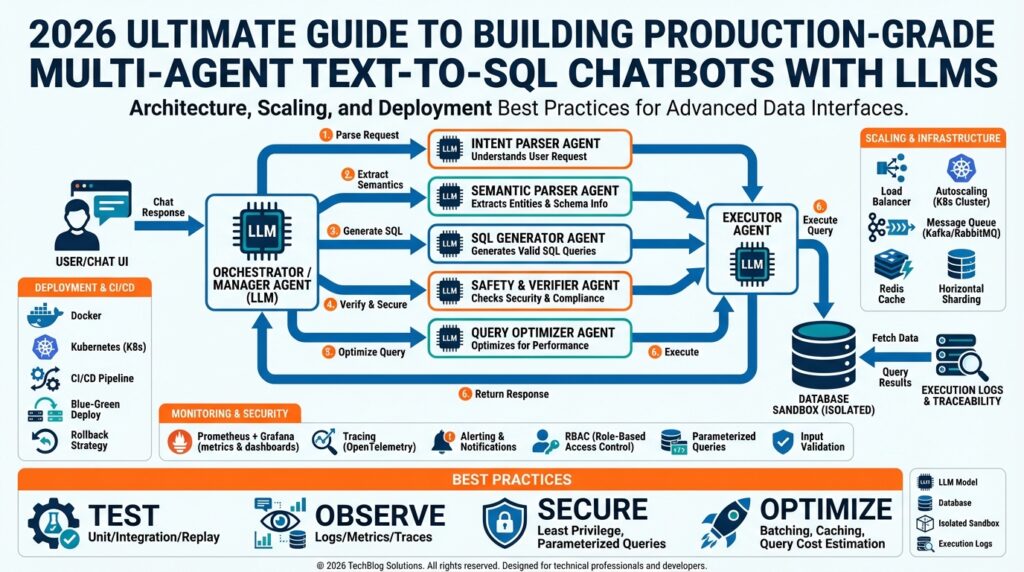
Architecture Overview and Components
Building on this foundation, we need a clear mental model of the components that make a production-grade multi-agent text-to-SQL system behave reliably under real traffic. Start by thinking in terms of two planes: a control plane that orchestrates agents and policies, and a data plane that executes user intents against your databases. Early placement of keywords matters for discoverability, so note that multi-agent, text-to-SQL, and LLMs should be central to the design from the start. This focus keeps decisions about scaling, security, and observability aligned with the real problem you’re solving: converting natural language into safe, performant SQL at scale.
At a high level you’ll see five cooperating components: the client/API layer, an intent and routing layer, a set of specialized agents, a query execution plane, and an observability/security layer. The client/API layer accepts user messages, enforces rate limits, and forwards normalized requests to the intent router. The intent router (sometimes called a dispatcher) classifies the request and selects an appropriate agent or agent chain—agents being lightweight services that encapsulate a single responsibility, for example schema understanding or SQL synthesis. The query execution plane handles prepared statements, connection pooling, and batched execution against your OLTP or OLAP stores, keeping runtime risk isolated from the rest of the system.
Break the multi-agent approach into small, testable roles so each agent can be scaled and audited independently. One agent performs NLU (natural language understanding) and intent extraction, a second retrieves and caches schema metadata and recent query patterns, a third constructs intermediate logical plans, and a fourth translates the plan into parameterized SQL that your executor will run. Parameterized queries and a strict query whitelist reduce injection risk and allow you to rely on the database’s native execution planner. By composing agents rather than a single monolith, you gain more precise autoscaling, simpler A/B testing of parsing strategies, and clearer audit trails for compliance.
Infrastructure choices determine how gracefully the system scales and recovers. Use container orchestration (Kubernetes or similar) to manage agent replicas, and a durable message bus (Kafka, Pulsar, or a cloud-native streaming service) for reliable handoffs between agents without tight coupling. Autoscaling should be based on observed latency and queue depth for each agent rather than raw CPU; for example, scale your SQL-generation agents on end-to-end latency while scaling your schema-caching agent on cache hit ratio. Connection pooling, query throttling, and a circuit-breaker for the database protect the data plane during spikes and prevent noisy neighbors from exhausting DB connections.
Instrumentation and security are non-negotiable in production-grade systems. Implement distributed tracing to follow a request through the chain of agents and correlate traces with database slow queries; expose metrics (P95/P99 latency, queue sizes, cache hit rates) to your alerting system and define SLOs early. Enforce least-privilege credentials for any component talking to a database, sandbox or emulate potentially destructive SQL in staging, and log both the input utterance and the canonicalized SQL with access controls for audits. Also introduce deterministic runtime safeguards—query timeouts, row limits, and a safety review workflow for any agent that can produce DDL or destructive statements.
