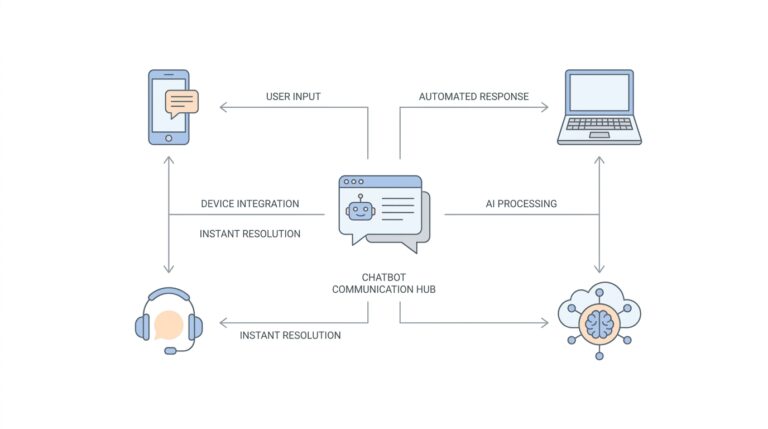
Annotation-free visual grounding overview
Imagine you just finished reading about the limits of boxed annotations and felt frustrated by how expensive and brittle they are — that feeling is exactly why researchers turned to annotation-free visual grounding and, more specifically, to language-attention masked reconstruction as a way to teach models to point at things without hand-drawn boxes. Visual grounding, in plain terms, is the task of linking a piece of language (a word or phrase) to the exact region in an image that it refers to. Building on that idea, annotation-free visual grounding trains models to discover those links from raw image–text pairs, not curated bounding boxes, so you can scale to millions of examples without hiring labelers.
Building on this foundation, let us step into the central insight: attention maps inside vision-language models act like soft pointers that hint where words belong in images. An attention mask is simply a way to highlight parts of the image or tokens in language that the model should focus on — think of it as dimming an entire photograph except for the area you suspect matches a word. With language-attention masked reconstruction, we deliberately hide (mask) some language or image signals and ask the model to reconstruct them using the remaining, cross-modal context. This reconstruction objective becomes the learning signal that implicitly teaches the model which visual region corresponds to which phrase.
First, we need to understand what masking and reconstruction mean in practice. Masking means replacing a chunk of input — perhaps the word “dog” in the caption or a patch of pixels in the image — with a placeholder so the model must infer the missing piece. Reconstruction means the model then predicts that missing word or visual content from the unmasked parts. Self-supervised learning is the style of training where the data itself creates the supervision (the mask), so we don’t need human annotations. When the model successfully reconstructs the masked language token, it often does so by using visual features that align to that concept; the attention weights used during reconstruction therefore reveal the grounding.
How do you get a model to point at objects without boxes? Picture making a recipe where you remove an ingredient and challenge a friend to guess what’s missing by smelling and tasting the dish — their guesses reveal which flavors map to which ingredients. In the same way, when we mask the word “red” or “ball,” the model leans on certain image regions to reconstruct that word, and those regions become the grounding. Language-attention masked reconstruction formalizes this by computing attention maps between textual tokens and visual tokens and optimizing the model so attention concentrates on the right image patches during reconstruction.
To make this concrete, imagine an image captioned “a child holding a red ball.” We mask the token “red” and train the model to predict it back. If the learned attention peaks over the spherical, red region in the photo during prediction, we have successfully grounded the adjective to a location. This approach scales naturally: millions of image–caption pairs from the web can provide diverse examples, allowing the model to learn grounding for many objects and attributes without explicit bounding boxes. Annotation-free visual grounding therefore reduces labeling cost, often improves robustness to dataset-specific biases, and generalizes better to novel compositions.
That said, there are real challenges we must note. Ambiguous language, phrases that refer to relationships (“the cup next to the book”), and dense scenes with many similar objects can confuse the attention signal. Evaluation becomes harder because standard bounding-box metrics don’t always align with the soft, heatmap-like outputs of attention-based grounding. Models can also exploit shortcuts in captions or learn spurious alignments if the training data isn’t carefully curated. These limitations mean we still need smart architectures, careful masking strategies, and evaluation protocols that respect soft localization.
Taking this concept further, advances beyond earlier work like ReconVLA focus on refining mask strategies, improving the fidelity of reconstructed tokens, and sharpening attention so groundings are more precise and interpretable. As we move to the next section, we’ll examine concrete architectural tweaks and training recipes that tighten this feedback loop between attention and reconstruction, showing how small design choices translate into noticeably better, annotation-free grounding in practice.
