What World Models Are
Building on that foundation, a world model is the part of an AI system that builds an internal picture of how its environment works. Instead of waiting passively for the next input, it learns patterns like cause and effect, then uses those patterns to predict what may happen next. In the classic formulation of this idea, the model is trained from experience, and the agent can use the model’s features to make decisions more efficiently. What does a world model actually do in practice? It acts a little like the mental map you carry when you walk through a familiar neighborhood: you do not re-learn every street from scratch each time, because you already have a sense of where things lead.
That idea becomes more vivid when we think about imagination. A world model does not need to simulate reality perfectly; it needs to simulate reality well enough to be useful. In the original World Models paper, the agent could be trained in its own learned “dream” and then transferred back to the real environment. DreamerV3 pushes the same basic principle further: it learns a model of the environment and improves behavior by imagining future scenarios rather than relying only on direct trial and error. That is why world models are often described as internal simulators, not because they are magical, but because they let the agent rehearse possibilities before acting.
This is where the connection to planning becomes important. Long before modern deep learning made the idea fashionable, Sutton’s Dyna framework already combined learning, planning, and reacting by using a learned model to generate extra experience. In plain language, the agent does not have to wait for the world to hand it every lesson; it can practice with an internal copy of the rules. World models follow that same logic. The difference is that today’s systems usually learn those rules with neural networks, which gives them the flexibility to handle images, motion, and other messy real-world signals.
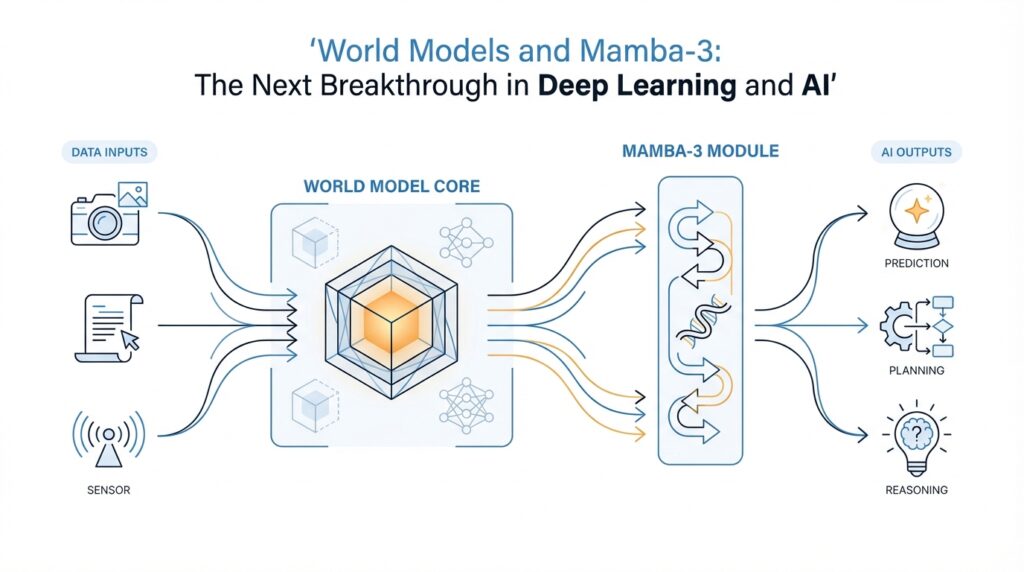
Now that we understand the purpose, let us look at the shape of the idea. In many modern world models, the first job is to compress raw observations, such as pixels from a camera, into a smaller latent space, which means a compact hidden representation that keeps the important information while dropping noise. Then the model learns how that hidden state changes over time, often alongside a reward predictor that estimates whether an action will help. Think of it like turning a noisy movie into a clean storyboard: once the story is shorter and tidier, it becomes easier to predict the next scene. That compression is what makes imagination-based planning practical.
So why does this matter so much? Because real environments are expensive, slow, or dangerous to explore blindly. If you are training a robot arm, a self-driving system, or a game-playing agent, every bad action can cost time, money, or safety. A world model lets the agent try many possible futures inside its own head before it commits to one in the real world. That is one reason model-based reinforcement learning can be so data-efficient: the agent learns from both actual experience and imagined experience, which reduces the need to poke the environment at random until something works.
