Understanding SQL Joins and Their Performance Implications
In the world of databases, SQL joins are essential tools that allow you to combine rows from two or more tables based on a related column between them. Understanding how these joins work and their implications on performance is crucial for optimizing database queries and ensuring efficient data retrieval.
At their core, SQL joins can be divided into several types, with the most commonly used being INNER JOIN, LEFT JOIN (or LEFT OUTER JOIN), RIGHT JOIN (or RIGHT OUTER JOIN), and FULL JOIN (or FULL OUTER JOIN). Each of these joins serves a particular function and can have distinct performance implications based on how they process data.
1. INNER JOIN:
When you use an INNER JOIN, the query returns only the rows that have matching values in both tables. This join is like a cross-reference that excludes any records without a match in the other table. Performance-wise, INNER JOIN is generally faster than other types of joins because it deals with the intersection of two datasets, which is usually smaller and more manageable. However, the way these joins perform can still be affected by the size of the datasets and the presence of proper indexing.
2. LEFT JOIN:
A LEFT JOIN returns all rows from the left table and the matched rows from the right table. If there is no match, NULLs are returned for columns from the right table. This join is particularly useful when you need all records from the main table regardless of whether there is a corresponding match in the related table. However, it can lead to performance issues if the right table is significantly large, as the database engine must process all rows from the left table and cross-check against the right.
3. RIGHT JOIN:
Similarly, a RIGHT JOIN returns all rows from the right table and the matched rows from the left table, with NULLs for non-matching rows from the left. While less common in typical database queries, RIGHT JOINs can be useful in specific scenarios where the right table contains primary data of interest. Performance considerations mirror those of LEFT JOINs, as processing requirements increase with larger datasets.
4. FULL JOIN:
FULL JOIN combines the results of both LEFT and RIGHT JOINs, returning all records when there is a match in either left or right table records. This join can provide a complete view when you need a comprehensive amalgamation of both tables. However, it is essential to manage these joins carefully as they can be resource-intensive, often involving large datasets that need significant processing power.
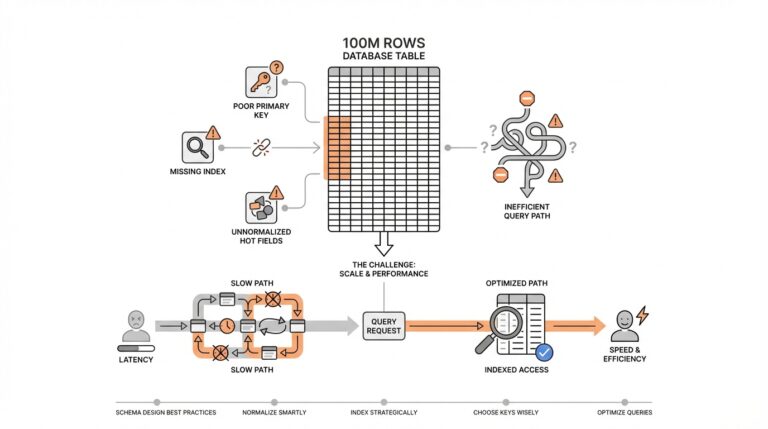
Indexing and Performance:
Indexes are crucial in boosting SQL join performance. They allow the SQL engine to quickly locate and combine relevant records without scanning the entire tables completely. When engaging in joins, especially with large datasets, ensuring that the join keys are indexed is a significant optimization step. Consider composite indexes when multiple columns are involved in joins, as this can further improve query efficiency.
Join Order and Execution Plans:
The sequence in which tables are joined can influence performance. SQL query optimizers usually determine the best sequence of joins, but understanding the execution plan can highlight areas of improvement. Execution plans display how a SQL query is processed, including detailed insights into join operations. Using tools like SQL Server’s Execution Plan Viewer or PostgreSQL’s EXPLAIN can help you understand and optimize join order and identify bottlenecks.
Real-world Example:
Imagine a scenario where you are managing a database for an e-commerce platform. The database contains tables for users, orders, and products. Using a LEFT JOIN on users and orders can be beneficial to get a list of all users with their respective orders, returning NULLs for users who haven’t made purchases. If the orders table is massive, ensuring that both the user_id and order_id columns are indexed could significantly speed up query execution.
