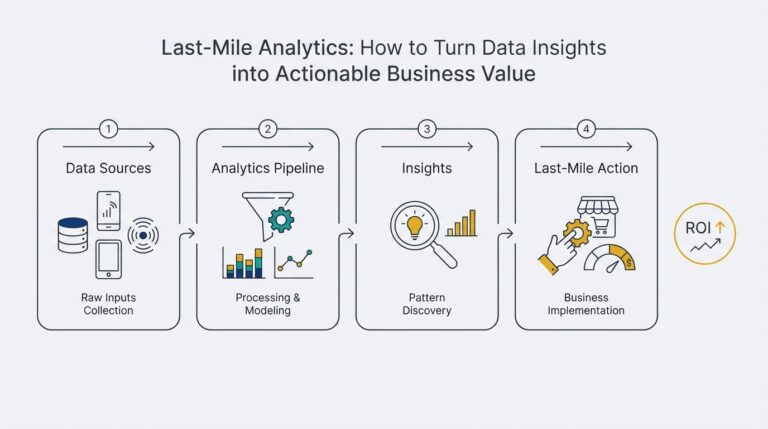
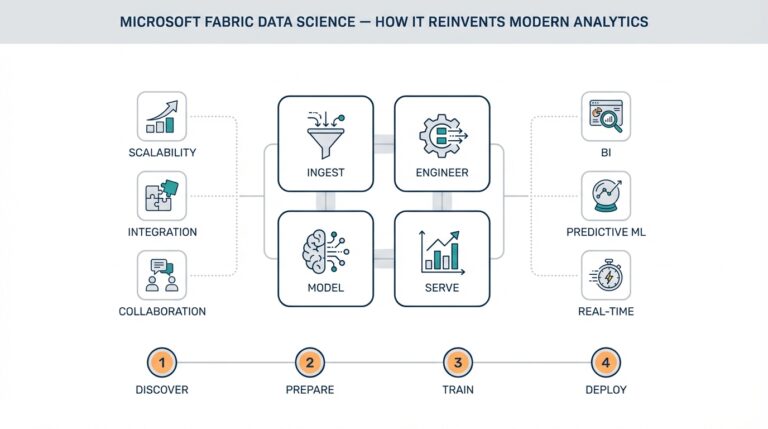
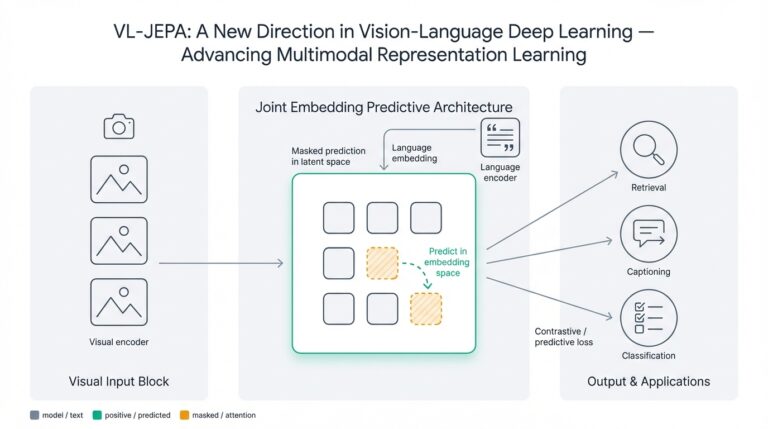
Introduction to LangGraph and MCP Servers
LangGraph is an open-source framework designed to streamline the development of complex, multi-agent language models. It leverages the capabilities of graph-based architectures to allow developers to define workflows where language models interact with each other and external tools. Unlike traditional linear processing models, LangGraph enables branching, looping, and dynamic decision-making, making it a natural fit for applications like voice assistants that require contextual interactions and real-time adaptability. For a deep dive into graph-based AI architectures, you can read more from the original LangGraph research paper on arXiv.
