Overview of Generative AI
Imagine you’ve just heard the phrase “Generative AI” and you’re trying to picture what it actually does — not in abstract, but in the kind of task you might hand it right now. Generative AI is a class of artificial intelligence that creates new content: text, images, code, or music. A large language model (a type of model trained to understand and produce human language) is one common example of generative AI; we’ll call these large language models and the shorthand LLMs interchangeably. What makes a model generative, and how do you get it to produce something useful?
You can think of training as the model’s schooling, and inference as its performance on stage. Training is the process where a neural network — a computer program inspired by how brains pass signals, made of layers of simple mathematical units — learns from a dataset, which is a large collection of examples (sentences, images, code) it studies. During training the model adjusts internal numbers called parameters to reduce mistakes; parameters are like knobs that control how the model transforms input into output. Once trained, the model performs inference: it takes your prompt (the text or instruction you give it) and generates a response using the patterns it learned.
At the heart of many language-focused models is the idea of predicting the next token. A token is a small unit of text — a word, part of a word, or even a punctuation mark — that the model treats as a building block. By practicing next-token prediction across billions of tokens, the model learns grammar, facts, style, and common sense connections without being explicitly told rules. This probabilistic prediction is why these systems can continue your sentence, draft an email, or imagine a scene: they pick the next token that best matches what they learned from similar contexts.
Learning patterns from data feels a bit like picking up a dialect by listening. If you’ve ever learned a recipe by watching someone cook, you noticed the common steps and the timing — the model does something analogous, but at scale. Because it sees many examples, a generative system can mix styles (a formal memo with a touch of humor), generalize from fragments (complete a partially written function), and even generate novel ideas by recombining learned elements. Large language models shine at these flexible, creative tasks because they model language statistically across vast and varied text.
Generative AI is powerful, but it has clear bounds and quirks you should watch for. Hallucinations — when a model confidently states something false — happen because the model is pattern-matching, not verifying facts; bias is inherited from the data it was trained on; and models can be sensitive to how you phrase a prompt. These are not mysterious failures but predictable behaviors of systems optimized to continue patterns. Knowing this makes you better at reading outputs critically and iterating prompts until the model’s response fits your needs.
Let’s make it practical: imagine asking the model to draft a cover letter. First, give context: your role, the company, and a few achievements. Then ask for a specific tone and length. You’ll likely rewrite the draft once or twice — that feedback loop (prompt, review, refine) is where human skill meets generative capability. Prompt engineering, the practice of crafting inputs to get better outputs, becomes a creative skill: specific prompts usually produce more useful results than vague ones.
Building on this foundation, we can now peel back the next layer and look at what happens inside LLMs during training and inference: attention, model architectures, and the trade-offs engineers make between cost, speed, and accuracy. As we move forward, we’ll explore those inner mechanisms step by step so the process stops feeling like magic and starts feeling like a toolkit you can use.
Transformer Architecture Basics
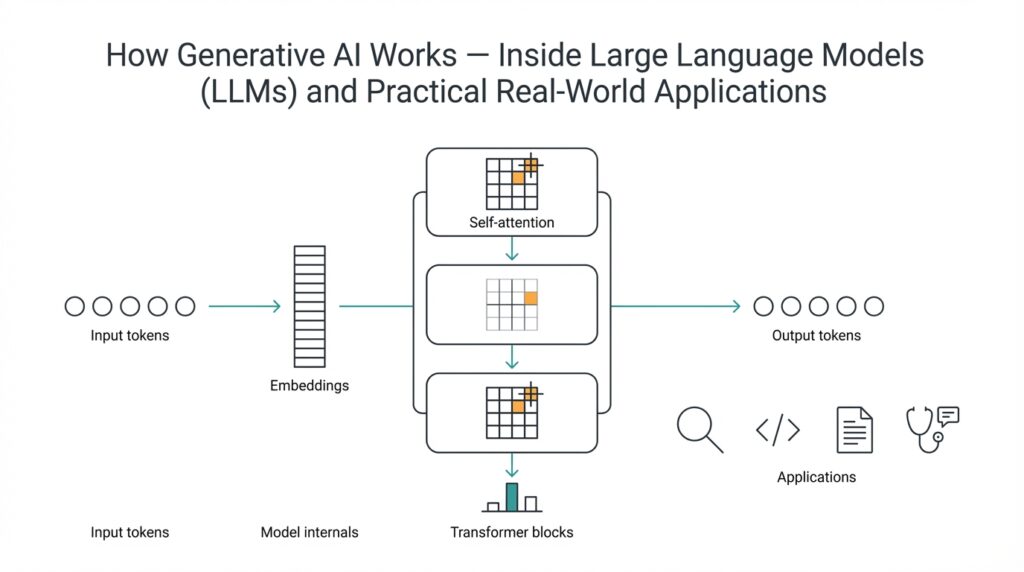
Building on this foundation, imagine you opening the hood of a generative model to see the design that makes modern language tasks possible: the Transformer architecture. The Transformer is a blueprint for how a model looks at sequences of tokens (small pieces of text like words or word fragments) and decides which pieces matter for predicting the next piece. In plain terms, it replaces older step-by-step designs with a system that lets every token talk to every other token at once, using a mechanism called attention to weigh those conversations. This change is what made LLMs fast to train on large datasets and flexible at inference.
