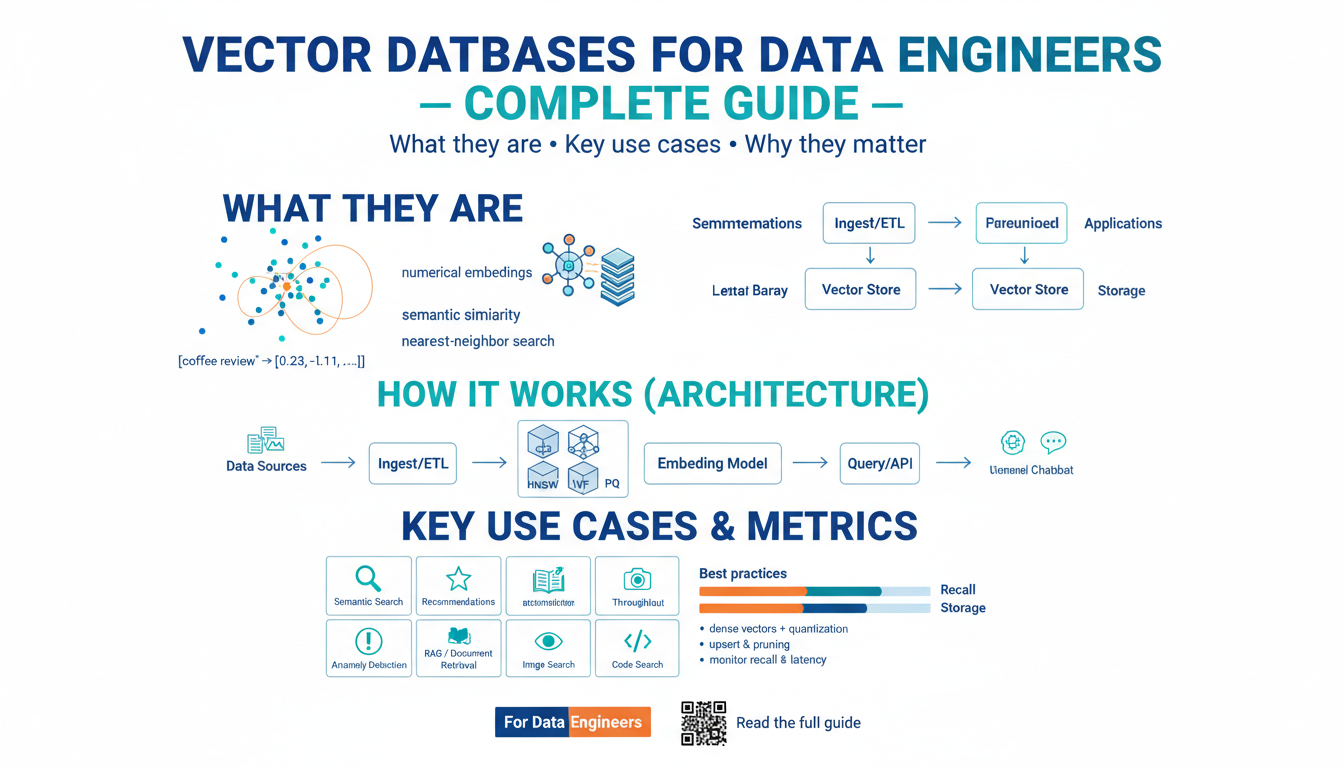
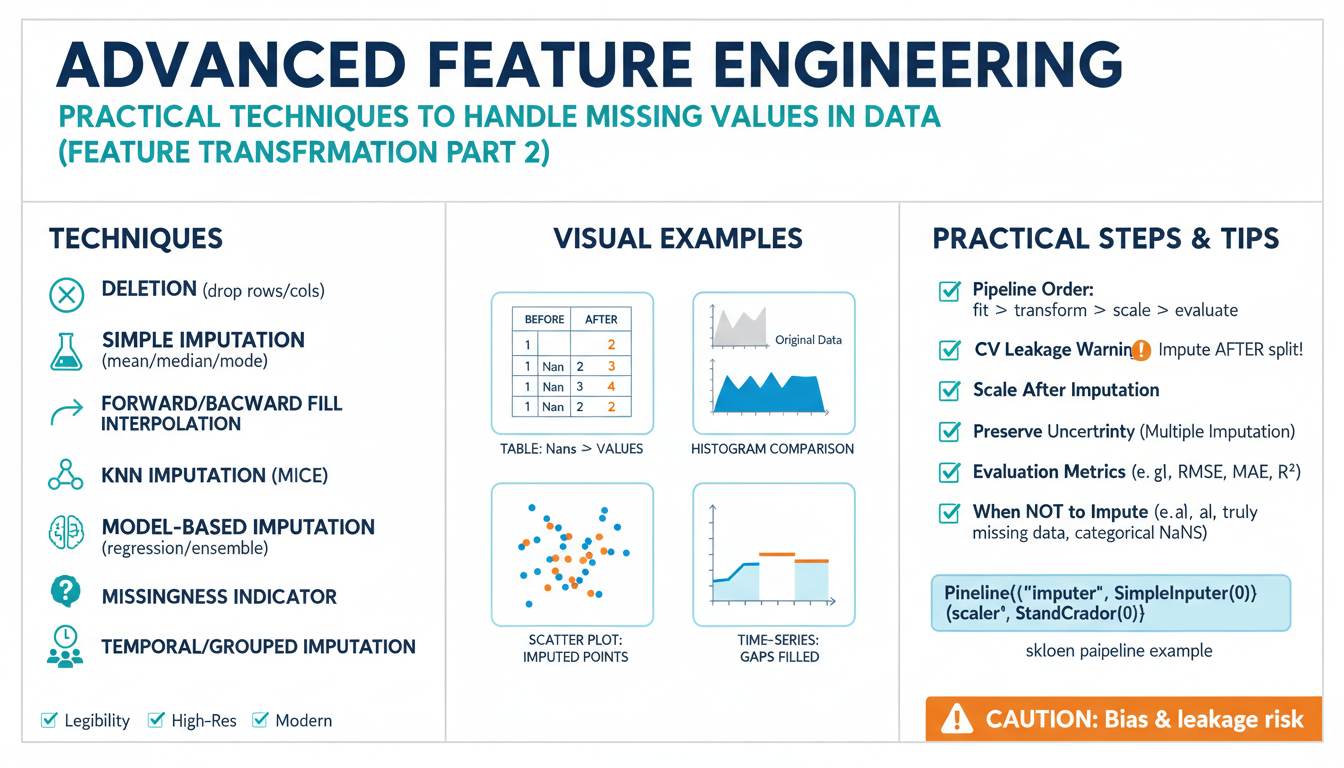
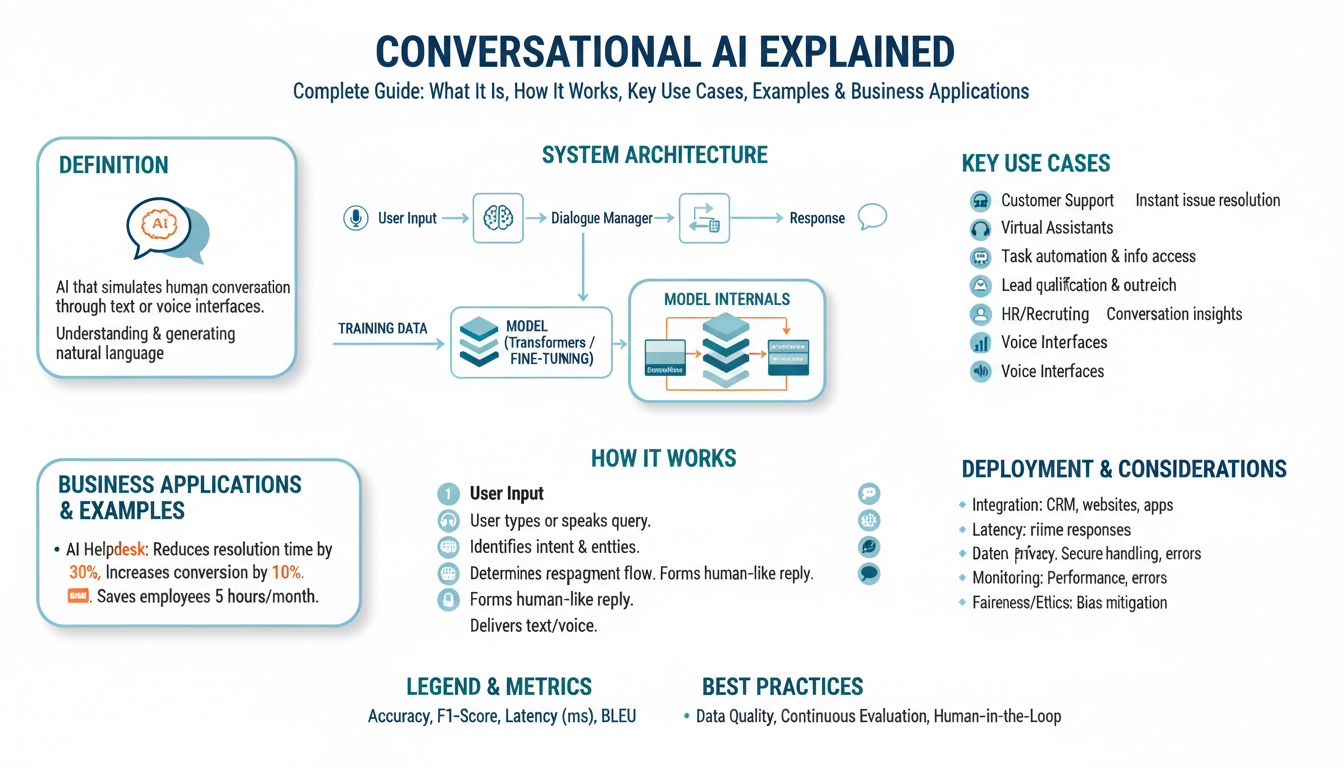
What Are Word Embeddings?
Word embeddings are a revolutionary technique in natural language processing (NLP), allowing computers to understand words more deeply than simply treating them as strings of characters. Traditionally, computers worked with words using so-called “one-hot vectors,” where each word is represented by a unique position in a massive, sparse vector space. However, this method fails to capture any semantic or syntactic relationships between words. For a machine, the words “king” and “queen” appear just as different as “king” and “apple.”
Word embeddings solve this problem by mapping words into a dense, continuous vector space where meaning is encoded by the position and direction of a word’s vector. This transformation enables algorithms to grasp subtle relationships between words, such as similarity, analogy, and context. For instance, in a well-trained embedding space, the vector operation king – man + woman yields a vector very close to queen. This fascinating property demonstrates that embeddings capture not just word similarity, but also more complex relationships like gender or tense.
One foundational technique to generate word embeddings is Word2Vec, developed by researchers at Google. Word2Vec learns word associations from large corpora of text, producing embeddings where related words cluster close together. Another popular approach is GloVe (Global Vectors for Word Representation) by Stanford, which uses global word co-occurrence statistics to train the embedding space. These techniques leverage context—words that appear together in similar environments tend to have similar vectors.
To illustrate, imagine you feed a model with thousands of sentences like “The cat sat on the mat,” “The dog lay on the rug,” and “The bird perched on the branch.” Over time, the model positions “cat,” “dog,” and “bird” closer together in the embedding space, as they tend to share similar surroundings in sentences. Similarly, “mat,” “rug,” and “branch” also group together, revealing the concept of places where animals rest.
This capability to represent meaning through geometry is why word embeddings are foundational to modern AI applications, powering search engines, chatbots, translation services, and more. If you’re interested in a technical deep-dive, the TensorFlow guide to word embeddings offers hands-on examples and further explanations.
A Brief History: From One-Hot Encoding to Dense Vectors
To understand how AI comprehends language, it’s important to trace the journey from early methods of representing words digitally to the more advanced techniques used today. In the earliest natural language processing (NLP) systems, computers used what’s called one-hot encoding. In this approach, each unique word in a vocabulary is represented by a long vector, mostly filled with zeroes except for a single one in the position corresponding to that word. For example, in a vocabulary of 10,000 words, the word “apple” could be represented as [0, 0, ... , 1, ... , 0], where the “1” marks its unique spot.
