Introduction to YOLO Models and Their Evolution
The world of object detection has advanced immensely over the years, and the “You Only Look Once” (YOLO) model series stands as a pioneering force in this domain. Initially developed by Joseph Redmon in 2016, YOLO disrupted traditional approaches by offering a real-time object detection framework that significantly improved speed and accuracy.
YOLO models operate on the principle of dividing an image into a grid and predicting bounding boxes and class probabilities for each grid cell simultaneously. This allows the model to view the image once and make predictions, reducing computational complexity and enhancing efficiency.
The evolution of YOLO has seen significant leaps in performance and capability:
YOLOv1 introduced the foundational architecture, utilizing a single convolutional network to predict multiple bounding boxes and their corresponding classes. It revolutionized fast object detection, but it did struggle with localization errors and was prone to making predictions for adjacent objects.
YOLOv2 (also known as YOLO9000) came with improved strategies to overcome these limitations. Incorporating various advancements such as batch normalization, high-resolution classifiers, and the use of anchor boxes, YOLOv2 drastically enhanced detection accuracy. One of the celebrated features was its capability to recognize over 9,000 object categories due to its novel hierarchical view of object classification.
YOLOv3 elevated the model’s robustness by introducing a better feature extraction network called Darknet-53, which allowed for multi-scale predictions improving detection on smaller objects while maintaining real-time processing speeds. YOLOv3 also improved upon the anchoring mechanism, making it more versatile and applicable to a broader range of object sizes.
YOLOv4 further optimized the real-time performance while maintaining accuracy, with emphasis on general-purpose optimizations rather than architecture-specific tweaks. YOLOv4 integrated techniques like auto-augmentation, bag of freebies, and bag of specials, significantly boosting performance.
YOLOv5, although not developed by the original creators, became popular for its ease of use and implementation, attributed to the integration of PyTorch. It featured further simplifications in hyperparameter management and architecture tweaks to enhance usability for industry applications.
YOLOv6 and beyond continued to refine the model, focusing on efficiency and scalability, allowing developers to balance accuracy and speed according to project needs. The implementation of novel optimization techniques and improved architectures reflected the ongoing commitment to maintain YOLO’s position at the forefront of object detection technology.
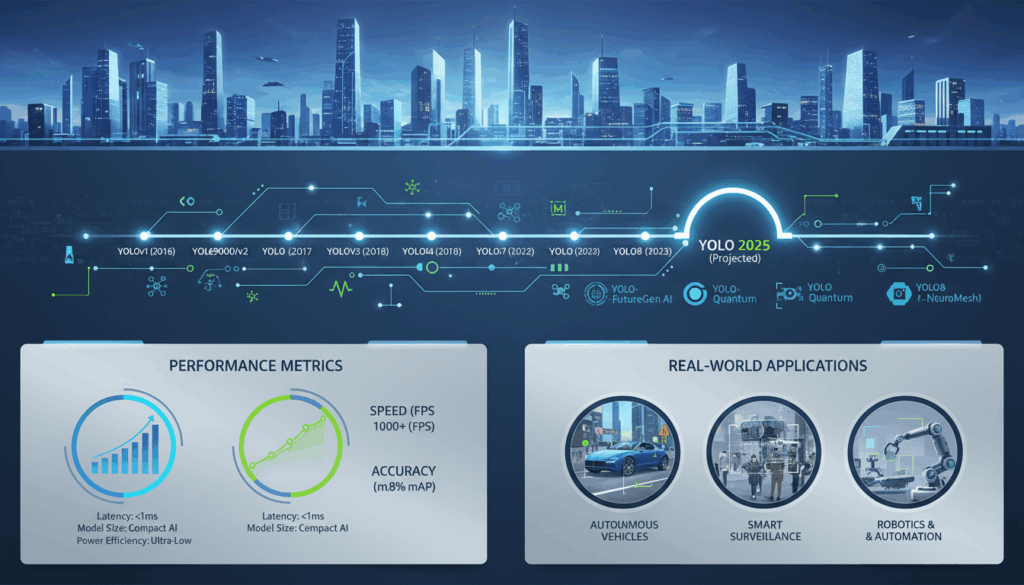
Looking ahead, the future YOLO iterations are likely to be marked by further advancements that accommodate more complex tasks like real-time video analytics, edge computing compatibility, and integration with machine learning pipelines. As the YOLO models continue to evolve, their versatility and ability to adapt to ever-changing demands make them a continued cornerstone in the field of computer vision.
Key Features and Improvements in YOLOv12
YOLOv12 represents the next frontier in the YOLO series, bringing a host of features and improvements that cater to the demands of modern object detection tasks in 2025 and beyond. This version builds upon the legacy of its predecessors by incorporating cutting-edge techniques that improve both the efficacy and versatility of the model.
One of the standout features is the introduction of a novel dynamic attention mechanism. This mechanism allows YOLOv12 to adjust the focus of its attention dynamically during inference. By shifting the attention weights based on context and input characteristics, the model can more accurately and efficiently detect objects within diverse scenes. This dynamic approach is particularly beneficial in cluttered or clutter-prone environments where distinguishing between overlapping objects becomes critical.
