CDC overview and benefits
Building on this foundation, Change Data Capture (CDC) is the pattern we use to propagate only the rows that changed from transactional systems into analytics stores, and it’s the fastest route to keep data fresh in Databricks-driven data pipelines. CDC captures inserts, updates, and deletes at the source and streams those events downstream instead of reprocessing full tables, which reduces latency and compute. For teams migrating monolithic ETL to event-driven, CDC becomes the backbone that lets downstream consumers see near real-time state without overloading operational databases.
At its core, CDC relies on a durable change source: database transaction logs, binlogs, or change tables that record committed modifications. We generally prefer log-based CDC because it observes committed transactions without adding write overhead to OLTP systems, whereas trigger-based approaches introduce latency and coupling. How do you ensure exactly-once semantics and preserve ordering? You design the pipeline around idempotent operations, stable change metadata (LSN, timestamp, or log sequence number), and checkpoints so each event is applied once and in the correct sequence.
In practical terms, CDC transforms row-level change events into idempotent upserts and delete operations in the target store. For example, ingest a compacted change stream and apply an upsert pattern such as MERGE INTO target_table USING cdc_stream ON target_table.id = cdc_stream.id WHEN MATCHED THEN UPDATE SET … WHEN NOT MATCHED THEN INSERT … to converge state efficiently. In an e-commerce system this pattern keeps orders, inventory, and customer profiles synchronized: order status transitions propagate to analytics in seconds, feature stores refresh features for models, and downstream dashboards reflect user-facing changes without full reloads.
The benefits are concrete: lower latency for analytics, smaller resource footprint, and simpler incremental logic compared to full-batch ETL. CDC reduces compute and storage costs because you only process deltas, enables near real-time monitoring and alerting, and supports advanced use cases like streaming ML and operational analytics where freshness matters. For compliance and auditability, CDC retains a change trail that helps reconstruct history and prove when and how records changed, which is invaluable for regulatory reporting and forensics.
Operationally, CDC introduces its own constraints we must design for: schema evolution, late-arriving events, delete semantics, and backfills. We address schema drift by versioning change records and using tolerant merge logic; we handle late-arriving rows with watermarking and replayable checkpoints; we treat deletes explicitly in upstream change identifiers rather than inferring tombstones. Instrumentation matters—monitoring lag, event throughput, and merge conflicts gives us early signals so we can automate retries or fall back to targeted backfills when necessary.
Taken together, CDC is both a design pattern and an operational discipline that transforms how you build data pipelines on Databricks. By converting transactional changes into reliably applied, idempotent operations, we get fresh analytics, predictable costs, and clearer audit trails. Next we’ll map these CDC patterns to concrete architectural choices and Databricks primitives so you can implement a resilient, maintainable pipeline that meets your SLAs.
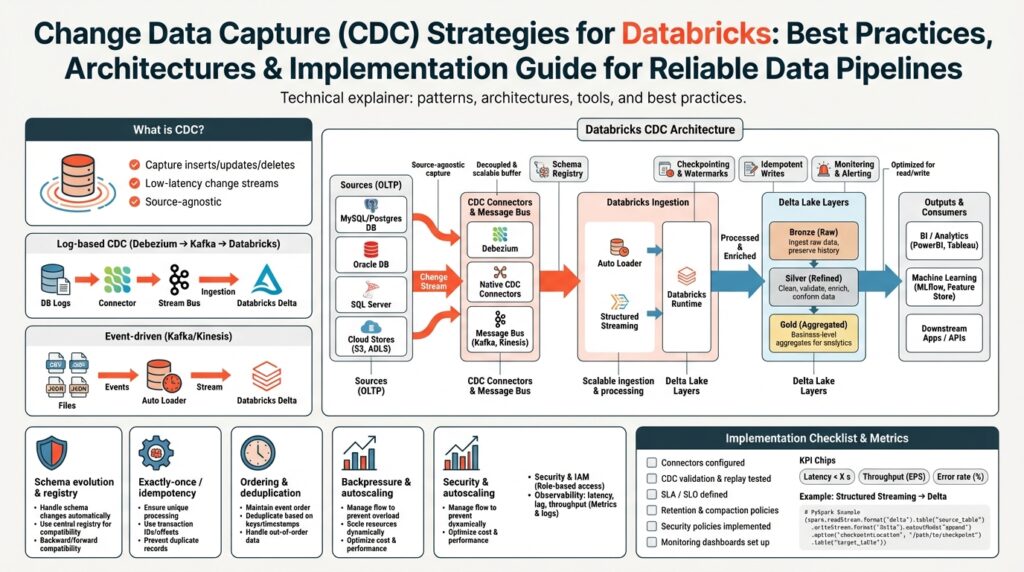
Databricks CDC reference architectures
Choosing an architecture for Databricks CDC starts with the trade-off between freshness, complexity, and operational risk. Building on the CDC overview, the core decision is whether you need sub-second visibility into state transitions or you can tolerate small latency in exchange for simpler operations and lower costs. Databricks CDC pipelines typically center on Delta Lake as the authoritative store and rely on idempotent upserts, durable checkpoints, and stable change metadata to guarantee convergence. How do you decide between a streaming-first architecture and a micro-batch approach? The answer depends on SLA, throughput, and the downstream consumers you must serve.
