Clarify Tenant and Scope Boundaries
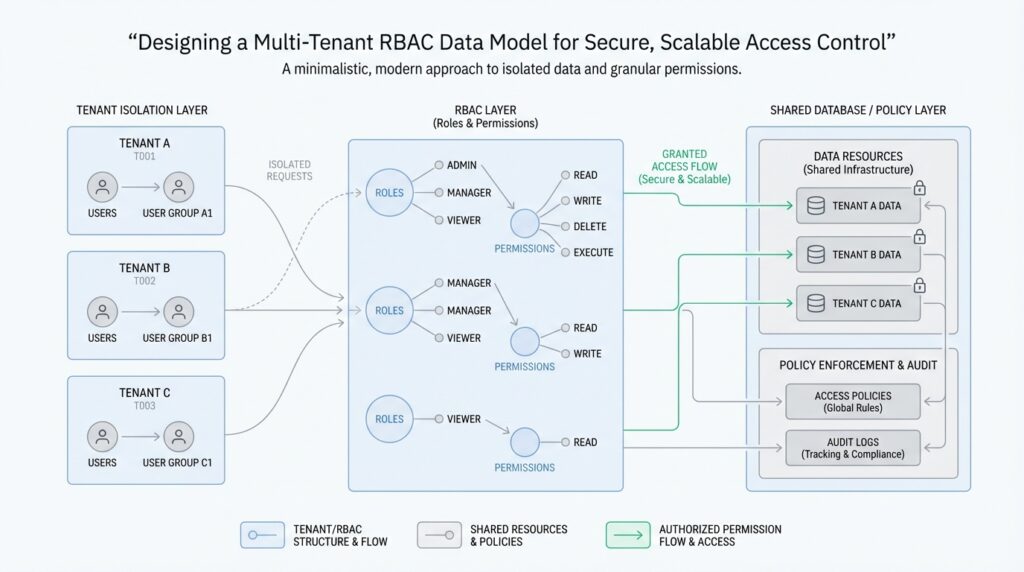
Building on this foundation, the first thing we need to make clear in a multi-tenant RBAC data model is where one tenant ends and another begins. A tenant is the customer, organization, or workspace that owns a private slice of the system, and that slice must stay separate from every other slice. Think of it like an apartment building: each family can have its own keys and rooms, but the walls matter just as much as the locks. If you blur that line, even a perfectly designed role-based access control system can leak data across customers.
This is why tenant boundaries come before role names, permissions, or dashboards. When you ask, “How do you keep a role that is powerful in one tenant harmless in another?”, you are really asking whether every access decision is anchored to the right tenant identifier. In practice, that means the tenant context must travel with users, roles, assignments, and protected resources. A role like “manager” only means something when we know which tenant it belongs to, because the same label can safely exist in thousands of different organizations without ever referring to the same people or data.
Now that we have the tenant boundary in place, the next layer is scope, which answers a different question: where inside that tenant does the permission apply? Scope is the range of objects a role can touch, such as a single project, a department, a folder, or the entire tenant. This is where the multi-tenant RBAC data model becomes more precise, because not every permission should be all-or-nothing. A billing user might be allowed to view invoices for one workspace, while a support lead might manage all workspaces inside the tenant, and a platform administrator might sit outside tenant scope entirely.
That distinction matters because tenant and scope are not the same thing, even though beginners often treat them like twins. Tenant says, “Which customer owns this data?” Scope says, “Which part of that customer’s world can this role reach?” If we mix them together, we create awkward rules that are hard to explain and even harder to enforce. A clean model keeps tenant_id as the outer guardrail and then adds scope_type and scope_id, or a similar structure, so each assignment says both who it belongs to and how far it stretches.
Here is where the data model starts to feel real. A user record should usually carry a tenant_id, a role assignment should point to both the tenant and the scope, and each protected resource should also know which tenant it belongs to. When an access check runs, the system first confirms the tenant matches, then checks whether the role covers the requested scope, and only then evaluates the permission itself. That sequence is what prevents a user from borrowing access from one tenant and accidentally carrying it into another.