Building on the success of scaling strategies from previous versions, YOLOv12 integrates flexible neural architecture search (NAS) methodologies. This enables the model to automatically adapt its architecture to different computational budgets and target hardware platforms. The integration of NAS helps optimize the balance between accuracy, speed, and resource consumption, ensuring that YOLOv12 can be deployed efficiently across edge devices or scalable server environments.
A key improvement in YOLOv12 is its focus on improved real-time processing capabilities. Leveraging advancements in parallel computing and asynchronous data pipelines, YOLOv12 significantly reduces latency during model inference. This makes it ideal for applications requiring instantaneous object detection results, such as autonomous driving systems and real-time surveillance operations.
The architecture of YOLOv12 has been refined to enhance its capacity to detect small and distant objects. This improvement is achieved through the use of a more intricate feature pyramid network (FPN). The enhanced FPN augments the model’s ability to create richer representations of input data by capturing finer details across different scales, thus improving detection performance for objects that would typically be missed by less sophisticated models.
YOLOv12 also emphasizes robustness to adversarial attacks. With adversarial learning frameworks integrated into its training regime, YOLOv12 can withstand and accurately classify objects even under adversarial conditions. This robustness is critical in environments where security and precision are paramount, such as military and critical infrastructure monitoring.
Lastly, YOLOv12 includes eco-friendly training protocols that minimize the environmental impact of model training. By using energy-efficient training algorithms and techniques such as distributed training on low-power devices, YOLOv12 reduces its carbon footprint, aligning with global sustainability goals while maintaining high performance standards.
In totality, YOLOv12 sets a benchmark for the future of object detection by enhancing adaptability, extending robustness, and optimizing performance, thereby aptly preparing developers and researchers for the challenges of a rapidly evolving computational landscape.
Comparative Analysis of YOLOv12 and Previous Versions
The latest iteration in the YOLO series, YOLOv12, represents a significant progression in comparison to its predecessors. One of the primary enhancements in YOLOv12 is the incorporation of a dynamic attention mechanism. This mechanism intelligently adjusts attention weights during inference, allowing the model to focus on the most pertinent features of images dynamically. Previous versions like YOLOv3 and YOLOv4 utilized fixed attention mechanisms, which, while effective, lacked the ability to adapt to varying complexities within different scenes. Consequently, the dynamism in YOLOv12 lends itself particularly well in scenarios with overlapping objects or densely populated environments, effectively reducing errors in object localization.
Another groundbreaking improvement in YOLOv12 is its innovative use of flexible neural architecture search methodologies. Compared to YOLOv5 and YOLOv6, which used more static architecture optimizations, YOLOv12 allows the architecture to adjust dynamically based on computational resources and specific deployment needs. This means that for edge devices with limited computational power, YOLOv12 can scale down its architecture while maintaining high levels of accuracy, setting it apart from earlier models.
YOLOv12 also showcases substantial advancements in real-time processing capabilities. Leveraging parallel computing paradigms and asynchronous data pipelines, it achieves a noticeable reduction in inference latency compared to models like YOLOv4 and YOLOv5. The reduced delay makes YOLOv12 particularly attractive for real-time applications such as autonomous vehicles, where prompt and precise decision-making is crucial.
Moreover, YOLOv12 features a more sophisticated feature pyramid network to improve detection of small or distant objects. In earlier versions like YOLOv3 and YOLOv4, the feature pyramid networks effectively enhanced multi-scale detection; however, the new design in YOLOv12 captures even finer details across varying scales. This advancement substantially improves the detection accuracy for tiny objects that were challenging for earlier YOLO versions.
A striking difference in YOLOv12 compared to its predecessors is its robustness against adversarial attacks. Prior YOLO models, such as YOLOv2 and YOLOv3, had limited defenses against such threats. By integrating adversarial learning frameworks within its training paradigm, YOLOv12 can maintain performance in adversarial environments, making it ideal for scenarios where security and reliability are essential, such as surveillance and defense systems.
Lastly, YOLOv12 pioneers eco-friendly training protocols. This shift towards sustainability was less pronounced in previous versions. By deploying energy-efficient algorithms and enabling distributed training on low-power devices, YOLOv12 supports environmentally conscious AI development without compromising its capabilities, thereby addressing both technological and ecological objectives in modern AI deployments.
Selecting the Right YOLO Model for Your Application
Choosing the appropriate YOLO model for your application requires a careful assessment of multiple factors, including the specific demands of your project, the computational resources available, and the nature of the objects to be detected. The evolution of YOLO models provides a variety of options, each with strengths tailored to different scenarios.
First, consider the necessity for speed versus accuracy in your application. If absolute speed is crucial, such as in real-time video processing or interactive applications, models like YOLOv4 or YOLOv5 may be suitable due to their balance between speed and performance. YOLOv4, popular for its general-purpose improvements, offers robust real-time capabilities, making it a favorite in high-speed environments. On the other hand, YOLOv5, known for its simplicity and ease of deployment, provides an excellent trade-off between usability and performance, perfect for quick implementations in industry settings.