Conclusion:
To maximize the efficiency of SQL joins, it’s important to have a deep understanding of how each join operates and the potential performance implications. By effectively using indexing strategies and scrutinizing execution plans, you can enhance query performance and achieve efficiency gains in database operations.
Identifying Performance Bottlenecks in SQL Joins
When working with SQL joins, identifying performance bottlenecks is crucial for optimizing query execution and ensuring efficient data handling. Several factors can influence the performance of joins, including table size, indexing, and join type. Understanding and addressing these bottlenecks can drastically reduce query execution time and improve overall database performance.
At the heart of performance bottlenecks in SQL joins is often an inefficient execution plan. SQL optimizers attempt to determine the most efficient way to execute a query, but certain conditions can mislead the optimizer into selecting suboptimal plans. This often occurs due to outdated statistics or missing indexes.
Examine the Execution Plan
The first step to identifying performance bottlenecks is to examine the execution plan of your query. Execution plans provide a roadmap of how SQL Server will execute a query, showing the order of table scanning, join operations, and the expected impact of each operation on performance.
- Retrieve the Execution Plan: Use SQL tools to retrieve execution plans. For instance, in SQL Server, you can use the
SET STATISTICS PROFILE ONstatement or the graphical execution plan in SQL Server Management Studio (SSMS) to visualize the operations. - Analyze Key Indicators: Look for costly operations in the plan. Indicators include table scans or scans on large datasheets, which suggest missing indexes. High logical reads are another clue indicating that optimization might be needed.
Implementing Indexes
Once potential bottlenecks are identified, implementing proper indexing can significantly enhance performance.
- Create Indexes on Join Columns: Ensure that both tables in the join operation have indexes on the columns being joined. For example, if you’re joining on
customer_id, ensure that both tables have indexes on this column. - Utilize Composite Indexes: If multiple columns are involved in the join condition or other filters, consider composite indexes. Composite indexes allow for more efficient query filtering and data retrieval.
- Regularly Update Statistics: Indexes rely on accurate statistics to be effective. Regularly update your database’s statistics so the optimizer has the most current data distribution information.
Optimizing Join Order and Reducing Data Load
Sometimes, simply changing the order of joins can alleviate bottlenecks.
- Optimize Join Order: Smaller datasets should be joined first, reducing intermediate result sets and potentially improving performance. Consider rearranging joins to process the smallest tables first.
- Filter Early: Apply
WHEREclauses as early as possible to reduce the amount of data being processed throughout the joins.
Exploit Query Optimizer Hints
In cases where the SQL optimizer doesn’t choose the best execution strategy, query hints can be useful.
- Use Join Hints: Instruct the optimizer on join order. For instance, using
INNER LOOP JOINorMERGE JOINhints can create more efficient query plans. - Force Parallel Execution: If your SQL environment allows, forcing parallel execution can help in breaking down the workload across multiple CPU cores, improving performance in large data joins.
Real-World Example
Consider a scenario where you have an e-commerce database with an orders table and a customers table. A frequent need might be to join these tables to generate sales reports. If you experience delays, examining the execution plan might reveal that SQL is performing a full scan on the orders table instead of using an index.
- Solution: Index the
customer_idon both tables. If theorderstable is massive and the report needs only recent sales, applying aWHEREfilter with a date condition againstordersbefore joining can reduce the data volume notably.
By systematically assessing execution plans and making strategic use of indexes and query optimizers, one can significantly mitigate performance bottlenecks in SQL joins, leveraging efficient database query capabilities.
Implementing Indexes to Accelerate Join Operations
Implementing indexes is an essential strategy to optimize SQL join operations, providing a considerable boost in query performance. Indexes function by creating a data structure that allows the database engine to locate and retrieve specific rows efficiently without having to scan entire tables. Here’s how you can effectively implement indexes to accelerate join operations.
To establish indexed join operations, first identify the key columns involved in the join condition. These are usually the columns that connect the tables, such as user_id when joining a users table and an orders table.