At the same time, world models are not crystal balls. Because they are learned from data, they can drift, miss details, or become less reliable the farther they predict into the future. That is why strong systems keep returning to real experience and updating the model instead of trusting imagination forever. As we move forward, this is the key question to keep in mind: how do we build a world model that remembers enough, predicts far enough, and stays stable enough to guide action? That question is exactly where the architecture underneath it starts to matter.
Mamba-3 Architecture Basics
Building on this foundation, the Mamba-3 architecture starts with a very practical challenge: a world model has to remember what matters across long sequences without paying the heavy cost of full attention at every step. Mamba-3 takes a state space model approach, which means it carries a compact hidden state forward as it reads the sequence, instead of repeatedly comparing every piece of history with every new token. In the 2026 paper, the authors describe Mamba-3 as an inference-first design aimed at improving both quality and efficiency, especially for retrieval and state tracking.
If that sounds abstract, think of it like keeping a running notebook while following a long recipe. You do not leave every ingredient spread across the kitchen; you keep the useful notes close by and update them as the dish develops. In a Mamba-style model, the hidden state plays that notebook role, and each new step can adjust it in a controlled way. The original Mamba paper introduced this selective state space idea as a way to handle long sequences efficiently, and Mamba-3 extends that family with more refined ways to move information forward.
Now here is where the Mamba-3 architecture basics get interesting. The paper highlights three core upgrades: a more expressive recurrence derived from state-space discretization, a complex-valued state update that supports richer state tracking, and a multi-input, multi-output formulation, often called MIMO, which lets one block read several inputs and produce several outputs without increasing decode latency. Those choices are meant to make the model better at holding onto the right details when the sequence gets noisy or long.
Why does that matter for world models? Because planning depends on memory that stays useful, not memory that grows clumsy. A world model is always asking, what should I preserve from the past so I can predict the next step? Mamba-3 answers with a sequence backbone that keeps the state compact while still letting information travel far across the sequence. The paper reports improvements on retrieval, state-tracking, and downstream language modeling, which suggests the architecture is doing more than moving faster; it is also keeping track of changing context more reliably.
Compared with a Transformer, the tradeoff looks different. Transformers rely on attention, which makes each token weigh many other tokens, so inference can become expensive as sequences grow. Mamba-3 comes from the state space model side of the family, so it is built to avoid that quadratic pattern and keep memory requirements lower while still working over long contexts. That is why the paper frames Mamba-3 as part of the broader push toward sub-quadratic models with better hardware efficiency.
Taken together, the architecture is less like a giant spreadsheet of pairwise comparisons and more like a disciplined stream of notes. Each step updates the current summary, and that summary becomes the bridge to the next step. If you are wondering how do you make a world model remember the right details without slowing it down, this is the heart of the answer: you give it a smarter memory mechanism, not a larger one. That is the core promise of Mamba-3 architecture as a sequence backbone for future world models.
Why State Space Models Matter
Building on this foundation, state space models matter because a world model is only useful if it can carry the past forward without drowning in it. Think of it like walking through a city with a good notebook: you do not redraw every street at every step, you keep a compact summary that tells you where you are and what tends to happen next. That is the promise of a state space model, or SSM, which turns long sequences into a manageable hidden state and is built to handle long-range dependencies efficiently.
This is where the contrast with Transformers becomes important. Transformers use attention, a mechanism that compares each token with many others, and that makes inference expensive as sequences grow because compute and memory scale poorly over long contexts. Mamba was designed to solve that bottleneck with selective state space updates, and its paper reports linear scaling in sequence length, fast inference, and strong results on very long sequences. In plain language, SSMs matter because they give us a way to remember far more without paying the full cost of rereading everything every time.
For world models, that difference is not academic; it changes what the agent can actually plan over. A world model often compresses raw observations into a latent space, meaning a smaller internal representation that keeps the important parts and drops the noise. Once that compressed state is in place, the model has to update it step by step as the environment changes, and SSMs are a natural fit for that job because they were built around evolving hidden dynamics rather than storing an ever-growing history. That is why Mamba-3 frames itself as an inference-first design and reports gains in retrieval, state tracking, and language modeling: it is trying to make the internal memory both compact and reliable.
So how do you keep the right details without making the model heavier and slower? Mamba-3 answers that question with three architectural ideas: a more expressive recurrence, a complex-valued state update that supports richer tracking, and a multi-input, multi-output, or MIMO, setup that can do more work without increasing decode latency. You can picture this as upgrading from a narrow clipboard to a smarter control panel: the model still keeps one running summary, but that summary can carry more nuance and more parallel information at the same time.
