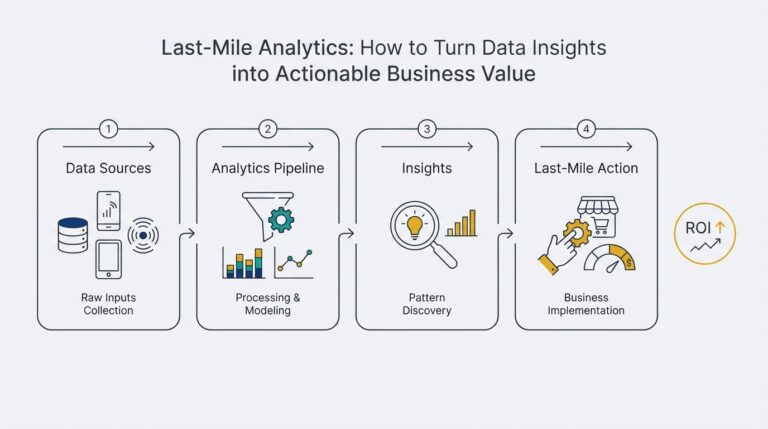
Client Sends Message
You hit Send and the client immediately begins turning your text into a formal ChatGPT API request: it serializes your message into a JSON payload, attaches authentication, and chooses an appropriate transport (HTTP POST for standard completions or a realtime channel for low-latency streaming). This moment—when the client takes your words and converts them into a request payload—is where many integration bugs appear: malformed JSON, missing headers, or the wrong endpoint will cause the message delivery to fail before the model ever sees it. How do you know the message actually left your app, and what guarantees do you get about delivery and response behavior? We’ll walk through the concrete steps your client performs and why each matters. (platform.openai.com)
The client assembles a messages array that represents conversation state: developer/system instructions (high-priority), user inputs, and any assistant messages you want to replay as context. Each entry has a role and content, and the model processes messages in order—so order, role, and content types are critical to the result you’ll get back. Keeping that structure correct prevents surprising outputs and lets you implement useful patterns like system-level safety instructions or progressive prompt compression when history grows too large. (platform.openai.com)
Next is transport: for most apps you’ll issue an HTTPS POST to /v1/chat/completions and receive either a complete response or a streamed sequence of chunks; for sub-100ms latency use cases you’ll open a WebSocket or WebRTC realtime session and stream tokens in both directions. Streaming changes how you handle partial output and errors: you must assemble chunks, handle out-of-order or truncated frames, and decide when to render intermediate tokens to users. Choosing the right transport directly affects perceived latency and resource usage, so pick POST for simple request/response flows and Realtime/WebSocket for interactive voice or live typing experiences. (platform.openai.com)
Authentication and token accounting are two invisible but decisive parts of message delivery. Your API key (or realtime session secret) is sent in an Authorization header, and the size of your request and expected response is measured in tokens—both input and generated output count toward token quotas; that token usage ties directly into rate limits and billing. If you send very long contexts or expect large completions, the request payload can push you into token or RPM/TPM throttling, which changes how quickly your messages will be accepted and processed. Plan prompts and max_tokens accordingly to avoid unexpected rate limiting. (help.openai.com)
Clients must handle network errors, 429s, and transient failures gracefully: implement exponential backoff, honor Retry-After headers, and surface clear retry semantics to callers. Servers and gateways often return standard headers (Retry-After, X-RateLimit-Remaining, X-RateLimit-Reset) so your client can back off intelligently instead of hammering the API; include idempotency or request IDs if your workflow cannot tolerate duplicate actions. These patterns reduce error rates in production and keep your message delivery reliable when usage spikes occur. (makeaihq.com)
For a practical pattern, send a compact messages array and request streaming when you want immediate feedback; fall back to a blocking POST for batch jobs. For example, a minimal curl POST uses a messages array with a developer and user entry and returns a completion object you can parse for content and token usage. This gives you both the concrete response to show users and the usage metadata to manage quotas and costs. In the next section we’ll take these client-side responsibilities and show how serverside routing, queuing, and observability complete the end-to-end message delivery picture. (platform.openai.com)
Network Transport and Encryption
Building on this foundation of client-side request assembly and transport choice, the network layer is where confidentiality and integrity are decided. You choose a transport (HTTPS, WebSocket, WebRTC) in the client, but the network transport and encryption you configure determine whether that payload can be observed or altered in flight. Treat this layer as part of your security contract: it enforces API key confidentiality, protects user inputs, and bounds where plaintext is acceptable. Early decisions here change operational procedures downstream—logging, inspection, and troubleshooting all rely on whether traffic is encrypted end-to-end or terminated at a gateway.
