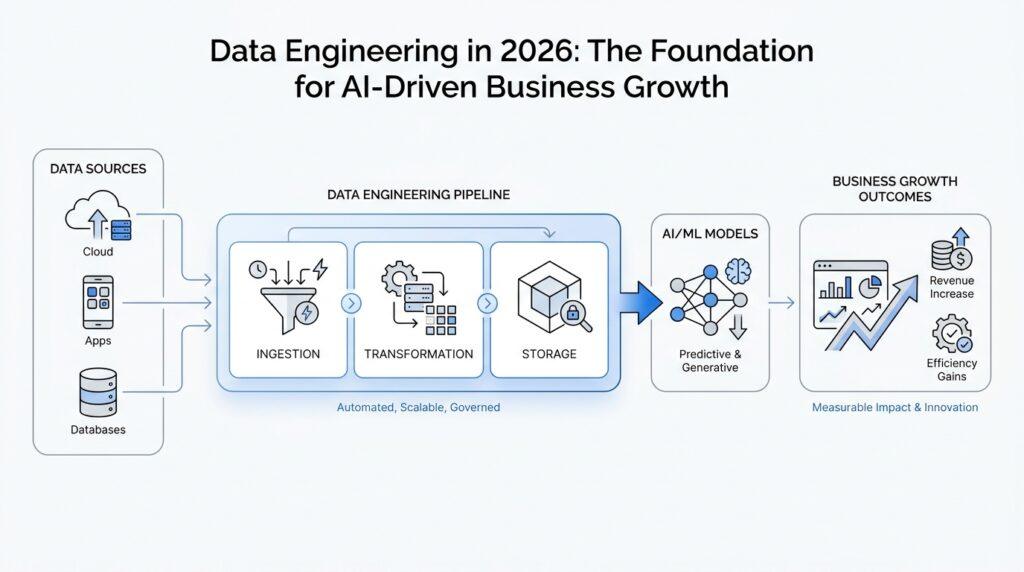
AI-Ready Data Strategy
When teams first start thinking about AI, they often imagine the model as the main event. The quieter truth is that the real work happens earlier, in the data that feeds it. What does AI-ready data actually look like when your warehouse is full of tables, reports, and half-remembered definitions? It looks like data with context: you know what it means, where it came from, who owns it, and whether you can trust it. That is the heart of an AI-ready data foundation, because modern governance tools are built to help organizations discover, manage, monitor, and use both data and AI assets together.
The first step is making the data legible. Metadata, which is “data about data,” gives each table, column, and file a small label that explains what it is for, while governance sets the rules for how that data should be used. Lineage, which is the record of where data came from and how it changed along the way, works like a family tree for your pipelines. That family tree matters because platforms like Microsoft Purview and Google Cloud’s governance tools use metadata and lineage to support discovery, troubleshooting, and trust across hybrid and cloud estates.
From there, we have to ask a harder question: is the data actually reliable enough for AI? Data quality means the data is accurate, complete, consistent, and timely enough for the job at hand, and that timeliness is often called freshness. This is where an AI-ready data strategy becomes practical, not theoretical, because poor quality can weaken insights and recommendations before a model ever sees them. Google Cloud and Microsoft both emphasize quality checks, profiling, classification, and governance rules, and that combination helps teams catch issues before they spread through reporting or model training.
The next layer is meaning. Business glossaries, which are shared lists of company-approved terms, help everyone use the same language instead of arguing over what “customer,” “active,” or “revenue” means in different systems. You can think of this as the translator sitting between technical data and business decisions. When Google Cloud describes contextual governance, natural-language search, and enriched metadata for AI artifacts, it is pointing to the same idea: AI works better when the platform can connect raw fields to human intent. That shared meaning is what turns scattered tables into reusable data products that teams can understand and trust.
