T5 Overview
T5 rethinks NLP pipelines by making “text-to-text” the single interface for every task: you feed the model a textual prompt and it returns text. This front-loaded idea—T5, text-to-text, transfer learning—lets us treat classification, generation, translation, and QA uniformly, which simplifies tooling and improves transfer across tasks. You’ll see this pattern immediately in examples (we’ll show a few) and in how T5 structures pretraining and fine-tuning to maximize reuse of learned representations.
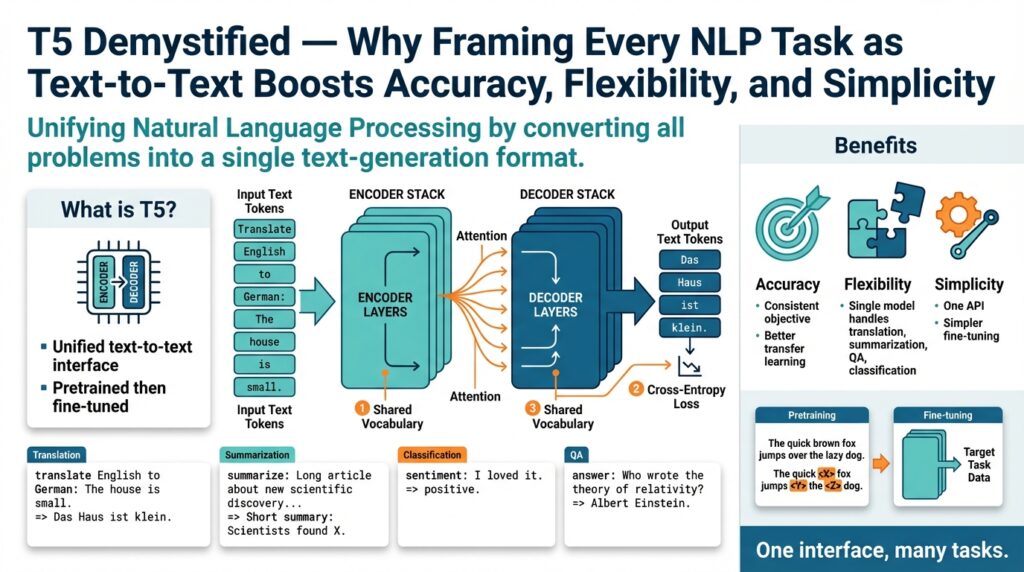
At its core, T5 uses an encoder–decoder Transformer: the encoder ingests the input string and produces contextual embeddings, while the decoder autoregressively generates the output string. An encoder–decoder Transformer is simply the sequence-to-sequence architecture popularized for machine translation, adapted here to handle any textual input and output. Because both input and output are text, tokenization, generation, and scoring become consistent operations you can reuse across pipelines.
The most practical benefit comes from the prompt format: you turn the task into a short instruction plus content, and the model emits the answer as plain text. How do you convert a classification task into text-to-text? For sentiment, you might call the model with "sst2 sentence: I loved the movie" and expect "positive" back; for translation: "translate English to German: The cat sat on the mat." -> "Die Katze saß auf der Matte.". This unified interface makes ensembling, multitask fine-tuning, and zero-shot prompting straightforward because we no longer need separate heads or bespoke label encodings.
Pretraining in T5 is centered on a denoising objective: we corrupt spans of text and train the model to reconstruct the missing pieces, which teaches both generation and contextual understanding. A denoising objective (a type of self-supervised learning) encourages the encoder to build stable context and the decoder to practice fluent generation—skills that transfer to downstream tasks. When you fine-tune, you typically give the same prompt-style inputs and supervise text outputs, which means the model’s learned generative skills accelerate learning on classification, extraction, or summarization tasks.
In real-world systems, the unified format reduces engineering surface area. Instead of maintaining separate classification heads, token-classifiers, and summarizers, you maintain a single inference wrapper that formats prompts and parses generated text. For instance, a single T5 deployment can handle internal document summarization, email intent classification, and multilingual translation by swapping short task prefixes—this reduces model churn, simplifies A/B testing, and aligns monitoring metrics around textual fidelity rather than bespoke head accuracy.