How do you decide which components to optimize first as load grows? Profile the end-to-end pipeline, identify the highest-latency agent or the most contended DB resource, and focus on that bottleneck—commonly a mis-sized connection pool or a schema-retrieval hotspot. Apply caching (query results, compiled plans, schema snapshots), read-replica routing, and sharding only where profiling shows clear benefit, and use progressive deployment techniques (canaries, blue/green, and feature flags for agent selection) to iterate safely. With this architecture in place, we can move into concrete scaling patterns and deployment recipes that ensure resilient, auditable, and maintainable multi-agent text-to-SQL services built on LLMs.
Agent Roles and Orchestration Patterns
When you build a production multi-agent text-to-SQL system with LLMs, the single biggest lever for reliability is clear role separation and predictable orchestration. Start by thinking of each agent as a small, testable service that owns one responsibility—NLU, schema discovery, logical planning, SQL synthesis, safety checks, or execution. By front-loading the multi-agent and text-to-SQL concepts, we make it easier to reason about scaling, auditability, and risk isolation as your traffic grows.
Define agent roles narrowly so each component has a crisp contract and measurable outputs. For example, an NLU agent must emit an intent and slot map; a Schema Cache agent returns a canonicalized schema snapshot and recent query telemetry; a Planner agent converts intent into a logical plan (filters, joins, aggregations); an SQL Generator emits parameterized SQL and a list of runtime guards; and an Executor applies row limits and binds parameters before handing work to the database. This decomposition lets you independently scale the SQL Generator when compilation latency is the bottleneck while keeping the Schema Cache highly available and read-optimized.
There are three orchestration patterns that cover most production needs: linear pipelines, event-driven choreography, and centralized conductors. A linear pipeline is a synchronous chain where each agent returns a deterministic artifact to the next—useful when you need strict ordering and simple tracing. Choreography uses a durable message bus so agents subscribe to domain events and operate asynchronously, which improves resilience and throughput at the cost of more complex reasoning about partial failures. A centralized conductor (orchestrator) makes dynamic decisions, selects agent chains, and enforces policy—ideal when you want runtime adaptation, A/B routing between alternative SQL strategies, or cross-agent transactional semantics. How do you decide which orchestration pattern to use for your agent chain? Base the choice on latency sensitivity, failure isolation needs, and how often agent selection must adapt at runtime.
Here’s a compact example showing a dispatcher that composes agent chains dynamically (pseudo-Python). The code demonstrates routing logic you’ll implement in the intent-router component described earlier:
def handle_request(utterance):
intent = nlu_agent.parse(utterance)
schema = schema_cache.get(intent.db)
plan = planner_agent.plan(intent, schema)
if safety_agent.approve(plan):
sql = sql_generator.generate(plan)
return executor.execute(sql)
return safety_agent.fallback(intent)
This pattern lets you insert instrumentation and policy checks between any step. In an event-driven deployment you’d replace direct calls with publish/subscribe topics (e.g., intent.parsed, plan.ready) and scale consumers independently based on queue depth or per-topic P99 latency.
Resilience patterns are critical: implement circuit-breakers around the Executor to prevent a noisy spike from exhausting DB connections, and provide graceful fallbacks when an LLM-based generator times out. A practical fallback is a templated SQL agent that covers the 70–80% of common query shapes; it keeps user-facing latency bounded while you run the LLM path asynchronously and reconcile results. Enforce parameterized statements and a query whitelist at the Executor boundary so any agent-generated SQL is constrained by runtime guards and DB-level privileges.
Observability and testability should drive your orchestration decisions. Instrument each agent with spans, expose per-agent SLOs (P95/P99 latency, queue sizes, cache hit ratio), and make the message bus replayable for deterministic debugging. Use canary deployments and feature flags for agent selection so you can A/B test parsing strategies or new LLM prompting without risking production stability. When you can replay a user intent through different agent chains while preserving trace context, you accelerate troubleshooting and safe iteration.
Taking these patterns together, we keep the multi-agent system modular and predictable: narrow roles simplify audits, orchestration patterns let us trade latency for resilience, and deterministic fallbacks protect the data plane. In the next section we’ll translate these orchestration choices into concrete scaling and deployment recipes that ensure safe autoscaling, efficient resource utilization, and auditable rollouts.
