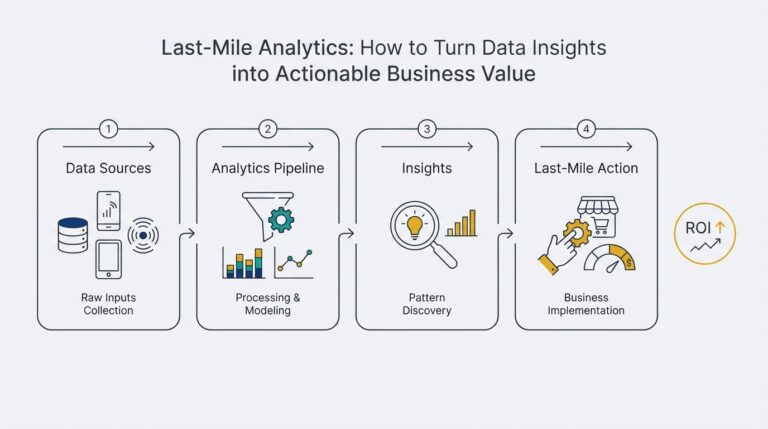
What is the Transformer Model? A Brief Overview
The transformer model stands as a groundbreaking innovation in the field of deep learning and natural language processing (NLP). Unlike its predecessors, such as recurrent neural networks (RNNs) and long short-term memory networks (LSTMs), the transformer model leverages a novel mechanism known as self-attention, enabling it to process sequences of data in a highly parallelized and efficient manner. Since its introduction in the landmark 2017 paper “Attention Is All You Need” by researchers at Google (arXiv.org), the transformer has reshaped the architecture of modern artificial intelligence systems.
At its core, the transformer is an architecture tailored to handle sequential data —think sentences, documents, or even DNA. Traditionally, tasks like translation, summarization, and text generation required models to process text one word at a time. Transformers, however, interpret inputs as an entire sequence, allowing the model to access all information simultaneously. This parallel processing dramatically speeds up training and inference.
The key innovation lies in the use of attention mechanisms. With self-attention, transformers assign different weights to different words (or tokens) in the sequence, empowering the model to determine which parts of the input are most relevant to each output. For example, when translating a complex English sentence into French, the transformer can “attend” to the correct nouns or verbs, regardless of their position in the sentence. This concept is explained in depth in Stanford’s CS224N course notes.
Another transformative aspect of the model is its encoder-decoder structure. The encoder reads and processes the input data, converting it into a set of vectors that represent the input context. The decoder then uses this processed information to generate the desired output, whether that’s a translated sentence or a summarized paragraph. This architecture has become the backbone of many modern NLP models, including the widely known BERT and GPT series (Google AI Blog).
The transformer model’s flexibility and unprecedented performance have made it the foundation for today’s most powerful language models. Whether powering machine translation, question answering, or text generation, transformers have set a new standard for what AI systems can achieve. Interested readers can dive deeper into the underlying mechanics and mathematical formulas in The Illustrated Transformer by Jay Alammar, which provides a visual explanation of these concepts.
The Attention Mechanism: The Heart of Transformers
At the core of what makes transformers so revolutionary in machine learning is the attention mechanism. Think of attention as a way for models to dynamically focus on the most relevant parts of the input sequence—much like how readers might skip to the important sections of an article. Unlike previous neural approaches, such as RNNs or LSTMs, attention lets the model simultaneously consider all input positions when processing each output, creating richer representations and allowing for vast improvements in performance on tasks like translation, summarization, and language modeling.
The primary innovation, known as self-attention or scaled dot-product attention, calculates a weighted sum of all input vectors for each output position. This means every word in a sentence can “pay attention” to every other word, with more important words getting higher weight. To break this down:
- Query, Key, and Value Vectors: Each word is projected into three vectors—query, key, and value. The similarity between a word’s query and every other word’s key determines how much “attention” it should pay to the value from that word. This illustrated guide offers an intuitive visualization of these concepts.
- Dot-Product and Scaling: The dot product measures similarity, giving a raw attention score. Scaling by the square root of the dimensionality prevents gradients from becoming unstable, making training more effective.