There are practical trade-offs to keep in mind when you adopt T5. Larger T5 variants scale accuracy but increase latency and cost, so pick a model size that balances throughput and performance for your SLA. You’ll also need robust prompt design and output parsing rules—generation introduces variability, so canonicalizing outputs (e.g., mapping synonyms to labels) keeps downstream consumers deterministic. Finally, multitask fine-tuning improves sample efficiency but can require careful curriculum design to avoid negative transfer between unrelated tasks.
Taking this concept further, we can treat prompt engineering, dataset formatting, and evaluation as first-class engineering concerns rather than ad-hoc steps. Building on this foundation, the rest of the post will dive into how text-to-text framing changes loss functions, model selection, and deployment patterns so you can apply T5-style transfer learning in production. By keeping interfaces textual and consistent, we gain flexibility without sacrificing accuracy—and we give you a single, maintainable pathway to support diverse NLP capabilities.
Text-to-Text Framing
T5’s power comes from one simple but disruptive decision: make every input and every output plain text. By front-loading the interface as text-to-text, we get consistent tokenization, a single generation pipeline, and reusable prompt engineering patterns that accelerate transfer learning across classification, extraction, and generation tasks. How do you convert a heterogeneous set of NLP problems into a single, maintainable API that scales from production classifiers to abstractive summarizers? The text-to-text approach answers that by treating everything as an instruction plus content, with the model producing a textual answer you can parse or display.
The technical payoff appears in the model internals. When you use an encoder–decoder Transformer like T5, the encoder produces a shared contextual representation and the decoder practices fluent token-level generation during both pretraining and fine-tuning. That shared representation is why transfer learning works so well here: weights learned reconstructing corrupted spans help the decoder generate labels, spans, and full documents at inference. Because input formatting, token vocabulary, and decoding mechanics are consistent, you can reuse the same batching, mixed-precision, and tokenizer pipelines across tasks and reduce engineering complexity.
Prompt design becomes part of your API contract rather than an afterthought. Define short task prefixes and canonical output forms — for instance, "sentiment: <text>" that must map to "positive"|"neutral"|"negative". Enforce canonicalization by constraining the decoder to emit one of a small whitelist or by post-processing free text into labels using deterministic normalization (lowercasing, punctuation stripping, synonym mapping). If you need structured outputs, encode them as compact JSON-ish strings like {"intent":"book_flight","slots":{"date":"2026-02-14"}} and train the model to match that exact format so downstream parsers remain robust.
Framing everything as text changes how we define loss and multitask curricula. Instead of separate heads with different loss terms, we minimize token-level cross-entropy across diverse targets — label words, spans, or long-form text — in a single objective. That unification makes it straightforward to interleave tasks during fine-tuning and to upweight low-resource tasks by repeating prompt variants or prefixing examples. Be mindful of negative transfer: when tasks conflict, curriculum scheduling or adapter modules help, but the text-to-text interface still simplifies experiment tracking because the output space and evaluation scripts remain consistent.
Evaluation follows naturally from the textual outputs, but you must be explicit about acceptance criteria. For classification, measure exact-match after canonicalization; for extraction, use span F1 computed on normalized tokens; for summarization, rely on ROUGE plus human fluency checks. Because generation is probabilistic, include deterministic decoding in production (greedy or constrained beam) and log raw generations for auditability. Also instrument normalization failures — when outputs fall outside the whitelist — as a distinct monitoring signal so you can retrain with corrected prompts or additional examples.
Operationally, the single text interface reduces deployment surface area but introduces generation-specific trade-offs. Token budgets and latency matter: longer textual answers increase inference time and cost, so compress prompts and prefer short canonical labels when possible. Control variability with beam search, forced tokens, or vocabulary masking for strict outputs, and choose model size based on SLA and throughput. There are cases where a specialized head still wins — extremely low-latency binary decisions or token-level tagging at massive scale — but for most multi-capability services, text-to-text shrinks maintenance and eases A/B testing.
Building on this foundation, we can treat prompt templates, dataset formatting, and evaluation as first-class engineering artifacts rather than ad-hoc tweaks. That shift lets us standardize training recipes, automate canonicalization, and reason about loss functions and model selection consistently across tasks. Next, we’ll examine how the unified interface affects loss engineering and practical model choices so you can optimize accuracy, cost, and reliability in production.