First, let us meet the main characters inside the model: layers, attention modules, and small feed-forward networks. A layer is a repeatable block that transforms the token representations; stacking many layers gives the model depth and expressive power. Some Transformer variants use two main stacks called encoder and decoder — think of the encoder as an analyzer that reads input and the decoder as a writer that produces output — while many large language models use a decoder-only stack optimized for next-token generation. Knowing these roles helps you understand why some models are better at translation (encoder-decoder) while others are tuned for free-form generation.
Now we come to the heart of the story: how attention works and why it feels so powerful. Attention is a method that lets the model assign a score to how relevant each token is to another token; self-attention means every token scores every other token in the same sentence. How does attention let models focus on what’s important? Picture a group conversation around a table where each person leans in more to the speakers they trust — attention gives more weight to those trusted voices when forming a response. Practically, the model computes those weights and forms weighted averages of token representations, letting context flow across the whole sequence instead of being limited to nearby words.
Attention becomes more flexible through multi-head attention, which you can think of as using several spotlights instead of one. Each head is an independent attention mechanism viewing the same tokens through a different lens — one head might track grammar, another might track named entities, another might track numeric relationships. By combining these perspectives, the model captures richer relationships than a single attention pass could. Behind the scenes we name the pieces queries, keys, and values: queries ask what to look for, keys are the signatures to match against, and values are the content we bring back — but you can hold onto the simple idea of multiple viewpoints converging on a better judgment.
Transformers also need a way to remember word order, because plain attention doesn’t care whether tokens are shuffled. Positional encoding injects a sense of sequence, giving each token a tiny identity based on its position — like adding a timestamp to every spoken sentence so you know which came first. Between attention blocks you’ll also find feed-forward layers that reshape each token independently and architectural helpers like residual connections and layer normalization that stabilize learning; think of them as guardrails that keep each layer’s changes from going off course. These parts are small but crucial for making deep stacks train reliably over billions of tokens.
Finally, picture many of these layers stacked like floors in a building: the higher you go, the more abstract the representations become. That stacking is why Transformers scale so well — more layers and wider internal dimensions often translate into better capabilities, at the cost of compute and memory. During training those parameters learn to predict next tokens across massive text corpora; during inference we use the learned structure to generate responses quickly. With this mental model in place, we’re ready to peel back the math and practical tricks behind attention, optimization, and the trade-offs engineers make when building real-world LLMs.
Tokenization and Embeddings
Imagine you’re handing a story or a question to a model and expecting it to understand — but the model doesn’t read letters the way you do. It reads numbers. That first leap — turning your sentence into a format a machine can work with — is where tokenization enters the scene. Tokenization is the process of chopping text into tokens, which are small units of text (a token might be a whole word, a fragment of a word, or a punctuation mark). By converting characters into tokens, we give the model tidy building blocks it can count, compare, and predict.