- Softmax Normalization: All scores across the input are passed through a softmax function, ensuring they sum to one—like probabilities. The attention weights then linearly combine the value vectors from every position in the input.
This allows a transformer to simultaneously build rich contextual understanding for every word in a sequence, capturing intricate relationships that span far beyond what traditional models could handle. For example, in the sentence “The cat sat on the mat because it was soft,” an effective attention mechanism understands that “it” refers to “the mat,” not “the cat,” despite their distance in the input. This ability to model long-range dependencies is central to transformers’ power, as explained in detail in the original “Attention Is All You Need” paper by Vaswani et al.
Moreover, transformers employ multi-head attention—several attention mechanisms in parallel—each learning to focus on different types of relationships. One head might focus on syntactic patterns, another on semantic similarities, all of which are then concatenated and further processed. TensorFlow’s official tutorial offers a hands-on example of multi-head attention in action.
The attention mechanism, by removing the sequential bottleneck of older models, enables efficient parallelization and sets the foundation for highly scalable architectures. Today, these principles underpin advances in language models, computer vision, protein folding, and beyond, making attention truly the heart of the transformer era in AI.
Positional Encoding: Giving Order to Sequences
One of the most innovative leaps of the Transformer model over traditional sequence-processing neural networks is its use of positional encoding. While models like RNNs naturally retain a sense of order because they process tokens sequentially, the Transformer model processes the entire sequence at once. This parallelization brings remarkable efficiency but also introduces a critical problem: how does the model know the order of the words?
This is where positional encoding becomes essential. In essence, it supplements the word embeddings with information about each token’s position in the sequence, enabling the model to make sense of word order when analyzing input data.
- Why Do We Need Positional Encoding?
- Unlike RNNs or CNNs, the Transformer lacks a natural way to account for sequence order, because all tokens are attention targets simultaneously. Without additional information, the model would interpret the input as a bag of words, ignoring any semantic relationships carried by word order.
- By injecting positional encodings, the model comprehends constructs like “The cat sat on the mat” versus “The mat sat on the cat“—subtly but crucially different in meaning.
- How Is Positional Encoding Implemented?
- The original Transformer, as introduced in the seminal Attention Is All You Need paper by Vaswani et al., uses a clever trigonometric approach. Each position in the sequence is mapped to an encoding vector derived from sine and cosine functions of varying frequencies.
- Specifically, for each dimension
iin the positional encoding, theposposition is encoded as:PE(pos, 2i) = sin(pos / 10000^(2i/d_model))PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model))
- This method means each dimension of the encoding corresponds to a sinusoid of different wavelength, allowing the model to easily learn to attend by relative positions. For a great technical visual explanation, see AI Summer’s detailed guide.
- Step-by-Step Example
- Imagine a sentence: “I love machine learning”. Each word is first embedded into a vector (through a lookup in an embedding matrix).
- For each word position (e.g., 0 for “I”, 1 for “love”, etc.), a positional encoding vector of the same dimension as the embedding is generated.
- The final input to the Transformer is the element-wise sum of the word’s embedding and its positional encoding. This fused vector now contains both the word’s meaning and its position in the sentence.
- During training, the model learns attention patterns that rely on these position-aware vectors, enabling tasks like translation, summarization, or question answering to account for word order.
- Beyond Sine and Cosine: Evolution of Positional Encoding
- Since the original proposal, researchers have experimented with other forms of positional encodings. For example, some models use learned positional embeddings, allowing the network to optimize positional vectors during training.
- Hybrid approaches and relative positional encodings, as described in papers like Self-Attention with Relative Position Representations, offer more flexibility for advanced NLP models.
In summary, positional encoding is the mechanism that empowers the Transformer to understand the order in unstructured sequences, striking a balance between parallel computation and sequence-aware processing. It remains a highly active area of research as large-language models continue to evolve—see this in-depth article on Towards Data Science for further reading.
