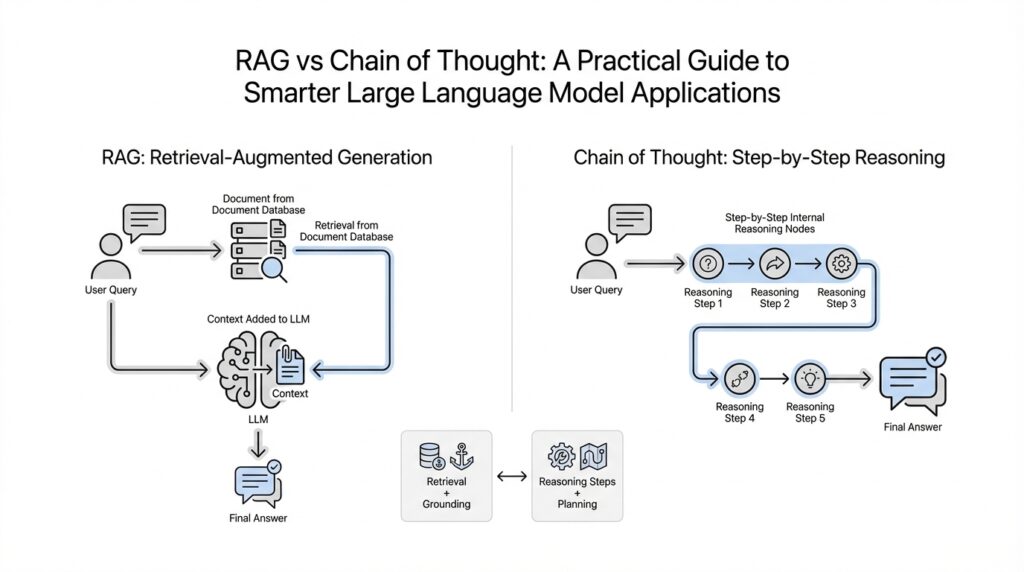
What RAG Solves
Building on this foundation, retrieval-augmented generation (RAG) solves a very specific problem: a large language model can sound fluent while still leaning on stale or incomplete memory. Instead of asking the model to answer from its training data alone, RAG gives it an external store of information to consult at the moment of answering. That makes it a better fit for questions where the value is not in clever wording, but in getting the right facts into the response at the right time.
Think of it like working with a notebook open beside you instead of trying to remember everything from scratch. When the model can retrieve passages first, it has a stronger chance of grounding its answer in something concrete rather than filling gaps with a plausible guess. The original RAG paper calls out two especially important benefits here: the ability to update world knowledge more easily and the ability to provide provenance, meaning a trace of where the answer came from. In practice, that is a big deal when you need answers you can inspect, not just answers that read well.
This is why RAG shows up so often in knowledge-intensive systems such as open-domain question answering, customer support assistants, internal search tools, and research helpers. In those settings, the question is often not, ‘Can the model talk about this topic?’ but, ‘Can it pull the right document and stay faithful to it?’ The RAG paper reports strong results on open-domain QA and found that retrieved grounding can make generated language more specific, more diverse, and more factual than a parametric-only baseline. So RAG solves the very practical problem of turning a general-purpose model into one that can work with your actual content.
In contrast to chain of thought, which helps a model reason step by step, RAG helps it gather the right ingredients before reasoning begins. Chain-of-thought prompting improves performance on arithmetic, commonsense, and symbolic reasoning tasks by encouraging intermediate reasoning steps, but it does not, by itself, give the model fresher facts or trusted source material. That is the key distinction: if the question is ‘How do we think this through?’, chain of thought is useful; if the question is ‘Where do the facts come from?’, RAG is the tool that addresses the gap.
How do you know when RAG is the better choice? Reach for it when the answer depends on documents, policies, product manuals, research notes, or any knowledge that changes over time. RAG lets you update the knowledge source without retraining the whole model every time the world shifts, which is exactly why it fits fast-moving, document-heavy workflows so well. It also helps teams answer with more confidence because the system can point back to the passages it used, making the result easier to review and defend. That is the heart of what RAG solves: not better style alone, but better access to the facts that style should be built on.
How CoT Works
Building on this foundation, chain-of-thought prompting works a little like asking someone to show their work on a scratch pad instead of blurting out the final answer. When a large language model breaks a problem into intermediate reasoning steps, it has more room to follow a path instead of leaping across a gap. That is the heart of chain of thought: not new knowledge, but a better path through the knowledge the model already has.