MCP servers, or Multi-Component Processing servers, provide a middleware layer that connects various components involved in a voice assistant setup—such as speech-to-text processing, natural language understanding (NLU), and text-to-speech synthesis. MCP servers handle the orchestration of these components, managing data flow, session management, and real-time communications. Well-known implementations like Facebook’s multimodal voice assistant infrastructure offer a robust example of such architectures in the industry.
To put it simply, if you imagine building your own voice assistant, LangGraph acts as the brain, managing the flow of information and logic, while the MCP Server is the nervous system, ensuring the different senses (listening, understanding, responding) all work seamlessly together. For instance, when a user says “Play some music,” the request flows through the MCP server, which routes it through a transcription service, sends the recognized text to the LangGraph-powered logic engine, and finally delivers a context-aware response that may call upon a music streaming API.
Combining LangGraph and MCP Servers empowers developers to build highly customizable, feature-rich voice assistants. The flexibility of LangGraph allows for easy inclusion of modules such as personalized user profiles, contextual reminders, or third-party integrations, while MCP servers ensure that responses are delivered quickly and accurately. Developers and AI enthusiasts who want to experiment with similar architectures can explore code samples and documentation on repositories such as the official LangGraph GitHub page and comprehensive machine learning middleware discussions at Towards Data Science.
Understanding both LangGraph and MCP Servers lays a strong foundation for developing systems that go far beyond simple query-and-response chatbots. Instead, these tools enable the creation of advanced, interactive digital assistants capable of managing complex, multi-step tasks and maintaining context over longer conversations—qualities that are essential in today’s rapidly evolving AI landscape.
Setting Up Your Development Environment
Before diving into building your custom voice assistant with LangGraph and MCP Servers, it’s vital to establish a robust and efficient development environment. This foundation ensures a smoother workflow, easier troubleshooting, and faster iteration on your voice assistant project. Let’s look at the core elements and steps to get everything set up correctly.
Choosing Your Hardware
Although LangGraph and MCP Servers are flexible enough to run on a range of systems, development is typically more convenient on a machine with multiple cores, at least 8GB of RAM, and sufficient disk space (20+ GB recommended). This is especially true if you plan on handling large datasets or experimenting with advanced speech recognition models. If you’re unsure about your hardware’s capabilities, check out this guide on system requirements from Computer Hope.
Setting Up the Operating System
A Unix-like environment such as Ubuntu Linux or MacOS is often preferred for machine learning and AI development due to better support for open source libraries and tools. For Windows users, setting up the Windows Subsystem for Linux (WSL) enables access to a Linux environment within Windows, making development more convenient and compatible with most guides online.
Installing the Core Dependencies
- Python: Most voice assistant frameworks (including LangGraph) are Python-based. Install the latest stable version from the official Python website. It’s best to use virtual environments (venv or virtualenv) to isolate your project dependencies.
- Node.js: Many MCP Server plugins and integrations leverage JavaScript or Node.js backends. Download and install Node.js from the official Node.js site.
- Git: Version control is critical for tracking changes and collaborating. Install Git from git-scm.com and consider creating a GitHub account to host and share your code.
- Docker (optional but recommended): For advanced setups or to replicate production-like environments, Docker can save hours of troubleshooting dependency conflicts. Learn more about Docker from the official documentation.
Setting Up LangGraph
LangGraph is a powerful open-source framework for managing complex conversational AI workflows. To install it, you can typically use pip:
pip install langgraph
For the latest releases and documentation, check out the LangGraph Documentation. Make sure to review the prerequisites section to ensure compatibility with your current Python version and system libraries.
Getting MCP Servers Ready
The Modular Command Processor (MCP) architecture powers many voice assistant platforms, providing a scalable way to connect modules (plugins) for speech recognition, natural language understanding, and automation. Install the MCP Server framework by following the instructions from reputable repositories or the original MCP documentation.
- Clone the MCP server source code from its official repository.
- Follow build instructions that are specific to your operating system.
- Test the server by running a simple command module—most repos include example plugins.
For hands-on examples, the GitHub community hosts several open-source MCP projects you can use as references or starting points.
