Transactions and Atomicity
Building on this foundation, imagine you are transferring money from one account to another. You do not want the system to subtract cash from the first account and then stop halfway before adding it to the second one. That is the moment where database transactions earn their keep: a transaction groups several database operations into one logical unit of work, so the database can treat them together instead of as unrelated steps. In practice, this means you can begin a transaction, run a sequence of statements, and then either commit them or roll them back if something goes wrong.
This is where atomicity comes in, and it is the promise that makes transactions feel safe. Atomicity means “all or nothing”: either every change in the transaction becomes visible, or none of them do. PostgreSQL describes a transaction as atomic from the point of view of other transactions, and Microsoft’s documentation explains the same idea in plain terms: a transaction must either succeed completely or leave no lasting effect at all. That sounds abstract until you picture a recipe in a kitchen; if the cake is missing one crucial ingredient, you do not serve a half-finished dessert.
So what happens when something breaks in the middle? The database uses rollback to cancel the changes made so far, which is why a failed transaction does not leave your data in a strange halfway state. PostgreSQL says that if you decide not to commit, or if an error interrupts the work, you can issue ROLLBACK and the updates so far are canceled. Microsoft’s transaction guidance says the same thing from the application side: if the transaction is rolled back, none of the operations are applied. That is the practical side of atomicity, and it is what lets you recover cleanly from application bugs, network hiccups, or validation failures.
Before we go further, it helps to see how the database draws the boundaries. In PostgreSQL, BEGIN starts a transaction block, and the statements that follow belong to that one unit of work until you end it with COMMIT or ROLLBACK. Outside an explicit transaction block, many systems operate in autocommit mode, where each statement is effectively its own transaction unless you group several statements together. That is a useful default for quick edits, but once your work spans multiple related changes, you want a real transaction so the database can protect the whole sequence as one package.
Now that we understand the mechanics, the reason atomicity matters becomes easier to feel. It prevents partial updates from leaking into your data model, which is especially important when one action depends on another. Think of an order checkout flow: you might reserve inventory, record the payment, and create the shipment record. If any one of those steps fails, atomicity lets the database unwind the entire attempt instead of leaving you with a paid order and no stock, or stock removed and no payment. That same all-or-nothing idea is one of the core reasons transaction processing remains the backbone of reliable database systems.
Taking this concept further, atomicity is the promise that lets you write multi-step database work with confidence. You still need to think carefully about what belongs in the same transaction, because the larger the unit of work, the more you ask the database to protect at once. But once the boundary is set, the story is reassuring: either the entire change makes it through, or the database rewinds and leaves things exactly as they were. That is the quiet power of transactions, and it is the reason atomicity matters so much when data must stay trustworthy.
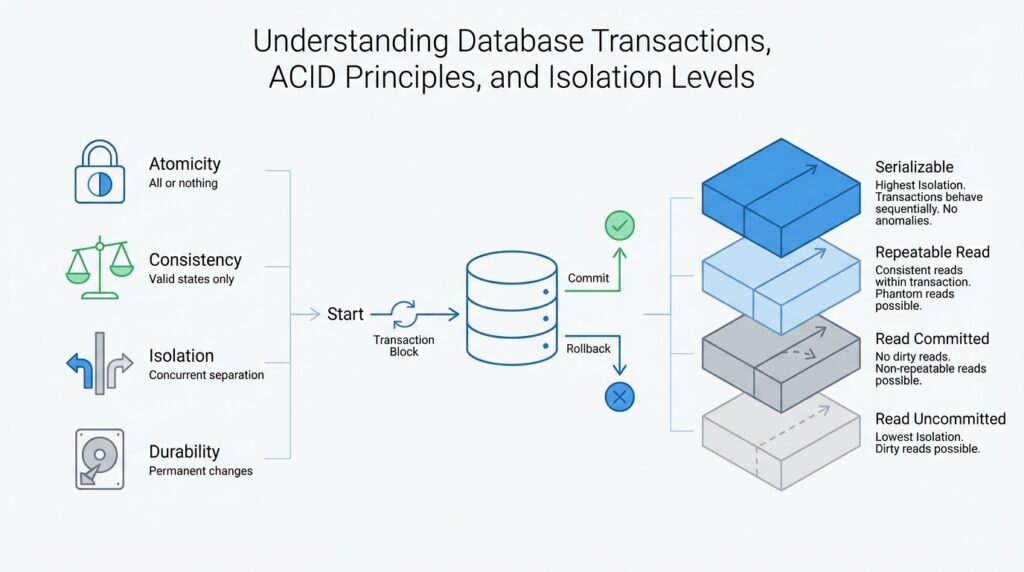
ACID Principles Overview
Building on this foundation, ACID principles are the broader safety contract that tells you why database transactions feel dependable in the first place. ACID stands for atomic, consistent, isolated, and durable, and PostgreSQL describes a transaction as a single unit whose effects stay hidden until the work is complete. If atomicity is the promise we already met, ACID is the full set of promises that keeps data from drifting into confusing half-states. How do database transactions keep that promise when several users are editing at the same time? The answer is that each letter protects a different part of the journey.