How do you get a model to slow down and reason more carefully? You nudge it to produce a sequence of smaller decisions rather than one big jump. Think of it like solving a puzzle with a few pieces at a time on the table, instead of trying to hold the whole picture in your head. The model may work through a math problem, compare clues, or unpack a multi-step instruction by generating those internal steps one after another.
That matters because many hard questions are really a bundle of easier questions hiding inside them. If the model must answer, “Which option is best?” it may struggle when the task actually requires first identifying the options, then comparing them, then checking for a constraint, and only after that choosing. Chain-of-thought prompting gives the model a structure for that sequence, which often improves performance on arithmetic, commonsense reasoning, and symbolic tasks. In plain language, it helps the model stop treating a staircase like a single jump.
This is where the contrast with RAG becomes especially useful. RAG brings in outside information, while chain of thought reorganizes the thinking process itself. If the model needs a policy document, a product manual, or a fresh fact, chain-of-thought prompting will not magically retrieve it. But if the model already has the needed information and the challenge is to connect the dots, chain of thought can make those connections more reliable.
A helpful way to picture it is to imagine a cook following a recipe. RAG is like opening the pantry and getting the right ingredients onto the counter. Chain of thought is like reading the recipe in order, mixing, tasting, and adjusting at the right moments instead of tossing everything into the bowl at once. Both matter, but they solve different problems. One supplies the ingredients; the other shapes the cooking process.
There is also a practical reason chain-of-thought prompting feels so powerful: intermediate steps can reduce the chance of an early mistake cascading into a bad answer. When the model explains each move, it has more opportunities to stay on track, and you get a clearer view of how it arrived there. That transparency can be useful for debugging too, because if a response goes wrong, you can often spot the step where the reasoning drifted. In other words, chain of thought is not only about better answers; it is also about more inspectable answers.
At the same time, chain-of-thought prompting is not a universal remedy. Some tasks do not benefit much from extra reasoning steps, and sometimes a model can produce convincing-looking reasoning that is still flawed. That is why you should think of it as a tool for structured reasoning, not a guarantee of correctness. When the question is, “What causes the answer to break down?” the answer is often not missing facts, but missing structure.
So when should you reach for chain of thought? Use it when the task calls for planning, multi-step logic, comparison, or careful deduction. If you are asking a model to solve a puzzle, estimate something from clues, or walk through a decision, chain-of-thought prompting often gives it the scaffolding it needs. And if you remember the earlier RAG discussion, the distinction is now clearer: RAG helps the model find the right material, while chain of thought helps it reason through that material in a more disciplined way.
Key Strengths of Each
Building on this foundation, the key strengths of RAG and chain of thought start to feel less like competing tricks and more like two different kinds of help you can give a model. RAG is strongest when the answer depends on outside information that may change, while chain of thought is strongest when the model already has the material and needs a better path through it. That split matters because a fluent answer is not the same thing as a well-grounded one, and a well-grounded answer is not the same thing as a carefully reasoned one. When should you reach for RAG, and when does chain of thought carry more weight? The answer depends on whether your bottleneck is facts or reasoning.
RAG shines when you want the model to stay close to a source of truth. In the original paper, retrieval-augmented generation combines a pre-trained language model with non-parametric memory, meaning an external store of passages that can be searched at answer time; that design was created to help with knowledge-intensive tasks, provenance, and world knowledge updates. In plain language, RAG gives you a way to open the notebook before answering instead of trusting memory alone. That is why it works so well for customer support, internal search, policy assistants, and research tools, where the best answer is the one you can trace back to a document.
Another strength of RAG is that it tends to make answers more specific and more faithful to the material it retrieved. The paper reports state-of-the-art results on three open-domain question answering tasks and says RAG produced language that was more specific, more diverse, and more factual than a parametric-only baseline. So if you are asking a model to explain a product rule, summarize a research note, or answer from a living knowledge base, RAG gives you a practical advantage: you can update the source without retraining the whole model. That makes it a very natural fit for fast-moving content, where old knowledge is a liability.
Chain of thought, by contrast, is at its best when the hard part is not finding facts but arranging them into a workable sequence. The CoT paper describes it as generating intermediate reasoning steps, and it shows gains on arithmetic, commonsense, and symbolic tasks, including strong performance on GSM8K math word problems. Think of it like asking the model to show its work on a scratch pad: it does not learn new information, but it gets more room to break a problem into smaller moves. That is especially helpful when a question hides several subquestions inside one prompt, such as comparing options, tracking constraints, or following a multi-step rule.