Setting Up an IDE or Code Editor
Your development experience can be dramatically improved with a feature-rich IDE. Visual Studio Code is a favorite among Python and JavaScript developers for its extensions, integrated terminal, and debugging tools. Configure your environment with recommended extensions such as Python, Docker, and GitLens for maximum productivity.
Testing Your Environment
Once everything is installed, create a “hello world” script in Python to verify that your environment supports the libraries you need. Optionally, test connectivity between LangGraph and MCP by setting up a minimal workflow—such as recognizing a spoken phrase and logging it to the console. Troubleshooting at this stage is useful, as you can learn about dependency issues or missing libraries early in the process. Refer to Stack Overflow for troubleshooting tips and solutions shared by the developer community.
By taking the time to set up your development environment properly, you’ll be rewarded with fewer hassles down the road and a more streamlined experience as you build out your own custom voice assistant. The next steps will become much easier with this strong foundation in place.
Integrating LangGraph for Natural Language Understanding
One of the most transformative elements in building a sophisticated voice assistant is its ability to comprehend natural language inputs accurately. LangGraph, an open-source conversational AI framework, stands out by providing a robust foundation for natural language understanding (NLU). By leveraging LangGraph’s modular architecture, developers can build highly flexible and intelligent voice-driven applications that adapt to a wide range of user requests.
Why LangGraph for NLU?
LangGraph is designed to orchestrate language model-driven workflows through nodes and edges, creating a graphical structure that maps conversation flows in a logical and easily modifiable manner. This contrasts with traditional intent matching or rule-based systems, allowing for more natural and context-aware dialog management. According to Meta AI, the graphical interface fosters rapid prototyping and adaptation, essential for voice assistants that must handle evolving user expectations.
Step-by-Step Integration of LangGraph for Voice Assistants
- Framework Setup: Start by installing LangGraph and its dependencies in your development environment. Detailed installation steps can be found in the official LangGraph documentation. Setting up a virtual environment is recommended for isolating packages and dependencies.
- Model Selection and Configuration: LangGraph supports integration with state-of-the-art language models like OpenAI’s GPT series or Google’s BERT. Configure LangGraph to use a model that aligns with your requirements for accuracy, speed, and language coverage. This step ensures that your assistant interprets spoken queries with greater nuance.
- Designing Conversational Flows: Use LangGraph’s node-based interface to visualize and construct the flow of conversations. Each node represents a different operation, from parsing user intents to generating spoken responses. This modular approach simplifies the process of updating or expanding the assistant’s functionality as user needs evolve.
- Integrating with Speech-to-Text Engines: For a seamless voice experience, combine LangGraph’s NLU capabilities with reliable speech recognition APIs such as Google Cloud Speech-to-Text or IBM Watson Speech-to-Text. Once the spoken input is transcribed, LangGraph interprets the resulting text and routes it through defined conversational paths.
- Feedback Loops and Continuous Learning: One of the most powerful features of LangGraph is the ability to implement feedback loops for continuous improvement. By capturing real interactions and user corrections, you can retrain your underlying language model and refine the graph over time, as suggested in research from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL). This adaptive approach increases both accuracy and user satisfaction.
Example: Adding a Weather Query Module
Imagine you want your assistant to answer weather-related queries. You would add a specialized node to your LangGraph flow that recognizes weather-related intents. This node would parse requests like “What’s the weather today?” or “Will it rain tomorrow?” and route them to an external weather API, such as The Weather Channel, before returning a spoken response to the user. This modular setup encourages rapid feature expansion while keeping conversational logic manageable.
By adopting LangGraph for natural language understanding, you lay the foundation for a voice assistant that is not only highly capable but also adaptive and maintainable. Whether enhancing user personalization or streamlining new features, the graphical, workflow-driven approach empowers developers to harness the latest advances in NLU for their custom voice projects.
Configuring MCP Servers for Efficient Communication
Setting up MCP (Message Control Protocol) Servers is a critical process for ensuring seamless and efficient communication between the components of your custom voice assistant. MCP acts as the backbone for exchanging messages, orchestrating requests between the user interface, voice engine, and LangGraph-powered natural language processing modules. Let’s take a deep dive into how to configure these servers for optimal performance and reliability.