So how do we start without getting overwhelmed? We begin with the few AI use cases that matter most, then document the data volume, refresh frequency, and data types each one needs. Microsoft’s strategy guidance calls for governed, high-quality, lineage-traceable data around priority use cases, and that is a good north star because it keeps the work focused on outcomes instead of abstraction. In practice, this means choosing one domain, one business question, and one trusted dataset, then building the AI-ready data controls around that narrow path before expanding outward. That is how the strategy starts to feel real: not as a giant platform project, but as a sequence of careful, visible wins.
Unify Batch And Streaming Data
If the earlier part of the journey was about making data trustworthy, this is where the road forks and then meets again. In many teams, batch and streaming data feel like two different worlds: batch arrives in neat piles, like yesterday’s mail, while streaming data trickles in continuously, like messages popping up on your phone. The challenge is not choosing one over the other. The real work in modern data engineering is creating a unified path so both can feed the same decisions, the same models, and the same business logic without drifting apart.
That question comes up quickly: how do you unify batch and streaming data without building two separate systems that tell two slightly different stories? The answer starts with treating them as different delivery styles, not different truths. Batch processing handles larger groups of records on a schedule, which works well for billing, reporting, and historical analysis. Streaming processing handles events as they happen, which matters when you need immediate signals from fraud detection, personalization, or operations. When both flows share the same definitions, governance rules, and quality checks, they stop competing and start cooperating.
This is where a unified data architecture becomes more than a neat diagram. Instead of copying logic into one pipeline for nightly jobs and another for live events, we want shared transformation rules and shared business meaning. Think of it like one recipe used in two kitchens: one prepares meals in advance, the other cooks to order, but both should season the dish the same way. In practice, that means aligning schemas, standardizing identifiers, and making sure the same customer, order, or product means the same thing whether the data arrived five seconds ago or five days ago. That kind of consistency is what makes batch and streaming data useful together.
The tricky part is that time changes the shape of the problem. A streaming event might be incomplete when it first arrives and only become trustworthy after later enrichment, while batch data often shows up already settled and reconciled. If we ignore that difference, we can end up with mismatched counts, duplicate records, or model features that disagree with the dashboard. To avoid that, teams usually design layered processing: raw ingestion first, then cleaning and enrichment, then a shared serving layer where both batch and streaming outputs land in the same governed view. That shared layer keeps real-time analytics and historical analysis from pulling in opposite directions.
Unifying batch and streaming data also protects AI work from becoming a patchwork of half-fresh inputs. Models do not care whether a feature came from a nightly load or a live event stream; they care whether the feature is timely, complete, and consistent. If a recommendation model sees one version of customer activity in training and another in production, its behavior can wobble in ways that are hard to explain. A unified approach helps us build a single source of feature logic, so the same transformations support analytics, reporting, and model serving without hidden forks.
The good news is that you do not need a grand redesign to begin. The safest starting point is one business process where batch and streaming both matter, such as orders, payments, or customer behavior. From there, we can define the shared keys, the freshness expectations, and the rules for late-arriving data before widening the scope. That small, careful design choice pays off because it turns batch and streaming data from parallel lanes into a coordinated system, and once that happens, the rest of the platform feels far less fragile.
Build Trusted Data Pipelines
After we know the data is worth trusting, the next question is where that trust can break down. That is the job of trusted data pipelines: the moving paths that carry data from source systems into analytics, reporting, and AI features without losing meaning along the way. How do you build trusted data pipelines when data is changing all the time? We start by treating every pipeline like a small contract between the system that sends the data and the people who will rely on it.
That contract begins with the source itself. A source system is the place where data is born, such as an app, a payment service, or a customer database. If the source changes a column name, drops a field, or starts sending a different format, the pipeline can still run and still be wrong, which is the dangerous part. So we add schema checks, which are tests that compare incoming data to the expected structure, and we fail fast when the shape changes in a way that could confuse downstream users.
From there, we move into validation, where trusted data pipelines earn their reputation. Validation means checking that the data is not only present, but believable: dates should look like dates, totals should add up, and identifiers should match the right business rules. This is where data quality becomes more than a slogan, because a pipeline that accepts broken records is like a mail sorter that keeps delivering letters to the wrong house. When we catch errors early, we protect dashboards, forecasts, and model training from quiet corruption.