A second strength of chain of thought is that it makes the model’s path easier to inspect. If the model answers badly, the intermediate steps often reveal where the logic drifted, which is useful when you are debugging prompts or evaluating a workflow. The follow-up empirical study also found that the quality of CoT prompting depends less on perfect demonstrations and more on whether the reasoning is relevant to the query and ordered well, which is a useful clue for practitioners. In other words, chain of thought is not magic; it is structure, and structure is often what turns a messy guess into a disciplined attempt.
This is where the contrast becomes especially useful in real projects. RAG is the stronger choice when you need fresh facts, source grounding, or evidence you can review later, while chain of thought is the stronger choice when you need planning, comparison, or careful deduction. One pulls in the right ingredients; the other helps the model arrange those ingredients into a sensible result. If you remember that division, you can match the tool to the job instead of hoping one method will fix every weakness at once.
Seen together, their strengths complement each other beautifully. RAG helps the model answer from better material, and chain of thought helps it reason over that material more carefully. That is the practical lesson here: the best systems do not ask a model to be magically omniscient or effortlessly logical; they give it the support it needs at the right stage of the task.
When to Use RAG
Building on this foundation, the clearest time to use retrieval-augmented generation (RAG) is when the answer lives somewhere outside the model’s own memory. If you are working with policies, manuals, research notes, help-center articles, or any document set that changes over time, RAG gives the model a place to look before it speaks. That matters because the original RAG paper was built around knowledge-intensive tasks, world-knowledge updates, and provenance, which means it is designed to help you answer from evidence rather than from a guess that sounds polished.
Think of it like this: when the question is, “What does our current document say?” RAG is usually the better first move. A customer support bot, an internal search tool, or a research assistant often needs to quote or summarize a specific passage, not improvise from broad training data. In those situations, the value is in grounding the answer in a source of truth, because that makes the result easier to review, explain, and update later. RAG is especially useful when the material is large, scattered, or too fast-moving to memorize reliably.
This is also why RAG is such a practical choice for teams that cannot afford to retrain a model every time the facts shift. If a product spec changes, a policy is revised, or a new research memo lands in the knowledge base, you can update the retrieved documents instead of rebuilding the whole system. That flexibility is one of RAG’s main strengths: it keeps the model connected to fresh information without asking the model itself to become a storage system. In practice, that is a huge win when accuracy depends on current content more than on elegant wording.
How do you know RAG is the right fit when you are planning a system from scratch? Ask whether the main bottleneck is missing facts rather than missing reasoning structure. If the model already knows the kind of thinking required, but it lacks the right document, RAG is the bridge you need. If the task is open-domain question answering over your own corpus, fact checking against a reference set, or answering from an internal wiki, RAG usually adds more value than asking the model to reason harder on its own. The point is not to make the model “smarter” in a vague sense; it is to give it the right materials at the right moment.
By contrast, if the challenge is multi-step logic rather than source lookup, RAG is not the main tool to reach for. Chain-of-thought prompting works by encouraging intermediate reasoning steps, and the original paper showed gains on arithmetic, commonsense, and symbolic tasks because the model gets a clearer path through a problem it already has the ingredients for. So if you are asking, “How should we think this through?” chain of thought helps more than retrieval. But if you are asking, “Where do the facts come from?” RAG is the stronger answer, because it brings the evidence into view before the reasoning begins.
A good rule of thumb is to reach for RAG when the answer must stay close to a document, a database, or a changing knowledge base. That includes customer support workflows, compliance questions, product documentation, and research helpers where the reader may want to verify the source behind the response. It is also the safer choice when stale memory would be a real problem, because RAG can narrow the model’s attention to the passages that matter most. Once that clicks, the next choice becomes much clearer: you are no longer asking whether the model can talk about the topic, but whether it can retrieve the right evidence before it talks.
When to Use CoT
Building on this foundation, chain-of-thought prompting starts to matter most when the model already has the right information, but still needs help arranging it. Imagine you are looking at a desk covered with clues: the facts are there, yet the answer is not obvious until you sort them in the right order. That is where CoT, or chain of thought, earns its place. It asks the model to show its work, step by step, instead of leaping straight to the final answer.