Input Formatting and Prefixes
The single clearest lever you have for predictable T5 behavior is how you format the input string: concise, consistent input formatting and well-chosen prefixes turn an ambiguous generator into an API you can rely on. When you front-load task intent in plain text, the encoder builds the right context and the decoder learns a compact mapping from prompt to canonical output. Because this is a text-to-text model, small changes in phrasing or separator tokens can dramatically alter performance; we treat input formatting as an engineering contract rather than ad-hoc tuning.
A prefix acts as the task contract: a short tag that tells the model what kind of output to produce and which output vocabulary to expect. How do you choose between natural-language prefixes and compact tokens? Use natural-language prefixes during early experiments to capture generalization, then migrate to normalized, low-variance prefixes (e.g., summarize-long: or classify-topic:) when you need strict downstream parsing. We prefer prefixes that are unambiguous, short, and typed consistently across datasets so the model learns a tight association between intent and output distribution.
Structure the body of the prompt so the prefix, separator, and content are deterministic. Put the prefix at the start of the string followed by a single, reproducible separator — newline, ||, or a sentinel token — then the document. For example: summarize-long\nThe quarterly report shows… or extract-address || Shipping information: …. Consistency matters: when you standardize the separator and the order of fields, the encoder’s position embeddings and attention patterns become stable and fine-tuning converges faster.
Design outputs to be easy to canonicalize and validate. Train the model to emit either a small whitelist of label words or a strict JSON-ish compact string like {"intent":"book_flight","date":"2026-02-14"} so downstream parsers can be deterministic. Constrain decoding at inference with vocabulary masking or forced tokens when you require exact labels; alternatively, log free-form generations and normalize them with a deterministic mapping. These choices reduce mismatches between the model’s probabilistic generations and brittle production consumers.
Don’t forget tokenizer and token-budget trade-offs when you engineer prompts. Prefix length consumes encoder capacity, so keep the prefix and instruction lean and move long contextual documents after the separator; sentinel tokens (unique unused tokens) can save token budget and simplify span extraction. Also consider tokenization edge cases: uncommon punctuation in prefixes can split into many subtokens and dilute the signal, so prefer alpha-numeric short tags for production prompts. We find that keeping the prefix short and consistently cased reduces tokenization variance and improves generalization across domains.
When you prepare training data, treat prefix design as part of dataset engineering: include prefix permutations to improve robustness, upweight low-resource tasks by repeating canonical prompt templates, and validate with held-out prefix variants to catch overfitting to phrasing. Monitor two failure modes closely: outputs that fall outside the expected whitelist and prefix drift where the model ignores the instruction and resorts to memorized answers. Building these checks into your training and evaluation pipeline creates a clear path from experimental prompts to reliable production calls, and primes us to discuss loss weighting and model selection next.
Accuracy Benefits
When your classifier or summarizer misses obvious signals, the problem is often inconsistent interfaces and noisy supervision rather than model capacity. T5’s text-to-text framing addresses this by collapsing disparate output formats into a single, learnable mapping—so when we talk about improving accuracy, we mean measurable reductions in label noise, better calibration across inputs, and faster convergence during fine-tuning. Because you present both intent and content as plain text, the model receives a stable training signal that aligns pretraining behavior with downstream objectives. That alignment is why practitioners see accuracy gains when they migrate pipelines to a text-to-text, transfer learning workflow.
The technical reason for improved accuracy starts inside the encoder–decoder: the encoder builds a shared contextual representation while the decoder practices fluent generation at token level. Minimizing token-level cross-entropy on canonical output strings trains the model to score short label words and long-form answers with the same objective, which reduces mismatch between training and inference. For example, teaching the model to output “positive” instead of a one-hot head forces the decoder to allocate probability mass to semantically meaningful tokens, improving calibration for low-frequency or ambiguous examples. This consistent objective is a direct contributor to higher end-task accuracy.
Constrained outputs make your accuracy gains reliable in production. When you canonicalize labels (“positive|neutral|negative”) or train the model to emit compact JSON, you reduce post-processing ambiguity and error propagation downstream. You can further enforce correctness with decoding constraints such as forced tokens, vocabulary masking, or short beams that only allow whitelist tokens; these techniques remove generation variance without degrading the model’s learned representations. For instance, mapping free-form generations to a deterministic label set or using a small constrained decoder for intent classification preserves the benefits of text-to-text while giving you exact-match guarantees where they matter.