One practical pattern is a scheduled micro-batch pipeline that ingests change feeds into a bronze Delta table and runs periodic MERGE jobs to converge state into silver and gold tiers. This architecture reduces operational surface area because you run controlled, repeatable jobs that are easy to backfill and test; it also minimizes pressure on source systems when throughput is moderate. Use Auto Loader or a managed CDC connector to land changes as append-only files, then use a MERGE INTO pattern on a cadence that fits your freshness SLA (for example, 1–5 minutes for near-real-time analytics). The micro-batch model is often the safest first step when migrating legacy ETL to change-data-driven flows.
For use cases that require lower end-to-end latency, a streaming-first reference architecture processes change events continuously with Structured Streaming and applies upserts via foreachBatch or streaming MERGE patterns. Start with a reliable CDC source such as Debezium to Kafka or a cloud-native change stream, consume with Structured Streaming, and persist into Delta with checkpointing enabled. To maintain exactly-once semantics we recommend idempotent keys, deterministic timestamps, and stable sequence numbers from the source; combine those with write-ahead checkpoints so retries do not create duplicates. In practice, we implement deduplication and watermarking inside the streaming pipeline to handle out-of-order events and late-arriving updates.
A compacted lakehouse pattern combines the best of both worlds: capture every change to a bronze change log, apply periodic compaction and dedup, and expose a stateful silver table for reading. In this hybrid architecture the bronze layer acts as an immutable audit trail you can replay, while compacted silver tables provide efficient reads for queries, feature stores, and dashboards. Use Delta’s time-travel and transaction metadata to replay history for targeted backfills or forensic queries, and schedule compaction jobs that consolidate micro-files and run MERGE operations to collapse change sets into the current state. This pattern helps when you must retain a full change history for compliance while still offering performant analytics.
Operational concerns drive architecture choices as much as technical ones: schema evolution, conflict resolution, replays, and monitoring must be designed up-front. Implement schema evolution handling by versioning change records and using tolerant MERGE logic that maps unknown fields into JSON columns or staged schemas for review. Plan a clear replay strategy: store source LSNs or offsets with each change so you can replay from a checkpoint, and build small, automated backfill jobs to resolve gaps. Instrument throughput, end-to-end latency, merge conflict rates, and checkpoint lag so you can automate retries, scale resources, or fall back to snapshot-based reconciliation when necessary.
When selecting an architecture for your pipeline, weigh SLA, cost, and operational maturity against feature needs such as time-travel, streaming ML, and operational analytics. Prototype both a micro-batch and streaming variant on a representative dataset, measure end-to-end latency and operational overhead, and then standardize the approach that meets your SLAs with the least complexity. In the next section we’ll walk through implementation patterns and code snippets that make the chosen architecture repeatable and testable across environments.
Delta Lake change data feed
If you want incremental, row-level replication from transactional systems into Delta Lake while keeping operational cost low, enable a native table-level change stream and build your pipelines around it. This approach gives you a durable source of inserts, updates, and deletes so you can implement CDC (change data capture) without replaying full snapshots. We rely on this pattern when we need predictable, idempotent upserts into downstream silver tables and feature stores, because it reduces compute and simplifies backfills compared with snapshot-based ingestion. How do you integrate the table-level change stream into a MERGE-driven pipeline and keep exactly-once behavior?