Understanding the Role of MCP Servers
At its core, an MCP server serves as a message broker, routing requests and responses in a distributed system. By centralizing communication, it eliminates redundancy and potential bottlenecks seen with direct API calls between services. This architecture is increasingly favored in scalable AI applications, as described by leading tech communities like Red Hat’s guide to message brokers.
Choosing the Right MCP Implementation
You have several implementation choices, from open-source frameworks such as RabbitMQ and Apache Kafka, to custom lightweight solutions for simpler deployments. When configuring your MCP server, consider factors such as:
- Latency: For voice assistants, low message delivery time is critical to maintain a natural conversational experience.
- Scalability: An architecture that supports easy scaling, both horizontally and vertically, positions your system for future growth.
- Security: Ensuring encrypted communications and authenticated message endpoints protects sensitive user interactions.
Review benchmarks published by Amazon Web Services for deeper insights on how popular message brokers perform under different scenarios.
Configuring the MCP Server: Best Practices
- Set up Distinct Communication Channels: Segment message channels by function—for example, separate channels for voice input, processing, and output. This reduces cross-talk and improves fault isolation.
- Enable Secure Connections: Leverage protocols like TLS for data encryption in transit. Refer to CSO Online’s guide to SSL/TLS for a technical overview.
- Optimize Message Queues: Fine-tune your queue sizes, timeout intervals, and delivery policies to accommodate burst traffic, which is common in voice interaction scenarios. Monitor real-time metrics to identify and resolve bottlenecks.
- Implement Retry Logic: Design your assistant to gracefully handle dropped messages or failed deliveries. Use retry policies, dead-letter queues, and error logging to boost resilience, as outlined by Martin Fowler.
- Monitor and Scale: Use monitoring tools to track latency, dropped connections, and throughput. Cloud solutions such as Google Cloud Monitoring integrate easily and support proactive scaling based on observed demand.
Example: A Simple MCP Server with RabbitMQ
For developers new to MCP server management, starting with RabbitMQ provides an approachable path. Here’s a high-level example:
# Start RabbitMQ (assuming Docker)
docker run -d --hostname my-mcp -p 5672:5672 -p 15672:15672 rabbitmq:3-management
With the server running, define queues for each service:
rabbitmqadmin declare queue name=voice_input_queue
rabbitmqadmin declare queue name=nlp_processing_queue
Configure each module (e.g., your speech recognizer, LangGraph, and audio output handler) to connect to the relevant queue, ensuring efficient and orderly communication throughout your voice assistant system.
By thoughtfully configuring your MCP servers, you create a robust communication layer that empowers your voice assistant to respond swiftly and reliably. This foundational step supports advanced features such as context-aware dialogue management and real-time feedback, enabling a smarter and more engaging user experience.
Building the Voice Recognition Pipeline
At the heart of any intelligent voice assistant is a sophisticated voice recognition pipeline—a sequence of processes that capture spoken input and transform it into data that an AI can understand and act upon. Integrating LangGraph with MCP Servers opens up exciting opportunities for building a custom solution that fits your specific needs. Let’s explore the essential components and steps to designing an effective voice recognition pipeline.
1. Capturing Audio Input
The first step is to reliably capture audio from the user. Whether you’re using a microphone on a local device or a remote client sending audio over the network, ensuring low-latency and high-fidelity recording is crucial. You can use libraries such as PyAudio for Python, or leverage Web Audio API for browser-based interfaces. The MCP Server facilitates audio streaming to your backend where LangGraph processes it.
- Use audio buffers to stream data in real time.
- Implement silence detection to start and end recordings at the right moments.
- Optionally, preprocess audio to remove noise using digital filters or pre-built libraries like Audacity.
2. Speech-to-Text Transcription
Once audio is captured, the next challenge is transcription. This is where Automatic Speech Recognition (ASR) models come in. You might choose an open-source solution such as OpenAI Whisper or commercial APIs like Google Speech-to-Text. The choice depends on your privacy requirements, desired languages, and budget.
- Stream the audio buffer to the ASR engine.