At the protocol level, TLS is the dominant mechanism for encryption in transit; modern deployments should default to TLS 1.3 for both HTTPS and WSS connections. How do you verify the server and avoid man-in-the-middle attacks? Rigorously validate certificates (not just expiration), prefer certificate chains that use strong cipher suites, enable OCSP stapling to avoid blocking checks, and implement session resumption to reduce handshake overhead. TLS 1.3 simplifies handshakes and removes legacy ciphers, improving both latency and security, but features like 0-RTT introduce replay risks you must understand before enabling them for sensitive payloads.
For realtime streams, WebSocket over TLS (wss://) and WebRTC provide distinct security properties that affect your design. WebSocket keeps the same TLS protection semantics as HTTPS, which makes it straightforward to reuse existing certificate tooling and firewall rules for streaming tokens and chunks. WebRTC uses DTLS for key exchange and SRTP for media encryption, delivering end-to-end media protection across NATs and peer connections; choose WebRTC when you need low-latency audio/video with browser-native encryption and TURN fallback for connectivity.
Operationally, TLS termination changes who can inspect ciphertext and where you can enforce application policies. Many architectures terminate TLS at an edge load balancer or CDN, then forward plaintext to internal proxies for routing and observability. That model simplifies logging and web application firewalling but breaks end-to-end encryption guarantees and increases blast radius for key compromise. If you need stronger assurances, adopt mutual TLS between internal services so client certificates authenticate services and remove ambiguity about which component can read message contents.
Certificate lifecycle and secret management are everyday engineering problems that directly affect uptime and security. Automate issuance and renewal (ACME-style tooling), rotate private keys on a schedule, and store certificates and API keys in a secrets vault with strict access controls. Be cautious with certificate pinning: it can protect against rogue CAs but complicates rotation and rollback; use pinning only for high-assurance clients. Monitor TLS metrics—handshake failures, expired certs, deprecated cipher usage—and alert on anomalous trends so you catch misconfigurations before they impact users.
In practice, aim for a layered approach: enforce TLS 1.3 for all public endpoints, use mTLS for service-to-service authentication, and preserve end-to-end encryption for particularly sensitive streams. Instrument your ingress and internal proxies so you can correlate delivery guarantees with encryption state, and document where plaintext is allowed and why. These rules let you preserve the delivery guarantees discussed earlier while keeping keys and tokens safe in transit—next we’ll trace how those encrypted requests flow through server-side routing and queuing so you can see where additional controls belong.
Tokenization and Input Encoding
Building on this foundation of client-side request assembly and transport, the first transformation your text undergoes on the way into a model is tokenization and input encoding—the noisy, technical step that determines what the model actually “sees.” This phase isn’t cosmetic: it converts human-readable characters into the discrete units that drive attention, positional indexing, and billing. If you ignore how tokens are produced and encoded, you’ll mispredict costs, hit unexpected token limits, and introduce subtle bugs when truncating or replaying conversation history.
Tokenization splits raw text into subword units called tokens; input encoding then maps those tokens to integer IDs in the model’s vocabulary. Tokenizers commonly use byte-pair encoding (BPE) or unigram methods and often operate at the byte level to ensure deterministic handling of UTF-8. For example, the simple string “Hello, world!” might produce tokens like [“Hello”, “,”, ” world”, “!”] which then become numeric IDs the model processes. Understanding that tokens are subword fragments—not words—helps explain why a long variable name or a URL can blow up token counts unexpectedly.