You must explicitly enable the table-level change stream on each Delta table you want to watch; it does not capture historical changes made before activation. Once enabled, the runtime records change events for UPDATE, DELETE, and MERGE operations and exposes them for batch and streaming reads, so you can process only the rows that actually changed since your last checkpoint. This activation constraint is critical for planning backfills—if you need a permanent history, write the stream into an archive table as part of your ingest. (docs.databricks.com)
Under the hood, change records are materialized efficiently and sometimes stored under a table’s internal _change_data folder, though Delta can compute change sets directly from the transaction log for certain operations like insert-only or partition-level deletes. Retention for those change files follows the table’s version retention and VACUUM policy, so you must plan your retention windows to support replays or audits. Don’t attempt to reconstruct change events by poking at files directly; always use the official APIs to read the stream and preserve transactional semantics. (docs.delta.io)
When you read changes, the feed includes metadata columns that make it straightforward to implement deterministic merges: the change type (_change_type) signals insert, delete, update_preimage, or update_postimage, and commit metadata (_commit_version, _commit_timestamp) gives stable offsets for replay and checkpointing. Use these fields to deduplicate, order, and resolve conflicts before applying a MERGE INTO pattern such as: MERGE INTO target AS t USING changes AS c ON t.id = c.id WHEN MATCHED AND c._change_type IN ('update_postimage') THEN UPDATE SET ... WHEN MATCHED AND c._change_type = 'delete' THEN DELETE WHEN NOT MATCHED THEN INSERT ... This lets you guarantee idempotence and consistent state convergence in downstream tables. (docs.databricks.com)
You can consume the feed either in batch (specifying start/end versions or timestamps) or as a Structured Streaming source by setting readChangeFeed=true; a streaming read will emit the table’s latest snapshot as INSERTs on startup and then stream subsequent deltas in commit order. For operational pipelines we recommend pairing streaming reads with deterministic keys and source sequence numbers so retries remain safe, and combining auto-triggered micro-batch MERGE jobs for compaction to keep read performance high. If you need permanent, queryable history for compliance, write the feed into an archival Delta table on ingest and compact it separately. (docs.databricks.com)
Building on the CDC patterns we covered earlier, treat the table-level change stream as the canonical incremental source for your Databricks pipelines: enable it where you need fidelity, design retention to match replay needs, use metadata columns to drive idempotent MERGE logic, and archive changes if you require long-term auditability. In the next section we’ll translate these operational rules into concrete implementation snippets and deployment checks you can run in CI/CD to make these pipelines repeatable and testable across environments.
SCD patterns: Type 1 vs 2
Building on this foundation, Change Data Capture (CDC) pipelines must decide how to represent updates in the target store: do we overwrite the existing row or preserve history? This choice between SCD Type 1 and SCD Type 2 affects query semantics, storage, downstream analytics, and compliance—so you should treat it as a deliberate design decision, not an implementation detail. How do you decide which pattern fits your use case, and how do those choices map to Delta Lake and MERGE-driven upserts? In the next paragraphs we unpack both patterns, trade-offs, and concrete Databricks implementation patterns.
SCD Type 1 means you apply the latest value and discard prior state; its topic sentence is that Type 1 provides a simple, current-state model. When you implement SCD Type 1 you perform idempotent upserts: incoming CDC events overwrite columns on the matching business key (for example, customer_id). Use Type 1 for non-auditable corrections—email normalization, typo fixes, or denormalized lookup tables where historical values are irrelevant. A typical MERGE pattern looks like MERGE INTO target USING cdc_stream ON target.id = cdc.id WHEN MATCHED THEN UPDATE SET … WHEN NOT MATCHED THEN INSERT …, and that upsert semantics keep queries fast and storage minimal because you don’t keep versions.
SCD Type 2 preserves history by creating new records when a tracked attribute changes; the main idea is to maintain a timeline of state transitions. Implement Type 2 with a surrogate key, effective_start/effective_end timestamps (or valid_from/valid_to), and a current_flag that marks the active row. Use Type 2 for address changes, subscription tiers, or anything requiring auditability or time-based joins for analytics and ML. In practice you map CDC update_postimage events into a two-step operation: close the existing current row (set effective_end and clear current_flag) and insert a new row with the updated values and a new effective_start; this pattern gives you time-travel semantics without relying solely on Delta time travel for business logic.