- Receive and process text output, handling special cases for accuracy improvements (such as domain-specific terms).
- Store both the raw audio and transcribed text for future analysis or improvements.
3. Integrating with LangGraph
After transcription, the textual data is sent to LangGraph for natural language understanding and orchestration. LangGraph allows for modular pipelines, so you can plug in custom logic to handle commands, context switching, or even multi-turn conversations. This modularity is key for maintaining and expanding your assistant’s capabilities over time.
- Create intent detection nodes to parse user requests.
- Deploy entity extractors to identify and act on important details (e.g., dates, locations).
- Use LangGraph’s workflow orchestration to pass information between nodes, enabling complex interactions.
4. Real-Time Feedback and Error Handling
Providing immediate, user-friendly feedback is essential for a natural voice assistant experience. Implement mechanisms to confirm what was heard, ask for clarification if needed, and gracefully handle unrecognized input. Many modern assistants use text-to-speech (TTS) systems to speak back responses—you can use engines like Google Cloud TTS or open-source alternatives such as Mozilla TTS.
- Send confirmation messages via TTS after successful transcription and understanding.
- Log errors and provide actionable prompts for improvement (e.g., “I didn’t catch that, could you repeat?”).
- Continuously monitor pipeline performance to improve robustness and user satisfaction.
By laying out your voice recognition pipeline in clearly defined steps and leveraging powerful tools like LangGraph and MCP Servers, you create a scalable foundation for your custom voice assistant. This thoughtful design allows for future integration of advanced features, such as contextual awareness or smart home connectivity. For a deeper technical dive into voice recognition architectures, consult the classic research overview at ScienceDirect and practical tutorials from Real Python.
Handling Intents and Responses
To build an effective voice assistant using LangGraph in conjunction with MCP servers, one of the core challenges is managing the connection between what a user says (the intent) and how your assistant should respond (the response). Let’s explore in detail how to structure and handle intents and map them to dynamic, relevant replies.
Understanding User Intents
When a user interacts with your voice assistant, they typically issue commands or ask questions in natural language. An intent represents the underlying goal or purpose of each user utterance. For example, when someone says, “Turn on the kitchen lights,” the intent is to activate a device in a specific location.
Accurately identifying these intents is foundational. Most modern voice assistants use machine learning models, often trained on hundreds or thousands of example phrases, to classify incoming speech. Frameworks powered by Rasa NLU or similar libraries can be used to extract intents efficiently.
Building an Intent Schema
Begin by outlining a list of common intents your assistant should recognize:
- Greeting (e.g., “Hi”, “Hello”)
- Device Control (e.g., “Turn off the fan”)
- Information Retrieval (e.g., “What’s the weather today?”)
- Reminder Setting (e.g., “Set a reminder for 5 PM”)
- Chit-chat (e.g., “Tell me a joke”)
Define training phrases for each intent, then use LangGraph APIs to connect your assistant’s NLU pipeline, which could be custom or based on well-established open-source tools.
Connecting Intents with MCP Server Logic
The MCP (Message Communication Protocol) server operates as the intermediary between your language model and external devices or databases. When LangGraph deciphers an intent, it crafts a structured message, usually as JSON, and relays it to the MCP server. The server parses this intent, triggering the real-world action or fetching the requested data.
For instance, given the intent to “turn on the lights,” LangGraph could output:
{
"intent": "turn_on_device",
"device": "lights",
"location": "kitchen"
}The MCP server interprets this command and communicates with a smart home API. This modular architecture is similar to how commercial assistants like Amazon Alexa operate with Alexa Skills.
Generating Adaptive Responses
Once the action is executed, the system needs to craft a response that feels natural. Here’s how you can achieve this:
- Template-Based Responses: For straightforward intents, such as confirmations, use basic response templates. For example: “I’ve turned on the kitchen lights.”
- Context-Aware Replies: Leverage LangGraph’s state management to include context. If a user asks, “Is the kitchen light on?” after the above command, your assistant should answer based on real-time feedback from the MCP server.
- Fallback Handling: When the assistant cannot parse the intent, provide helpful clarifications or ask for more information. This ensures continuity and a better user experience. The Google AI Blog provides insight into dialogue fallback strategies.
