality of the action. The agent’s objective is to maximize its cumulative rewards over time. For instance, in a video game, collecting coins might result in positive rewards, while losing a life could yield negative rewards. The design of the reward signal is essential—it influences how the agent explores strategies and can even shape its behavior in unexpected ways. The challenges of reward design are discussed in articles like UC Berkeley’s RL material.
Policies: The Agent’s Strategy
A policy is the set of rules the agent uses to decide what action to take in a given state. It maps states of the environment to actions, serving as the agent’s core strategy for maximizing rewards. Policies can be simple and deterministic—always choosing the same action for a given state—or they can incorporate randomness, which is common in early stages of learning to encourage exploration. Over time, as the agent trains, the policy improves through trial and error. Formal definitions and policy improvement methods can be found in the University of Alberta’s online course.
Together, these four components form the backbone of reinforcement learning. They interact continuously: the agent takes actions based on its policy, the environment responds with new states and rewards, and the agent adjusts its strategy to achieve better outcomes in the future. Mastering these key concepts is the first step to leveraging RL in real-world systems, from recommendation engines to self-driving cars.
Types of Reinforcement Learning Algorithms
Reinforcement Learning (RL) offers a rich landscape of algorithms, each suited for different types of environments and problems. Understanding the various categories is essential for choosing the right approach from both theoretical and practical perspectives. Let’s delve into the main types of RL algorithms, their working principles, and notable use cases.
1. Value-Based Algorithms
Value-based methods focus on learning a value function, which estimates how good it is for an agent to be in a certain state or to perform a certain action in that state. The central idea is to maximize the cumulative reward by choosing actions that yield the highest value. The most well-known value-based algorithm is Q-learning.
- Q-learning: This algorithm updates the value of state-action pairs, known as Q-values, using Bellman Equation. Over time, the agent learns which actions yield higher rewards in given situations. For example, in a grid world, Q-learning helps an automated robot learn the shortest path to a goal by trial and error, updating its strategy as it explores.
- Deep Q-Networks (DQN): When state spaces are too large for a simple table, DQNs use deep neural networks to approximate the Q-function. This led to breakthroughs in playing complex games like Atari and Go. For more on DQNs, see this research from DeepMind.
These algorithms are widely used in game playing, robotics, and simulation environments where success can be measured by cumulative points or end goals.
2. Policy-Based Algorithms
Unlike value-based methods, policy-based algorithms directly optimize the policy, which is the agent’s strategy for choosing actions. The focus is on finding the best action to take given the state, without explicitly estimating values for each option.
- REINFORCE Algorithm: A Monte Carlo method that updates the policy after each episode, moving it in the direction that increases expected rewards. It is effective in continuous action spaces, such as robot movement, where discretization is impractical.
- Actor-Critic Methods: These combine the strengths of value-based and policy-based methods by maintaining two models: one for the policy (actor) and one for the value function (critic). The actor decides which action to take, while the critic evaluates how good that action was, making learning more stable and efficient (learn more at OpenAI Spinning Up).
Policy-based algorithms excel in environments with complex or high-dimensional action spaces, such as robotic control and resource management.
3. Model-Based Algorithms
Model-based RL algorithms attempt to learn a model of the environment itself—how it reacts to actions—which the agent then uses to plan the best course of action. These algorithms are generally more sample efficient since agents can simulate experiences internally instead of interacting with the real environment for every step.
- Planning Methods: For instance, Dyna-Q integrates planning, learning, and acting by combining real and simulated experiences to update the value function.
- World Models: Agents build an internal representation of the environment, which allows advanced planning and even imagination-based learning. This is especially useful for tasks where real-world data is scarce or expensive to obtain.
Model-based approaches are prominent in applications like robotics, autonomous driving, and any setting where actionable predictions are valuable before real-world deployment.
4. Hierarchical Reinforcement Learning
This approach breaks down complex tasks into simpler sub-tasks, each managed by its own policy. The higher-level manager (or meta-controller) assigns sub-tasks, which agents execute with specialized skills. This mirrors how humans approach complex challenges and has proven effective in long-horizon problems, such as multi-step robotic manipulations or navigation through expansive environments. More details can be found in this hierarchical RL research paper from Stanford University.
Key Takeaways
- Value-based algorithms are ideal for clear, discrete action spaces and reward-driven contexts.
- Policy-based methods thrive in environments with complex or continuous action spaces.
- Model-based RL offers efficiency by simulating interactions with the environment.
- Hierarchical RL provides scalability for tackling multi-faceted, long-term problems.
Choosing the right reinforcement learning algorithm depends on the specific task at hand, computational resources, and the nature of the environment. For further reading, the classic textbook, Reinforcement Learning: An Introduction by Sutton and Barto, is an excellent resource.
