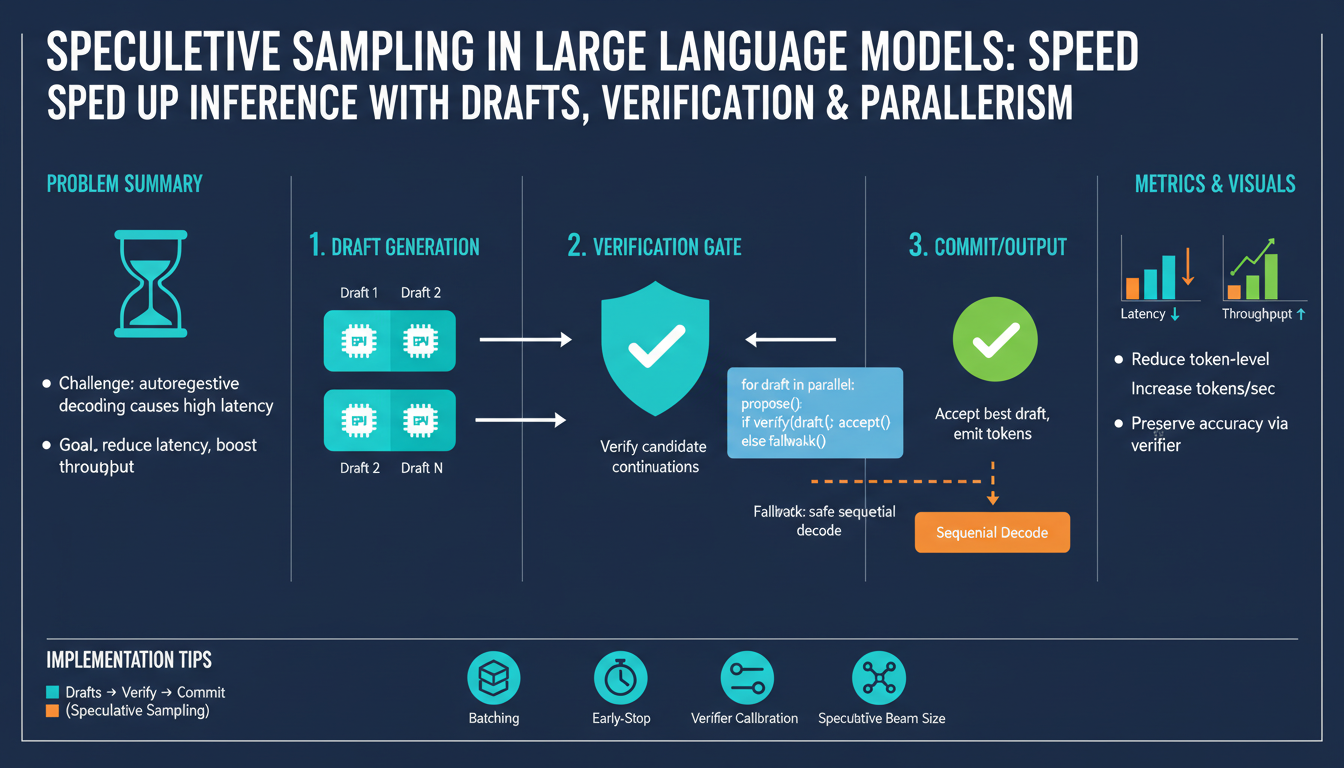
Speculative sampling overview
Speculative sampling speeds up autoregressive generation by splitting work between a small, fast draft model that proposes token candidates and a larger, high-quality target model that verifies and accepts or rejects those proposals. The draft generates short sequences (chunks) quickly; the target evaluates them and either accepts a proposed token (appending it) or rejects and computes its own next token. This lets the heavy target model avoid computing every autoregressive step, converting some sequential work into cheaper parallel verification.