Choosing between the two is a set of trade-offs: Type 1 minimizes storage and simplifies joins, while Type 2 increases storage and query complexity but preserves lineage and enables temporal analytics. From an operational standpoint, Type 2 pipelines need careful partitioning and compaction strategies because write amplification and historical rows increase file counts; Delta Lake compaction jobs and periodic MERGE-based consolidation help keep read latency acceptable. For CDC-driven pipelines you must also handle ordering and deduplication—use stable source sequence numbers or _commit_version/_commit_timestamp metadata to ensure you close and open Type 2 rows in the right sequence and avoid overlapping effective ranges.
On Databricks, practical implementation pairs CDC change records with deterministic MERGE patterns in Delta Lake so you get idempotent convergence. For Type 1, apply simple MERGE upserts using the business key and source change type to decide UPDATE vs INSERT. For Type 2, implement conditional MERGE logic: when matched and values differ, update the matched row to set effective_end = c.commit_ts and then INSERT the new active row; you can orchestrate this in a single atomic transaction or a controlled two-step job to preserve consistency. Use the table-level change feed and its metadata fields (for example, change_type and commit timestamp) to deduplicate and order events before applying these changes so retries remain safe.
Operationally, align your choice with downstream consumers and compliance requirements: choose Type 1 when consumers only need current-state views and query simplicity matters; choose Type 2 when audits, temporal analytics, or model feature continuity require history. Wherever possible, prototype both patterns on representative datasets, measure storage and query cost, and build backfill strategies that use stored LSNs/commit versions to reconstruct history. By treating SCD semantics as part of your CDC design rather than an afterthought, we make MERGE-driven upserts in Delta Lake predictable, maintainable, and aligned with the analytics guarantees your teams depend on.
Implement CDC with Delta Live Tables
If you need reliable CDC at scale on Databricks, the pragmatic path is to treat Delta Live Tables as the orchestration and enforcement layer that converts a change stream into idempotent state. CDC and Delta Live Tables together let you capture source inserts, updates, and deletes, enforce schema and quality rules, and converge state into Delta Lake tables with deterministic MERGE logic. By front-loading metadata (source LSNs or _commit_version/_commit_timestamp) and clear business keys, you preserve ordering and make retries safe without duplicating rows or corrupting history.
Start by landing a durable bronze change log: use a managed CDC connector (Debezium → Kafka), Auto Loader, or Delta table-level change feed to persist raw change events into a bronze Delta table. Keep the change metadata (change_type, source_seq, commit_ts) and a copy of the pre/post images when available so you can reconstruct updates and tombstones. Configure retention and VACUUM policies to match your replay/backfill windows; if you need permanent auditability, write the feed to a separate archival Delta table on ingest so enabling the change stream later won’t lose history.
In the transformation layer, define declarative tables and expectations in Delta Live Tables that read the bronze stream, deduplicate, and order events before applying them. Use lightweight data-quality assertions (dlt.expect) to catch malformed events early and route failures to a quarantine table for manual inspection. Deduplicate using the stable source sequence or Delta commit metadata, then sort by commit timestamp to collapse multiple change events for the same key into a single deterministic row before you MERGE.
A compact, repeatable MERGE pattern is the core convergence mechanism. For example:
MERGE INTO analytics.orders AS tgt
USING (
SELECT id, payload.*, _change_type, _commit_version, _commit_timestamp
FROM bronze.order_changes
WHERE _commit_version > :last_applied_version
) AS src
ON tgt.id = src.id
WHEN MATCHED AND src._change_type = 'delete' THEN DELETE
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
Place that MERGE inside a Delta Live Tables transformation so the pipeline applies it atomically and Databricks manages checkpoints for you. In Python you’ll typically define a transformation with @dlt.table (or a CREATE LIVE TABLE in SQL) that reads the pre-processed change set and issues a single MERGE per micro-batch; keep the MERGE deterministic and idempotent by relying only on stable keys and source offsets, not on transient system timestamps.
For SCD semantics, map the MERGE behavior to the pattern you need: SCD Type 1 is a straightforward upsert using MERGE to overwrite current values. SCD Type 2 requires a two-step converging transaction: update the existing active row to set effective_end (and clear current_flag), then INSERT a new active row with the new values and effective_start. You can implement this in one atomic job inside Delta Live Tables by running a conditional MERGE that updates existing rows and inserts new ones, or by orchestrating two DLT transforms that the system executes as a single pipeline commit.
