Why use RAG for LLMs
RAG—short for retrieval-augmented generation—and retrieval-augmented generation techniques are the quickest practical lever we have to make LLMs more reliable and factual. If you’ve been frustrated by models inventing confident but incorrect answers, you’re seeing the limits of parametric-only knowledge stored in model weights. Building on this foundation, RAG shifts factual responsibility from the model’s implicit memory to explicit, queryable documents so you can control, update, and audit what the model uses to answer questions.
The core benefit is grounding: when a model conditions its generation on vetted external context, factual accuracy and traceability improve. For engineering teams that ship customer-facing assistants, legal summarizers, or code-audit bots, grounding means you can update a knowledge base and immediately propagate corrections without expensive fine-tuning. Moreover, retrieval lets you keep the LLM small and fast for inference while relying on a separate retrieval stack for freshness and scale, which reduces both compute cost and the surface area for hallucinations.
Mechanically, RAG combines a retrieval pipeline (embeddings, vector search, and optionally reranking) with a prompt-fusion strategy so the LLM composes answers from retrieved passages. For example, a simple pattern is: retrieve top-k docs, build a prompt like: `Context: {doc1}
Answer using only the context: {user_query}`, then generate. This pattern keeps the model’s generation tethered to explicit evidence; similarity search via dense embeddings (e.g., cosine or dot-product) finds semantically relevant chunks, while a lightweight reranker or metadata filter reduces noise before the LLM sees inputs.
In practice, retrieval gives three operational wins that matter to teams: correctness, agility, and observability. Correctness improves because you can require citation and limited scope generation; agility improves because you update indexes instead of retraining; observability improves because you can log which document produced an answer and build QA tests against those sources. For example, a developer support assistant that returns API snippets and links to your internal docs will be measurably more useful and less risky when each answer includes source references and a relevance score.
RAG is not a silver bullet, so you must manage its failure modes proactively. Noisy or outdated documents will still produce plausible-sounding but wrong answers if retrieval returns bad context, and long multi-hop reasoning across many short snippets can still confuse models. Mitigations include conservative prompt templates that forbid invention, retrieval-quality metrics (recall@k and precision on labeled queries), source filtering by trust level, and conservative answer-abstention thresholds tied to retrieval confidence. We also recommend an adversarial test suite that exercises edge cases to reveal when the retrieval layer or prompt fusion leaks.
How do you know RAG actually improves your LLM? Start by measuring accuracy on real queries, citation coverage, and end-user trust signals like escalation rate. Operationalize by tracking where answers came from, running periodic reindexing for freshness, and adding human-in-the-loop feedback so your vector store learns which documents are useful. Taking this concept further, the next section will show concrete evaluation metrics and instrumentation patterns you can adopt to quantify reliability gains and reduce hallucinations in production.
RAG architecture and components
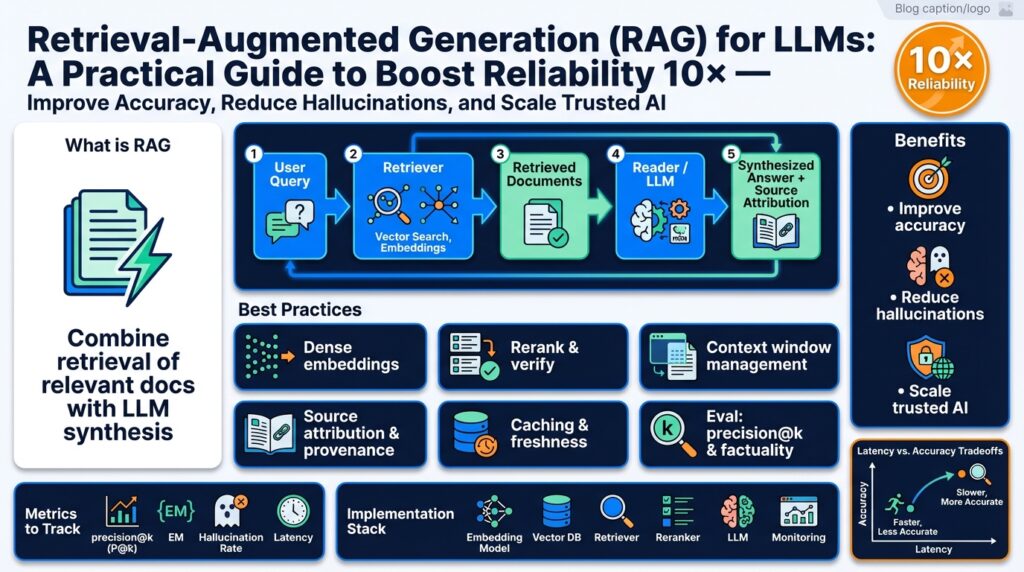
When you design a RAG system the architecture matters as much as the model choice. Retrieval-augmented generation and RAG rely on a pipeline that moves responsibility for facts from model weights to an explicit knowledge layer — typically a vector store populated with semantic embeddings — so we can update, audit, and scale information independently of the LLM. In practice that means thinking in components: ingestion and chunking, embedding generation, vector indexing and ANN search, optional reranking, prompt construction (fusion), the generator, and post‑processing for citation and safety. Front-loading these components lets you reason about correctness, latency, and operational complexity early.