Multi-Head Attention: Enhancing Communication
The magic behind the transformer model’s groundbreaking performance lies in its unique approach to processing information—multi-head attention. Unlike previous architectures that either processed sequences step by step (like RNNs) or with limited context (like CNNs), transformers leverage attention to seek relationships among all elements of a sequence in parallel. But what exactly is multi-head attention and how does it truly enhance communication within the model?
At its core, multi-head attention allows the model to focus on different parts of a sequence simultaneously. Imagine reading a sentence: one attention head might focus on the subject, another on the verb, and yet another on objects or contextual information. This mechanism brings several benefits, profoundly impacting the model’s ability to understand complex language structures.
- Learning Diverse Patterns
Each attention “head” in a multi-head setup operates with different projection matrices, enabling it to extract specific types of relationships or patterns. For example, one head might capture short-range dependencies like “he – is,” while another can identify long-range relationships such as subject-object bindings. This parallel exploration is what makes transformers especially powerful across diverse language tasks. For a closer look at how attention diversifies understanding, check out this comprehensive resource from Google AI Blog on transformers. - Improved Context Understanding
Multi-head attention lets each token in a sequence “communicate” with other tokens, weighing their relevance differently. Consider the sentence: “The article the professor wrote was excellent.” Here, the word “wrote” connects more closely to “professor” than “article”. Multi-head attention helps the model learn these nuanced connections, even across long sentences. This mechanism frees language models from the strict sequential constraints of prior architectures, allowing for precise and adaptable communication. - Parallelization for Scalability
By splitting the attention process across multiple heads, transformers can process sequences much faster and scale to larger datasets, making them suitable for modern, data-rich AI tasks. Tasks that once took hours via sequential models are now handled with remarkable efficiency, opening doors to applications in translation, summarization, and more. For more technical details on how multi-head attention achieves this, the original paper, Attention Is All You Need, provides invaluable insight.
Multi-head attention, therefore, is not just an enhancement—it’s a fundamental shift in how models can “communicate internally”. By examining multiple viewpoints on every bit of data, transformers build a richer, more robust understanding, powering state-of-the-art advances in natural language processing and beyond.
Feed-Forward Networks and Layer Normalization Explained
One of the cornerstones of the Transformer architecture is its ability to process information efficiently through mechanisms like feed-forward networks and layer normalization. Both components play crucial roles in shaping how Transformers learn and represent complex data, from language to images. Let’s break down each of these mechanisms, examining their structure, purpose, and impact, while providing practical examples and expert insights.
Feed-Forward Networks: Processing and Transforming Data
Within each Transformer layer, after self-attention has contextualized the input tokens, the output passes through a position-wise feed-forward neural network (FFN). Unlike traditional neural networks that process data across layers, the Transformer’s FFN applies to each position independently and identically. This structure enables the model to learn complex transformations while keeping computational efficiency high.
- Structure: A standard feed-forward network consists of two linear transformations with a non-linear activation function—often Rectified Linear Unit (ReLU)—in between. Mathematically, this is represented as:
FFN(x) = max(0, xW₁ + b₁)W₂ + b₂
where x is the input, W₁ and W₂ are weight matrices, and b₁, b₂ are biases.
- Purpose: By using the same FFN across all input positions, the Transformer can learn nuanced patterns unique to each sequence element while maintaining parameter sharing—critical for scalability. This means every token passes through identical mathematical transformations, enabling efficient learning and inference.
- Example in Practice: Suppose a sentence is encoded into word vectors. After the attention layer enriches these vectors with contextual information, the FFN can then transform these representations further—helping the model detect higher-level patterns, such as syntax or sentiment. As explained in the Google AI Blog’s original Transformer post, these networks assist each layer in building progressively more abstract linguistic features.
Layer Normalization: Stabilizing and Accelerating Training
Deep neural networks, including Transformers, often encounter issues like internal covariate shift—where the distribution of each layer’s inputs changes during training. Layer normalization addresses this by standardizing the inputs for each layer, helping stabilize and accelerate learning.
- How It Works: For each data point and at every layer, layer normalization computes the mean and variance, normalizing the sum of the layer inputs. The normalized output is then scaled and shifted by learned parameters. This operation is performed for each position separately, making it particularly suitable for architectures, like Transformers, where batches may contain variable-length sequences or single examples.
