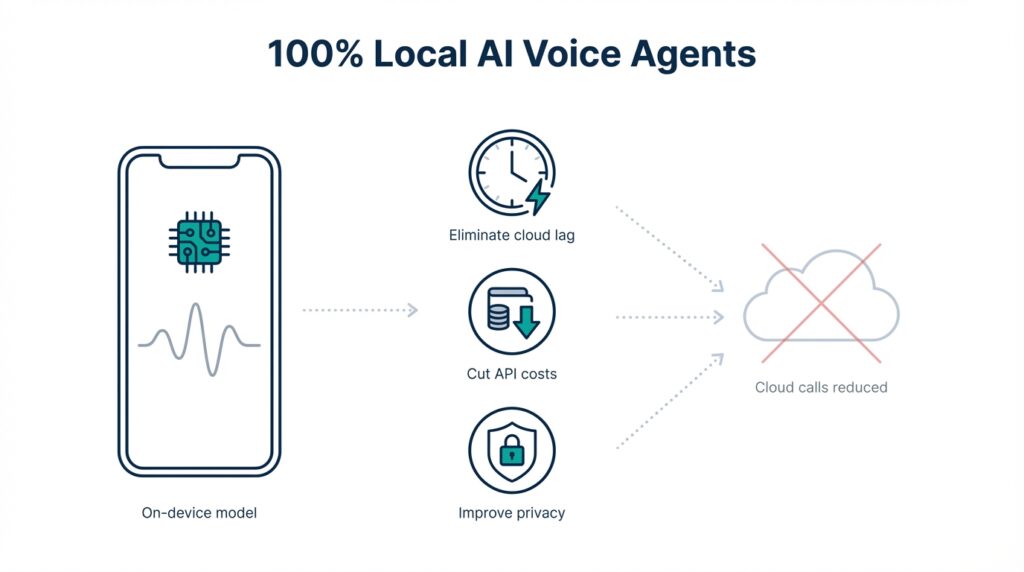
Why Use Local Voice Agents
Building on this foundation, consider why moving intelligence onto the device changes the equation for latency, cost, and data control. Local voice agents and on-device voice assistants eliminate cloud lag for interactive flows by keeping wake-word detection, intent parsing, and slot-filling inside the endpoint. That shift reduces round-trip time and avoids variability caused by network jitter or transient service outages. For teams designing voice-enabled products, these benefits translate directly into higher task completion rates and fewer user frustrations during short, conversational interactions.
Latency is the most visible technical win when you run speech processing locally. On-device inference—running a neural model on the client hardware without a remote API call—lets you achieve consistent sub-100ms response times for critical path operations like confirmation prompts and simple commands. To get there we often combine model distillation (to shrink a large model into a small, performant one), quantization (to reduce numerical precision and memory), and hardware acceleration such as DSPs, NPUs, or SIMD instruction sets. This combination gives you deterministic responsiveness that cloud-only architectures cannot guarantee.
Cost optimization is just as compelling: local voice agents help you cut API costs by removing high-frequency, low-value traffic from metered cloud endpoints. Imagine a fleet of 10,000 kiosks making short-status queries every minute—those token-based or per-request charges add up quickly. By performing initial NLU (natural language understanding) and intent resolution on-device, you reduce calls to large LLMs to the few cases that truly need context or billing-sensitive reasoning. The result is a predictable operational bill and fewer surprises in monthly cloud invoices.
Privacy and compliance advantages follow naturally from the architectural change. Keeping raw audio and intermediate embeddings on-device reduces exposure of personal data and can simplify compliance with regulations such as GDPR or HIPAA where applicable. Federated learning—training or fine-tuning models across devices without centralizing raw data—lets you improve personalization while minimizing data transfer. In healthcare, industrial, or in-vehicle scenarios this pattern prevents sensitive audio from being streamed to third-party clouds while still enabling continuous local improvements.
Developer ergonomics and product velocity improve when we own the runtime environment. Testing A/B variants of a local NLU pipeline is faster when you can push model updates via over-the-air shards rather than coordinating cloud model rollouts and pricing tiers. Practical patterns include packaging a small quantized runtime (for example, a TFLite or ONNX Runtime build) inside your app, exposing a stable local API like recognize() and parseIntent() and reserving cloud calls for summarizeContext() or long-form generation. That separation makes debugging reproducible, lowers test flakiness, and gives you clear SLAs for on-device vs. cloud behaviors.