While simple and easy to implement, one-hot encoding quickly hit its limitations. The approach results in extremely large and sparse vectors—each word is distinct from every other, with no mathematical relationship between similar words (like “king” and “queen”, or “cat” and “kitten”). The lack of semantic closeness meant that computers couldn’t truly “understand” how words relate to one another. For more on one-hot encoding, you can visit this overview by GeeksforGeeks.
Recognizing these shortcomings, researchers developed more compact and meaningful methods called dense vector embeddings. Embeddings revolutionized NLP by allowing each word to be represented as a point in a multi-dimensional space. Words that appear in similar contexts have vectors that are mathematically close together, reflecting their similarities and relationships. These embeddings are learned from large text corpora using machine learning algorithms, a breakthrough demonstrated by models such as Word2Vec and GloVe (Global Vectors for Word Representation) from Stanford University.
To make this tangible, consider how these models embed “king”, “queen”, “man”, and “woman”. In a well-trained embedding space, subtracting the vector for “man” from “king” and adding the vector for “woman” yields a vector remarkably close to “queen”. This phenomenon, known as vector arithmetic, demonstrates that word embeddings capture deep semantic relationships. As described by Stanford’s NLP Group, these embeddings expose fascinating patterns such as countries and capitals (“Paris” – “France” + “Italy” ≈ “Rome”).
This leap from rigid, isolated representations to flexible, meaning-rich vectors laid the groundwork for modern AI language models. Dense vectors made it possible for algorithms to process meaning, analogy, and context—essential steps on the path toward true language understanding. To further explore the mathematics and intuition behind embeddings, check out this detailed guide by Jay Alammar.
How Word Embeddings Capture Meaning
At the heart of word embeddings lies a fascinating capability: transforming the subtle, complex nature of language into mathematical representations that capture not just the meaning of individual words, but also the relationships between them. These representations, referred to as “vectors,” allow AI models to process and understand human language with remarkable nuance.
Traditional approaches to language, like one-hot encoding, treated words as isolated entities—each word as a unique number in a list. However, this method misses the deeper connections between words. For example, while “cat” and “dog” might appear near each other in a text, one-hot encoding provides no way for AI to recognize their similar context and meaning.
Word embeddings, popularized by models such as Word2Vec and GloVe, address this by encoding thousands of words as high-dimensional floating point vectors. Each vector’s position reflects its semantic meaning based on context from massive text corpora. This means that similar words have embeddings—points in this mathematical space—that are close together. For example:
- Cat and dog will have similar embeddings because they frequently appear in similar contexts (“the cat and the dog”).
- King and queen are close, yet the difference between king and man is similar to the difference between queen and woman—a striking example of how embeddings capture nuanced relationships.
These relationships can be explored through simple arithmetic in the vector space. A famous demonstration is:
Vector(“King”) – Vector(“Man”) + Vector(“Woman”) ≈ Vector(“Queen”)
This arithmetic showcases how embeddings encapsulate gender, profession, and other contextual attributes. For a deeper dive, see the technical overview by Carnegie Mellon University.
How do embeddings learn this? During training, models are fed enormous libraries of text. They look at windows of surrounding words (context) to learn that, for instance, “bank” in the context of rivers has a different meaning than “bank” referring to financial institutions. The research paper on Word2Vec explains how the model is optimized to maximize the likelihood of context words, forcing the model to learn genuine, richly descriptive relationships.
Ultimately, word embeddings allow AI not just to “see” words, but to understand how they fit together in the web of language meaning. This forms the basis for many modern advances in deep learning, natural language processing, and even conversational AI like the one you’re interacting with now. For further reading, check out the explanation by Nature and the overview on Machine Learning Mastery.
Popular Models: Word2Vec, GloVe, and FastText
One of the breakthroughs that made AI-powered language models possible is the development of word embeddings: these are mathematical representations of words that capture their meanings much better than older techniques like one-hot encoding. Let’s explore three of the most popular word embedding models, each with its unique approach and contributions to the advancement of natural language processing (NLP).
Word2Vec: Learning Meaning from Context
Developed by researchers at Google in 2013, Word2Vec is a neural network-based method that learns word associations from a large corpus of text. The magic lies in its ability to efficiently transform words into vectors such that words sharing similar contexts have similar representations.