Core mechanics use a probabilistic acceptance test: for each proposed token the target compares its probability to the draft’s and accepts with a chance proportional to that ratio, guaranteeing the final distribution stays faithful to the target model when implemented correctly. Key knobs are draft size and temperature, chunk length k, and the acceptance threshold; larger k raises parallelism but increases rejection risk, which wastes draft proposals and hurts latency.
Practical guidance: choose a draft model with the same tokenizer and a similar conditional distribution to maximize acceptance rate; tune k so acceptance stays high (commonly 0.5–0.9); run draft generation and target verification concurrently to exploit parallel compute; always include a reliable fallback when many rejections occur. When tuned, speculative sampling offers substantial latency and throughput gains with minimal impact on output quality.
Drafting: goals and tradeoffs
The drafting stage should produce proposals that the target model will accept often enough to save work, while being cheap and fast to compute. Design goals are therefore threefold: maximize acceptance probability (so the target rarely has to re-compute), minimize draft compute cost (so proposals are cheaper than full autoregression), and preserve enough diversity so the final output quality and coverage aren’t harmed. These goals conflict: a very small or high-temperature draft is fast and diverse but lowers acceptance; a draft too close to the target yields high acceptance but provides little speedup and may be costly.
Balance these tradeoffs by matching tokenization and conditioning to the target, and by choosing draft temperature and scale to hit a practical acceptance band rather than an extreme. Shorter chunks reduce wasted verification when rejection happens but limit parallelism; longer chunks increase throughput when acceptance is high but amplify the cost of a rejection. Monitor acceptance rate and end-to-end latency rather than draft loss alone: aim for a sweet spot where acceptance stays high enough that the combined draft+verify time beats running the target alone.
Operationally, run drafts and target verification in parallel, implement a simple fallback path when rejections spike, and tune chunk length, draft temperature, and model size per workload (dialogue, summarization, code) because the best tradeoff differs by task.
Selecting a draft model
Pick a draft model by prioritizing acceptance-per-compute rather than raw accuracy. Use a model that shares the same tokenizer and conditioning as the target to avoid tokenization mismatches and to raise per-token agreement; small architectural or vocabulary differences drastically reduce acceptance. Favor architectures optimized for low-latency inference (smaller depth, reduced attention cost, and support for quantization) so each proposed chunk is much cheaper than the target. Match the draft’s distribution to the target via distillation or fine-tuning on the same task data; a slightly warmer temperature increases diversity but lowers acceptance, while a cooler temperature can boost verification success with minor quality tradeoffs. Start with a draft roughly an order of magnitude cheaper than the target (empirically many teams use drafts 5–20× faster) and then sweep draft size and temperature to find the sweet spot where draft+verify latency beats target-alone latency. Measure acceptance rate, end-to-end latency, and wasted verification cost together—aim for a high acceptance band (commonly 0.5–0.9) rather than optimizing draft loss alone. Finally, enable pragmatic optimizations: quantize the draft, use larger batch sizes for draft generation, and implement an adaptive fallback that switches to the full target when rejection rates spike.
Designing verifier acceptance tests
Design the verifier to make acceptance a fast, well-calibrated statistical decision rather than a binary guess. Score each proposed token using the target model’s conditional log-probability and compare it to the draft’s score: accept with probability proportional to the target/draft ratio (clipped to [0,1]) so the final distribution remains faithful to the target. Implement this in log-space to avoid underflow and to allow straightforward thresholds or soft-clipping that trade acceptance for safety.
Prefer per-token checks inside a chunk with an early-stop rule: verify tokens sequentially until one is rejected, append accepted prefix tokens, and fall back to the target for the rest. This limits wasted work when a later token in a chunk has low agreement. For speed, use a two-stage verification: fast approximate screening (top-k or cached logits) to eliminate obviously bad proposals, then compute exact target logits only for candidates that pass the screen. Maintain identical tokenization between draft and target to avoid spurious rejections.