Data Retrieval and RAG Integration
Building on this foundation, retrieval is the single most important lever for making multi-agent, text-to-SQL systems accurate and auditable when they call LLMs. If your LLM agent only ever sees the user utterance, it will invent schema shapes or business rules; retrieval-augmented generation (RAG) supplies structured, verifiable context—schema snapshots, sample rows, and policy documents—that constrain generation and reduce hallucination. In practice we place retrieval early in the agent chain so the planner and SQL generator receive concrete artifacts rather than relying on latent memory inside the model. This upfront framing keeps downstream agents deterministic and easier to test under load.
Start by treating retrieval sources as first-class data types that your system version-controls and audits. Canonical schema snapshots, column-level metadata, recent query telemetry, and sanitized sample rows should live in purpose-built stores: a fast key-value or document store for schema snapshots and a vector index for natural-language fragments (help text, docs, sample results). Use embeddings for semantic lookup of free-text docs and hybrid retrieval (BM25 + ANN) for short, structured tokens like column names. How do you choose what to cache versus what to retrieve on-demand? Cache high-cardinality metadata and stable schema snapshots with short, explicit TTLs; resolve volatile or user-specific rows via on-demand parameterized queries protected by least-privilege credentials.
Integrate retrieval into the multi-agent orchestration by giving retrieval its own contract and observability. The intent-router should attach a retrieval descriptor (db, table, user-role, max_rows, freshness) to each request. A dedicated Retrieval agent then executes the descriptor: it fetches a schema snapshot, performs semantic lookup in a vector store for relevant docs, and returns a ranked set of context items plus provenance IDs. The Planner and SQL Generator agents consume that ranked context to build logical plans and parameterized SQL. This separation lets us scale retrieval independently from the LLM-heavy SQL generation step and replay the same retrieval results across different generator strategies for A/B testing.
Prompt design and context engineering change when you have deterministic retrieval. Instead of asking the LLM to infer column semantics, inject a small canonical schema block and two representative rows, then follow with the user intent and strict generation instructions. For example:
Schema: orders(order_id:int, user_id:int, created_at:timestamp, total_cents:int)
Sample rows: {order_id:123,user_id:42,created_at:...,total_cents:4500}
User: "Show monthly revenue for last 6 months by product category"
Instruction: "Output only parameterized SQL and bind types; do not guess missing columns."
That pattern converts free-form asks into safe, parameterized statements and makes the generated SQL auditable against the retrieval provenance.
Operational concerns around freshness and safety are non-negotiable. Hook schema-change events (migrations, DDL) to invalidate snapshots via CDC or a schema registry so your retrieval agent never returns stale column definitions. Apply automated redaction for any retrieved rows to remove PII before they become part of LLM context and enforce per-request token budgets to avoid oversized prompts. Also set retrieval quotas and circuit-breakers so a surge of semantic lookups doesn’t exhaust the vector index or inflate your embedding costs; when the retrieval path is overloaded, fall back to the templated SQL agent we discussed earlier.
Measure and iterate on retrieval quality with the same rigor as your agents. Track retrieval precision@k, context-usefulness (did the LLM consume retrieved items), cache hit ratio, and end-to-end P95 latency attributable to retrieval. Correlate retrieved document IDs with downstream SQL outputs in your traces so you can audit why a particular query was produced and roll back or tune the retrieval strategy if it introduces risk. A/B test vector sizes, chunking strategies, and reranking models to find the best trade-off between context length and signal-to-noise.
Taking these practices together, retrieval and RAG integration convert opaque LLM outputs into grounded, traceable artifacts that the rest of the multi-agent, text-to-SQL pipeline can rely on. As we move into scaling and deployment patterns next, we’ll translate these retrieval contracts into autoscaling rules, cache topologies, and operational runbooks that keep the data plane safe and performant.
Text-to-SQL Generation and Validation
Multi-agent, text-to-SQL systems powered by LLMs unlock conversational access to data, but they also raise a basic operational question: how do you validate generated SQL before it touches production data? Start with the assumption that generation is probabilistic and treat every SQL artifact as untrusted until it passes a deterministic validation pipeline. By front-loading validation in the agent chain you keep risky work out of the executor and preserve auditable provenance for every decision we make.
Design the pipeline as distinct, testable stages so validation becomes a composable responsibility rather than an afterthought. After retrieval and planning, the SQL Generator should emit three artifacts: parameterized SQL, a bind-type map, and provenance IDs for the schema/sample rows used. A dedicated Validator agent then enforces static checks, dynamic checks, and policy gates before handing the statement to the Executor agent—this separation lets you scale validation independently and attach SLOs and alerts to it.