Start by mapping data flow end-to-end so you can prioritize optimizations where they pay off. The ingestion step converts raw sources into canonical documents with metadata and chunk boundaries; embedding generation turns text into numeric vectors; the vector store indexes those vectors and serves nearest-neighbor queries; the retriever returns top-k candidates and a reranker or filter improves precision before the LLM sees context; finally the prompt-fusion layer composes evidence for generation and enforces grounding constraints. How do you prioritize which components to optimize first? Focus on retrieval quality (recall@k) and freshness, since poor retrieval dominates hallucination risk and user trust issues.
Ingestion and chunking are deceptively important for retrieval quality. Choose chunk sizes by document type — API docs and code benefit from smaller, semantically coherent chunks (256–1,024 tokens) while long-form policy text can use larger windows with overlap to preserve context; include deterministic overlap (e.g., 20–30%) to retain sentence continuity across boundaries. Normalize and tag chunks with metadata (source, timestamp, section id, language) so you can filter by trust level or perform role-based access control at query time. A simple pattern: for i in range(0, len(text), stride): chunk = text[i:i+window]; store(chunk, metadata) — batching both tokenization and embedding calls reduces cost.
Embeddings and the vector store are the retrieval backbone and deserve explicit design choices. Select an embedding model whose semantic granularity matches your queries and measure vector dimensionality effects on latency and disk usage; apply L2 or cosine normalization consistently so similarity scores are comparable. Deploy an ANN index (e.g., IVF/PQ, HNSW) that balances recall and query time, shard and replicate indexes for throughput, and ensure metadata-backed filters are supported so you can do semantic+attribute queries. Maintain versioned indexes so reindexing or rolling back to a previous snapshot is operationally safe.
Retrieval, reranking, and prompt fusion determine what the LLM actually conditions on. Combine dense retrieval with lightweight lexical filters for precision in domain-specific vocabularies; when top-k contains noise, run a cross-encoder reranker or a small classifier to reorder candidates. For prompt fusion, prefer conservative templates that bind the model to evidence and include a permissive fallback only when retrieval confidence is high. For example: System: “You are an assistant. Use only the evidence below. Evidence: {doc1}\n{doc2}\nQuestion: {query}. Answer with citations.” This pattern reduces invention and makes generation auditable.
At the generator and post-processing stage we enforce grounding, citations, and abstention policies. Condition the LLM on provenance metadata alongside passages, surface source links and relevance scores in the UI, and implement a confidence threshold tied to retrieval scores for safe abstention. Cache recent queries and batch embeddings for throughput; log retrieval traces and user feedback so we can retrain rerankers and prioritize reindexing. Monitor tail latency and recall degradation — they’re the leading indicators you’ll need to act on.
Operationalizing RAG means automating reindexing, establishing freshness SLAs, and wiring a human-in-the-loop feedback loop for continuous improvement. Instrument recall@k, citation coverage, and downstream accuracy on labeled queries, and map those metrics to SLOs so engineers can prioritize fixes. Building those traces and telemetry now sets up a reliable feedback path; next we’ll quantify these metrics and show instrumentation patterns you can adopt to measure the reliability gains from retrieval-augmented generation.
Choose embeddings and retriever
Choosing the right embeddings and retriever is one of the highest-leverage decisions you make for a RAG system because retrieval quality directly controls grounding and hallucination risk. How do you choose embeddings and retriever for your RAG pipeline? Building on the foundation we covered earlier about chunking and vector stores, start by treating embeddings not as a one-size-fits-all component but as a semantic lens tuned to your domain, query style, and latency budget.