Tune acceptance mechanics using representative workloads. Track acceptance rate, end-to-end latency, wasted-verification tokens, and output fidelity (e.g., token-level agreement and downstream BLEU/ROUGE or human checks). Sweep chunk length, draft temperature, and the clipping/threshold parameter to hit a sweet spot (commonly 0.5–0.9 acceptance). Add adaptive behavior: if recent rejections spike, shorten chunks or cool the draft; if acceptance is high, lengthen chunks for throughput. Log decisions and store confusion counts (accepted vs. what the target’s greedy/top choice would have been) to debug miscalibration and guide retraining or distillation of the draft.
Parallelism, batching and scaling
Speculative sampling becomes effective only when you turn its verification step into parallel work instead of a single slow loop. Run the draft generator and the verifier concurrently: let the draft produce chunks while the target consumes proposals in parallel threads or async streams. Verify tokens incrementally with an early-stop rule so accepted prefixes are appended immediately and you avoid verifying the rest of a chunk after a rejection. This preserves low tail latency even when chunk length k is nontrivial.
Batching is the core throughput lever. Aggregate draft proposals across in-flight requests (or across positions within a request) into large verifier batches, but use a two-stage pipeline: fast screening (top-k, cached logits, or cheap heuristics) to prune candidates, then compute exact target logits only for survivors. Keep and reuse cached key/value states for shared prefixes to avoid recomputing attention. Use micro-batching to balance latency and utilization: small micro-batches for low-latency traffic, larger ones for throughput-oriented workloads, and auto-scale the micro-batch size based on GPU utilization and observed acceptance rates.
Scale horizontally by running multiple verifier replicas or sharding the target with tensor/pipeline parallelism; route drafts to the cheapest available compute (CPU, small GPU, or edge instance) and centralize verification on TPU/GPU clusters. Implement backpressure and adaptive controls that shrink k, cool the draft, or fall back to target-only when rejection rates rise. Continuously measure end-to-end latency, throughput, wasted-verification tokens, and acceptance; tune batch sizes, chunk length, and screening thresholds to the hardware and workload for the best latency/throughput tradeoff.
Implementation steps and benchmarks
Start by measuring a clean baseline: run the target model alone on representative inputs and record P50/P95/P99 latency, tokens/sec, GPU/CPU utilization, cost per 1k tokens, and task-quality metrics (perplexity, BLEU/ROUGE or functional tests for code). Use these as the control for all experiments.
Integrate a draft generator that shares the target tokenizer and prefix KV cache. Make the draft produce fixed-length chunks (k) and expose temperature and size knobs; quantize or run the draft on cheaper hardware to maximize proposal throughput. Implement a thread-safe proposal queue so draft generation and verifier consumption run concurrently.
Implement verifier logic in log-space: compute target log-prob for each proposed token, compute the log-ratio against the draft, clip to [0,1] and accept with that probability. Verify tokens sequentially within a chunk with an early-stop on the first rejection; append accepted prefix tokens and fall back to target autoregression for rejected positions. Add a two-stage path: a cheap fast-screen (top-k / cached logits) to prune obvious rejects, then exact logits for survivors.
Optimize parallelism and batching: run draft and verifier asynchronously, batch candidate tokens across in-flight requests, reuse cached KV states for shared prefixes, and use micro-batching to trade latency for utilization. Add adaptive controls that shorten k, cool the draft, or switch to target-only when recent rejection rates exceed a threshold.
Benchmark by sweeping draft size, temperature, and k. For each config, report acceptance rate, end-to-end P50/P95/P99 latency, throughput (tokens/sec), wasted-verification tokens, compute cost, and downstream quality deltas. Compare against baseline and plot tradeoff curves. Aim for high acceptance (commonly 0.5–0.9) and validate that task metrics remain within an acceptable delta; empirically tuned setups often yield substantial throughput gains (typically 1.5–4×) or meaningful P95 reductions depending on hardware and acceptance. Log decisions and confusion counts to guide further draft distillation or verifier tuning.