Building on the shared-objective idea, multitask fine-tuning amplifies sample efficiency and boosts accuracy for low-resource tasks. When you interleave translation, summarization, and classification examples under the same prompt format, the encoder learns task-agnostic context features while the decoder refines conditional generation patterns. You can upweight scarce tasks by repeating canonical prompts or inserting curriculum phases that emphasize underperforming classes; this targeted sampling often yields larger accuracy improvements than training independent heads on tiny datasets. In practice, we routinely see few-shot gains simply by leveraging related tasks with the same text-to-text interface.
Robustness to domain shift is another accuracy win that follows from denoising pretraining and consistent prompt engineering. The span-corruption objective used during pretraining teaches the model to infer missing pieces from noisy context, which translates to better generalization when phrasing or terminology changes. In a real-world example—support ticket triage across product lines—the same T5 model adapted more quickly to new templates when trained with consistent prefixes and a compact label vocabulary, reducing misclassification rates during rollout. Logging raw generations and normalization failures lets you detect drift early and retrain with corrective examples.
How do you ensure model outputs remain accurate in production? Use deterministic decoding for strict tasks, instrument normalization and whitelist-violation rates, and keep prompt templates compact to preserve encoder capacity. Choose greedy decoding or constrained beams for runtime stability, but log beams or n-best lists during evaluation to catch edge cases. Also treat canonicalization rules and prefix schemas as versioned engineering artifacts: when a label set changes, rerun a small calibration dataset to measure accuracy deltas before deploying.
To translate these principles into practice, pick a small, unambiguous output vocabulary, train with consistent prefixes, and favor constrained decoding for critical decisions. Monitor three signals—exact-match after normalization, whitelist-violation rate, and calibration error across confidence bins—to quantify real accuracy gains. Taking this approach keeps the benefits of transfer learning and text-to-text consistency while giving you predictable, auditable improvements in downstream performance, and it naturally leads into how loss weighting and model selection further optimize those gains.
Flexibility Advantages
Text-to-text framing with T5 gives you a level of task flexibility that changes how you think about model ownership and runtime interfaces. By front-loading the interface as plain text, we convert classification, extraction, translation, and generation into the same plumbing: a tokenizer, an encoder–decoder, and a generator. That uniformity reduces the number of moving parts you maintain and lets you swap task semantics by changing a prefix or prompt rather than rebuilding architecture or adding heads.
Because prompts become the API contract, you can iterate on capabilities rapidly. Instead of deploying new model checkpoints for every new classification label or JSON schema, you add prompt variants and a small normalization layer that maps free-form text to structured outputs. For example, the same deployed model can answer "summarize:\n<document>", "intent: <utterance>", or "translate en->fr: <sentence>" with no code changes to the model itself; you only change the prefix and post-processing. This means faster experimentation, simpler A/B testing, and clearer rollback paths when outputs drift.
Extensibility is one of the most tangible engineering wins. When a product owner asks for a new intent or a new extraction slot, you can create training examples with the canonical prefix and fine-tune or few-shot prompt the existing model rather than engineer a new classifier. You preserve the same tokenizer and decoding engine, so inference pipelines remain identical. For strict outputs you can constrain decoding with vocabulary masking or forced tokens, giving you deterministic labels where needed while retaining generative flexibility for other tasks.
A small canonical inference wrapper shows this pattern in practice. In Python-like pseudocode: input = f"{prefix}\n{content}"; tokens = tokenizer.encode(input); out = model.generate(tokens, max_length=64, do_sample=False); result = tokenizer.decode(out) — swap prefix between "classify-intent:", "summarize-long:", or "translate en->de:". That single function is the surface area you deploy, test, and monitor. Because the wrapper normalizes inputs and canonicalizes outputs, downstream services only need to trust one textual contract instead of many bespoke heads.
How do you add a new label or task without redeploying the model? Train or prompt with the new prefix and publish a corresponding normalization map; for critical flows you can upload a short calibration dataset to measure exact-match and whitelist-violation rates before enabling the feature. In practice this reduces release friction: tagging, logging, and rollback live at the prompt/schema level, not the model binary. Real-world teams use this to offer multilingual features, experiment with abstractive vs extractive summaries, and roll out new NLU intents gradually across customer cohorts.