Select an embedding model that matches the semantic granularity of your documents and queries. If your corpus is code, API snippets, or highly structured logs, prefer models fine-tuned on code or technical language; if you index legal, clinical, or policy text, pick models that capture long-form semantics and domain vocabulary. Generate embeddings in batches to amortize tokenizer and model overhead, then normalize vectors (L2 or cosine normalization) before you write them to the vector store so similarity scores are comparable at query time. Experiment with dimensionality: higher-dimensional vectors can encode finer semantics but cost more storage and slightly increase ANN query latency, so benchmark recall@k and throughput as you vary vector size.
Decide between dense, sparse, or hybrid retrievers based on recall and precision requirements. Dense retrievers (semantic embeddings + ANN) excel at paraphrase and intent-matching queries, while sparse retrievers (BM25, TF-IDF) remain strong for keyword-heavy or exact-match needs; hybrid approaches combine both to improve precision on domain-specific jargon. Use an ANN index that supports your operational constraints (HNSW for low-latency, IVF/PQ for large-scale storage efficiency) and tune index parameters to balance recall and query time. When top-k contains noisy hits, add a cross-encoder reranker or a small binary classifier that reranks the top N results using full-context scoring before prompt fusion; a common pattern is retrieve k=50 with ANN, then rerank top 20 to produce the final k=5 evidence passages.
Chunking and metadata interact tightly with embeddings and the retriever—don’t treat them as independent knobs. Smaller, semantically coherent chunks (256–1024 tokens depending on content) help embeddings produce focused vectors that avoid conflating unrelated topics; deterministic overlap (20–30%) preserves sentence continuity across boundaries and improves recall for boundary-spanning queries. Include rich metadata (source, section id, timestamp, trust level) and enforce metadata filters at query time so you can combine semantic similarity with attribute constraints (for instance: recent docs only, or internal policy documents only). Calibrate similarity thresholds empirically: score distributions vary by model, so map cosine/dot ranges to human-labeled relevance and use that calibration to decide when to abstain or escalate.
Plan embedding lifecycle and operational tests before you need them. Version every embedding model and index snapshot in metadata so you can A/B new embeddings against a labeled query set and roll back if recall or latency regress. Reindex on a schedule that matches your freshness SLA and warm up new indexes with a representative query burst; measure recall@k, precision on high-value queries, and downstream generation accuracy rather than relying solely on nearest-neighbor metrics. Remember cost trade-offs: larger embedding models and cross-encoder rerankers improve semantic fidelity but increase compute and inference latency—budget these choices against your SLOs.
Choosing embeddings and a retriever is an iterative process grounded in metrics and domain tests rather than intuition. Start with a pragmatic baseline (domain-appropriate embeddings, ANN index, k=20 retrieval) and instrument labeled queries, human feedback, and retrieval traces so you can converge on the combination that maximizes citation coverage and minimizes hallucination. Taking this approach makes the subsequent steps—reranking strategies, prompt fusion templates, and production instrumentation—far more effective and predictable.
Chunking, indexing, and vector stores
Building on the RAG pipeline we described earlier, effective chunking, careful indexing, and a resilient vector store are the three practical levers that determine whether retrieved evidence actually improves generation. If your chunks are incoherent or your index returns low-recall neighbors, the downstream model will still hallucinate despite high-quality embeddings. We’ll walk through patterns you can adopt in production so you get repeatable retrieval quality, lower latency, and operational controls that let you iterate without re-training the LLM.
Start by treating chunking as a semantic design problem rather than a purely mechanical one. Choose chunk boundaries by the unit of meaning in your corpus: code functions, API sections, FAQ Q/A pairs, or legal clauses each map to different window sizes and overlap strategies. For code and API docs, favor smaller chunks (roughly 256–1,024 tokens) with deterministic 20–30% overlap so you preserve call-site context across boundaries; for long-form policies, use larger windows and index paragraph-level units to keep topic coherence. When you chunk, tag each piece with rich metadata (source, section id, language, timestamp, trust_level) so you can apply filters at query time and combine semantic search with attribute constraints.
Indexing is where retrieval performance and cost trade-offs become concrete. Choose an ANN algorithm that matches scale and latency needs: HNSW often gives very low tail latency for production read-heavy workloads, while IVF/PQ provides compression advantages at extreme corpus sizes. Tune index knobs (ef_construction, M for HNSW, nlist / nprobe for IVF) with a labeled validation set—tune for recall@k and tail latency rather than raw throughput alone. Maintain versioned snapshots of your index so you can roll forward or back after a reindex, and shard or replicate the index to match your throughput SLOs; a small production trick is to warm new replicas with a representative query set before routing real traffic.