Continuous Improvement
As you gather user interaction data, review mismatched intents and update your intent schema for accuracy. Integrate feedback loops—popular in research showcased at NAACL—to refine your system and better anticipate user needs over time.
Effectively mapping intents to well-tailored responses is what distinguishes a robust, conversational voice assistant. By leveraging LangGraph’s natural language capabilities and MCP server’s operational power, you establish a responsive and intelligent bridge between voice commands and real-world actions.
Testing and Improving Your Voice Assistant
Once you have your voice assistant running on LangGraph and MCP Servers, the next step is to rigorously test and continually improve its performance. This process ensures that your assistant delivers accurate, reliable, and contextually appropriate responses, enhancing its value and user experience. Below, we break down the essential aspects of testing and improving your custom voice assistant.
Establishing an Effective Testing Framework
Creating a robust testing framework allows you to evaluate your assistant’s strengths and identify areas for improvement. Here’s how you can approach this:
- Develop a Comprehensive Test Suite: Start by listing real-world scenarios your users might encounter. Include a variety of queries covering different accents, question complexities, and phrasings. Tools like Amazon Mechanical Turk can help crowdsource diverse voice samples for your test cases.
- Automate Regression Testing: As you update your assistant, automate certain tests to catch regressions early. Utilize open-source test platforms like Pytest for Python scripts or integrate continuous testing within your CI/CD pipeline.
- Track Key Metrics: Measure accuracy, response time, and user satisfaction. Tools such as Google Analytics or Microsoft’s Application Insights can help by providing in-depth analytics and error tracking.
Collecting and Analyzing User Feedback
User feedback provides actionable insights into how your assistant performs in the real world. Here are some effective feedback strategies:
- Build Feedback Loops: Add mechanisms for users to rate responses or flag errors directly from your assistant interface. Review flagged interactions regularly and prioritize common issues or critical failures.
- Leverage User Surveys: Periodic surveys help gather qualitative feedback. Tools such as Qualtrics make designing and collecting survey data easier.
- Analyze Usage Patterns: Examine logs to identify phrases that result in errors or timeouts. Improving these weak spots can yield significant improvements, as described in resources such as Nielsen Norman Group’s user feedback primer.
Iterative Improvement and Model Retraining
Voice assistants thrive on iterative updates. By retraining your models and optimizing your prompt configurations, you ensure ongoing relevance and accuracy. Here’s how to proceed:
- Refine Natural Language Understanding (NLU): Use user errors or misunderstood queries as new training data. Resources like Google’s ML Text Classification Guide provide excellent starting points for refining classifiers.
- Adjust Voice Recognition Settings: If you notice consistent misrecognition patterns, tweak your recognition parameters or integrate domain-specific vocabularies, as recommended by IBM’s Speech-to-Text documentation.
- Conduct A/B Testing: Experiment with multiple response strategies. A/B testing reveals whether new prompt templates or changes improve user satisfaction metrics.
Preparing for Edge Cases and Failures
Voice assistants inevitably encounter ambiguous or unexpected queries. Preparing for these cases leads to a more resilient system:
- Design Fallback Responses: When the assistant is uncertain, offer helpful clarifications or guide users on rephrasing. Best practices are discussed in this Alexa skill fallback resource.
- Perform Stress Testing: Simulate large volumes of requests to ensure your MCP Servers and LangGraph instance handle load gracefully. Research best practices from industry leaders like Microsoft Azure’s load testing guide.
Continuous Learning and Community Engagement
Staying engaged with the voice assistant and AI developer communities helps you learn from peers and stay on the cutting edge. Participate in forums such as AI Stack Exchange or contribute to open-source projects related to voice tech. Continuous learning ensures your assistant benefits from best practices and innovations as they emerge.
By systematically testing and iteratively improving your voice assistant, you not only future-proof your solution but also deliver a consistently high-quality experience for your users. Remember, the goal is continual, measurable improvement—consider each cycle as an opportunity to make your assistant smarter, faster, and more adaptable.