Operationalize retries, late-arriving events, and compaction. Use the source commit/version as your checkpoint for replay and backfill; expose that offset in pipeline metrics so you can restart from a known point. Schedule compaction and MERGE-based consolidation jobs to collapse micro-files and historical change records into efficient read-optimized tables. Instrument expectations, pipeline lag, merge conflict rates, and applied commit versions so you can automate safe retries or trigger targeted backfills when reconciliation is necessary.
How do you make this repeatable across environments? Parameterize pipeline inputs (bronze path, retention window, business keys), codify expectations and MERGE templates in your repo, and include idempotent backfill jobs that accept a start/end version for deterministic replays. With these patterns in place, Delta Live Tables gives you a maintainable, auditable implementation of CDC that scales from prototype to production while keeping Delta Lake as your single source of truth.
Monitoring, testing and maintenance
Building on this foundation, operationalizing CDC on Databricks depends as much on observable telemetry and repeatable tests as it does on correct MERGE logic. We need to prioritize monitoring, testing, and maintenance from day one so you can detect drift, recover from failures, and scale without surprises. Start by treating Delta Lake commit metadata and source sequence numbers as your ground truth for health signals; expose them early in dashboards and alerting. If you don’t know which offsets were applied, you can’t prove your downstream tables are converged or reproduce a backfill deterministically.
The most actionable metrics are end-to-end lag, upstream offsets applied (for example _commit_version or source LSN), merge conflict rate, row throughput, and checkpoint age. Track file-level signals too: small-file counts, snapshot sizes, and VACUUM/retention violations often precede performance regressions. Instrument both the ingest (bronze) stream and the convergence layer (MERGE jobs or DLT transforms) so you can correlate spikes in incoming change rate with increased conflict or latency in target tables. Surface these metrics alongside contextual dimensions—table, partition, and business key—so alerts point you to the right scope immediately.
Implement instrumentation where it’s easiest to reason about correctness: emit pipeline metrics at ingest, after deduplication, and post-MERGE with the same offset you committed. For example, capture the latest applied version with a simple query against the bronze change log (SELECT max(_commit_version) AS last_applied FROM bronze_changes) and publish that to your metrics backend. Record how many source events collapsed per key, how many updates became deletes, and the MERGE duration per partition. Those signals let you build automated reconciliation jobs that compare source offsets with target offsets and either trigger a replay or open a targeted backfill ticket.
Testing must cover deterministic correctness, not just green CI runs. Unit-test your MERGE logic with synthetic pre/post images and property-based tests that assert idempotence: reapplying the same batch should not change row counts or business-key state. Run integration tests that inject out-of-order events, late arrivals, and overlapping updates so you validate watermarking and deduplication rules under realistic conditions. How do you validate correctness under retries and replays? Recreate a deterministic sequence of commits with stable _commit_version values and assert that replaying from any checkpoint converges to the same final state.
We also run chaos-style and regression tests against real infrastructure. Inject transient failures during MERGE, simulate worker restarts in Structured Streaming, and run concurrent compaction while writes occur to validate isolation and conflict resolution. Automate a nightly smoke test that replays a compacted sample of the bronze feed into a sandboxed Delta table and runs both Type 1 and Type 2 query patterns to detect semantic regressions. These tests prevent subtle bugs—like off-by-one effective_end windows in SCD Type 2—that only show up under load.
Maintenance practices are the safety net. Codify VACUUM and retention windows aligned with your replay/backfill requirements, and schedule compaction and file consolidation jobs to keep read latency predictable. Treat schema evolution as a controlled operation: stage unknown fields into a JSON column, run schema-compatibility checks in CI, and only evolve production tables through a gated migration. Parameterize retention windows and compaction cadence so you can tune them per table without code changes, and keep a small set of automated backfill jobs that accept start/end versions for deterministic replays.
Finally, document runbooks that map alerts to concrete remediation steps and automated playbooks that can perform reconciliation at scale. Define SLAs for convergence, list the queries to compute reconciliation diffs, and provide the one-click backfill that accepts a version range. By combining focused monitoring, rigorous testing, and proactive maintenance, you transform CDC on Databricks from a fragile integration into a predictable, auditable pipeline—ready for scale and easy to operate as your downstream SLAs evolve.