Indexes can be created as follows:
- Single-column Indexes:
Single-column indexes are straightforward and are created on the columns frequently used in join operations. For instance, if you frequently perform joins involving acustomer_idcolumn, an index like the following can be established:
sql
CREATE INDEX idx_user_id ON users(user_id);
CREATE INDEX idx_order_user_id ON orders(user_id);Applying a single-column index to both tables optimizes the database’s ability to quickly find matching keys during a join operation.
- Composite Indexes:
When multiple columns are part of the join conditions or other query filters, composite indexes become useful. They allow the query to be efficiently optimized when more than one column is involved. Suppose your query joins tables with conditions on bothuser_idandorder_date:
sql
CREATE INDEX idx_user_order ON orders(user_id, order_date);This composite index will boost performance not only for join operations but also for specific queries that involve filtering by order_date.
- Updating and Managing Indexes:
An essential part of using indexes effectively in join operations involves their maintenance. As the data changes, so must the indexes to remain effective.
-
Regularly Update Statistics:
Run commands to update statistics, ensuring that the database query optimizer has current data distribution metrics. Updated statistics help the optimizer choose the best execution plan.sql UPDATE STATISTICS users; UPDATE STATISTICS orders; -
Monitor Index Usage:
Utilize tools such as SQL Server Management Studio (SSMS) orEXPLAINin PostgreSQL to analyze if your indexes are being effectively used or if there’s room for adding or reorganizing indexes. -
Remove Redundant Indexes:
While indexes accelerate query performance, they also require storage and can slow down insert, update, and delete operations. Periodically evaluate index usage and remove any that are not contributing to performance improvement.
- Real-world Application Scenario:
Consider an e-commerce application database with several tables—includingcustomers,orders, andproducts. To optimize performance, especially for demanding reports that combine customer and order details, create indexes on the join columns.
sql
CREATE INDEX idx_customer_id ON customers(customer_id);
CREATE INDEX idx_order_customer_id ON orders(customer_id);Implement these indexes to ensure fast retrieval of matching customer and order data. If your reports often include recent order data, consider adding a composite index that includes the customer_id and order_date, further narrowing down relevant records quickly.
By thoroughly implementing indexes and keeping them well-maintained within your SQL operations, you can achieve substantial improvements in join performance, enhancing the responsiveness and efficiency of your database queries.
Optimizing Join Order and Query Execution Plans
To optimize SQL join operations effectively, understanding and manipulating both join order and query execution plans is paramount. These aspects play a crucial role in how quickly and efficiently queries are processed, which in turn can significantly impact performance.
When dealing with SQL queries involving joins, the optimizer aims to determine the most efficient way to execute them. This includes selecting an optimal join order and creating a suitable query execution plan, which dictates the sequence of operations.
Consider these strategies:
Analyze Query Execution Plans
Query execution plans provide a detailed roadmap of how a query will be executed. Tools like SQL Server’s Execution Plan Viewer or PostgreSQL’s EXPLAIN are invaluable for visualizing and understanding these plans. Here’s how to analyze them:
-
Access Execution Plans: In SQL Server Management Studio (SSMS), enable “Include Actual Execution Plan” when running queries. Alternatively, use the
EXPLAINstatement in PostgreSQL to generate a textual representation of the plan. -
Identify Join Operations: Examine each step in the execution plan. Look for “Nested Loops,” “Hash Matches,” or “Merge Joins,” which indicate how SQL joins are executed. Understanding these can help identify areas for improvement.
-
Spot Bottlenecks: Pay attention to costly operations, noted by high CPU or memory usage, or repeated scans of large tables. These often indicate inefficient join orders or missing indexes.
Optimizing Join Order
The order in which tables are joined can heavily influence performance. Though SQL optimizers generally choose an efficient order, manual adjustments may sometimes be necessary:
-
Join Smaller Tables First: Guide the optimizer to process smaller tables first to quickly reduce the search space, minimizing intermediate datasets and overall processing time.
-
Use the Most Restrictive Joins Early: Apply join conditions that filter out the most rows at the earliest possible stage. This reduces the volume of data handled in subsequent operations.
-
Experiment with Query Hints: In some databases, you can use hints to override the optimizer’s decisions. For example, specifying
LOOP JOINorHASH JOINin SQL Server can directly influence join behavior.