When should you choose a local agent over cloud-based voice assistants? Choose local when responsiveness, privacy, predictable costs, and offline capability matter more than access to the very largest models for every utterance. Taking this concept further, the next section will show concrete architecture patterns—hybrid pipelines, model sizing heuristics, and OTA strategies—that help you balance on-device inference with occasional cloud augmentation for tough queries.
Required Hardware, Models, and Tools
Building on this foundation, the first practical decision you must make is which class of device will host your local voice agents and on-device voice assistants — that choice constrains latency, power, and model size from day one. Target low-latency, deterministic hardware for interactive flows: that could be an MCU or DSP handling wake-word detection, a mobile SoC with an NPU for full ASR and intent parsing, or an edge GPU for heavier on-device inference. Early in the design phase we size the pipeline around available compute, RAM, and persistent storage so we can trade off model complexity against predictable response times. How do you pick a baseline device for a consumer-grade assistant versus an industrial kiosk or in-vehicle system?
For hardware tiers, define three buckets and pick one to optimize: ultra-low-power endpoints, mid-tier mobile-class devices, and high-performance edge nodes. Ultra-low-power endpoints (Cortex-M class MCUs, small DSPs, or microcontrollers) are ideal for always-on wake-word and basic intent triggers; they let you implement sub-50ms wake-word paths while preserving battery life. Mid-tier mobile SoCs with NPUs or DSPs (smartphones, tablets, ARM single-board computers) are the sweet spot for running quantized ASR + compact NLU locally and for delivering on-device voice assistants without constant cloud calls. High-performance edge nodes with discrete GPUs or NVIDIA Jetson–class boards support larger models for offline batching, personalization, and higher-quality TTS, but you’ll pay in power and cost.
Model selection and compression are the levers that make local deployment viable. Start by splitting responsibilities: a tiny wake-word model, a compact acoustic model for streaming ASR, a small NLU/intent classifier, and optionally an on-device TTS for confirmations. We rely on model distillation to transfer capabilities from a large teacher model into a smaller student and apply quantization (int8 or lower where feasible), pruning, and layer fusion to reduce memory and CPU footprint. For constrained hardware, target a combined runtime memory budget early — for example, keep the working set under 20–50MB on mid-tier devices and under 2–8MB on MCU-class parts — and measure latency after quantization because accuracy and latency can shift in non-linear ways.
Toolchains and runtimes determine how effectively you use hardware acceleration and how portable your stack will be. Use vendor-optimized runtimes to reach best throughput: Core ML on Apple devices, NNAPI or TFLite delegates on Android, Qualcomm SNPE or Hexagon SDK on some SoCs, and TensorRT/ONNX Runtime on NVIDIA edges. Packaging models as TFLite FlatBuffers or ONNX with operator support ensures you can swap runtimes without a complete rewrite. In practice, we also include a small fall-back CPU runtime so edge cases remain functional when hardware delegates are unavailable.
Developer workflows and observability are critical to operationalize on-device models at scale. Build profiling into your CI so every model change reports worst-case latency and memory on target hardware; use automated tests that exercise the recognize() and parseIntent() local API you expose to the rest of the app. For updates, implement signed OTA shards and staged rollouts that let you A/B test different quantization levels or NLU heuristics without bricking fleets. We also instrument privacy-preserving telemetry (aggregate error rates, not raw audio) to iterate on model accuracy without increasing data exposure.
Consider a concrete example: a fleet of interactive kiosks where you want sub-100ms confirmation and occasional cloud escalation for complex queries. We put a 1–5MB wake-word and streaming ASR on a mid-tier ARM board with an NPU delegate, run a distilled intent classifier locally, and reserve cloud calls for long-form generation or billing-sensitive reasoning. OTA-delivered model shards let us push a new intent model to 10% of kiosks, gather anonymized telemetry, then roll to the rest — this pattern minimizes API cost while preserving privacy.
Ultimately, the right combination of hardware, models, and tools depends on your latency, power, and privacy constraints. By front-loading decisions about on-device inference, quantization, and deployment tooling, you make the hybrid architecture we described earlier practical: deterministic local responsiveness for common flows, with cloud augmentation only when it adds real value. Next, we’ll map these choices into concrete hybrid pipeline patterns and OTA strategies that scale.