The practical implication is reduced engineering surface and faster iteration velocity. You maintain one tokenizer, one generation pipeline, and one set of monitoring signals (canonicalization errors, whitelist-violation rate, calibration drift) rather than a growing zoo of heads and metrics. There are trade-offs—latency for long text, generation variability for unconstrained outputs—but for most multi-capability services the flexibility gains outweigh the costs. Building on this flexibility makes loss weighting and model selection simpler to reason about, and it gives you a single, maintainable path to expand NLP capabilities without multiplying infrastructure complexity.
Fine-tuning T5 Guide
When you start a fine-tuning run with T5, unpredictability in outputs and label drift are the most common headaches, and they usually come from inconsistent prompts or sloppy canonicalization. Building on the text-to-text framing we discussed earlier, the single most powerful lever you have is deterministic input formatting: use a short, unambiguous prefix, a single, reproducible separator, and a canonical output vocabulary so the decoder learns a tight mapping from prompt to label. How do you structure fine-tuning so it’s stable and reproducible? We’ll walk through practical choices—data format, training recipe, decoding constraints, and monitoring—that make fine-tuning T5 reliable in production while preserving the benefits of transfer learning.
Start with dataset engineering because high-quality prompts beat extra epochs. Use consistent prefixes such as sentiment:, translate en->fr:, or intent: at the start of every example, followed by a single separator like \n or ||, and then the content; training with these fixed templates reduces position-embedding variance and speeds convergence. Canonicalize targets to a small whitelist (for classification) or a strict compact JSON-ish string for structured slots; if you need free-form text, provide clear examples that demonstrate allowable variation. Mind token budgets: keep prefixes short, push long context after the separator, and consider sentinel tokens for span-reconstruction tasks so you don’t waste decoder steps on boilerplate.
Set up a conservative training recipe that balances stability and speed. Use AdamW with linear warmup and cosine decay, start with a learning rate in the 1e-5 to 3e-4 range depending on model size, and prefer gradient accumulation instead of enormous batch sizes if GPU memory is limited. Apply mixed-precision (FP16) to accelerate throughput, and consider freezing the encoder or using adapters when you have very little task data—this preserves pretrained representations while you tune the decoder mapping. In code-like terms, a typical loop looks like: for batch in dataloader: outputs = model(input_ids=batch['input_ids'], labels=batch['labels']); loss = outputs.loss; loss.backward(); optimizer.step(); scheduler.step(); optimizer.zero_grad(); keep checkpoints and a small validation set formatted with the same prefixes for stable early stopping.
Regularization and curriculum matter more on multitask or low-resource projects than you’d expect. When you fine-tune multiple tasks together, interleave examples using the same text-to-text schema and upweight scarce tasks by repeating canonical prompts or using task-specific sampling probabilities; this targeted sampling often outperforms separate heads for low-data classes. Use label smoothing sparingly for long-form targets and track fine-grained metrics: exact-match after normalization, span F1 for extraction, and whitespace-insensitive ROUGE for summarization. Monitor whitelist-violation rate explicitly—when the model generates tokens outside the expected set, log the examples and add corrective training examples rather than relying on ad-hoc post-processing.
At inference, constrain generation to match your production contract and control variability. For strict labels, use vocabulary masking or force the first token(s) of the decoder to match a JSON prefix like {"intent": so the model cannot drift into synonyms; for looser tasks, choose greedy decoding or narrow beams to reduce stochastic output. Watch token budgets: set max_length conservatively, and prefer short canonical labels to long textual responses when latency is a concern. Also record n-best lists and raw generations in logging so you can audit failures and retrain when patterns of drift appear, keeping your service auditable and debuggable.
Version prompts and treat prefix schemas as part of your release artifacts, not throwaway text. Before a rollout, run a small calibration dataset through the candidate checkpoint and measure exact-match, whitelist violations, and calibration across confidence bins; if whitelist violations exceed a practical threshold, either tighten decoding constraints or augment training data and rerun fine-tuning. We find that this operational discipline—consistent prefixes, constrained decoding, targeted curriculum, and careful monitoring—lets you leverage T5’s transfer learning strengths while keeping outputs deterministic enough for production. Building on this foundation, the next step is to tune loss weights and select the right model size to meet SLA and cost targets.