Input encoding goes beyond token splitting: it assigns token IDs, applies positional indexing, and feeds token sequences into embedding tables that the model consumes. These embeddings are the numeric vectors the network uses to compute attention and generate outputs. How do tokens map to bytes and why does that matter? Byte-level tokenizers map every UTF-8 byte deterministically, which avoids failure cases for odd characters, but can increase token counts for languages or scripts with multi-byte characters—so encoding decisions directly affect both model accuracy and billing.
For you as an engineer, token accounting is a practical, day-to-day concern: every input token counts toward rate limits and cost, and truncation strategies shape model behavior. Measure tokens before you send them—use the official tokenizer library for your model (for example, call tokenizer.encode(text) in your client) to compute precise token usage and simulate truncation. When you need long context, prefer progressive summarization or selective replay of high-signal messages rather than naive truncation; that keeps the most relevant instructions and reduces the chance that a safety or system instruction will be dropped.
There are common pitfalls that cause production surprises: inconsistent tokenizer versions between client and server, Unicode normalization differences (NFC vs NFD), and special tokens that signal system-level behavior. Emojis, zero-width characters, and language-specific scripts can expand token counts and change semantics; code snippets and diffs often tokenize into many small subword tokens, increasing both latency and cost. Mitigate these risks by normalizing text, validating client/server tokenizer parity, and adding quick unit tests that show how typical inputs (prompts, code, logs) tokenize and where truncation will occur.
Taking this concept further, tokenization and input encoding are the bridge between the transport layer and server-side routing where queuing, batching, and priority scheduling make different trade-offs. As we move to server-side queuing and observability, keep token-aware metrics in your telemetry—track token distribution per request, truncation rates, and tokenizer mismatches—so you can correlate delivery and billing anomalies with the exact encoded inputs the model received. That instrumentation makes the next stage of our traceable, reliable pipeline practical and debuggable.
Context Assembly and Prompts
When you stitch together the bits that actually shape a model’s reply, the difference between a useful answer and an irrelevant tangent often comes down to how you assemble context and craft prompts. In practical systems we treat prompt engineering as a subscription of patterns—templates, prioritized instructions, and selective history replay—that determine what the model “sees” inside the context window. If you want predictable behavior at scale, start by treating prompts as code: testable, parameterized, and versioned. That mindset prevents brittle integrations where small phrasing changes suddenly break downstream automation or escalate costs through unexpected token usage.
Order and role matter more than wording alone. Put the highest-priority directives in a system instruction so they survive downstream truncation and enforce constraints across user turns; follow that with any developer or assistant messages you must replay, and append the user input last so it’s freshest in the model’s attention. We prefer explicit instruction hierarchy because the model processes messages in sequence—so a system instruction placed after user content can be ignored or misapplied. Where you need different behaviors across endpoints, parameterize the system instruction rather than hard-coding new prompts in your client; that enables safer rollout and easier auditability.
Rather than replaying an entire conversation, use retrieval and summarization to keep only high-signal context in the messages array. For long-lived chats, compute embeddings for each turn, fetch top-k relevant items for the current query, and include those as compact, labeled entries (for example as a brief “context_summary” assistant message). If the combined token count exceeds your context window, apply progressive prompt compression: summarize older segments into increasingly coarser summaries and promote only the distilled facts and constraints back into the messages array. This pattern reduces cost and latency while preserving the semantic cues the model needs for accurate responses.
Protect instructions and secrets by design. Place immutable policies, safety rules, and sensitive configuration in system instruction entries that are stripped from user-visible logs, and keep any API keys or PII out of the prompt body entirely. Instruction injection is a frequent root cause of failure: a user-supplied snippet can accidentally override behavior if you naively concatenate content. We recommend redaction and canonicalization stages before assembling the messages array, plus an allowlist for user fields that may be forwarded to the model.
Prompt templates and dynamic parameter substitution accelerate consistency and testing. Create templates that accept typed slots (e.g., task, audience, constraints) and render them server-side so clients only provide values, not raw instruction text. This separates prompt engineering from client code and lets you run unit tests against deterministic template renders. Also tune model parameters—temperature, max_tokens, top_p—alongside the prompt; the same text at temperature 0.0 behaves very differently than at 0.8, and those choices interact with your truncation strategy and token accounting.