ReconVLA core concepts
Building on this foundation, let us walk through the handful of ideas that make the approach work in practice and feel like a clever sleight-of-hand rather than magic. In this section we’ll explain how an image–text model can learn to point without boxes using annotation-free visual grounding and language-attention masked reconstruction, and we’ll answer a practical question you might be asking: How does ReconVLA turn attention maps into reliable localizers? This paragraph sets the scene so you know we’re moving from intuition into the concrete pieces that must cooperate.
At the heart of the method is a small cast of components that play clear roles, and understanding each is the quickest way to demystify the whole system. First, a visual encoder (a neural network that converts image patches into vector tokens) turns images into a set of visual tokens — think of these as the words of the image. Second, a text encoder (a neural network that converts caption words into token embeddings) does the same for language. Third, a cross-attention mechanism (an algorithm that computes how much each text token should attend to each visual token) lets language and vision talk to each other; we call the resulting matrices attention maps, which are soft heatmaps showing where the model looks in the image for each word. Finally, a reconstruction head (a small predictor that tries to recreate masked content) uses the unmasked context to predict the missing token or visual features.
Masking is the deliberate partial blindness that creates learning signals, and different mask strategies act like different puzzles you give the model. Language masking means hiding a word token from the caption so the model must use the image to predict it; visual patch masking hides a subset of image patches so the model must use the caption to fill in visual detail. Joint masking hides correlated fragments in both modalities so the model learns tighter two-way mappings. These strategies are the recipes we give the model — when we remove an ingredient, the model has to infer it from the remaining flavors, and the patterns it leans on become the grounding.
The training objective turns those guesses into measurable progress: reconstruction loss asks the model to correctly predict masked words or visual features, which we typically measure with cross-entropy for discrete tokens or mean-squared error for continuous features. ReconVLA-style systems often add auxiliary alignment or regularization terms that encourage attention maps to be sharp and consistent across heads; in plain language, these extra losses say “not only should you reconstruct the word, but focus your gaze in a small, stable region while doing it.” That combination nudges attention maps from fuzzy suggestions toward reliable indicators of localization.
So how do attention maps become the final pointing output you can inspect or evaluate? During reconstruction, we extract the cross-attention weights tied to the masked language token and aggregate them across attention heads and layers to build a heatmap over image tokens. We then upsample that heatmap to image resolution and optionally apply simple post-processing — smoothing, peak-finding, or thresholding — to produce a localized region or soft mask. This yields a visual grounding: a heatmap or region tied to the original word that you can visualize or score against a reference.
Like any method, this one has predictable failure modes, and knowing them helps you fix them. Ambiguous captions, pronouns, or relational phrases (“the cup next to the book”) can scatter attention because multiple regions are plausible; background co-occurrence bias (a “beach” caption often co-occurs with sky) can create spurious peaks; and dense scenes with many similar objects can split the signal. Practical remedies include harder masking schedules (masking context more aggressively), contrastive negatives (forcing the model to distinguish similar regions), and aggregating evidence across multiple masked passes so a transient mistake doesn’t define the grounding.
Now that we’ve laid out the essential parts — encoders, masks, reconstruction loss, and attention-derived heatmaps — you should have a clear map of how the pieces interact. With that mental model in place, the next step is to see which architectural tweaks and training recipes sharpen the attention signal in practice and translate these mechanics into measurable improvements on benchmark tasks.
Language-attention masked reconstruction
Building on this foundation, let us walk through how to turn the soft signals inside a model into consistent, usable localization without any boxed labels — a practical guide to masked reconstruction that leans on attention maps and real training tricks. In case you need a quick refresher, attention maps are the soft, per-token weights that show where a text token looks in the image; think of them like a dimmer that brightens the image patches the model consults when predicting a word. Annotation-free visual grounding depends on those maps, and masked reconstruction (hiding parts of the caption or image and asking the model to predict them) is the engine that forces attention to reveal meaningful links. By the end of this section you’ll know concrete masking schedules, loss terms, and aggregation steps that make those heatmaps reliable enough to act like pointers you can trust.