The next layer is observability, which means being able to see what the pipeline is doing in real time. Think of it as the dashboard lights in a car: we do not need them until something feels off, and then we are very glad they are there. Good data observability tracks freshness, volume, latency, and failures, so we know whether data arrived on time, whether it arrived in the expected amount, and whether it is taking too long to move. That visibility makes trusted data pipelines easier to operate because problems stop being mysteries.
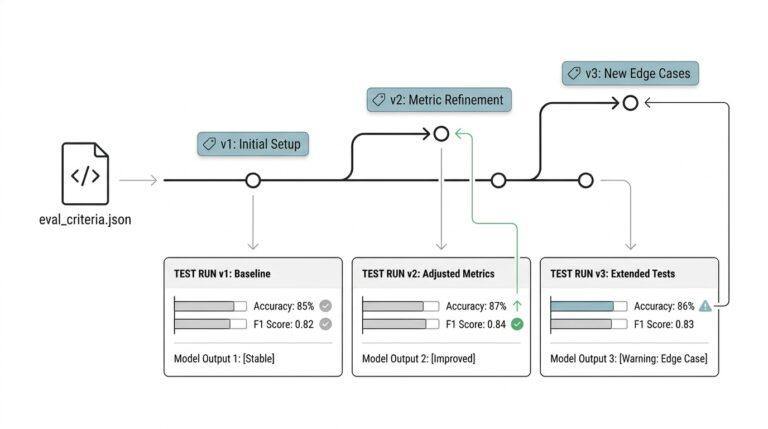
We also need to make room for versioning, which is the practice of keeping track of how pipeline logic changes over time. A pipeline version is like a chapter in a recipe book; if we change the ingredients or the order, we want to know exactly when and why. This matters because AI systems are especially sensitive to hidden changes, and a model can behave differently if the same feature is computed a new way next week. By versioning code, schemas, and transformation rules, we make the pipeline easier to audit and much easier to repair.
Another piece of the puzzle is lineage, or the trail that shows where each dataset came from and how it was transformed. We mentioned lineage earlier, and here it becomes practical: when a number looks strange in a report, lineage helps us trace it back through the pipeline instead of guessing. That trail also supports trusted data pipelines by making ownership clearer, because someone has to be responsible when a transformation fails or a business rule changes. In a healthy system, trust is not a feeling; it is a record.
So what should we build first if the goal is to strengthen data pipelines without overwhelming the team? We begin with one critical path, one business question, and one set of checks that matter most to the people using the data. Maybe that is orders, customer activity, or financial events, but the shape is the same: define expectations, test them automatically, monitor the flow, and keep a clear history of changes. Once we do that, data pipelines stop feeling like fragile plumbing and start behaving like a dependable foundation for analytics and AI.
Add Quality And Observability
Once the pipelines are running, the next surprise is that trust can still slip away after the data leaves the source system. That is where data quality and data observability become the quiet guardians of an AI-ready data foundation. If the last section gave us the road, this one gives us the headlights, speedometer, and warning lights. We are no longer asking whether the data exists; we are asking whether it is still accurate, complete, fresh, and safe to use for decisions and models.
The easiest way to think about data quality is to picture a kitchen. Ingredients can arrive on time and still ruin the meal if one is spoiled, mislabeled, or missing altogether. In the same way, a record can pass through a pipeline and still fail the basic tests that matter to the business: does the customer ID match a real customer, do the totals add up, and is the timestamp recent enough to be useful? When teams build trusted data pipelines, these checks turn quality from a vague hope into a repeatable habit.
So what is data observability, and why does it matter for AI? Data observability is the ability to watch data as it moves, notice when its behavior changes, and understand why it changed. Instead of waiting for a dashboard to look strange or a model to behave badly, we monitor signals like freshness, volume, latency, schema drift, and error rates. Freshness means how recently the data arrived, latency means how long it took to move, and schema drift means the structure changed in a way we did not expect. Those signals give us early warning before small issues become expensive ones.
