Map the Use Case
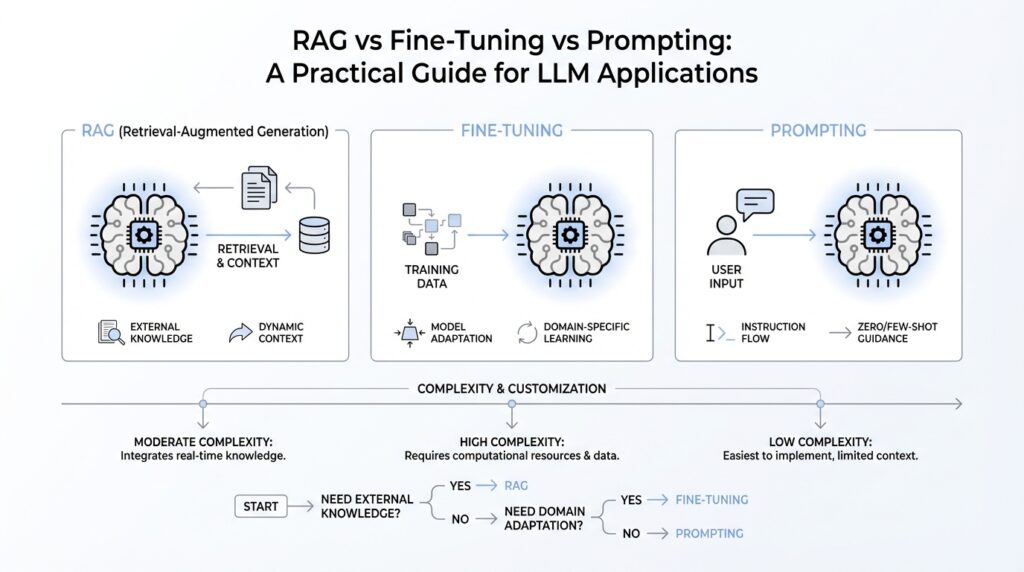
Building on this foundation, the real job is not picking a favorite technique; it is mapping the problem in front of you. If the model already has the right knowledge and mainly needs clearer direction, prompt engineering is the best place to start, and OpenAI notes it is often enough for tasks like summarization, translation, and code generation. That is why we begin with a baseline prompt and ask a very practical question: what is the model failing at right now—understanding the task, finding the facts, or behaving consistently? Once you know that, the path becomes much clearer.
When should you use RAG instead of fine-tuning? Use RAG, or retrieval-augmented generation, when the model needs outside information at the moment it answers. OpenAI describes RAG as retrieving content to augment the prompt before generating a response, and points to it as the right move when the model lacks the needed context, the information is out of date, or the task depends on proprietary knowledge. Think of it like handing the model a textbook at the desk instead of hoping it remembers everything from class. If your use case lives in documents, policies, tickets, or a changing knowledge base, RAG is usually the cleaner fit.
Fine-tuning, by contrast, is about teaching the model how to behave, not just what to know. OpenAI says fine-tuning lets you give a base model the kinds of inputs and outputs you expect so it can excel at the task you care about, and it is especially useful when you want a consistent format, a steadier tone, or better handling of task-specific patterns. It also helps when you need more examples than would fit in a single prompt, when you want to keep prompts shorter, or when you want to train on proprietary data without repeating it every time. In other words, fine-tuning is the right lever when the issue is repetition, style, or reliable structure rather than missing facts.
Here is where things get interesting: these are not three rungs on a ladder so much as different levers in the same control room. OpenAI explicitly warns against treating prompt engineering, RAG, and fine-tuning as a simple linear sequence, because each one solves a different problem. A typical workflow starts with prompt engineering, then adds retrieval if the answer needs fresher or private context, and then fine-tunes if you still need more consistent behavior. That means the smartest mapping strategy is to look at the failure mode first: if the answer is wrong because the model is uninformed, reach for RAG; if the answer is technically informed but awkward, inconsistent, or poorly formatted, reach for fine-tuning.
So what does that mean in practice for your LLM application? It means you do not need to solve everything at once. Start with the simplest prompt you can write, define what a good answer looks like, and measure the gap before you add more machinery. OpenAI recommends using evals, or evaluations, to compare outputs against representative test data, then iterating on the prompt or training data based on what you learn. That habit turns the decision from a guess into a guided walkthrough: first we see whether the model needs better instructions, then whether it needs better context, and only then whether it needs a stronger behavioral imprint.
Start With Prompting
Building on this foundation, the first move in many LLM applications is still the humblest one: write a better prompt. When the model already has the right knowledge and the main problem is clarity, prompt engineering gives you the fastest path forward because it changes how you ask before you reach for bigger tools. Think of it like giving directions to a helpful colleague; if the request is vague, the result wanders, but if the request is specific, the answer often snaps into place. How do you know whether prompting is enough? Start by seeing whether the model can do the task at all when the instructions are clear, because that tells you whether you have a communication problem or a knowledge problem.