It also helps to define a clear boundary for shared or cross-tenant access, because this is where many systems get messy. If you have a support engineer, an internal auditor, or a platform admin, do not treat them as “special users” with vague shortcuts; give them an explicit global scope or a separate platform-level domain. That way, the multi-tenant RBAC data model stays honest about what is tenant-local and what is system-wide. You keep the rules readable, and you make it much easier to audit why a person could see a given record.
As we discussed earlier in the broader access-control flow, clarity is what keeps security from turning into guesswork. Once tenant boundaries and scope boundaries are explicit, every later decision becomes easier to reason about, test, and explain to your future self. You are no longer asking whether a permission exists in the abstract; you are asking whether it exists for this tenant, at this scope, on this resource. That one habit does a lot of quiet work in a multi-tenant RBAC data model, and it sets up the rest of the design to stay secure as it grows.
Define Core Authorization Entities
Building on this foundation, the next step is to name the characters in the story of access. In a multi-tenant RBAC data model, you usually start with four core authorization entities: the user or service account that asks for access, the role that describes a job, the permission that names an allowed action, and the resource that holds the data or feature being protected. If tenant and scope tell us where access applies, these entities tell us who is acting, what they can do, and what they can do it to.
The user is the easiest place to begin because every permission check starts with a request from someone or something. A user is a person, while a service account is a non-human identity used by software, such as a background job or integration. Thinking about a user identity in a multi-tenant RBAC data model is a little like putting a name tag on every guest at a large conference: before we decide where they can go, we need to know exactly who walked in the door.
Next comes the role, which is not the permission itself but the container that groups permissions into a meaningful job. A role is a label like “billing manager,” “support agent,” or “editor,” and it gives you a human-friendly way to describe access without listing every action one by one. This is why role-based access control works so well: instead of teaching the system dozens of isolated rules, you teach it a few job shapes and let those shapes carry the details. When people ask, “Why does a role matter if permissions already exist?”, the answer is that roles make the multi-tenant RBAC data model understandable to humans.
Permissions are where the real precision lives. A permission is the smallest unit of allowed behavior, such as viewing an invoice, updating a project, or deleting a record. You can think of permissions like verbs in a recipe: one verb says “stir,” another says “bake,” and another says “serve.” In the same way, permissions tell the system exactly which action is allowed, and they prevent a role from becoming a vague bucket of power that nobody can explain clearly.
Now that we know who can act and what action they want, we need the thing they are acting on: the resource. A resource is any protected object in the system, such as a document, customer record, project, folder, or dashboard. This matters because authorization is never abstract for long; it always ends up touching a real object. In practice, how do you know whether a user can open a specific invoice? You check whether the user’s role grants the needed permission on that resource, within the tenant and scope you defined earlier.
The glue between these pieces is the role assignment, which links a user to a role in a specific context. This is where the multi-tenant RBAC data model becomes operational instead of theoretical, because a role sitting in a table means very little until it is attached to an identity and bounded by the right tenant and scope. A single person can hold different roles in different places, and that is not a contradiction; it is the whole point of separating identity from access. One user might be a viewer in one workspace, an editor in another, and a support contact in a third.
Once these entities are clear, the rest of the system starts to feel less mysterious. You are no longer juggling fuzzy ideas like “someone can probably edit this,” because you can trace the path from user to role, from role to permission, and from permission to resource. That clarity is what keeps a multi-tenant RBAC data model maintainable as it grows, and it gives us a clean base for the next layer, where we connect these entities into rules the system can enforce consistently.
Separate Global and Tenant Roles
Building on this foundation, the next choice in a multi-tenant RBAC data model is to keep global roles and tenant roles in separate lanes. That separation matters because a person who helps maintain the whole platform does not need the same access pattern as someone working inside one customer workspace. If you blend those powers together, the model starts to feel like one giant master key ring, and that is where security gets slippery. How do you let a support engineer help many customers without turning them into an all-powerful tenant admin?