First, we need to understand why tokens matter to LLMs. A token is like a Lego brick in a model’s language toolbox: some bricks are full words, others are pieces of words (subwords) so the model can represent rare words without memorizing every possibility. Tokenization also defines the model’s vocabulary — the list of all tokens it knows. If a new word appears, the tokenizer breaks it into known subword tokens so the model can still reason about it. This is why tokenization affects speed, memory, and how gracefully the model handles new or misspelled words.
So how do we move from tokens to something the model can compute with? We map each token to a vector — a list of numbers — and that mapping is called an embedding. An embedding is a numeric fingerprint for a token: similar meanings end up as similar fingerprints, so the model can tell that “cat” and “kitten” are neighbors in meaning even if they’re different tokens. Think of embeddings like coordinates on a map where nearby points represent similar ideas. Once tokens become vectors, the model can do algebra with meaning — adding, subtracting, and comparing these coordinates to infer relationships.
Embedding vectors are usually high-dimensional, which just means they have many numbers in them so the model can encode nuance. When we say vector, we mean an ordered list of numbers the model uses internally. These vectors feed into the Transformer layers and attention mechanisms we discussed earlier: attention looks at the vectors and decides which token-vectors should influence the next prediction. Because embeddings capture semantic relationships, attention can focus on tokens that matter not only because they’re nearby in the sentence, but because their vectors say they’re related.
What happens during training is important to picture. The model doesn’t start with perfect embeddings; it learns them. During training, the system adjusts the numerical values in token embeddings alongside all its other parameters so that similar contexts pull related tokens closer in vector space. Over time, common patterns — like how “bank” behaves differently in financial vs. river contexts — are reflected in how those token vectors position themselves. That learning process is why embeddings are a core part of what LLMs store about language, not just a one-off conversion step.
Let us take a concrete example to ground this: you type the sentence, “Write a friendly email to my manager about taking a day off.” The tokenizer breaks it into tokens, each token becomes an embedding vector, and the Transformer’s attention mechanisms use those vectors to decide which words influence the next token prediction. Because embeddings place “friendly,” “email,” and “manager” in related regions of vector space, the model is more likely to generate polite, context-appropriate phrasing. This is the same machinery behind paraphrasing, summarization, and many generative AI behaviors you’ve seen.
Now that we’ve built this bridge from text to numeric representations, the next step is to see how positional signals and attention refine those embeddings into coherent predictions. Building on this foundation, the model combines the token vectors with positional cues so it knows order, and then attention weaves those signals together to produce the next token. Understanding tokens, tokenization, embeddings, and vectors gives you a clear mental map of how raw text becomes the working language inside LLMs — a map we’ll use as we explore attention and decoding next.
Pretraining and Fine-tuning
Imagine you’ve trained a large language model on a mountain of text and now you want it to help with a very specific job — drafting polite customer replies or summarizing legal briefs. In that moment you’re standing between two complementary stages of model development: pretraining and fine-tuning. Pretraining is the broad schooling where the model learns language patterns from massive, diverse text; fine-tuning is the apprenticeship where you teach the model the particular skills and constraints your task needs. We’ll walk through what each stage does, why both matter, and how to decide which one you actually need.
Pretraining builds the model’s general knowledge and instincts. During pretraining — the phase where a model learns to predict the next token across billions of words — it discovers grammar, common facts, and stylistic patterns without being told rules. Think of it as listening to tens of thousands of conversations, books, code repositories, and articles so the model forms a wide-ranging sense of how language works. That broad base is why a pretraining-trained large language model can produce coherent paragraphs, mimic different tones, and generalize from partial prompts.
Fine-tuning sculpts that broad capability into focused competence. Fine-tuning is the process of continuing training on a smaller, task-specific dataset so the model performs well on your target job; supervised fine-tuning uses labeled examples (input paired with the desired output), instruction tuning gives many examples framed as directions, and reinforcement learning from human feedback (RLHF) uses human preferences to shape behavior. Picture pretraining as a general education and fine-tuning as an internship where experts correct the model’s work and reward preferred behavior. Each method has a role: supervised examples teach exact outputs, instruction tuning improves following requests, and RLHF helps align style and safety to human judgment.