This is where quality and observability start working together like a pair of teammates. Quality checks answer, “Is the data correct?” Observability answers, “Is the data behaving the way we expected?” A pipeline can be perfectly healthy one day and quietly break the next because a source system changed a field, a batch arrived late, or a streaming event suddenly doubled in volume. When we combine validation with monitoring, we catch both the obvious mistakes and the subtle shifts that can confuse analytics and AI systems.
The practical step is to define what good looks like before the data goes live. That usually means setting a data contract, which is a clear agreement about what fields will arrive, what format they will use, and how often they should show up. It also means creating service-level objectives, or SLOs, which are the measurable targets we want the data to meet, such as “customer orders should be available within 15 minutes.” These expectations give the team something concrete to monitor, and they turn data observability into a working discipline instead of a stack of alerts no one trusts.
Once those expectations exist, observability tools become much more useful because they can point us toward the real source of trouble. If a feature store suddenly feeds an AI model fewer rows than usual, we can trace the issue back through lineage, compare it against the expected pattern, and see whether the problem started in ingestion, transformation, or delivery. That matters because AI systems are sensitive to hidden changes. A model does not need a dramatic failure to become unreliable; it only needs a quiet shift in the data it sees every day.
The payoff is bigger than fewer errors. Strong data quality and observability help teams move faster because they spend less time arguing about whether a number is right and more time deciding what to do with it. They also make AI governance easier, because leaders can see which datasets are trustworthy, which ones are drifting, and which ones need attention before they are used in production. In that sense, data quality and data observability do not sit beside AI work; they make AI work possible.
A good next step is to pick one high-value dataset and watch it end to end. Choose the fields that matter most, define the checks that protect them, and monitor the signals that would tell you the data is starting to wobble. Once that single path feels stable, you can extend the same discipline to other domains, and the whole platform starts to feel less like a guessing game and more like a system you can rely on.
Strengthen Governance And Security
After quality and observability give us confidence in the data itself, the next question is whether we are protecting it with the same care. That is where data governance and data security step in together. Governance sets the rules for who can use data, how they can use it, and what “allowed” means in practice, while security puts up the locks, alarms, and watchful eyes that keep those rules real. What good is trusted data if anyone can reach it, change it, or copy it without a trace? In an AI-driven environment, governance and security are not extra layers; they are the guardrails that keep the whole journey from slipping off course.
The first place to tighten control is access. When data flows across warehouses, lakes, feature stores, and BI tools, it can start to feel like every door is open unless we deliberately close some of them. Access control means deciding who can view, edit, export, or share data, and role-based access control, or RBAC, means those permissions are tied to a person’s job role instead of handled one by one. That sounds technical, but the idea is familiar: the finance team should not need the same keys as the marketing team, and an analyst should not automatically have the power to see sensitive records just because they can query a table.
From there, we move to the principle of least privilege, which means giving people and systems only the access they truly need to do their work. This is one of the simplest ways to reduce risk in data security, because every extra permission becomes another chance for mistakes or abuse. If a pipeline only needs to read from one source and write to one destination, we should not hand it a broad, permanent credential that can wander anywhere else. The same logic applies to humans, service accounts, and AI tools that may touch governed datasets during training or inference.
Governance gets stronger when we can classify data clearly. Data classification means labeling information by sensitivity, such as public, internal, confidential, or restricted, so the right protections can follow it automatically. Once we know which records contain personal data, payment information, or regulated content, we can apply masking, encryption, or stricter approval rules without guessing. Think of it like putting colored tags on boxes before a move: the fragile ones get handled differently, and no one has to inspect every item from scratch to know how careful to be.
Security also has to travel with the data, not sit in one place. Encryption, which turns readable data into protected text unless you have the right key, helps keep information safe both when it is stored and when it moves between systems. Audit logs add another layer by recording who accessed what, when they did it, and what changed. That record matters because governance is not only about preventing bad behavior; it is also about being able to explain what happened when someone asks, “Who saw this dataset, and why?” In practice, those logs become the paper trail that supports both accountability and troubleshooting.