Choose On-Device STT and TTS
Building on this foundation, the single biggest decision you’ll make is which on-device speech stack to trust for recognition and synthesis—on-device STT and on-device TTS determine your latency, memory budget, and privacy surface in one sweep. Pick models and runtimes that match your target hardware early: a streaming, quantized ASR for mid-tier SoCs will behave very differently than a small offline keyword recognizer on an MCU. We focus on practical trade-offs rather than chasing peak accuracy: choose the smallest model that gets your critical flows under your latency SLA and reserve cloud calls for the rest.
Start with the STT architecture because it anchors the interaction path: do you need low-latency streaming transcription, periodic batch transcription, or only intent-level features? How do you pick the right STT/TTS stack for your device? For interactive assistants, streaming end-to-end ASR (CTC or RNN-Transducer variants) quantized to int8 and delegated to NNAPI/TFLite delegates gives the best balance of latency and accuracy on mobile SoCs. If you only require intent triggers, a compact acoustic model plus a small on-device parser dramatically reduces compute and memory; implement a streaming recognize() API that emits partial transcripts and confidences so the NLU can act early.
Synthesis choices drive perceived quality and power. On-device TTS ranges from small concatenative or parametric engines that cost minimal memory to neural vocoder pipelines (WaveRNN, LPCNet variants) that deliver natural prosody but demand more cycles. When you need short confirmations and brand-consistent prompts, a cached set of pre-rendered clips or an LPCNet-style neural codec often hits the best trade-off between naturalness and deterministic latency. For longer responses, stream the waveform progressively from a compact acoustic model and apply a lightweight vocoder on-device to avoid a full cloud round-trip.
Integrate STT and TTS with robust fallback and decision logic so you get the hybrid benefits we discussed earlier. Expose confidence thresholds from the recognizer and use a simple policy: if confidence < 0.7 or OOV (out-of-vocabulary) detected, escalate to the cloud for re-scoring or longer-context LLM reasoning. For example, implement a local policy like if (asr.confidence < threshold) escalateToCloud(context) so you conserve API calls for genuinely ambiguous cases. This pattern preserves privacy and cost savings while still giving you high-quality responses when the device can’t resolve intent locally.
Optimize runtime and observability before you optimize models. We recommend profiling quantized STT and TTS on representative audio with hardware delegates enabled and measuring worst-case tail latency, not just median. Pay attention to operator coverage in your chosen runtime—missing ops force fallback to slower CPU kernels and negate quantization gains—so validate TFLite/ONNX operator support early in CI. Also instrument aggregate telemetry (error rates, escalation rates, memory pressure) to iterate; that telemetry lets you tune confidence thresholds and decide whether to move rendering from cloud to device or vice versa.
Finally, design for deployability and iteration: package your STT and TTS artifacts as signed OTA shards with clear versioning so we can A/B model variants on cohorts of devices. This lets you measure real-world trade-offs—latency, user satisfaction, and cost—before committing a fleet-wide rollout. With those mechanisms in place, you get deterministic local responsiveness for most conversations and a controlled, economical path to cloud augmentation when higher-quality reasoning or long-form generation is required.
Assemble Local Voice Agent Pipeline
Building on this foundation, start by defining a deterministic, stage-based pipeline that keeps the common path entirely on-device. Local voice agents and on-device voice assistants work best when you explicitly separate the low-latency hot path (wake-word → streaming ASR → local NLU → action) from the cold path that escalates to cloud LLMs. Define clear SLAs for each stage—sub-100ms for wake-word and confirmation, sub-200–300ms for short intent resolution—and size models and runtimes to meet those numbers. How do you guarantee those SLAs in the field? You design the pipeline so the device owns predictable inference and only delegates when a policy triggers escalation.
First, implement a streaming audio handler that produces partial transcripts and confidence scores so downstream components can act early. The recognizer should expose a small, stable local API (for example recognize(session) that yields partial text and parseIntent(text) that returns intent, slots, and confidence) so application code can optimistically confirm or cancel actions. For many product flows, emitting partial hypotheses with metadata lets the NLU confirm a command before full ASR completes, which reduces perceived latency and increases task completion rates. Keep the local NLU compact and deterministic: a distilled classifier or small seq2seq intent resolver is easier to profile and update than a full LLM.