Static validation should be deterministic, fast, and conservative: parse the statement into an AST (e.g., parse_sql(sql)) and verify it against a schema snapshot identified by provenance ID. Enforce parameterization and reject any literal interpolation that could introduce injection risk; validate table and column whitelists, disallow DDL/DDL-like patterns unless explicitly permitted, and apply syntactic row-limit or pagination requirements. Also compute a conservative cost heuristic (estimated rows, joins, aggregations) so you can fail early on queries that would likely time out or scan entire tables.
Dynamic validation complements static checks by executing non-destructive probes on a safe surface: run EXPLAIN or EXPLAIN ANALYZE on a read-replica or a sandboxed optimizer to validate the planner’s cost assumptions and ensure parameter bindings map to expected types. Bind test values using the declared bind-type map and confirm the returned column set matches the schema snapshot (names, types, nullability). If runtime plans deviate substantially from historical fingerprints, route the request to a human-in-the-loop review or the templated fallback path to avoid surprising production load.
Because LLMs can still hallucinate schema names or compose logically valid but semantically wrong joins, add LLM-specific constraints in the prompt and validate their adherence post-generation. Force the model to produce output in a strict, machine-parseable format (JSON with fields for sql, binds, provenance) and let the Validator fail fast on unexpected shapes. Maintain a small suite of unit tests that replay representative prompts and assert that generated SQL references only allowed columns and reproduces expected plan shapes; run these tests during CI for prompt changes and model upgrades.
Observability and metrics make validation actionable: track validator-reject rate, hallucination rate (generated references to non-existent columns), explain-cost anomalies, and average time to human review. Correlate traces from parsing through execution with the retrieval provenance IDs so you can answer audits like “which sample rows and schema snapshot led to this query?” and use replay logs to re-run requests against new generator strategies for A/B testing. Instrumenting these signals lets us iterate on prompts, retrieval quality, and validator rules with measurable impact on production risk.
In practice, implement the validator as its own agent in the orchestration graph with clear contracts, SLOs, and circuit-breakers; when it rejects an LLM output, fall back to a templated SQL agent or a queued human review workflow. This pattern preserves low-latency handling for common queries while preventing unsafe or expensive statements from reaching the data plane. Building validation into the multi-agent pipeline gives you both the flexibility of LLM-driven text-to-SQL and the operational guardrails needed for production-grade deployments, which we’ll translate into autoscaling and deployment recipes next.
Scaling, Caching, and Cost Optimization
Building on this foundation, multi-agent, text-to-SQL systems that rely on LLMs are where scaling and cost decisions stop being academic and start driving architecture. Early in the pipeline you must decide which artifacts to cache, which model calls to route, and what SLOs you’ll tolerate for freshness versus expense. We’ll treat caching and autoscaling as operational levers you can tune, and show practical patterns you can apply to reduce latency, control database load, and lower model-inference bills without sacrificing auditability or safety.
Start by categorizing what to cache: schema snapshots and provenance IDs, vector-embedding results, compiled logical plans, parameterized SQL templates, and full query results. Each type has different freshness and consistency needs, so place them in appropriate tiers: an in-process L1 for microsecond reads (hot schema pieces and recent plan fragments), a shared L2 Redis or Memcached for cross-replica caches (compiled SQL, binds), and a durable L3 store or object bucket for longer-lived artifacts (embeddings, materialized result blobs). How do you balance cache freshness against cost when embedding vectors and schema snapshots grow? Versioned keys and short TTLs on schema snapshots combined with CDC-driven invalidation let you avoid stale-reads while keeping TTLs long enough to amortize embedding and retrieval costs.
Design cache keys and provenance so you can invalidate deterministically and audit outcomes. Use a compact, deterministic key format such as db/schema_version/table:hash(query_descriptor) and store a provenance ID alongside any cached retrieval or generated SQL so traces map back to the exact snapshot. For example: key = f"{db}:{schema_v}:{agent_role}:{sha256(descriptor)}" — that single pattern makes rollbacks and replay trivial and avoids mystery cache misses during canaries. We also keep a small LRU for per-instance warm caches to eliminate repeated network round-trips for hot conversational flows.
Autoscaling should follow the same decomposition we use for agent roles: scale agents, not hosts. Configure horizontal autoscalers using multiple signals—queue depth for asynchronous choreography, P95/P99 latency for synchronous pipelines, and cache hit ratio for retrieval-heavy agents. Route inexpensive intents to lightweight models or templated agents and reserve larger models for complex planner or validator tasks; model routing reduces API tokens and inference time. Batch LLM requests where semantics allow (coalescing similar prompts or multi-user batching) and add a short micro-batching window (5–20 ms) to amplify throughput without blowing user latency budgets.