Consistency is the part that keeps the story believable. A transaction should move data from one valid state to another valid state, so the database never accepts a change that breaks the rules the system depends on. Think of it like a well-run library: a book can move from one shelf to another, but it should never disappear from the catalog in between. Microsoft notes that much of this responsibility sits with the application developer, which is a useful reminder that ACID is not magic; it works best when your schema, constraints, and business rules all agree on what valid means.
Isolation is where things get interesting, because now we are talking about concurrent work. Isolation means one transaction should behave as if it were running alone, even while other transactions are active in the background. That is why isolation levels exist: they are the control dial that decides how much one transaction can see of another transaction’s in-flight work. PostgreSQL supports the standard levels, and its documentation shows that stricter isolation can rule out more anomalies, while the tradeoff is often less concurrency and more retry work. In other words, why does a database sometimes let you see a newer value and sometimes not? Because the isolation setting changes the rules of the conversation.
Durability is the final lock on the door. Once a transaction commits, its results should survive a crash, a restart, or a power failure, because the database has recorded the change in a way it can recover later. Microsoft describes this as a committed transaction remaining persistent even if the computer fails immediately after commit, and PostgreSQL defines a transaction as a unit whose effects become final only when the work is complete. For you, the practical takeaway is simple: after the database says the transaction is committed, you can treat that outcome as permanent rather than tentative.
Taken together, ACID principles explain why database transactions are more than a convenient grouping of statements. Atomicity stops partial work from leaking out, consistency keeps rules intact, isolation protects concurrent activity, and durability preserves committed results. Once those four ideas click, the next question becomes much more practical: when two transactions overlap, how much can they see of each other? That is the doorway into isolation levels, where we start turning the abstract promise of ACID into everyday behavior you can actually choose and tune.
Concurrency and Anomalies
Building on this foundation, concurrency is where database transactions stop feeling like a tidy solo performance and start looking like a crowded kitchen. Two people can be reading and writing the same data at once, and transaction isolation is the rulebook that decides how much they can notice about each other’s work. That is why concurrency anomalies matter: they are the surprising results that appear when overlapping database transactions are allowed to see too much, too soon, or in the wrong order. How do you keep one user’s half-finished update from leaking into another user’s view? That is exactly the question isolation levels are designed to answer.
The first anomaly is the dirty read, and it happens when one transaction reads data that another transaction has changed but not yet committed. Think of it like glancing at a recipe while someone is still editing it with a pencil; if they erase the ingredient later, you were trusting information that never really became final. A dirty read can cause your application to make decisions based on a value that disappears a moment later, which is why many systems block this behavior at safer transaction isolation settings. When people ask why database transactions sometimes seem cautious, this is one of the reasons.
Next comes the non-repeatable read, which shows up when you read the same row twice inside one transaction and get two different answers. Imagine checking the price of a ticket, pausing to answer a message, and then finding that the price changed before you clicked buy. The row was valid both times, but another transaction slipped in and updated it between your two reads. This is where concurrency becomes subtle: the data is not broken, yet your transaction no longer sees a stable picture of the world, and that can make business logic feel inconsistent.
Then we reach the phantom read, which sounds dramatic because the effect is a little uncanny. You run the same query twice, and the second time it returns extra rows that were not there before because another transaction inserted new matching records. Picture checking how many open orders exist for today, then refreshing the list and discovering a few new ones have appeared. The rows were not wrong; the set itself changed under your feet. In practice, phantom reads are one reason stricter isolation levels can feel safer for reporting and validation work, even if they reduce how freely transactions run side by side.
There is also a sibling problem called a lost update, where two transactions read the same starting value, both make changes, and the later write quietly overwrites the earlier one. This is especially frustrating because each transaction may look correct in isolation, yet the combined result loses someone’s work. Stronger transaction isolation and careful application design help prevent that kind of collision, but the exact protection depends on the database and the isolation level you choose. That is the practical tradeoff of concurrency: the more freedom you give overlapping work, the more you need to understand which anomalies your system can tolerate.
This is why isolation levels matter so much in real systems. At lower settings, database transactions can run faster and with less waiting, but they may allow more concurrency anomalies; at higher settings, the database protects a more stable view of the data, but it may force more blocking or retries. You do not choose an isolation level for the sake of theory alone; you choose it based on the kind of mistake your application can afford. Once that clicks, the next step is much easier to understand: instead of asking whether transactions are “safe” or “unsafe,” you start asking which anomalies your workload can live with, and which ones it absolutely cannot.
Isolation Levels Explained
Building on this foundation, isolation levels are the part of transaction control that decide how much one transaction can peek at another transaction’s work while both are running. If atomicity gave us the promise that a transaction finishes as one complete unit, isolation levels tell us how private that unit should feel in a busy database. Think of it like a conversation in a crowded room: at one setting, you hear every half-finished sentence; at another, you only hear fully spoken ideas; at the strictest setting, everyone waits their turn. That is the practical heart of database isolation levels.