The clean answer is to treat a global role as system-wide authority and a tenant role as customer-specific authority. A global role belongs to the platform itself, so it can cover tasks like managing infrastructure, reviewing logs, or assisting with account recovery across tenants. A tenant role, by contrast, lives inside one tenant and only speaks for that tenant’s data, users, and workflows. In a well-shaped multi-tenant RBAC data model, these two kinds of roles should look related, but they should not behave as if they are interchangeable.
This is where many designs get tangled. If you use the same role record for both platform staff and tenant users, you force the system to guess whether a permission is broad or local every time it runs an access check. That guessing creates brittle rules, confusing audits, and too many edge cases to reason about confidently. When we separate global and tenant roles, we give each one a clear job: the global role handles cross-tenant operations, while the tenant role stays safely inside its own boundary.
A practical way to picture it is to imagine a building with both a front desk team and individual apartment residents. The front desk can open shared doors, inspect building systems, and help multiple units when needed, while each resident can only enter their own apartment and personal storage area. Both groups use keys, but the keys mean different things depending on who holds them. That same idea applies in a multi-tenant RBAC data model: a global role is a building-level key, and a tenant role is an apartment-level key.
To make that distinction real in the database, it helps to store global and tenant roles in separate namespaces or at least mark them with a role_type that cannot be ignored. A global role assignment should not require a tenant_id in the same way a tenant role assignment does, because its authority comes from the platform layer. A tenant role assignment, on the other hand, should always point to a specific tenant and should never be allowed to drift beyond it. This keeps the rules readable, and it gives you a much cleaner path when you later ask, “Is this permission valid here, for this person, in this context?”
The same separation also makes auditing far easier. When someone sees an unusual action, they should be able to tell whether it came from a global operator role or a tenant-scoped business role without tracing through a maze of exceptions. That clarity matters because global access is usually the most sensitive part of the system, and it should stand out instead of hiding inside ordinary tenant permissions. A strong multi-tenant RBAC data model makes that difference visible instead of implicit, which is exactly what you want when access decisions need to be explained after the fact.
Once you separate the two, another benefit appears: you can evolve them independently. Tenant roles can grow with product features like project editors, billing viewers, or workspace admins, while global roles can stay tightly controlled and relatively small in number. That keeps the model flexible without making it fuzzy. And as we move forward, this clean split gives us a stable base for deciding how role assignments, inherited permissions, and cross-tenant support workflows should fit together.
Link Permissions to Resources
Building on this foundation, we finally connect the words permission and resource so the model can do real work. Up to this point, we have named the actors and drawn the boundaries; now we need to answer the practical question readers usually ask: how do you know that a role can edit this invoice but only view that project? In a multi-tenant RBAC data model, that answer comes from linking each permission to a specific resource type, and sometimes to a specific resource instance, so access is never vague or floating in the air.
This link is easier to understand if we treat permissions like verbs and resources like nouns. A permission such as invoice.read or project.update says what action is allowed, while the resource says what object receives that action. That pairing keeps the system honest, because “edit” means something very different on a dashboard than it does on a user profile or a billing record. When you design a multi-tenant RBAC data model, this is the moment where access control stops being abstract policy and becomes a set of precise relationships you can store, query, and audit.
A clean way to model this is with a permission-to-resource mapping table, often a many-to-many relationship, because one permission can apply to many resources and one resource can accept many permissions. Think of it like a library card catalog: the card does not contain the book, but it tells you exactly which shelf and which category are connected. In the same way, the data model should record that a role includes project.read, and that project.read applies to the project resource type, while a separate assignment may attach it to only one project inside one tenant. That structure lets the multi-tenant RBAC data model stay flexible without turning into a pile of one-off rules.