- Skip-Gram Model: Predicts context words given a target word. For example, given the word “cat” in a sentence, the model predicts nearby words (like “pet,” “meow,” and “furry”).
- Continuous Bag-of-Words (CBOW): Predicts a target word from its surrounding context words. If you see “The ___ chased the mouse,” CBOW tries to predict “cat.”
Both techniques help map semantic relationships; famously, vector operations such as King - Man + Woman ≈ Queen work because of how these vectors capture meanings. Word2Vec has been widely adopted and implemented, with code and instruction widely available in resources like the TensorFlow tutorial.
GloVe: Global Vectors for Word Representation
While Word2Vec focuses on predicting words using local context, GloVe (Global Vectors for Word Representation)—developed by Stanford—takes a different route. GloVe constructs embeddings by analyzing word co-occurrence statistics across the entire text corpus, not just within nearby words.
- Step 1: Build a word co-occurrence matrix, where each entry tells you how often one word appears in the context of another.
- Step 2: Factorize this matrix using mathematical techniques to derive embeddings for each word.
- Step 3: These embeddings capture both direct context and broader statistical information about word usage across the entire data set.
GloVe’s global approach helps to better capture subtle relationships. For example, words like “ice” and “steam” may appear in similar local contexts but also demonstrate contrasting relationships with words like “cold” and “hot”—GloVe’s global statistics expertly capture this nuance.
FastText: Understanding Subword Information
FastText was introduced by Facebook AI Research to address a specific limitation present in Word2Vec and GloVe: their inability to handle rare or out-of-vocabulary words efficiently. FastText improves upon this by representing each word as a bag of character n-grams (subword units).
- If the word “unbelievable” is represented, FastText considers components like “un-“, “believe”, “-able,” as well as short character sequences inside the word.
- This technique helps the model understand and create embeddings for words it has never seen before, simply by combining information from the n-grams.
This is especially useful for languages with rich inflection or for technical vocabularies. As a result, FastText can generate meaningful vectors for rare words and misspellings—an advantage for real-world applications. For more technical details, the official Facebook research paper describes the approach in depth.
Together, these models—Word2Vec, GloVe, and FastText—form the foundation for many of today’s advanced NLP systems. Each offers distinctive advantages; understanding their mechanics is key to leveraging AI’s linguistic power for increasingly sophisticated applications. For further reading, consider this comprehensive overview from Machine Learning Mastery.
Visualizing Word Embeddings in Practice
One of the most fascinating aspects of word embeddings is the ability to visualize their structure and relationships in a way that is intuitive and tangible. These visualizations allow us to “see” how words relate to each other in a high-dimensional space—something that adds a new layer of understanding to the phrase “AI understands meaning.” Let’s explore how researchers and developers bring these embedding spaces to life with visualization techniques.
Understanding the Basics of Word Embedding Visualization
Word embeddings, such as those generated by Word2Vec or GloVe, are typically represented as vectors in a high-dimensional space—often hundreds of dimensions. Since humans can’t visualize such high-dimensional data directly, we need to project these vectors into lower-dimensional spaces (usually 2D or 3D) for interpretation. The most common techniques for this projection are t-SNE (t-distributed stochastic neighbor embedding) and PCA (principal component analysis). These methods preserve the structure of the data as much as possible, maintaining clusters of similar words and separating outliers.
Steps to Visualize Word Embeddings
- Obtain a Set of Word Embeddings: Start with a pre-trained model such as GloVe or Word2Vec. These can be downloaded and used in Python with libraries such as Gensim.
- Select a Subset of Words: Visualizing the entire language is impractical, so select a group of words of interest (for example, colors, countries, or professions) to keep the plot interpretable.
- Project Down to 2D/3D: Use t-SNE or PCA to reduce the dimensionality, making sure to document your choice of method and its parameters. Tutorials like the one from Towards Data Science provide accessible step-by-step guides.
- Plot and Interact: Use visualization libraries such as Matplotlib or interactive tools like TensorFlow Embedding Projector. These allow you to zoom in, filter, and highlight relationships between words. Observing which words cluster together can give profound insights into how the AI “views” language.