Next, design a clear escalation and arbitration policy that conserves API cost and respects privacy. Use thresholds and signals—ASR confidence, OOV detection, slot-fill failure, user frustration (repeats), or multi-turn context complexity—to decide when to call the cloud. A practical policy looks like if (asr.confidence < 0.7 || missingSlots > 0) escalateToCloud(context); tune that threshold with A/B cohorts rather than guessing. When you escalate, send minimal context: compressed embeddings, redacted slots, and a concise dialog history to limit data exposure and billing scope while preserving cloud utility.
Package models and runtime artifacts for safe OTA updates and rapid iteration. We build signed shards that contain the wake-word, quantized ASR, the local NLU model, and optionally an on-device TTS cache; each shard includes a semantic version, a compatibility matrix for runtime delegates (NNAPI/Core ML/TFLite), and a rollback token. Staged rollouts let you evaluate real-world escalation rates: push a new intent model to 10% of devices, monitor escalation and error telemetry, then expand or rollback. This allows you to iterate on quantization levels and compression without risking the fleet or exploding API costs.
Instrument end-to-end observability into the pipeline so tests reflect production behavior on representative hardware. Profile worst-case tail latency with hardware delegates engaged and measure memory working set after model load; gate CI merges on regressions for both latency and peak RAM. Collect privacy-preserving telemetry—escalation rate, average ASR confidence, and slot-fill success—so you can correlate model changes with user impact without shipping raw audio. Also include robust fallbacks: a minimal CPU runtime for operator gaps, a cached prompt set for TTS failures, and a graceful degraded UX when neither local nor cloud paths respond.
Finally, treat the pipeline as a productizable component you can reuse across form factors and use cases. Standardize the local API surface, version your shards aggressively, and document escalation behavior so application teams can rely on predictable semantics. Taking this approach gives you deterministic on-device inference for most interactions, clear policies for when cloud reasoning is necessary, and operational patterns—OTA shards, staged rollouts, and telemetry—that let you scale local voice agents across devices while controlling latency, cost, and privacy. In the next section we’ll map these pipeline choices into concrete hybrid architectures and rollout strategies for different hardware tiers.
Optimize Performance, Latency, and Costs
Building on this foundation, the single most practical lever you control is where and when inference happens — move the hot path onto the device to hit strict latency SLAs and drive cost optimization. Local voice agents and on-device voice assistants shine when you profile for worst-case tail latency and design the pipeline around deterministic response times. Start by deciding strict SLAs for the hot path (wake-word → streaming ASR → local NLU → action) and treat those numbers as immutable product requirements during model selection, quantization, and runtime choice. Front-loading these constraints prevents a later trade-off between accuracy and responsiveness that costs you users and money.
Measure and gate every model change against hardware-realistic metrics before deployment. Quantization and distillation will shrink models, but they can introduce non-linear shifts in latency and accuracy; we recommend CI gates that run quantized models on representative NPUs/DSPs and report median and 95th/99th-percentile latencies. Pay attention to operator coverage in your runtime (TFLite, ONNX Runtime, Core ML, NNAPI); missing operators silently fall back to CPU kernels and erase your gains. Instrument synthetic and recorded audio scenarios in CI so you catch regressions in tail latency and memory working set early rather than in the field.
Decide escalation policy conservatively and encode it close to the recognizer so cloud calls are deliberate, measurable, and minimal. How do you decide when to call the cloud? Use a compact policy that combines ASR confidence, OOV detection, missing slot counts, and an interaction cost budget; tune thresholds with staged A/B cohorts rather than guessing. A simple policy might look like this:
if (asr.confidence < 0.7 || missingSlots > 0 || userRequestedDetail) {
escalateToCloud({embeddings, redactedSlots, shortHistory});
} else {
handleLocally(intent, slots);
}
This pattern conserves API spend while preserving privacy, since you send only compressed embeddings and redacted context on escalation.
Reduce recurring API costs with caching, batching, and payload minimization strategies that work at scale. Cache frequent short responses (confirmations, status checks) on-device and invalidate with a compact version token from the cloud; batch non-urgent escalations during idle windows to amortize network overhead; and compress context by sending embeddings or concise tokenized histories rather than full transcripts. In operational terms, these choices convert unpredictable per-request billing into predictable periodic charges and often cut monthly invoices dramatically without degrading user experience.