As AI use grows, data governance has to cover more than tables and files. Model inputs, training datasets, prompt libraries, and generated outputs can all carry sensitive or regulated information, so the same discipline needs to follow the whole AI path. If we do not govern these assets carefully, a model can expose private data, learn from stale or unauthorized sources, or produce outputs that violate policy. That is why many teams now treat governance and security as part of the AI lifecycle, not as a separate compliance task at the end. How do you strengthen governance and security without slowing the business down? You make the rules machine-readable, automate the checks, and keep the human review focused on exceptions instead of every routine action.
The practical starting point is to narrow the field. Pick one high-value domain, identify the sensitive data it uses, decide who really needs access, and document the approvals, retention rules, and monitoring steps that protect it. Then connect those rules to the systems that move and transform the data so governance and security happen by default, not by memory. When we do that, the platform starts to feel less like a collection of risky shortcuts and more like a controlled environment where data can support AI with confidence.
Operationalize Real-Time AI Insights
Now that the data is trustworthy, the next challenge is making it act fast enough to matter. Operationalizing real-time AI insights means turning live data into decisions while the moment is still useful, whether that decision is a fraud alert, a recommendation, or a routing change. If batch data is yesterday’s mail, real-time AI is the conversation happening at the door, and the answer only counts if it arrives before the moment passes. How do you operationalize real-time AI insights without building something fragile? We do it by designing for speed, consistency, and control at the same time.
The first piece is the serving path, which is the route data takes from the pipeline to the application that needs it. In practice, this often means a feature store, a shared place where prepared model inputs are stored and served the same way in training and production. That shared layer matters because a model can only make good decisions if the features it sees in production match the ones it learned from earlier. When we use one governed feature logic instead of separate copies, we reduce the chance that real-time AI insights drift away from the truth.
Latency, which is the delay between an event happening and the system reacting, becomes the next character in the story. A few seconds may not matter for monthly reporting, but it can make all the difference when a shopper abandons a cart or a payment looks suspicious. So we ask a simple question: what is fast enough for the business moment we are trying to support? That answer helps us choose between streaming inference, which scores events as they arrive, and micro-batch processing, which groups a few events together to keep speed and cost in balance.
Once the live path exists, the system needs memory. Real-time AI insights become much more useful when every prediction and action is written back into the data platform as a feedback loop. That feedback loop lets us see what the model recommended, what the user did next, and whether the outcome was actually good. Without that record, we are flying with one eye closed, because we can feel activity but not learn from it.
This is also where model monitoring earns its place. Model monitoring means watching for changes in accuracy, input patterns, and behavior over time, and model drift is what happens when the world changes enough that the model’s assumptions no longer hold. A shopping model trained on last quarter’s behavior can start to wobble if customer demand shifts, new products launch, or fraud patterns change. By monitoring both the data and the predictions, we can spot trouble early and retrain before the model quietly loses usefulness.
But real-time AI only works when the business can act on it. If an insight lands in a dashboard that nobody sees until tomorrow, it is no longer real-time for the person who needed it. The better pattern is to connect insights to workflows, such as sending an alert to an operations queue, adjusting a recommendation on a website, or triggering a manual review for a risky transaction. That is the difference between analytics that informs and operational AI that moves the business.
Governance and security still have a role here, especially because live systems can expose sensitive data faster than batch systems ever did. We need clear rules for who can read live features, which decisions can be automated, and when a human should review the result. This is where policy becomes practical: access controls, audit logs, and approval paths keep real-time AI insights useful without making them reckless. In other words, speed should never cancel out accountability.
The safest way to begin is with one narrow use case and one visible outcome. Choose a business event that happens often, define the live signals it needs, decide how fast the response must be, and wire the insight into a workflow the team already uses. Then watch the full loop: event, prediction, action, outcome, and correction. Once that loop is working, real-time AI insights stop feeling like a futuristic promise and start feeling like a reliable part of everyday operations.