The deeper reason this matters is that state space models come from a long line of control-theory ideas, where systems are described by how they change over time rather than by static snapshots alone. The classic S4 formulation, for example, starts from a continuous-time state-space system and then finds a parameterization that preserves long-range strength while making computation practical. That historical link is important for world models, because planning is really a dynamics problem: you are not only asking what is true now, but what happens if the system moves this way instead of that way.
Taken together, state space models matter because they give a world model a smarter memory mechanism, not merely a bigger one. They help the system carry forward the facts that matter, forget the clutter that does not, and stay efficient enough to imagine many possible futures before acting. That is exactly the kind of backbone you want when the next step is not more perception, but better planning.
Training for Prediction and Planning
Once the world model has a compact latent state, the next job is to make that state useful for prediction and planning. How do you train a model to think ahead without letting it drift into guesswork? In DreamerV3, the world model learns from replayed experience and predicts future representations, rewards, and continuation flags, while the actor and critic learn from those predicted sequences instead of waiting for new real-world trials. That is the key shift: you are not only teaching the system what happened, you are teaching it what is likely to happen next.
The training process works because the model gets several different lessons from the same experience. The prediction loss teaches it to reconstruct inputs and forecast reward and continuation signals, the dynamics loss teaches the sequence model to predict the next latent representation, and the representation loss keeps those latents informative enough to be worth predicting. Think of it like training a navigator who must remember the road, estimate fuel, and notice when the trip can continue, all from the same drive log. DreamerV3 also uses symlog predictions to keep large values from overwhelming learning, which helps stabilize training across very different reward scales.
Now the planning part begins to feel more like rehearsal than prediction. Starting from states sampled from past experience, the dynamics model and actor roll forward imagined trajectories in latent space, and the critic estimates how valuable those future states are beyond the immediate prediction horizon. In other words, the model is not asking, “What happened in the data?” It is asking, “If I act this way, where do I end up, and is that place worth reaching?” That imagined rollout becomes a practice field for policy learning, which is why model-based reinforcement learning can improve behavior with far fewer risky real-world steps.
This is also where a Mamba-3-style backbone starts to make sense. Mamba-3 is designed around state space principles, with a more expressive recurrence, a complex-valued state update, and a multi-input, multi-output setup that improves retrieval and state tracking without increasing decode latency. For long imagined rollouts, that matters a lot, because planning depends on memory that stays sharp rather than memory that bloats with every step. A sequence model that can carry context efficiently gives the world model a better chance of keeping the right details alive while it imagines the future.
Still, we do not want the model to live entirely inside its own imagination. The real world keeps it honest, and replayed experience keeps it grounded. DreamerV3 trains the world model, actor, and critic concurrently from replayed data, and it uses robustness tricks like normalization, free bits, and symlog scaling to handle different reward frequencies and magnitudes without constant retuning. That combination matters because prediction only helps planning when the model remains stable enough to trust. So the real trick is not dreaming more; it is dreaming well enough that the next action in the real world becomes easier to choose.
Benchmarks Against Transformers
Building on this foundation, the benchmark story is where Mamba-3 stops feeling like an architecture diagram and starts looking like a practical choice you might actually make. The Mamba-3 paper frames the model as an inference-first state space model, and at the 1.5B scale it reports the fastest prefill+decode latency across the tested sequence lengths among Mamba-2, Gated DeltaNet, and Llama-3.2-1B, while also improving average downstream accuracy by 0.6 points over Gated DeltaNet; the MIMO version adds another 1.2 points. Prefill is the pass that reads your prompt, and decode is the part where the model generates new tokens, so this is a comparison of both speed and usefulness, not speed alone.
But the retrieval benchmark tells a more human story, because memory is where these models reveal their habits. In the Together AI write-up, pure Transformers still come out ahead on retrieval-based tasks, while Mamba-3 performs best among the sub-quadratic alternatives and the MIMO variant improves retrieval without increasing state size. The paper also says Mamba-3 makes significant gains on retrieval and state-tracking, which means the model is getting better at carrying the right details forward, even if it does not erase the Transformer’s advantage everywhere.
If you are wondering why that gap persists, think of the KV cache, the running memory a Transformer keeps while generating text, as a large notebook with many exact copies of earlier details. That notebook is powerful for exact recall, but it gets expensive as the sequence grows, which is why Transformer inference often slows down with longer contexts. Mamba-3 takes the opposite route: it keeps a fixed-size hidden state and updates it in place, so the benchmark curves stay flatter, and the blog shows Mamba-3 SISO beating Llama-3.2-1B on prefill+decode latency at every tested length. In other words, the model is trading some raw recall machinery for a leaner path through long sequences.