Now that we have the basic link, we need to decide how specific that link should be. Some permissions belong to an entire resource type, such as every invoice in a tenant, while others point to a single resource instance, such as one invoice, one folder, or one customer record. This is where the model gets useful for real products, because not every user should inherit the same reach just because they share a role name. If you have ever wondered, “Why does one person get access to all projects while another only sees one?”, the answer is usually that the permission-resource link carries both the action and the level of scope.
Inheritance can make this even smoother when resources live inside larger containers. For example, a folder may pass read access to the documents inside it, or a project may grant visibility to its tasks and comments. That kind of behavior can save you from repeating the same assignment on every child object, but it should be explicit rather than accidental. In a multi-tenant RBAC data model, inherited access works best when the parent-child relationship is part of the resource structure itself, so the system can follow a clear path instead of guessing.
The strongest models also keep the resource identity separate from the permission definition. A permission should describe capability, not hold the data itself, and a resource should describe the protected thing, not the rule that governs it. This separation makes the system easier to change later, because you can add a new resource type or introduce a new action without rewriting the whole access layer. It also helps audits, since you can trace exactly which permission was attached to which resource, within which tenant, and through which role assignment.
Once those links are in place, the rest of the authorization flow becomes much easier to reason about. A request arrives, the system identifies the resource, checks which permission applies to that resource type or instance, and then follows the role assignment back to the user in the correct tenant. That chain is the quiet backbone of a multi-tenant RBAC data model, and it is what turns access control from a loose idea into something you can enforce consistently as the system grows.
Enforce Tenant Isolation Rules
Building on this foundation, the real work of tenant isolation is making the rules impossible to ignore. In a multi-tenant RBAC data model, the danger is not only that someone has the wrong role; it is that a valid role may be evaluated against the wrong customer boundary. Tenant isolation is a separate layer from ordinary authentication and authorization, and a user can be authenticated and still reach another tenant’s data if the system does not enforce the boundary on every request. How do you stop that from happening? You make tenant context a required part of the access decision, not a detail the application can remember later.
The safest pattern is to treat tenant_id like a passport stamp that every protected object must carry. When a request arrives, the system should first confirm which tenant owns the target record, then compare that tenant to the caller’s tenant context, and only then ask whether the role has the needed permission. That order matters because RBAC, by itself, defines access through roles and permissions; it does not magically know which customer’s data is in view. In other words, the multi-tenant RBAC data model becomes secure only when the role check and the tenant check travel together.
This is where enforcement needs to happen in more than one place. We should not rely on one defensive check in the user interface, because user interfaces can be bypassed. Instead, the application layer, the data access layer, and any background job that reads or writes tenant data should all carry the same tenant filter. AWS’s guidance on tenant isolation is clear that shared-infrastructure systems need explicit mechanisms that tightly control access to tenant resources, and that any attempt to reach a tenant resource should be scoped to resources belonging to that tenant. That is the habit we want in code: every query, every mutation, every export, every webhook handler.
Once that habit is in place, resource ownership becomes much easier to trust. A project, invoice, folder, or dashboard should never be treated as “available” unless the system can prove it belongs to the current tenant. Think of it like a hotel key card: even if the card opens the elevator, it still has to match the right floor and room before the door will move. In practical terms, that usually means storing the owning tenant on each protected resource, then checking that value against the caller’s tenant before applying the permission rule. That simple discipline keeps the multi-tenant RBAC data model readable and makes cross-tenant leakage far less likely.
The tricky part is cross-tenant support, because real systems often need a support engineer, auditor, or platform operator to look across many customers without becoming a hidden superuser. The answer is not to blur the boundary; it is to make the exception explicit. A global role should be visibly different from a tenant role, and its power should come from a separate platform context rather than a casual shortcut in the tenant model. NIST’s RBAC model emphasizes that permissions flow through roles, which makes it a good fit for representing these distinct lanes cleanly instead of mixing them together.