A concrete example helps make the choice practical. Suppose you want an assistant that answers product-support tickets in your company’s voice: first, you start with a pretraining-trained model because it already knows how to write and reason. Then you fine-tune on a curated set of past tickets and ideal responses so the assistant learns product details, acceptable phrasing, and compliance constraints. How much data do you need, and when should you fine-tune instead of prompting? If you have hundreds to thousands of high-quality examples and need consistent, auditable outputs, fine-tuning is usually worth the cost; if your needs are exploratory or you only have a handful of examples, careful prompt engineering can be a lighter first step.
There are also smarter, cheaper ways to adapt models without re-training everything. Parameter-efficient fine-tuning techniques — like adding small adapter modules, applying low-rank updates (LoRA), or using prompt tuning — let you modify a model’s behavior by changing a tiny fraction of parameters or by learning a short, trainable prompt. These approaches feel like sewing a patch onto a jacket rather than tailoring the whole coat: you get task-specific behavior with far less compute and storage. They’re especially useful when you want to maintain a shared base model and swap small, task-aligned modules in and out.
Fine-tuning brings benefits but also risks you should plan for. Models can overfit to narrow datasets and forget general abilities, they can internalize biases present in your training examples, and they may reveal sensitive information if your data is not properly de-identified. That’s why you need validation sets, adversarial testing, and monitoring after deployment to catch regressions and hallucinations. Treat evaluation like part of the training loop: measure correctness, tone, and safety, and iterate until the model behaves reliably on real-world inputs.
With that groundwork, you’ll better know when to lean on pretraining’s broad knowledge and when to invest in fine-tuning to meet specific constraints. The key takeaway is practical: use the pretrained model as a powerful generalist, then selectively fine-tune or apply parameter-efficient methods where consistent, domain-aware behavior and auditability matter. Next, we’ll carry these ideas forward to how models are optimized and evaluated in deployment so your assistant stays useful and trustworthy over time.
Decoding and Inference Methods
Imagine you’ve handed a trained model a prompt and are watching it choose words one by one — that moment is where decoding and inference methods decide whether the model feels like a careful editor, a daring storyteller, or a stuck recorder. Inference, the act of running a trained model to produce answers, is the stage performance; decoding is the director’s playbook for how the model selects each next token (a token is the small unit of text the model generates). Right away, the choice of decoding method shapes tone, creativity, and reliability, so understanding the options helps you match model behavior to your task.
First, let us meet the simplest strategies as characters in our story. Greedy decoding picks the single most probable next token every time; it’s deterministic (always the same given the same model and prompt) and fast, but can feel repetitive or safe. Beam search keeps multiple candidate sequences (beams) alive and expands the most promising ones, trading more computation for better global coherence — think of it as exploring several draft endings before picking the best. Both methods rely on the model’s raw scores, often called logits, which are converted into probabilities with a function called softmax; logits are just the model’s unnormalized preferences for next tokens.
Then there’s the creative side: stochastic sampling. Sampling treats the model’s probability distribution like a lottery and draws tokens randomly according to those probabilities. Temperature is a control you apply to that distribution: lower temperature (closer to zero) sharpens probabilities so the model behaves more predictable, while higher temperature flattens probabilities and increases diversity. Top-k and top-p (nucleus) sampling are ways to limit randomness by trimming the candidate pool — top-k keeps the k most probable tokens, while top-p keeps the smallest set whose cumulative probability exceeds p. These knobs let you tune for inventiveness or conservatism depending on whether you’re writing marketing copy or answering factual queries.
How do you choose between deterministic and stochastic approaches? Ask what matters more: reproducibility or creativity. For a legal summary, product documentation, or anything requiring auditability, prefer lower temperature, greedy or beam search, and deterministic seeds. For brainstorming, dialogue, or creative writing, use sampling with moderate temperature and either top-k or top-p to prevent nonsensical outliers. This trade-off between reliability and novelty is a practical design choice you’ll revisit as you evaluate outputs.