That tradeoff becomes clearer when we step back from one paper and look at the broader Mamba literature. NVIDIA’s empirical study found that pure Mamba and Mamba-2 models can match or exceed Transformers on many tasks, but they lag on copying, in-context learning, and long-context reasoning; its 8B Mamba2-Hybrid exceeded the 8B Transformer on all 12 standard tasks and was predicted to be up to 8x faster at inference. That broader result helps us read the Mamba-3 benchmark correctly: the family is competitive, but the advantage shifts depending on whether the task rewards speed, exact retrieval, or deep context handling.
So when you read the benchmark charts, the best question is not which model is better, but better for what kind of work? Mamba-3’s core upgrades — more expressive recurrence, complex-valued state tracking, and MIMO — are aimed at improving the quality-efficiency frontier, and the paper says they deliver comparable perplexity to Mamba-2 with half the state size while moving the model forward on downstream accuracy. For a world model, that is the part that matters: if the memory stays compact, stable, and fast enough, planning can happen over longer horizons without turning every step into a costly reread of the past.
Real-World Agent Applications
Building on this foundation, real-world agent applications are where world models stop feeling theoretical and start acting like a working memory for robots, game agents, and other decision-makers. If you have ever wondered, “How do you let an agent practice before the stakes are real?” that is the problem world models solve: they let the system rehearse futures inside a compact latent space, a smaller internal representation that keeps the important parts of experience. In robotics, that matters for dexterous manipulation, locomotion, and long-horizon navigation, which are exactly the kinds of tasks where one bad move can waste time or cause damage. DreamerV3 fits this pattern by learning from experience and improving behavior through imagined future scenarios.
The reason this approach is so attractive is that it changes the learning loop from try everything in the real world to learn, imagine, then act. DreamerV3’s world-model-based reinforcement learning has been described as a general algorithm that outperforms previous approaches across more than 150 diverse tasks with a single configuration, which is a strong sign that the idea is not limited to toy settings. For beginner readers, reinforcement learning means learning by trial and feedback, while model-based reinforcement learning adds an internal simulator to reduce blind trial and error. That is why agents built this way can be more sample-efficient: they learn from both real experience and the futures they simulate.
This is where Mamba-3 architecture starts to matter. A world model has to remember what changed a few steps ago, what still matters now, and what might matter next, without turning every new observation into an expensive rereading of the past. Mamba-3 is built around a state space model, which means it carries a compact hidden state forward through the sequence instead of repeatedly comparing everything with everything else. In the paper, the authors highlight three upgrades — a more expressive recurrence, a complex-valued state update, and a multi-input, multi-output design — and they report better retrieval and state-tracking without increasing decode latency. For agents, that kind of memory is not a luxury; it is the difference between reacting and planning.
You can see the payoff most clearly in navigation. DreamerNav, a 2025 robot-agnostic system built on DreamerV3, tackles dynamic indoor environments by combining multimodal perception, hybrid global-local planning, curriculum training, sparse rewards, and sim-to-real transfer. The paper reports deployment on two different quadruped robots without retraining and mentions preliminary real-world tests, which is a concrete example of world models moving out of simulation and into physical spaces. In plain language, the agent does not merely react to what it sees; it keeps a small internal movie of where the world is heading, then adjusts its path as obstacles move.
That same pattern extends to manipulation and locomotion, where timing matters just as much as accuracy. The robotics world-modeling community specifically calls out dexterous manipulation, locomotion, and long-horizon navigation as areas where learning-based world models are already having a significant impact. Here, the Mamba-3 architecture is especially appealing because it can preserve useful context across long sequences while staying inference-efficient, so an agent can remember a grasp approach, a moving object, or a safety boundary without bloating its internal state. That is an inference from the architecture, but it is a natural one: the better the memory, the more reliably the agent can connect action to outcome.
What should you take away if you are thinking about building an agent of your own? Real-world systems still need fresh experience, because learned models can drift and miss details over time, so the loop must keep returning to reality for updates. The original World Models page describes exactly that iterative pattern: explore, collect new observations, retrain the model, and improve the controller. So the practical recipe is familiar, almost like learning to drive with a patient instructor: the agent rehearses in its head, checks the road with its senses, and keeps refining its instincts as conditions change.