Real-World Examples of Embedding Visualization
When visualizing word embeddings, clear patterns often emerge. For example, plotting embeddings for countries and their capitals might show them paired together. Similarly, words with gender relationships (like “king” and “queen” or “man” and “woman”) tend to share similar spatial relationships, which is highlighted in classic analogies: King – Man + Woman ≈ Queen. You can explore interactive demos, such as Google’s TensorFlow Projector, to see real embedding spaces and experiment with your own word sets.
Why Visualization Matters for Understanding AI Meaning
Visualization isn’t just a parlor trick—it has powerful implications. Researchers use it to uncover biases and stereotypes embedded in models (read more on this topic from Nature Machine Intelligence), debug models, and inspire new architectures by seeing how clusters form. In industry, these insights can improve search engines, chatbots, and translation services by refining how relatedness is mathematically defined.
Curious minds can further experiment with open datasets and guided projects. For a deeper technical dive, consider the excellent tutorials and code examples from the TensorFlow documentation or hands-on guides available with scikit-learn.
Applications of Word Embeddings in AI
Word embeddings have revolutionized the way artificial intelligence systems process and interpret human language by capturing semantic meaning in mathematical form. Their ability to encode the subtle relationships between words opens up a wide range of powerful applications. Here’s a closer look at how word embeddings are transforming various domains within AI:
1. Natural Language Processing (NLP)
Natural Language Processing forms the backbone of many AI-powered applications, from chatbots to language translation. Word embeddings make it possible for machines to grasp context, synonyms, and even nuances like sarcasm by mapping words to high-dimensional vectors based on their usage in massive datasets. A classic example is GloVe from Stanford, which demonstrates how word relationships can be captured through global word co-occurrence statistics. When these embeddings power tasks such as sentiment analysis, they enable models to better distinguish between positive and negative expressions, even when the sentiment is implicit rather than spelled out.
2. Machine Translation
The ability to convert one language into another smoothly depends greatly on understanding the true meaning of words, phrases, and sentences. Word embeddings underpin many state-of-the-art translation systems by linking words with similar meanings across languages, regardless of spelling or cultural context. Tools like DeepMind’s multilingual embeddings help align vocabulary across languages, making translations more accurate and natural-sounding.
3. Information Retrieval and Search Engines
Modern search technologies, like those behind Google’s BERT algorithm, leverage word embeddings to go beyond simple keyword matching. These systems determine the intent of a user’s query and retrieve the most relevant documents—even if the documents themselves use different vocabulary. By capturing semantic similarity, embeddings help ensure that results match the user’s needs rather than just echoing their exact words.
4. Recommender Systems
Recommender systems, found in platforms like streaming services and e-commerce sites, use word embeddings to understand and anticipate user preferences. By analyzing past behaviors and item descriptions, embeddings can connect users to items they’re likely to enjoy, even if those items don’t obviously resemble previous choices. For instance, if a user often reads articles about “machine learning,” an embedding-driven recommender might also suggest content about “deep learning” or “AI ethics” due to their semantic proximity in the embedding space. The use of word embeddings in recommender systems has been widely documented by leading research teams at companies like Facebook.
5. Question Answering and Chatbots
Virtual assistants such as Siri, Alexa, and Google Assistant rely on word embeddings to understand and respond to user queries effectively. Embeddings allow these systems to “read between the lines” and provide contextually appropriate answers, even if questions are phrased differently than expected. For example, if a user asks, “What’s the weather like in Paris?” or “Is it sunny today in Paris?”—the system can interpret both queries as fundamentally similar using embeddings, leading to a more human-like, intuitive AI interaction. For more on this application, see Microsoft’s exploration of word embeddings in conversational agents.
6. Text Classification and Spam Detection
Word embeddings empower text classification at scale, enabling automated moderation, spam filtering, and topic sorting. By defining the semantics of language mathematically, AI systems can rapidly scan emails or social posts to flag malicious, unwanted, or irrelevant content. For example, detecting phishing emails or social media policy violations becomes increasingly robust as embeddings are trained on larger and more nuanced datasets, as discussed in peer-reviewed literature on language models in security applications.
Through these and other applications, word embeddings act as the bridge enabling machines to genuinely understand language, unlocking the full potential of AI across industries and everyday technology. As research continues to develop, we can expect even greater sophistication in how AIs interpret, reason, and assist based on the subtle shades of human meaning.