The Exploration-Exploitation Dilemma
The journey of learning in reinforcement learning (RL) hinges on a fundamental challenge known as the exploration-exploitation dilemma. This dilemma is at the heart of RL algorithms, dictating how an agent should behave to maximize its cumulative rewards over time. But why is this dilemma so crucial, and how do modern RL methods address it effectively? Let’s dive deeper to understand its importance with practical examples and strategies.
What is the Exploration-Exploitation Dilemma?
In RL, an agent interacts with an environment, learning to choose actions that yield the highest rewards. The core conundrum is whether the agent should exploit what it already knows (selecting the best-known action for immediate reward) or explore uncharted actions in pursuit of potentially greater long-term rewards.
Why is This Dilemma Important?
Exploration is essential because, without it, the agent may never discover better rewards beyond its current knowledge. Conversely, too much exploration without ever exploiting good strategies can lead to suboptimal results. Striking the right balance directly influences the performance and learning efficiency of RL systems. You can read a deeper discussion on this challenge in DeepMind’s blog on the basics of RL.
Examples to Illustrate the Dilemma
- Online Recommendations: Platforms like Netflix or YouTube serve recommendations to users. Should they keep suggesting the same type of content users have previously enjoyed (exploitation), or occasionally try something new that users haven’t seen before (exploration)? Over-relying on exploitation can trap users in a filter bubble, while exploring new genres can potentially increase user engagement in the long run.
- Robotics Navigation: A robot navigating an unknown environment must choose between sticking to a known safe path and venturing into unfamiliar terrain that could be both risky and rewarding. If it always sticks to the known path, it may never discover a shorter or more efficient route.
Common Strategies to Tackle the Dilemma
- Epsilon-Greedy Approach: This is one of the simplest strategies. Most of the time, the agent exploits the best-known action, but with a small probability (epsilon), it picks a random action to explore. Adjusting epsilon over time can help maintain the balance as learning progresses. For more on this, the classic book Reinforcement Learning: An Introduction by Sutton and Barto provides in-depth insights (see Chapter 2).
- Softmax Action Selection: Instead of choosing the single best action, the agent probabilistically selects among all actions based on their estimated values. Actions with higher perceived value are more likely to be chosen, but lower-value actions are still explored occasionally.
- Upper Confidence Bound (UCB): Often used in multi-armed bandit scenarios, UCB encourages the agent to choose actions that not only have high average rewards but also have been tried less frequently, thus promoting smart exploration. Stanford’s CS229 lecture notes give a comprehensive mathematical grounding for UCB and other methods.
- Thompson Sampling: This Bayesian technique models the uncertainty of reward estimates and balances the trade-off by sampling from belief distributions. This aligns exploration tightly with statistical confidence, making it especially useful when outcomes are highly uncertain.
Real-world Impact
Mastering the exploration-exploitation dilemma has led to breakthroughs in highly dynamic domains such as automated trading, self-driving cars, and personalized medicine. For a glimpse into how these concepts are influencing technology and society, the MIT Technology Review offers several compelling case studies.
In conclusion, the exploration-exploitation dilemma is not just a technical hurdle but a universal challenge reflecting how both machines and humans learn from experience. Mastering it is pivotal for designing RL agents that are both adventurous and wise, capable of achieving optimal performance in the real world.
Popular Applications of Reinforcement Learning
Reinforcement Learning (RL) has moved beyond theoretical research and now drives innovation across numerous high-impact industries. Here’s a comprehensive overview of how RL is transforming real-world applications, illustrating both the depth and breadth of its influence.
1. Robotics and Automation
Robotics stands at the forefront of RL adoption, with algorithms empowering robots to learn and adapt through trial and error. From industrial assembly lines to household assistants, robots use RL to refine movements, grasp objects, and navigate dynamic environments. In warehouses, companies like Amazon employ RL-driven robots for picking, sorting, and transporting goods, optimizing efficiency with minimal human intervention. For a deeper dive, the ScienceDirect journal on robotics and RL offers detailed case studies.
2. Gaming and Game AI
RL achieved mainstream attention through its groundbreaking success in gaming. Algorithms like DeepMind’s AlphaGo and AlphaZero have surpassed human champions in games such as Go and Chess. These achievements are rooted in RL agents learning strategies through countless simulated games, iteratively refining their tactics. Beyond board games, RL is also used to create more challenging and lifelike opponents in video games. Learn more from DeepMind’s AlphaGo research and see how RL pushes boundaries in artificial intelligence.