Operational vector store practices matter as much as algorithm choice. Enforce idempotent upserts and soft deletes so reingestion and partial reindexing are predictable, and expose a compact provenance schema to the generator (source, section, score, timestamp) so answers remain auditable. Separate hot vs cold storage for older embeddings and evict or compress low-value vectors to control costs, but always keep a mechanism to restore cold content for forensics. Implement rolling reindex jobs that compute diffs (new/changed/deleted documents) rather than full rebuilds when possible, and log retrieval traces (query → candidate ids → scores) to diagnose failure modes and feed reranker training.
Chunking, indexing, and the vector store don’t operate in isolation—embedding lifecycle and monitoring close the loop. How do you detect semantic drift or embedding regressions? Run periodic A/B tests of embedding model versions against a labeled query set and instrument recall@k, downstream generation accuracy, and citation coverage. Calibrate similarity thresholds by mapping cosine/dot distributions to human-labeled relevance so you can implement deterministic abstention rules. Automate alerts on falling recall or rising tail latency and surface counterexamples for human review so rerankers and chunking heuristics can be iterated quickly.
Here is a concise pattern you can adopt in your ingestion pipeline to tie these ideas together:
# pseudo-code: tokenize, chunk with overlap, batch embeddings, upsert
for doc in docs:
tokens = tokenizer.encode(doc.text)
for i in range(0, len(tokens), stride):
chunk_tokens = tokens[i:i+window]
chunk_text = tokenizer.decode(chunk_tokens)
chunks.append({"text": chunk_text, "meta": doc.meta})
embeddings = model.embed_batch([c['text'] for c in chunks])
vector_store.upsert([(uuid(), e, c['meta']) for e,c in zip(embeddings,chunks)])
Taking these operational practices seriously reduces hallucination risk and makes your retrieval layer auditable and maintainable. Building on this foundation, the next step is choosing and validating embedding models and retrievers against the labeled queries that matter most to your product so retrieval fidelity maps directly to user trust.
Mitigate hallucinations with grounding
Even with a solid retrieval-augmented generation setup, models will still produce plausible-sounding fabrications unless we intentionally tether them to evidence. Hallucinations arise when the generator fills gaps in retrieved context with confident invention, so grounding—explicitly constraining outputs to verifiable passages—becomes the operational lever you tune first. Building on the RAG architecture we already described, this section focuses on concrete, repeatable patterns you can apply to reduce hallucinations while preserving useful, informative responses. We’ll emphasize provenance, calibration, retrieval hygiene, and test-driven validation so you can measure progress instead of guessing.
Grounding means more than passing documents into the prompt; it means making factual responsibility auditable and enforceable. In practice that requires (1) surfacing provenance metadata with every retrieved chunk, (2) designing prompts that require citation and restrict generation to evidence, and (3) coupling retrieval confidence to downstream behavior. For customer-facing assistants, legal summarizers, and code-audit tools you’ll want to treat grounding as a guardrail: the system should prefer abstention or a conservative, cited answer over an invented claim. This is why we push provenance into the response payload and your UI—not as an afterthought but as the primary signal consumers use to trust answers.
Make citations explicit and machine-readable so the LLM and downstream systems can only use verified text. When you include source IDs, timestamps, and section anchors with each passage, you enable deterministic citation rendering and easier audits; for example, inject a small provenance header with each chunk like: Source: service-docs/api.md#auth (2025-11-03). Prompt templates should then state an evidence rule such as: “Answer using only the evidence below; if no evidence, respond with ‘Insufficient evidence to answer.’” This pattern converts hallucination prevention from a hope into a contractual behavior the generator can follow and your monitoring can validate.
Calibrate confidence and implement principled abstention instead of brittle thresholds. How do you decide when to abstain? Start by mapping similarity scores from your vector store to human-labeled relevance on a representative validation set, then compute a composite confidence score (e.g., weighted sum of top-k cosine scores, reranker probability, and metadata trust_level). Set two operational thresholds: a soft threshold where the assistant returns a cited but hedged answer, and a hard threshold that triggers abstention or human escalation. Regularly re-evaluate these thresholds as embeddings and index snapshots change so your abstention policy remains aligned with real recall performance.
Improve retrieval hygiene so grounding has a chance to work—bad context still yields hallucination. Use hybrid retrieval (dense + lexical) for domain jargon, run a cross-encoder reranker over the top N hits to improve precision, and keep chunking semantically coherent to avoid context conflation. Maintain versioned indexes in your vector store and test each new index with labeled queries that matter to product correctness; when recall@k drops for critical queries, rollback or retrain rather than hoping the generator will compensate. These choices trade latency and cost for factuality, but the cost of ungrounded answers in production is far higher.