- Key Benefits: Research from Microsoft demonstrates that layer normalization improves training speed and can lead to more stable gradient flow, reducing the likelihood of vanishing or exploding gradients. This contributes to faster convergence and better overall performance in practical applications.
- Behind the Scenes: In practice, every time a Transformer processes a batch during training, layer normalization ensures that the representation at every layer is well-scaled and consistent. This makes it easier for subsequent layers—whether attention or feed-forward—to extract useful features without being confounded by erratic input distributions.
Combined, these two mechanisms—feed-forward networks and layer normalization—are fundamental to the Transformer’s remarkable success. They not only unlock powerful capabilities for sequence processing but also ensure large models can be trained quickly and robustly, as evidenced by the impressive results in natural language understanding, translation, and beyond (read the original Transformer paper for deeper insights).
Training Transformers: Challenges and Solutions
Training transformer models is a complex process that involves addressing multiple challenges associated with their architecture and data requirements. Let’s explore these challenges and the innovative solutions that have emerged in recent years, drawing from authoritative sources to back up our journey.
Data Requirements and Scalability
Transformers are known for their voracious appetite for data, as they thrive on vast datasets to learn meaningful representations. Unlike traditional neural networks, their performance often scales favorably with more data (Kaplan et al., 2020). However, acquiring, curating, and labeling such massive datasets can be a significant hurdle. Data cleaning pipelines and techniques like data augmentation, semi-supervised learning, and transfer learning are frequently employed to address this.
- Transfer Learning: By pre-training transformers on large corpora (for example, Wikipedia or Common Crawl) and then fine-tuning them on specific tasks, researchers have made transformers accessible even for domains with limited data. The success of models like BERT and RoBERTa leverages this approach.
- Semi-Supervised and Unsupervised Learning: Methods such as self-training and pseudo-labeling allow transformers to leverage unlabelled data efficiently, reducing reliance on annotated corpora.
Computational Complexity and Efficiency
The self-attention mechanism that powers transformers comes at the cost of quadratic complexity with respect to sequence length. This means memory and processing demands soar as input size grows, making training prohibitively expensive for longer texts.
- Efficient Attention Mechanisms: Techniques such as Linformer, Longformer, and Big Bird reduce computational overhead by approximating or sparsifying the attention matrix, enabling transformers to scale to much longer sequences.
- Model Parallelism and Distributed Training: Training large transformers often relies on splitting computations across multiple GPUs or even entire clusters. Frameworks like PyTorch Distributed and TensorFlow Distributed Training facilitate this process, making it possible to fine-tune models that would otherwise be too large for a single machine.
Overfitting and Regularization
With millions—even billions—of parameters, transformers are susceptible to overfitting, especially when fine-tuned on smaller datasets. Regularization strategies are critical:
- Dropout and Layer Normalization: Applying dropout layers and normalization techniques (see Layer Normalization) helps generalize learning across batches and reduce reliance on any single feature.
- Early Stopping: Monitoring performance on a held-out validation set and terminating training when overfitting is detected prevents unnecessary parameter updates.
Tokenization and Input Representation
Transformers operate on tokenized inputs, and the choice of tokenizer (such as Byte-Pair Encoding or WordPiece) affects both efficiency and performance. Subword tokenization enables models to handle out-of-vocabulary words and rare sequences with grace, a crucial capability for languages with rich morphology or specialized vocabularies.
Hyperparameter Optimization
Finding the optimal learning rate, batch size, sequence length, and other training parameters is a non-trivial task. Automated solutions like grid search, random search, or more advanced approaches such as Bayesian optimization are widely used. Practical libraries like Optuna or Ray Tune help simplify this process for practitioners.
By tackling these multifaceted challenges with innovative engineering and scientific rigor, the field has enabled a wide array of practical applications—from language understanding to protein folding. For a comprehensive overview, readers are encouraged to explore reviews from Nature Machine Intelligence or dive into leading-edge research at conferences like NeurIPS or ICML.