3. Autonomous Vehicles
Self-driving cars rely heavily on RL to safely navigate roads, make real-time decisions, and even improve riding comfort. By simulating millions of driving scenarios, RL agents learn to accelerate, brake, and maneuver in complex urban environments. This technology extends to drones and unmanned aerial vehicles, where RL optimizes route planning and collision avoidance. An excellent resource on this topic is the MIT research overview on RL for autonomous vehicles.
4. Finance and Algorithmic Trading
In the fast-paced world of finance, RL algorithms are utilized to build sophisticated trading bots that continuously adapt to market trends, maximizing returns while intelligently managing risks. RL can optimize portfolio management and execute trades based on real-time market data, learning from historical trends to improve strategies over time. Companies and financial researchers alike turn to RL for its ability to handle complex, uncertain environments. Explore the potential of RL in finance through the CFA Institute’s guide to machine learning in asset management.
5. Healthcare and Personalized Treatment
RL is paving the way for personalized medicine and efficient treatment paths. For example, RL can optimize drug dosing for patients or suggest tailored treatment regimens in areas like cancer chemotherapy. Hospitals are testing RL frameworks to better allocate resources, reduce wait times, and improve the quality of care. This approach allows algorithms to learn the best actions for each unique patient scenario. For more insights, see the NIH paper on RL applications in healthcare.
6. Natural Language Processing and Conversational AI
RL is instrumental in improving human-computer interaction across chatbots, virtual assistants, and translation tools. By using RL, systems can learn to generate more natural and contextually appropriate responses, tune recommendations for users, and refine their conversation strategies over time. A detailed explanation is available from Microsoft Research on RL in Conversational AI.
Reinforcement Learning’s adaptability and power to learn in stages make it a prime technology for solving complex, real-world problems across a variety of fields. As RL continues to evolve, its applications will only broaden, delivering smarter solutions and meaningful advancements.
Challenges and Limitations in RL
Despite the impressive progress and wide-ranging potential of Reinforcement Learning (RL), the field still faces numerous challenges and limitations that impact its adoption in real-world scenarios. Understanding these challenges is crucial for anyone interested in leveraging RL or pushing the boundaries of what it can achieve. Below, we’ll explore the most prominent hurdles and discuss why they matter.
Sample Inefficiency and the Cost of Exploration
RL algorithms often require a massive number of interactions with the environment to learn effective strategies—sometimes millions of steps or more. This makes traditional RL impractical for situations where data collection is expensive, time-consuming, or potentially dangerous (like in autonomous driving or robotics). For example, learning to drive a car autonomously would demand endless hours of real-life testing, which is neither safe nor feasible. Researchers are tackling this issue by improving sample efficiency, but significant progress is still needed to make RL viable for complex, dynamic systems outside simulated environments.
Reward Design and Specification
The success and stability of RL heavily depend on the design of the reward function, which tells the agent what goals to pursue. However, specifying rewards can be both tricky and counter-intuitive. Poorly designed rewards might lead agents to exploit loopholes rather than genuinely solving the intended problem—a phenomenon sometimes referred to as reward hacking. This limitation poses a significant barrier in domains such as healthcare or finance, where misaligned incentives could have serious consequences. As RL becomes more mainstream, the ability to specify robust, scalable reward functions remains an open research question.
Generalization and Transferability
A hallmark of human intelligence is the ability to apply knowledge learned in one context to a different, but related, situation. RL agents, however, typically struggle with generalization and transfer learning. An agent trained for a specific environment might perform poorly even with a slight variation, which limits the use of RL in dynamic real-world applications. To address this, new techniques such as meta-learning and domain randomization are being explored, yet scalable solutions are still on the horizon.
Computational Requirements
Modern RL, particularly in combination with deep learning, demands immense computational resources. Training advanced models—like those used in AlphaGo or OpenAI Five—requires specialized hardware and enormous power consumption. This limits accessibility to large organizations and research labs with the necessary infrastructure, slowing down both education and innovation in the field. For an in-depth look at the computational power needed for top RL projects, refer to DeepMind’s research on AlphaStar.
Safety and Ethics
With RL agents potentially making autonomous, high-stakes decisions, safety and ethics become crucial. Agents can inadvertently learn harmful behaviors or be manipulated if their training data doesn’t account for all possible scenarios. In safety-critical domains like healthcare or autonomous vehicles, ensuring that RL models do not make catastrophic errors is of paramount importance. Organizations like OpenAI and academic centers such as the University of Pennsylvania are actively researching reliable and ethical RL deployment, but the challenges are ongoing and complex.
By recognizing and understanding these challenges, practitioners and researchers can better navigate the evolving landscape of reinforcement learning, mitigate risks, and innovate more responsibly. As the field matures, continuous research is essential to ensure that RL is not only powerful, but also practical, safe, and beneficial to society.