Latency gains come from runtime-level optimizations and deployment hygiene as much as model size. Use vendor delegates (NNAPI/Core ML/TFLite delegates/TensorRT) where possible, pre-warm model memory on app start, and keep the working set small to avoid memory thrashing. Provide a minimal CPU fallback runtime for operator gaps and implement graceful degradation for TTS (cached clips or lightweight vocoder) so users always get a timely response. Also consider model partitioning: run a tiny always-on acoustic model for wake and intent triggers and load a larger local NLU only when needed to keep steady-state latency low and memory pressure manageable.
Finally, treat observability and OTA as first-class cost-control tools rather than ops niceties. Instrument escalation rate, average and tail latency, slot-fill success, and per-device API spend into your telemetry so you can correlate model changes with cost and user impact without shipping raw audio. Use signed, versioned OTA shards and staged rollouts (10% → 50% → 100%) to A/B different quantization levels and thresholds; rollbacks should be fast and automatic if escalation rates or latency spike. Taking this approach lets you operationalize on-device inference: deterministic low-latency behavior for most flows, a controlled cloud escalation path for hard cases, and a predictable cost model you can tune over time — next we’ll map these controls into concrete hybrid architectures and rollout strategies for different hardware tiers.
Deploy, Test, and Monitor Locally
Building on this foundation, the most important operational shift is treating local voice agents and on-device voice assistants as first-class deployable artifacts rather than opaque app binaries. You should front-load deployment concerns—semantic versioning, compatibility for NNAPI/Core ML/TFLite delegates, and signed OTA shards—into your build pipeline so updates are traceable and rollbackable. How do you keep a fleet responsive while changing models? By designing releases around small, validated shards and staged rollouts that keep the hot path deterministic and predictable for users.
Package model artifacts with a clear compatibility matrix and a rollback token so you can safely push a new wake-word or quantized ASR to a subset of devices. Sign every shard and include a minimal manifest that lists runtime delegate support, memory working-set requirements, and a compatibility hash for the local API (for example, recognize() and parseIntent()). Deploy in stages—10% → 50% → 100%—and gate progress on measured escalation and tail-latency metrics rather than calendar time. This reduces risk and preserves the privacy and cost benefits we designed for on-device inference.
Test with hardware-in-the-loop and automated CI that exercises quantized runtimes on representative NPUs/DSPs and CPU fallbacks. Run synthetic and recorded audio suites that measure median and 95th/99th-percentile latency, memory peaks, operator fallbacks, and ASR/NLU accuracy after quantization. Include small integration tests that assert behavior of your local API; for example, run a harness that calls recognize(session) with partial audio and asserts partialTranscript and confidence under a latency SLA. Failing early in CI prevents expensive rollbacks and unpredictable field behavior.
Instrument privacy-preserving telemetry focused on signals, not raw audio: escalationRate, asrConfidenceDistribution, slotFillSuccess, tailLatencyP99, and otaRollbackEvents. Aggregate these metrics on-device and upload buckets at controlled intervals using differential privacy or k-anonymity where applicable so you can iterate without increasing data exposure. A simple telemetry payload might include deviceIdHash, shardVersion, escalationCount, and p99LatencyMs; keep the payload compact and redact slots before any cloud escalation to minimize compliance risk.
Monitor rollouts with automated thresholds and canaries that trigger immediate rollback or hold-and-investigate states when escalation or latency exceed expected ranges. Use canary cohorts to A/B different quantization levels or confidence thresholds and expose a remote tuning API so you can tweak escalationPolicy (for example, confidenceThreshold or missingSlotCount) without shipping a new shard. Correlate per-device API spend with escalationRate to detect runaway cloud costs, and implement per-device quotas or batching windows to keep billing predictable.
Taking these practices together makes deployment, testing, and monitoring repeatable and safe: signed OTA shards for controlled updates, CI with hardware-realistic gates, privacy-first telemetry to evaluate user impact, and automated canary rollouts to limit blast radius. Building on this foundation, the next step is mapping these operational controls into hybrid architectures and staged rollout strategies that match your hardware tiers and business constraints.