Start with the masking recipe: how often, how much, and which modality to blind. The topic sentence here is simple — the mask schedule is the single most practical lever you control. A balanced strategy mixes language-only masks (hide tokens in the caption), visual-only masks (hide contiguous image patches), and joint masks (hide correlated pieces across modalities) so the model learns one-way and two-way inference; when we hide a descriptive adjective, the model must attend to color or shape; when we hide a patch, it must use the caption’s semantics to reconstruct texture or object identity. Progressive masking helps: begin with easier predictions (small masks, high context) and anneal to harder ones (larger masks, sparser context) so the model’s attention sharpens rather than collapses. How do you decide mask size? Empirically, 10–30% token masking for language and 15–40% patch masking for vision often balance signal and difficulty, but you should treat these as tunable knobs for your data domain.
Loss design is the next lever that turns attention into discipline. The main idea is that reconstruction loss teaches correctness while auxiliary terms teach focus. Reconstruction loss (cross-entropy for discrete tokens, MSE for continuous features) is the primary objective that rewards predicting the missing content; add attention-regularization losses that encourage sparsity or consistency across heads and layers so attention maps stop spreading everywhere. Contrastive penalties that push attention for a masked token toward the correct region and away from similar distractors are particularly helpful in dense scenes where many candidate patches look alike. We also like consistency losses that force the model to produce similar attention when the same concept appears under different masks — it’s a simple way to make groundings repeatable rather than accidental.
Next, extract and refine the signal: how to turn raw attention matrices into a localized heatmap you can visualize or evaluate. The key sentence is that aggregation and post-processing matter as much as training. Aggregate cross-attention across several top-performing heads and later layers (not just one head) to reduce noise, then normalize and upsample patch-level scores to full image resolution. Apply light smoothing to eliminate speckle, and use soft thresholding or peak-clustering to produce a dominant region; this yields a heatmap that corresponds to the word and can be converted to a region for scoring or downstream use. Running multiple masked passes with different random seeds and averaging the resulting heatmaps often reveals stable peaks and mitigates single-pass flukes.
Finally, expect and mitigate practical failure modes by design. Ambiguous language, relational phrases, and background co-occurrence create messy attention; fix these by mixing harder negatives in training, explicitly masking neighboring relation phrases, and incorporating relational contrastive losses that penalize attention if it concentrates on contextually plausible but incorrect regions. For long captions, teach the model to attend in two stages — coarse search then fine refinement — so it doesn’t split attention across many small clues. Remember: small architectural choices (which layers to extract from, whether to include a lightweight decoder head) and simple training recipes (mask schedules, consistency terms, and multiple-pass averaging) often produce bigger improvements than exotic model changes.
With these practical levers in place, you’ll find masked reconstruction becomes a reliable, scalable path to annotation-free visual grounding: it’s how attention maps stop being mere hints and start behaving like consistent visual pointers. In the next part we will explore specific architectural tweaks and training recipes that tighten this feedback loop even further, showing how small, concrete changes translate into measurable improvements on benchmark tasks.
Model architecture and training
Building on the intuition we’ve already built, picture yourself assembling a machine whose sole job is to point — not with boxes, but with focused, interpretable attention. Right away we should front-load a pair of key ideas: annotation-free visual grounding relies on language-attention masked reconstruction as the learning engine, and the architecture is the recipe that decides whether attention maps become reliable pointers or noisy guesses. If you’ve ever tuned a complex appliance, you’ll recognize this: the right combination of encoders, attention wiring, and loss terms makes the whole system hum, and the wrong choices leave you endlessly fiddling with knobs.
Start with the cast of components — these are the familiar characters in our story and each has a clear role. The visual encoder (the backbone) converts image patches into vector tokens; the text encoder turns caption words into embeddings; a cross-attention module lets text query vision and produces attention maps that act like soft pointers; finally, a reconstruction head reads the attended context and predicts masked content. Think of the cross-attention as a translator sitting between two people who don’t share a language: it learns which visual tokens correspond to which words, and our training will reward translations that let the reconstruction head succeed.
Choosing the visual and text backbones matters more than you might expect because they set the vocabulary the model can use. Here the backbone means the core neural network (for vision, a convolutional network or a Vision Transformer; for text, a transformer-based tokenizer and encoder) that produces token representations. If you use patch-based ViTs, image tokens are natural and attention maps align to patches; with CNN backbones you often add a projection to create patch-like tokens. We usually experiment with freezing the visual backbone early to preserve pretraining gains, then fine-tune later so the attention mechanism can adapt; this curriculum-like approach helps stabilize learning when you have millions of noisy image–text pairs.