For applications requiring enhanced precision and the ability to detect smaller or overlapping objects, consider the more recent iterations like YOLOv12. This version incorporates an advanced feature pyramid network and dynamic attention mechanisms, enabling it to excel in environments where detail is paramount. Thus, deploying YOLOv12 in scenarios where object localization and minimizing detection errors are critical, such as autonomous vehicles or intricate surveillance systems, can offer significant benefits.
In scenarios where computational resources are limited, such as edge devices or IoT applications, leveraging the scalability of YOLO models is essential. Models from YOLOv6 onwards often include flexible architecture and optimization strategies that allow them to scale down their computational requirements without dramatically sacrificing accuracy. The neural architecture search (NAS) capabilities integrated into YOLOv12, for instance, provide adaptability, making it suitable for resource-constrained environments while retaining high accuracy.
Additionally, evaluate the diversity of object classes your application needs to handle. Earlier versions, like YOLOv2 with its capability to recognize over 9,000 object categories, remain relevant for applications involving a vast array of object types. More recent models further improve the capability to classify complex or less common objects due to advanced training protocols and dataset integrations.
Another factor is resilience to adversarial conditions. If your application requires fortified security measures or is expected to operate in adversarial environments (e.g., military or secure data settings), YOLOv12’s robust adversarial learning frameworks will be indispensable. These frameworks enhance the model’s ability to withstand and accurately process inputs even under challenging conditions.
Finally, consider sustainability and eco-friendly considerations, particularly if your organization prioritizes green technology practices. YOLOv12 has been designed with eco-friendly training protocols, which minimize its environmental impact during deployment and training. This can be a vital consideration for projects aiming to align with global sustainability goals.
In conclusion, selecting the right YOLO model involves matching the model’s capabilities to your application’s specific needs. By evaluating and prioritizing factors such as speed, accuracy, resource availability, application context, and environmental considerations, you can ensure that the YOLO model chosen not only meets technical requirements but also supports broader project objectives.
Implementing YOLOv12: Practical Considerations and Best Practices
Implementing YOLOv12 requires careful planning and execution to fully harness its advanced features and capabilities. Here we’ll focus on practical considerations and best practices for integrating YOLOv12 into your projects, ensuring optimal performance and ease of use.
Start by ensuring you have a well-prepared computational environment. YOLOv12, with its dynamic architecture, can be resource-intensive depending on the deployment scale. Ensure compatibility with your hardware. For high-speed demands, such as real-time video processing, deploy on powerful GPUs. When working with constrained environments or edge devices, leverage YOLOv12’s flexible neural architecture capabilities to adjust the model’s complexity, ensuring efficient utilization of available resources.
An essential step is installing the necessary software dependencies. YOLOv12 is built with compatibility for platforms like PyTorch or TensorFlow, both of which offer pre-trained models and tools for fine-tuning. Use containerization technologies such as Docker to maintain consistency across different development and production environments. This approach simplifies dependency management and enhances the reproducibility of your experiments.
Data preparation plays a pivotal role in the deployment of YOLOv12. Given its enhanced feature pyramid network, the model can detect objects with greater detail, but it requires a well-curated training dataset. Ensure your dataset is diverse and represents the real-world variance your model will encounter. Use augmentation techniques, such as scaling, rotation, and color adjustments, to enrich your dataset and improve the model’s ability to generalize from training data.
Training and fine-tuning are critical components. Begin by leveraging pre-trained weights available from benchmarking datasets, which can significantly reduce initial training time. Configure hyperparameters appropriately to balance convergence speed and accuracy. YOLOv12 supports advanced hyperparameter tuning facilitated by the integrated architecture search functionality, which can automatically optimize configurations for your specific needs and objectives.
During deployment, real-time processing capabilities can be maximized by using asynchronous data pipelines. This ensures minimal latency in applications requiring immediate feedback, such as autonomous systems or live monitoring setups. Data should be preprocessed efficiently to minimize delays; for instance, by resizing images to optimized dimensions that have been identified during initial tests.
Security and robustness against adversarial conditions are achieved by integrating adversarial training frameworks from the start. Regularly test the model against potential adversarial attacks and refine models as needed to ensure reliability. This approach is particularly important in sensitive applications like surveillance or military operations where data integrity cannot be compromised.
To address considerations of sustainability, employ YOLOv12’s eco-friendly training methodologies if your project’s goals align with reducing environmental impact. Implement distributed training on low-power or renewable energy-supported devices to diminish carbon footprints while maintaining efficiency.
Continuous evaluation and monitoring of the model’s performance post-deployment are crucial. Implement logging and visualization tools to monitor various performance metrics and detect issues promptly. Use platforms such as TensorBoard or custom dashboards to track model predictions, latency, and throughput over time.
Finally, ensure your team is well-versed in the nuances of YOLOv12 through comprehensive training sessions and access to updated documentation and best practice guides. This preparation enables smoother transitions from development to deployment and promotes a culture of proactive management and enhancement within your teams.