That is why a baseline prompt matters so much. A baseline prompt is your plain starting version, the one you use before adding templates, examples, or extra logic, and it gives you something honest to compare against. If you ask for a summary, a translation, or a piece of code and the output is mostly right but a little messy, then prompt engineering is usually the first lever to pull. The goal is not to write a perfect prompt on the first try; the goal is to make the task legible to the model so you can see what still breaks.
Once you begin shaping the prompt, the work feels a lot like tuning a recipe. You decide what ingredients belong in the response, what style you want, and what should be left out, then you give the model that structure in plain language. For example, instead of asking for a vague explanation, you can ask for a short answer, a beginner-friendly tone, and a specific format such as one paragraph followed by a concrete example. This is where prompt engineering shines in LLM applications: it can improve consistency, reduce wandering answers, and make outputs easier for people to use without changing the model itself.
Prompting also gives you a low-cost way to discover the real failure mode. If the answer improves when you add clearer instructions, a stronger example, or a tighter format, then the model was probably not confused by the subject itself; it was confused by the request. On the other hand, if the model still invents facts, misses private context, or drifts away from your domain even after careful prompting, that is a sign to stop squeezing the prompt and start thinking about retrieval or training. In other words, prompt engineering is not a compromise; it is the diagnostic step that helps you avoid solving the wrong problem.
There is another reason to start here: prompting teaches you what your application actually needs before you invest in heavier machinery. A good prompt can reveal whether your workflow depends on tone, format, reasoning steps, or domain-specific phrasing, and that insight makes every later decision sharper. You may discover that a single well-designed prompt handles most cases, or you may learn that the model needs outside context or more durable behavior changes. Either way, starting with prompting gives you a clean, practical baseline, and that baseline becomes the reference point for everything that comes next.
Add RAG for Context
Building on this foundation, RAG, or retrieval-augmented generation, becomes the next move when the prompt is clear but the answer still depends on outside facts at the moment you ask. Think of it like giving the model a folder of relevant papers before the meeting starts. OpenAI describes retrieval as semantic search over your data and notes that it is especially powerful when combined with models that synthesize responses.
A vector store is the quiet engine behind that process, and it helps to picture it as an index for your documents. Semantic search means searching by meaning, not just by exact words, which matters when a user says “return policy” but the document uses a phrase like “refund window” or “post-purchase terms.” OpenAI’s retrieval guide points out that semantic search can surface relevant results even when the query and the source share few or no keywords.
In practice, RAG adds a short detour before generation. We first place documents, policies, support tickets, or notes into the vector store, then search that store with the user’s question, and then pass the best snippets into the prompt so the model can answer with fresh context. OpenAI’s model-optimization guidance frames this as part of a broader loop: provide relevant context and instructions, measure the output, and refine what is missing. That makes RAG feel less like a magic trick and more like careful preparation.
When should you use RAG instead of fine-tuning? Use RAG when the answer needs current, private, or source-specific information. Use fine-tuning when the model already knows the facts but needs to behave more consistently, follow a format, or adopt a particular style. OpenAI’s fine-tuning guide describes fine-tuning as a way to provide example inputs and outputs so a base model excels at the task you care about, and it highlights benefits like shorter prompts and training on proprietary data without repeating it in every request.
How do you know the retrieval step is actually helping? This is where evals, or evaluations, earn their keep. For Q&A over docs, OpenAI recommends measuring things like context recall and context precision, then comparing runs as you tweak retrieval, prompts, or both. If the answer improves when the right passages are retrieved, the problem was context; if the retrieved passages are good but the response still feels uneven, as an inference, the remaining gap is usually behavior rather than missing information.
Once RAG has given the model enough grounding, you can see the rest of the application more clearly. Some outputs still need tighter structure, a steadier tone, or better instruction-following, and that is when fine-tuning starts to look attractive. In other words, retrieval handles the library, and fine-tuning handles the delivery style, which is why the strongest LLM applications often use both tools for different jobs.
Fine-Tune for Consistency
Building on this foundation, fine-tuning starts to matter when your model already knows the task but keeps behaving a little differently each time. You may have seen this in the wild: one response is crisp and structured, the next is wordy, and a third drifts off-format even though the question is the same. How do you get the model to answer the same way every time? That is where supervised fine-tuning, or SFT, comes in, because it teaches the model with example inputs and known good outputs so it can more reliably produce the style and content you want.
Think of it like showing a new teammate a stack of excellent finished work before asking them to take over. In the context of LLM applications, that stack is your training data: prompt-and-answer pairs that demonstrate the exact shape of a good response. OpenAI’s guidance is clear that SFT is a strong fit for generating content in a specific format and for correcting instruction-following failures, which makes it especially useful when your prompt is already decent but the output still feels slippery. The goal is not to teach the model new facts every time; the goal is to teach it a dependable habit.