How attention is computed and regularized is the secret sauce that turns soft heatmaps into dependable localizers. Cross-attention is computed across multiple heads and layers, so one practical choice is which heads and layers to trust — later layers often contain more semantic alignment while early heads capture low-level detail. The reconstruction loss (cross-entropy for discrete language tokens or mean-squared error for continuous visual features) trains correctness, while attention-regularization terms encourage sparsity and consistency so attention maps don’t smear across the image. We also add contrastive or relational penalties that push attention for a masked token toward informative patches and away from distractors; that discipline is what makes attention peaks repeatable rather than accidental.
Training curriculum and masking strategy are the daily work of shaping behavior: how often and what to hide defines the puzzles the model must solve. Start with easier masks — small language masks and few visual patches — then progressively increase difficulty so the model learns to rely on visual cues rather than caption shortcuts. Use a mix of language-only, visual-only, and joint masks; empirical ranges we often try are ~10–30% token masking for language and ~15–40% patch masking for vision, but treat these as knobs tuned to your data. How do we design the training recipe so attention becomes a trustworthy pointer? Include multi-pass averaging (run several random masks and average attention heatmaps), consistency losses across masks, and hard negatives to teach discrimination in cluttered scenes.
Finally, practical engineering decisions tie the architecture and training into a usable system and point the way to evaluation. Batch composition, augmentation (color jitter, cropping), and stable optimizers (AdamW with learning-rate warmup) reduce shortcut learning; keep compute manageable by sharing encoders across tasks and extracting attention from a small set of late layers for efficiency. At inference, aggregate selected cross-attention heads, normalize and upsample patch scores, and apply light smoothing or peak clustering to form a final heatmap you can visualize or score. With these architectural choices and a careful training regimen, language-attention masked reconstruction stops being an experimental trick and becomes a repeatable path to scalable, annotation-free visual grounding — and the next section will show concrete tweaks that sharpen this signal even further.
Advancements beyond ReconVLA
Imagine you’re standing at the edge of a forest of models and datasets, holding the idea of annotation-free visual grounding like a flashlight that reveals paths without needing a map. You remember how language-attention masked reconstruction taught models to point by hiding words or patches and watching where attention drifts; now we want that drift to be steadier, sharper, and useful across harder scenes. Building on ReconVLA’s intuition, researchers have pushed in several directions at once: smarter masking puzzles, attention discipline that prefers focus over fuzz, and architectural modules that turn transient hints into persistent pointers you can trust.
One major strand of progress starts with the mask itself. Where ReconVLA used balanced language and visual masks to create cross-modal puzzles, newer recipes make masking adaptive and contextual — masks that scale to object size, that target relation tokens, or that follow linguistic structure so the model can’t take a caption shortcut. These adaptive masks act like targeted tests rather than random quizzes; by forcing the model to infer adjectives, spatial phrases, or small objects under tougher conditions, attention maps become more discriminative. How do you know which mask schedule to use? Developers often compare stability across many random masks and favor schedules that increase difficulty gradually while preserving reconstructability.
Architectural tweaks have also tightened the feedback loop between attention and reconstruction. Instead of treating every attention head equally, modern designs weight and gate heads with a small learned selector so the model learns which ‘‘eyes’’ are reliable for grounding. Lightweight decoder blocks trained specifically for reconstruction can amplify semantic correspondence without overwriting the frozen visual backbone, and multi-scale fusion layers let the model combine coarse search with fine-grained refinement. The net effect is that attention heatmaps move from noisy speckle toward repeatable peaks, because the network now has explicit pathways that encourage semantic localization rather than global shortcutting.
Training recipes complement those architectural choices. Alongside the standard reconstruction loss, contrastive objectives push attention for a masked token toward true image regions and away from plausible distractors; consistency losses force the model to produce similar groundings when the same concept is masked in different contexts. Multi-pass averaging — running several masked forward passes with different seeds and aggregating attention — has become a practical trick to reveal stable peaks and reduce flukes. Curriculum strategies start with easy, highly contextual masks and progress to harder, sparser masks so the model builds robust visual priors before being challenged to disambiguate crowded scenes.
On the practical side, inference and evaluation received focused attention. Upsampling strategies that respect patch boundaries, light smoothing to remove speckle, and peak-clustering to choose dominant regions make attention heatmaps usable as soft masks or pseudo-boxes for downstream tasks. Evaluation protocols evolved too: rather than forcing attention into rigid bounding-box metrics, researchers use overlap with soft masks, region ranking, and human-in-the-loop checks to better capture what annotation-free visual grounding actually produces. Small engineering choices — patch size, input resolution, which late layers to aggregate — often move the needle more than exotic model expansions.