Operationalize adversarial testing and feedback loops that exercise grounding explicitly. Build an adversarial suite of queries that intentionally probe edge cases and ambiguity—examples include ambiguous API defaults, regulatory exceptions, or historical bug behaviors—and assert citation coverage and factual parity with trusted documents. Log retrieval traces (query → candidate ids → scores) alongside generated citations so you can triage failures and surface counterexamples to reranker training. Combine automated tests with lightweight human-in-the-loop review for high-risk domains; continuous feedback will drive faster improvements than model-only tuning.
Taking these measures together shifts hallucination risk from the generator to measurable retrieval and policy knobs. You will trade some latency and engineering complexity for auditability: track citation coverage, downstream accuracy on labeled queries, recall@k, and abstention rates as primary SLOs. Building on this foundation, the next section shows concrete evaluation metrics and instrumentation patterns you can adopt to quantify reliability gains and operationalize continuous improvement for your RAG pipeline.
Scaling, deployment, and monitoring
Scaling, deployment, and monitoring are the operational levers that decide whether your retrieval-augmented generation system survives real traffic and delivers trustworthy answers. If you build RAG without production-ready scaling and observability, retrieval failures, index staleness, or tail latency will silently erode accuracy and user trust. How do you design a deployment that scales search, model inference, and the orchestration glue while keeping citation coverage and recall@k stable? We’ll walk through concrete patterns you can apply in production and the monitoring signals you must track.
Start deployments by separating concerns: serve the retriever, the reranker, and the generator as autonomous components so each can scale on its own. Containerize each service and use an orchestration platform (for example Kubernetes with HPA) to autoscale pods based on meaningful SLIs such as query-per-second for the vector store or GPU utilization for the generator. Pin resource limits, use node pools for GPU and CPU workloads, and prefer model servers that support batching and dynamic batching to improve throughput and amortize GPU cost. This separation also lets you deploy new embedding or model versions using canary or blue-green rollouts without disrupting retrieval traffic.
For the vector store and ANN index, scale with sharding, replication, and read/write separation to meet throughput and availability targets. Shard by document namespace or time window to keep hot partitions small, and replicate read-only shards across availability zones to reduce tail latency. Cache high-frequency results at the service edge and implement a compact in-memory cache for the top-k responses to avoid repeating expensive ANN queries. Tune your ANN parameters (ef_construction, ef_search, M, nprobe etc. depending on implementation) against a labeled validation set so you hit recall@k targets without blowing up latency or memory.
Release management matters for index and embedding lifecycles as much as for model binaries. Version embeddings, index snapshots, and reranker checkpoints in your CI/CD pipeline; run a staged reindex where you warm a new index with synthetic and representative queries before switching traffic. Use canary traffic to compare downstream generation quality (citation coverage, abstention rate, and generated accuracy) between index versions and rollback immediately when regression thresholds are exceeded. Automate diff-based reindexing for incremental changes and schedule full rebuilds only when schema or embedding models change fundamentally.
Instrument retrieval traces end-to-end so you can answer the question “Why did the model make this claim?” in production. Record query → candidate ids → scores → reranker probabilities → fused prompt and generation output in a compact trace that respects PII and privacy rules. Surface key SLIs on dashboards: recall@k on labeled queries, citation coverage, median and 95/99th percentile latency for retrieval and generation, abstention rate, and downstream task accuracy. Tie those SLIs to SLOs and create automated alerts on drift (for example, a sudden drop in citation coverage or a rise in tail latency) so you can triage quickly.
Detect semantic drift with continuous validation and lightweight adversarial tests. Run scheduled synthetic queries, adversarial edge-cases, and high-value user samples against the current index and new snapshots; compute drifting distributions for cosine similarity, reranker scores, and generation confidence. When drift crosses thresholds, trigger pipelines that either reindex, retrain a reranker, or route traffic to a more trusted snapshot. Maintain a human-in-the-loop review queue for high-risk escalations so annotation and feedback directly improve reranker training and indexing decisions over time.
Operationalizing RAG also means attending to cost, security, and reliability trade-offs: enforce RBAC on your vector store, rotate keys for embedding services, and isolate private corpora into access-controlled namespaces. Balance cost and accuracy by selectively using larger cross-encoders only for reranking top-N candidates while keeping dense ANN for first-stage retrieval. Building these deployment, scaling, and monitoring practices into your pipeline turns retrieval quality and grounding from a brittle experiment into a measurable, maintainable capability. Building on these operational foundations, we can now quantify the evaluation metrics and instrumentation patterns you should adopt to prove reliability gains.