Attack cost from both the infrastructure and model sides. On the infra side, use read replicas, materialized views, and pre-aggregations to keep the Executor cheap; size DB connection pools per-replica and enforce circuit-breakers. On the model side, cache LLM outputs for identical prompt+context fingerprints, apply strict token budgets, and prefer embedding reuse (store canonical embeddings once per document ID rather than per request). Consider mixed provisioning—use spot GPUs for heavy offline generation, reserved instances for consistently hot agents, and serverless for spiky, low-duration workloads to avoid paying for idle capacity.
A concrete example ties these patterns together: for a high-volume analytics dashboard, we keep schema snapshots with 60–120 second TTLs, cache common parameterized SQL templates in Redis, precompute embeddings for help-text and docs into an ANN index, and route simple filter/aggregation intents to a templated SQL agent while sending complex joins to an LLM-backed generator. This combination reduces repeated model calls by an order of magnitude, caps DB cost through precomputation, and preserves traceable provenance for audits. As we move into deployment recipes, we’ll translate these caching topologies and autoscaling signals into concrete manifests and runbooks you can apply to production multi-agent, text-to-SQL stacks.
Deployment, Security, and Observability
Deploying a production-grade multi-agent text-to-SQL system built on LLMs means you must treat deployment, security, and observability as a single integrated concern rather than three separate checkboxes. Start by assuming any runtime artifact—the LLM prompt, a retrieved schema snapshot, a generated SQL statement, or a provenance ID—will be needed for debugging, audit, or rollback. When you front-load traceability into manifests and runtime contracts, you make safe rollouts, forensic audits, and cost controls feasible at scale. This integrated mindset reduces surprise when a model upgrade or schema migration interacts with a live agent chain.
Pick orchestration and deployment patterns that map to the operational properties of each agent: scale the schema-cache agent differently from the SQL-generator and validate the planner separately. How do you know which autoscaling signal to use? Use queue depth and consumer lag for asynchronous choreography, and P95/P99 latency for synchronous agent chains; route simple intents to a lightweight templated agent and reserve the LLM path for complex joins and ad-hoc analytics. Implement progressive delivery—canary, blue/green, and feature-flag-driven agent selection—and build your CI/CD to run replay tests against a staging message bus so canaries exercise the same orchestration graph you run in production.
Treat security as runtime policy plus least-privilege identity. Give each agent its own short-lived credential, enforce mTLS between pods, and apply Kubernetes NetworkPolicies or equivalent to limit which services can reach your Executor and the DB. At the database layer, map agents to distinct DB roles: a readonly role for retrieval, a limited-aggregate role for analytics, and a tightly constrained executor role that enforces row limits and a query whitelist. Rotate keys automatically and store secrets in a vault with dynamic credentials so an agent compromise yields minimal blast radius.
Add deterministic runtime safety guards at the execution boundary rather than inside the LLM agent. Enforce static validation (AST checks, parameterization, table/column whitelists) and dynamic probes (EXPLAIN on a read-replica or optimizer sandbox) before letting SQL touch production data. Implement a circuit-breaker and per-user or per-tenant rate limits at the Executor; when the Validator rejects a statement, fall back to a templated SQL path or queue the request for human review. For enforcement-as-code, run a sidecar policy agent (e.g., OPA-style) that receives the parsed AST and returns allow/deny decisions tied to provenance IDs.
Observability must capture three linked artifacts: request traces across the multi-agent chain, retrieval provenance IDs that tie context back to stored snapshots, and cost/usage signals for LLM calls. Correlate distributed traces with DB slow-query logs and model billing metrics so an alert for rising P99 latency also surfaces whether the culprit was an LLM token storm, a cache-miss storm, or a bad execution plan. Instrument per-agent SLOs (P95 latency, queue depth, cache hit ratio, validator-reject rate) and create composite SLOs for end-to-end request success; use sample-based tracing and retention policies tuned for audit windows rather than indefinite retention.
Operationalize incident response with replayable queues and clear runbooks. When a user reports an incorrect result, you should be able to replay the original intent with the same retrieval provenance and generator prompt against a staging model, compare ASTs, and produce a diff that maps to a validator rule change or prompt tweak. Build runbooks that map common alerts to immediate mitigations—scale the schema-cache, flip the model routing to smaller models, enable strict query whitelisting—so you avoid ad-hoc fixes that disable telemetry. Use feature flags for fast rollbacks and keep an auditable change log tied to deployments.
Taking these practices together, we preserve the agility of LLM-driven generation while keeping the data plane safe, auditable, and performant; next we’ll translate these operational contracts into concrete manifests, autoscaling rules, and runbooks you can apply directly to your clusters and CI pipelines.