Finally, new methods tackle the sticky problems ReconVLA highlighted: ambiguous references, relational phrases, and compositional novelty. Relational contrastive losses explicitly penalize attention that latches onto contextually plausible but incorrect regions, and two-stage coarse-to-fine attention helps with long captions that otherwise scatter focus. As a result, you’ll see models that generalize better to novel compositions and give more interpretable heatmaps in cluttered scenes. With these advancements, the path from language-attention masked reconstruction to reliable, annotation-free visual grounding becomes clearer — and the next section will dive into concrete evaluation recipes and example code that show these ideas in action.
Evaluation metrics and datasets
Imagine you’ve trained a model with language-attention masked reconstruction and you stare at a beautiful but noisy attention map wondering, “How do I know if this model really learned to point?” This is the practical crossroads for anyone working on annotation-free visual grounding: we need evaluation that respects soft, heatmap-like outputs while still allowing apples-to-apples comparison with older box-based approaches. Right away, let’s name the familiar datasets and metrics you’ll likely use, then walk through how to evaluate fairly, diagnose failure modes, and design tests that reward true grounding rather than clever shortcuts.
To ground our discussion, start with the datasets researchers commonly use as benchmarks. Referring-expression datasets like RefCOCO, RefCOCO+, and RefCOCOg provide images paired with natural-language expressions that point to objects; these usually include a human-drawn bounding box as the reference localization. Flickr30k Entities links noun phrases in captions to region boxes in complex scenes, which is useful when captions are longer and more descriptive. Visual Genome offers dense region descriptions and relationships across many images, which makes it valuable for testing relational grounding and crowded scenes. Each dataset has its own linguistic quirks (for example, some discourage absolute location words), so pick evaluation splits that match the behavior you want to measure.
Before we change metrics, let’s recall classic box-based measures because they remain useful. Intersection over Union (IoU) compares an output box to the reference box by measuring overlap; mean IoU (mIoU) averages that score across examples. Pointing-game accuracy is a simpler test: extract the highest-scoring pixel or patch from your heatmap and count it as correct if it falls inside the ground-truth box. These metrics are intuitive and widely reported, which helps comparison with prior work — but they can under-represent the value of a diffuse or multi-modal heatmap produced by annotation-free visual grounding.
So how do we evaluate heatmaps themselves? Start by converting patch-level attention into an upsampled heatmap at image resolution, then measure both localization and distributional similarity. Localization metrics include peak localization accuracy (the pointing-game variant), soft IoU where we threshold the heatmap to form a soft mask and compute overlap, and region-ranking metrics where the model must rank candidate boxes by relevance. Distributional metrics include normalized scanpath saliency (NSS) and rank-correlation (Spearman) between predicted and ground-truth saliency maps; area under the curve (AUC) over threshold sweep is another way to capture how well the heatmap concentrates on true regions across operating points.
Practical protocol choices matter as much as the metric names. Always report a small battery: pointing accuracy for direct comparison, mIoU or soft-IoU for overlap, and an AUC or NSS-style score for heatmap quality. Be explicit about preprocessing: how you upsample patches, which attention heads and layers you aggregate, whether you apply smoothing or multi-pass averaging, and the thresholding rule you used to make a soft mask into a region. These engineering knobs can swing scores dramatically; documenting them makes your evaluation reproducible and prevents accidental overfitting to one metric.
Evaluation should also probe robustness and generalization. Design splits that test compositionality (novel adjective–noun pairs), relational phrases (“the cup next to the book”), and cross-dataset transfer (train on one corpus, test on another). Include adversarial probes such as distractor-heavy scenes, occlusions, and syntactic paraphrases so you can see if the model relies on spurious co-occurrences. When language ambiguity creeps in, human evaluation remains invaluable: ask annotators to rank heatmaps or select correct regions among top candidates to measure perceived grounding quality beyond automated scores.
Building on what we’ve covered about masks, attention aggregation, and architecture, a final practical tip is to report multiple complementary metrics and dataset behaviors rather than one headline number. That way, you show whether your advances in annotation-free visual grounding and language-attention masked reconstruction sharpen peaks, improve overlap, or simply shift behavior in edge cases. With a transparent, multi-faceted evaluation protocol you’ll be able to compare fairly to ReconVLA-style baselines and demonstrate real progress on the hard problems we care about next.