The easiest way to understand them is to start with the loosest setting and move upward. Read Uncommitted is the most permissive level, which means a transaction may see changes from another transaction even before those changes are committed. That can be useful in rare cases where speed matters more than precision, but it can also expose you to the dirty reads we discussed earlier. In plain language, you are looking at work that may still be erased, so this level asks you to accept a little risk in exchange for more freedom.
Read Committed is the next step, and for many people it is the first level that feels comfortably familiar. Here, a transaction only sees data that other transactions have already committed, so you avoid reading values that might disappear a moment later. The tradeoff is that the picture can still change between two reads inside the same transaction, which is why non-repeatable reads can still happen. If you are asking, “Why does my query show one value now and another value later?” this level is often part of the answer.
Repeatable Read goes further by trying to give your transaction a steadier view of the rows it has already seen. Once you read a record, the database works to keep that record consistent for the rest of the transaction, so you are less likely to feel the ground shifting beneath you. This helps when you need to compare values over time or make a decision based on something you checked earlier. It does not solve every problem, though, because new rows that match your query can still appear in some systems, which is where the idea of phantoms comes back into the story.
Serializable is the strictest of the standard isolation levels, and it behaves as though transactions ran one after another instead of all at once. That sounds slow, but it gives you the cleanest mental model: no dirty reads, no non-repeatable reads, and no phantoms slipping in to surprise you. When accuracy matters more than throughput, this is the level that most closely matches the way people naturally expect a system to behave. The cost is that the database may block more work or ask you to retry more often, because it is protecting a very careful view of the data.
So how do you choose the right isolation level? You start by asking what kind of surprise your application can tolerate. A shopping cart, for example, may handle slightly looser rules because speed matters and a refresh can correct the view, while a money transfer or inventory reservation often needs stronger protection because a mistaken read can cause real damage. The most important thing to remember is that isolation levels are not about picking the “best” setting once and forgetting it; they are about matching the database’s behavior to the story your application is trying to tell.
Once that idea clicks, the rest of transaction design becomes much easier to reason about. You stop treating concurrency as a mysterious source of bugs and start seeing it as a set of tradeoffs the database can manage for you. That is why isolation levels matter so much in database transactions: they shape whether your application favors speed, stability, or the strongest possible guarantee that each transaction sees a world that makes sense.
Choosing the Right Level
Building on this foundation, the real question is not whether database transactions are safe in theory, but how strict they need to be in your day-to-day application. Choosing the right isolation level feels a little like choosing how closely you want to lock the door before leaving a room: a stronger lock gives you more certainty, but it can also slow everyone down. So when you ask, “How do I choose the right isolation level for my database transactions?”, you are really asking how much risk, waiting, and complexity your system can comfortably carry.
The first thing to do is match the isolation level to the kind of work your application performs. If your app mostly reads data, a lighter setting may be enough because the occasional shifting view does not usually cause much harm. If your app changes money, inventory, reservations, or anything where a wrong decision can create real loss, you usually want stronger transaction isolation so the data feels steadier while the work is in progress. In other words, the more your logic depends on one consistent snapshot of the world, the more carefully you should protect it.
Now that we have that frame, it helps to think in terms of consequences rather than labels. A shopping feed can tolerate a stale count for a moment, because the next refresh will probably correct it. A checkout flow cannot shrug off the same kind of uncertainty, because a second order, a missing item, or a duplicated charge is not a small mistake. That is why isolation levels are not a ranking of “good” and “bad”; they are a set of tradeoffs between speed and certainty, and the right choice depends on which kind of surprise your users can live with.
You can also use the shape of your workload as a guide. If many users read the same records and only a few update them, you may not need the strictest setting everywhere. If several processes regularly touch the same rows, stronger isolation can prevent the kinds of concurrency anomalies we explored earlier from turning into bugs that are hard to reproduce. A practical way to think about it is this: when updates are rare and the data is forgiving, you can often favor throughput; when updates are frequent and the data must stay exact, you should favor protection.
This is where many teams make a useful split in their design. Instead of choosing one isolation level for every transaction in the system, they reserve stricter database transactions for the sensitive paths and use lighter ones for the rest. That keeps the important flows, like payments or stock changes, under tighter control while allowing less critical reads and lookups to stay fast. It is a bit like using a strong seal on a medicine bottle and a simpler cap on a notebook; both are closures, but they do not need the same strength.
Before you settle on a setting, it also helps to ask how your database handles retries and blocking. Some isolation levels may force a transaction to wait, restart, or fail more often when two operations collide, and that is not a bug so much as the cost of stronger protection. If your application can retry safely, a stricter level becomes easier to live with. If retries would confuse users or duplicate side effects, you may need to design more carefully around the transaction boundary itself.
The easiest way to choose the right level is to start small, test the real behavior, and pay attention to the mistakes that would hurt most. What outcome would be unacceptable if two transactions overlap? Which parts of the system need a calm, stable view of the data, and which parts can tolerate a little movement? Once you answer those questions, isolation levels stop feeling abstract and start feeling like a practical control knob, helping you tune database transactions to fit the story your application is trying to tell.