Implement Index Strategies
Effective indexing is integral to optimizing join orders and execution plans:
-
Index Join Columns: Ensure that all columns used in join conditions have appropriate indexes. This facilitates quicker access and matching of rows between tables.
-
Maintain Index Health: Regularly update indexes and statistics to keep them effective in guiding the optimizer. This ensures that the execution plans leverage the most current data distribution information.
-
Use Composite Indexes: When multiple columns are involved in join conditions or filter criteria, composite indexes can significantly improve query performance by utilizing combined data characteristics.
Practical Application Example
Imagine a scenario with a business intelligence application that regularly queries orders, customers, and product tables for reporting purposes. Suppose the query performance issues persist:
-
Index All Key Columns: Create indexes on
customer_idandproduct_idacross relevant tables to facilitate fast joins. -
Analyze Execution Plan: Upon examining the execution plan, notice extensive use of merge joins on unsorted datasets. Convert these to hash joins if they prove more efficient for your data distribution.
-
Adjust Join Order: If the execution plan indicates that the largest table contributes to significant processing overheads, alter the query to join smaller, restrictive datasets first, minimizing the impact of larger tables later in the operation.
By strategically altering join orders and utilizing detailed analysis of execution plans, SQL query performance can be significantly enhanced. Such changes lead to more efficient data retrieval, reduced resource consumption, and overall optimized database operations.
Utilizing Partitioning and Denormalization for Enhanced Performance
Leveraging partitioning and denormalization can dramatically improve the performance of SQL queries by reducing the complexity and size of the datasets processed during join operations.
Partitioning involves dividing a large table into smaller, more manageable pieces without altering the data itself. These pieces, or partitions, are efficiently handled by the database engine to optimize query performance. By targeting only the relevant partitions instead of scanning the entire table, the query execution time is significantly reduced. This is particularly beneficial for very large tables where operations such as joins, filters, and aggregations are applied frequently.
To implement partitioning effectively:
-
Choose a Partition Key: Select a column to serve as the partition key. This decision should be based on query patterns. For instance, if queries often filter data by
order_date, consider using that as your partition key. -
Design the Partition Scheme: Establish a partitioning strategy based on your key. Common methods include range partitioning (such as evenly distributing records by year) or list partitioning (like segmenting data by predefined categories).
-
Create the Partitioned Table: Apply the partition scheme to create a new partitioned version of your table. For example, in PostgreSQL, you can use:
“`sql
CREATE TABLE orders (
order_id SERIAL PRIMARY KEY,
order_date DATE,
customer_id INT,
total_amount DECIMAL
) PARTITION BY RANGE (order_date);
CREATE TABLE orders_2022 PARTITION OF orders
FOR VALUES FROM (‘2022-01-01’) TO (‘2023-01-01’);
“`
By querying only the relevant partitions, unnecessary data scanning is avoided, leading to faster data retrieval.
Denormalization, on the other hand, involves restructuring a database to combine related tables into a single table, thereby reducing the number of joins required and enhancing query performance. This is particularly useful when read operations vastly outnumber write operations and the database predominantly handles simple queries.
To apply denormalization effectively:
-
Identify Frequent Joins: Determine which joins are frequently executed and assess if their operations can be streamlined by merging tables.
-
Evaluate Data Redundancy Costs: While denormalization can accelerate read performance, it might introduce data redundancy. This requires careful balance since it can increase storage requirements and complicate updates.
-
Structure the Combined Tables: Create new tables that incorporate fields from commonly joined tables. For example, if
customersandordersare frequently queried together, a denormalized table could include fields from both:
sql
CREATE TABLE customer_orders AS
SELECT
c.customer_id, c.customer_name, o.order_id, o.order_date, o.total_amount
FROM customers c
JOIN orders o ON c.customer_id = o.customer_id;By using techniques like materialized views, you can maintain these denormalized tables automatically, merging freshness with speed.
Incorporating partitioning and denormalization requires a thoughtful approach to database architecture, but it unlocks significant performance gains, particularly in environments with large datasets and complex join operations. When strategically utilized, these techniques help focus on distributing workload, minimizing data processing, and ultimately accelerating query execution efficiently.