That separation also improves auditing, which is where isolation rules either prove their worth or fall apart. When someone asks why a person could see a record, you want a trace that says, “This user had this role, in this tenant, against this resource, at this moment,” not a pile of implied behavior. OWASP highlights cross-tenant vulnerabilities as a real cloud risk, especially when security boundaries are weak or overly broad access slips in. A strong multi-tenant RBAC data model answers that risk by making the boundary visible in the data and enforceable in the request path.
The payoff is subtle but powerful: once tenant isolation rules are enforced everywhere, the rest of the authorization design becomes calmer. You stop wondering whether a role is “probably safe” and start checking whether it is safe for this tenant, this resource, and this operation. That gives you a system that is easier to test, easier to explain, and much harder to accidentally widen as features grow.
Validate with Access Tests
Building on this foundation, the next thing we need is proof. A multi-tenant RBAC data model can look perfect on paper, but the real question is whether it behaves the same way when a request arrives at 2 a.m., from the wrong tenant, with the wrong role, and for the wrong record. That is where access tests come in: they are automated checks that simulate real permission requests and confirm the system says yes only when it should. If tenant boundaries, scope boundaries, and role assignments are the rules of the road, access tests are the road signs that tell us whether traffic is staying in its lane.
How do you know the model is actually safe? You test the most ordinary paths first, because those are the ones users will hit every day. A member in Tenant A should open a resource in Tenant A when the role grants that permission, and the same member should be blocked from the same kind of resource in Tenant B. This sounds straightforward, but it is exactly the kind of check that catches a broken tenant filter, a forgotten scope condition, or a role lookup that was never tied back to the correct tenant. In a multi-tenant RBAC data model, a good access test does not only ask “Can this user do the thing?” It also asks “Can they do it here, on this resource, under this tenant?”
Once the happy path is covered, we need to probe the edges where models often slip. A strong test suite should include both positive cases, where access is allowed, and negative cases, where access must fail. For example, if a project editor can update one project inside a workspace, that same editor should not update a different project unless the scope explicitly allows it. The same pattern applies to resource types too: a role that can read invoices should not mysteriously gain the ability to edit users, because that would mean the permission-to-resource mapping is too loose. These tests are especially valuable in a multi-tenant RBAC data model because they verify that permissions stay precise instead of drifting into broad, hard-to-audit power.
Taking this concept further, we also need to test the tricky exceptions we discussed earlier, especially global roles and cross-tenant support. A platform operator may have a legitimate reason to act across tenants, but that access should still be traceable and deliberately granted, not accidentally inherited from an ordinary tenant role. Access tests should confirm that a global role can reach only the system-wide actions it is meant to cover, while tenant roles remain sealed inside their own customer boundary. This is also a good place to test service accounts, background jobs, and integrations, because non-human identities can be just as dangerous as human ones if the multi-tenant RBAC data model treats them loosely.
The most useful tests often look less like abstract policy checks and more like little stories. We set up a user, attach a role, create a tenant, place a resource inside that tenant, and then try the exact action we care about. That setup matters because authorization failures are often caused by bad context, not bad logic, so the test data has to resemble the real shape of the system. If your model uses tenant_id, scope_id, or resource ownership fields, the test should populate them in a way that mirrors production, because a fake setup can give you fake confidence. In other words, access tests are not only about permission rules; they are also about proving that the data model carries the right context all the way through the check.
As we discussed earlier, clarity is what keeps a security model understandable, and tests are what keep that clarity honest over time. When a teammate adds a new role, a new scope type, or a new resource, the access tests should tell you immediately whether the change preserved isolation or widened it by accident. That is why a well-tested multi-tenant RBAC data model becomes easier to trust as it grows: every new path has to survive the same tenant-aware checks, the same resource checks, and the same role checks before it can ship. With that safety net in place, we can move forward knowing the model is not only well designed, but also continuously verified in the places where it matters most.