The most important ingredient is not volume, but agreement. OpenAI recommends starting with a small, high-quality dataset and notes that performance often improves with 50 to 100 well-crafted examples, while the minimum for fine-tuning is 10. That matters because consistency comes from pattern, and pattern only emerges when your examples look and sound alike in the ways you want the model to copy. If one example sounds formal, another sounds casual, and a third ignores the required structure, the model learns a blur instead of a rule. In other words, fine-tuning for consistency works best when your data already looks like the behavior you want in production.
Here is where the practical part gets interesting. OpenAI recommends keeping every training example in the same format you expect at inference time, and that advice is easy to overlook when you are moving fast. If your app will ask for JSON, then your training outputs should look like JSON; if your app needs a short, friendly support reply, then your training data should show short, friendly support replies, over and over again. You can also include the same instructions or prompt framing in each example, especially when you have fewer than 100 examples, because that repetition helps the model learn the full pattern instead of guessing at the missing pieces.
When fine-tuning goes sideways, the fix is often hiding in the dataset itself. OpenAI’s best-practices guide suggests checking whether the training examples contain the same grammar, logic, or style problems you are seeing in the output, whether the examples are balanced, and whether they include all the information needed for a correct response. If your dataset over-represents refusals, the model may become overly cautious; if your examples are inconsistent, the model will inherit that inconsistency. The safest mindset is to treat the fine-tuning dataset like a recipe: if the ingredients are mixed carelessly, the final dish will taste uncertain no matter how strong the oven is.
This is why evals, or evaluations, stay in the loop even after training. OpenAI recommends building a test set and comparing your fine-tuned model against it so you can see whether the change actually improved the behavior you care about. If the model is still wobbling, you can adjust the data, increase or decrease the number of training examples, or tweak hyperparameters, which are the training settings that control how the model learns. For consistency work, that feedback cycle is the real payoff: you are not hoping for a better answer, you are measuring whether the model now answers in the same reliable shape every time. Once that behavior is stable, you are in a good position to decide whether the next gap is structure, context, or something RAG needs to supply.
Compare Tradeoffs
Building on this foundation, the real comparison is not “which technique is best?” but “which tradeoff matters most for this LLM application?” Prompt engineering is the lightest tool because it changes instructions, not the model itself, and OpenAI describes it as the practice of writing effective instructions so the model consistently produces the output you want. That makes prompting the fastest way to test an idea, but it also means you are still relying on the model’s existing knowledge and behavior. If the answer is mostly right but the shape is wrong, prompting is often enough; if the answer is missing facts, style alone will not fix it.
Here is where the first tradeoff becomes clear: prompting is cheap to try, but it is fragile when your use case depends on facts that live outside the model. RAG, or retrieval-augmented generation, adds a retrieval step before the answer is written, and OpenAI says retrieval works by semantic search over your data using vector stores, which surface relevant results even when the query and source share few keywords. In plain terms, RAG trades a little extra plumbing for fresher, source-specific, or private context. How do you know you need it? If the model is well-instructed but still cannot answer because the information changes, lives in documents, or comes from proprietary knowledge, RAG is usually the better fit.
Fine-tuning sits on a different branch of the decision tree. OpenAI says supervised fine-tuning trains a model with example inputs and known good outputs so it can more reliably produce the style and content you want, and it is especially useful for generating a specific format or correcting instruction-following failures. The payoff is consistency: shorter prompts, fewer in-request examples, and the ability to train on proprietary data without repeating it every time. The tradeoff is that you are paying upfront with training data and experimentation, so fine-tuning makes the most sense when the task repeats often enough that stable behavior matters more than quick iteration.
Another way to think about the comparison is maintenance. Prompting is like editing the note you hand to the model, so it is easy to revise but can become messy as the workflow grows. RAG is like keeping a library next to the desk, which keeps facts current but adds retrieval, chunking, and vector store management; OpenAI’s retrieval guide notes that vector stores are the containers powering semantic search and that files are chunked, embedded, and indexed when added. Fine-tuning is like training a habit, which can reduce prompt length and improve consistency, but it also means you must keep your dataset clean and revisit it when your requirements change. In practice, that means RAG often carries the highest infrastructure overhead, while fine-tuning carries the highest data curation overhead.
Cost and latency are part of the same story. Prompting usually wins on simplicity, but long prompts can become expensive and repetitive at scale, which is why OpenAI highlights shorter prompts as one benefit of fine-tuning. RAG adds retrieval time and context assembly, so it can make each request heavier even though it protects you from stuffing every fact into the prompt. Fine-tuning shifts work into training, then gives you a model that may be cheaper or faster to use afterward, especially when the same behavior is needed again and again. The practical question is not “Which is cheapest?” but “Where do I want to pay: at runtime, during retrieval, or during training?”
This is why evals, or evaluations, stay so important in the comparison. OpenAI recommends measuring a baseline, running tests on representative data, and then improving the prompt, retrieval setup, or fine-tuning dataset based on what the results show. That gives you a simple rule of thumb: use prompting when the model needs clearer direction, use RAG when it needs better context, and use fine-tuning when it needs steadier behavior. Once you see the problem through that lens, the choice stops feeling abstract and starts feeling like a series of practical tradeoffs you can test one by one.