There are hybrid strategies that combine strengths. You can run beam search but inject controlled sampling at later steps to break monotony, or run multiple stochastic generations and rank them with a scorer (for example, a smaller model or heuristics) to pick the best candidate. Another useful trick is constrained decoding, where you forbid specific tokens or enforce patterns (useful for safety, compliance, or keeping formats like JSON). Constrained decoding feels like giving the actor a strict script while allowing improvisation in permitted parts.
Performance matters in production: sampling is often cheaper per token than wide-beam search but can require more post-filtering to guarantee quality. Latency and throughput become practical constraints — if your application needs instant replies, you may accept slightly lower quality for faster, deterministic methods or use smaller models for quick drafts followed by a larger model for refinement. Also consider caching repeated prompts and using parameter-efficient techniques to tune behavior without retraining the whole model.
A few concrete rules of thumb will save time. Start with greedy or low-temperature sampling to set a baseline, then raise temperature or switch to top-p when output feels repetitive. Use beam search when you need structured, high-precision outputs and can afford the compute. When safety or format strictness is critical, add constraints and rerank generations using a verifier. These steps turn decoding from magic into a repeatable workflow you can iterate on.
Now that you know how inference choices steer a model’s voice and reliability, the next step is to practice: try the different knobs on real prompts, compare outputs side-by-side, and measure what matters (accuracy, creativity, latency). With that hands-on feedback loop, we’ll be ready to dig into how attention patterns and model internals influence the probabilities that these decoding methods use — a useful lens for fine-tuning behavior and improving results.
Real-World Applications and Risks
Imagine you’re sitting at your laptop with a real problem to solve — a product launch, a tricky bug, or a marketing brief — and you open a chat with a generative AI to get help. Generative AI and large language models (LLMs) show up here like talented generalists: they can draft copy, propose code, summarize long reports, and even brainstorm new product names. Because we already walked through how these models learn patterns and predict tokens, it helps to think of them now as tools you’ll put into real workflows, not magic boxes that always get it right.
Think about common jobs you might hand to an LLM in daily work: drafting customer emails, generating boilerplate code, creating study guides, or producing creative prompts for designers. Each of these applications benefits from a different setup — sometimes heavy fine-tuning is worth the investment, other times precise prompt engineering (crafting your request carefully) plus a verification step is enough. We’ve seen that decoding and inference choices shape tone and reliability, so the same prompt can produce a concise legal-style summary with low temperature or a creative brainstorm with higher temperature and top-p sampling.
Let’s walk through a concrete scene: you need a customer-support assistant that summarizes tickets and suggests replies. First we pick a base LLM for language fluency and latency. Then we decide: do we fine-tune on past tickets so the model learns company voice, or do we rely on prompt engineering to steer outputs? How do you decide when to trust an LLM’s answer? We answer that by adding tests: validation sets for correctness, human review for tone, and a verifier that flags uncertain responses during inference so a human can approve before sending.
Real-world use also brings real-world risks that you must plan for. Hallucinations — confident but false statements — are a persistent concern because models predict plausible continuations, not verified facts. Bias shows up when training data reflects societal prejudices, causing unfair or harmful outputs unless corrected. There are also privacy risks: models can sometimes reveal sensitive information from their training data, and adversarial users can try to coax unsafe responses through clever prompts. Recognizing these failure modes early makes mitigation practical rather than reactive.
So what practical safeguards work in production? First, use human-in-the-loop workflows where high-stakes outputs require approval, and instrument continuous monitoring for accuracy, bias, and safety regressions. Second, apply technical controls: constrained decoding to forbid dangerous tokens, reranking generations with a verifier model, and parameter-efficient fine-tuning so task-specific behavior lives in small, auditable modules. Third, test with adversarial and edge-case inputs (red-teaming) and log enough context to trace errors without exposing private data. Combining these approaches turns an LLM from a black box into a managed component of your system.
With those trade-offs in view, you’ll start to see patterns: LLMs open routes to automation and creativity, but they need guardrails — design choices about fine-tuning, prompt engineering, decoding strategy, and verification — to be useful and safe. As we go deeper next, we’ll examine how to measure those guardrails in practice and set up the monitoring and evaluation that keep real-world deployments both powerful and responsible.