How do you validate that your prompts produce reliable, auditable outputs? Treat prompts as first-class artifacts in your CI pipeline: snapshot rendered prompts, run synthetic queries, assert on presence/absence of critical phrases, and measure hallucination or factuality against a ground truth. Instrument telemetry to record token usage per prompt, truncation events, and retrieval hits so you can correlate user-facing regressions with changes in prompt composition. Run A/B experiments on prompt variants to balance cost, latency, and fidelity before rolling a change to production.
Building on the transport, tokenization, and security practices we discussed earlier, adopt a layered prompt strategy that merges compact summaries, prioritized system instructions, and retrieved high-signal content into a tightly constrained messages array. That approach preserves the most important instructions inside the context window, minimizes token waste, and gives you clear levers—templates, retrieval thresholds, and compression policies—to iterate safely. In the next section we’ll trace how these assembled prompts flow through server-side routing and observability so you can see exactly where behavior diverges and why.
Model Inference and Sampling
When your assembled prompt reaches the model, the engine converts tokens into a probability distribution and iteratively selects the next token—that probabilistic loop is where inference and creative control meet. How do you choose between deterministic decoding and probabilistic sampling? We’ll look at what the model computes for each token, the knobs you can turn (temperature, top_p, top_k), and why those choices change behavior, latency, and safety in production systems.
At every decoding step the model emits logits: raw, unnormalized scores for each vocabulary token. We apply a softmax to those logits to get a probability distribution; this distribution is the fundamental object of inference because it encodes the model’s uncertainty about “what comes next.” Logits are affected by attention, positional context, and any cached past-key-values, so your prompt composition and context assembly directly shape those probabilities before sampling or search occurs.
You can turn that probability distribution into actual text with several decoding strategies, each with different trade-offs. Greedy decoding picks the argmax and tends to be deterministic but repetitive; beam search keeps multiple high-scoring hypotheses and favors coherence at the cost of compute; stochastic methods like top-k and nucleus (top_p) sampling add controlled randomness for variety and creativity. Temperature rescales logits before softmax to make the distribution sharper (temperature < 1) or flatter (temperature > 1), so choosing temperature and top_p together lets you control diversity and tail-risk—use lower temperature and top_p near 0.9 for conservative expansion, higher values for creative drafts.
Here’s a minimal pseudocode example showing parameter wiring we use in production to toggle behavior quickly. Set temperature=0.0 for deterministic answers (good for canonical responses), or temperature=0.7 with top_p=0.9 when you want more varied outputs for creative writing.
# render policy
logits = model.step(context)
probs = softmax(logits / temperature)
probs = apply_top_p(probs, p=top_p)
token = sample_from(probs) # or argmax for greedy
Understanding the practical trade-offs is crucial for choosing defaults that match product goals. Deterministic decoding reduces variance and simplifies testing and auditing, so customer support, billing text, or safety-critical instructions should bias toward temperature=0.0 or greedy/beam search. Conversely, marketing copy, brainstorming assistants, or social bots benefit from stochastic sampling to avoid repetitive outputs; in those cases we tune temperature and top_p while monitoring hallucination rates and token cost.
Operationally, inference behavior also interacts with latency and throughput. Batching many requests increases GPU utilization but amplifies tail latency and reduces per-request reproducibility; caching past-key-values (KV cache) for conversational contexts reduces compute per token and is essential for low-latency streaming. Quantization, mixed-precision FP16, and CPU/GPU placement further change cost and speed—so when you pick a sampling strategy, test it under realistic traffic with your model quantization and batch sizes to understand real-world performance.
Reproducibility and safety deserve particular attention because per-token sampling can produce divergent outputs from tiny RNG differences. If you need deterministic replays for audits, seed your PRNG and prefer deterministic decoders; if you allow randomness, log token-level probabilities and sample seeds so you can reconstruct outputs. For safety, add post-sampling filters that reject low-probability sequences or apply safety classifiers to sampled candidates before presenting them to users.
Instrumenting inference metrics makes these trade-offs visible and actionable as you scale. Log latency, throughput, average entropy of the next-token distribution, and truncation events so you can correlate sampling settings with hallucination, user satisfaction, and cost. With those signals in place we can decide whether to lower temperature, tighten top_p, or switch to beam search under specific routes—next we’ll trace how server-side routing and observability capture these decisions in real time.
Safety Checks, Logging, and Delivery
Building on the transport, tokenization, and prompt assembly we just discussed, the next critical layer enforces safety and observability before your users ever see a response. You face three simultaneous requirements: prevent harmful or private content from leaving your system, record enough information to debug and audit interactions, and guarantee message delivery semantics under network and rate-limit pressure. If any of those fail, you expose users to risk, investigators to blind spots, and operators to outage storms. We’ll treat safety checks, logging, and delivery as a single, instrumented pipeline so each decision can be traced and reasoned about in production.
Start by placing safety checks at well-defined points: pre-send, in-flight, and post-generation. At pre-send we sanitize and redact user-supplied fields to remove PII and secrets and run allowlist/denylist filters where applicable; in-flight checks validate message shape, token counts, and rate limits so malformed requests get rejected early; post-generation safety classifiers evaluate model output for policy violations (toxicity, disallowed content, leakage of secrets) before rendering. How do you balance latency and thoroughness? Use fast, conservative synchronous checks for high-risk paths and enqueue deeper, asynchronous review or human-in-the-loop workflows when a classifier flags ambiguous cases. This staged approach minimizes false negatives while keeping median latency acceptable.
Decide exactly what you record and how. Log structured metadata—request id, correlation id, model version, truncated token counts, sampling parameters, and safety decision outcomes—rather than raw prompts or full completions. Keeping logs JSON-formatted makes them machine-queryable and easy to feed into SIEMs, observability backends, or compliance archives; however, avoid writing PII, secrets, or sensitive user data into logs in plaintext. Use deterministic redaction or tokenization for any snippet you must retain for debugging, and enforce RBAC on log storage so only authorized auditors can retrieve full traces. Retention windows, encryption-at-rest, and immutable audit trails are vital for compliance and post-incident forensics.
Delivery guarantees must be explicit in your API contracts and instrumentation. Implement idempotency keys for at-least-once paths where duplicate downstream actions are unacceptable; support client-visible retry headers and surface Retry-After and X-RateLimit-* metadata so callers can back off responsibly. For streaming use cases prefer a persistent channel (WebSocket/WebRTC) with sequence numbers and ack/NACK semantics so you can resume or replay tokens without user-visible corruption; for batch workflows a blocking POST with strong idempotency and server-side deduplication often suffices. When retries occur, correlate them with the original request id in logs so you can distinguish transient network retries from logical duplicate submissions.
Observability ties all three concerns together: correlate safety classifier metrics, logging events, and delivery traces in a single dashboard so you can answer questions like “Which prompt templates correlate with safety rejections?” or “When did a particular model version start producing higher latency?” Instrument token-level metrics (tokens in, tokens out), classifier confidence scores, rejection rates, and delivery latency, then create meaningful alerts—e.g., sustained increase in safety-rejection rate or a spike in truncated prompts—that trigger automated mitigations such as throttling, model rollback, or deeper human review. Distributed tracing and sampled full-trace capture let you reconstruct incidents end-to-end without storing every piece of content forever.
Operationalize these controls through codified rules, automated tests, and runbooks. Treat safety rules and logging schemas like code: version them, review changes in CI, and run synthetic queries that assert expected classifier behavior and log formats before deployment. Define retention and access policies that satisfy legal and business constraints, and schedule periodic audits of redaction efficacy and classifier drift so you don’t accumulate silent failures. With these practices in place we keep user trust intact while maintaining the telemetry and delivery guarantees operators need—next we’ll trace how these instrumented requests move through server-side routing and queuing so you can see where additional controls belong.