You usually reach for chain-of-thought prompting when the task hides several smaller decisions inside one larger question. Maybe the model needs to compare two choices, follow a rule with exceptions, keep track of multiple conditions, or solve a math problem where each line depends on the last. In those moments, asking for a one-shot answer can feel like asking someone to jump across a stream in a single leap. CoT gives the model stepping stones, which is especially useful for planning, arithmetic, commonsense reasoning, and symbolic tasks.
So when should you ask a model to think step by step instead of search for more facts? The easiest answer is this: use CoT when the bottleneck is reasoning, not retrieval. If the model already has the needed material and the hard part is connecting the dots, chain-of-thought prompting helps it slow down and organize those connections. In contrast to RAG, which brings in outside evidence, CoT works inside the thinking process itself. That is why the two tools solve different problems, even though they may appear side by side in the same application.
A simple way to feel the difference is to picture a recipe. RAG is like opening the pantry and putting the right ingredients on the counter, while CoT is like following the recipe in order so you do not mix, taste, and bake at the wrong time. If you are asking, “What does the policy say?” or “What does the manual contain?” then retrieval is the bigger need. If you are asking, “Given these rules, which option wins?” then chain of thought is doing the heavier lifting. The model does not need more facts in that second case; it needs a clearer route through the facts it already has.
Chain-of-thought prompting is also useful when you want to inspect how the model arrived at its answer. That matters in debugging, because a wrong response is often easier to fix when you can see which step went off course. It also helps in workflows where the reasoning itself is part of the value, such as explaining a decision, working through a puzzle, or checking a multi-step calculation. In practice, CoT gives you more than an answer; it gives you a path you can examine.
At the same time, we should be careful not to treat chain of thought as a universal cure. Some questions are too simple to benefit from extra reasoning, and some prompts can produce confident-looking steps that still miss the mark. So when you use CoT, think of it as a tool for structure, not a guarantee of correctness. It works best when the model is not lost because of missing knowledge, but because the problem needs to be unpacked before it can be solved.
A good rule of thumb is to ask whether the challenge is “finding” or “figuring out.” If you need fresh facts, documents, or source-backed evidence, RAG is the better starting point. If you already have the ingredients and need the model to reason carefully through them, chain-of-thought prompting is the better fit. Once that distinction clicks, the choice feels much less mysterious—and it becomes much easier to decide whether the next step is retrieval, reasoning, or a little of both.
Combine RAG and CoT
Building on this foundation, the most practical systems do not ask you to choose between RAG and chain of thought at all. They let retrieval bring the right evidence to the table, then let reasoning organize that evidence into an answer that actually makes sense. If you have ever wished a model could both find the relevant passage and think carefully about what it means, this is that moment: RAG handles the sourcing, and CoT handles the interpretation.
How do you combine them in practice? Start with retrieval-augmented generation, which means the model searches for the most relevant documents or passages before it answers. Then give the model a prompt, meaning a written instruction, that encourages step-by-step reasoning over those passages instead of a rushed final response. The result is a two-stage flow: first we gather the ingredients, then we cook with them. That sequence matters because the model is less likely to invent missing facts when it has to reason from concrete text already in front of it.
This combination is especially useful when the question is both factual and multi-step. Imagine you are asking about a company policy that lives in a handbook, but the answer also depends on comparing exceptions, deadlines, and conditions. RAG can pull the policy text into view, while chain of thought can help the model trace how one clause affects another. Without retrieval, the model may reason elegantly about the wrong source material. Without reasoning, it may quote the right passage but miss the practical answer hiding inside it.
A good hybrid workflow often looks like a careful conversation. First, the system retrieves a small set of relevant passages from a knowledge base, document store, or search index. Next, the model is asked to read those passages, identify the key facts, and work through the problem in order. Finally, it synthesizes, meaning it combines those pieces into one coherent response. In other words, RAG gives the model a map, and chain of thought helps it follow the route without taking unnecessary turns.
This is where the combination becomes more powerful than either method alone. Retrieval improves grounding, which means the answer stays anchored to evidence rather than drifting into plausible-sounding guesses. Reasoning improves structure, which means the answer does more than repeat what it found; it connects the dots, resolves conflicts, and handles exceptions. So when people ask, “Can you use RAG and CoT together?” the answer is not only yes, but often that is the better design when the task mixes changing facts with nontrivial logic.
There is also a more subtle benefit: the two methods can help each other expose errors earlier. If the retrieved passages are off-topic, the reasoning step has less to work with, and that problem becomes visible quickly. If the reasoning step jumps too fast, the retrieved text gives you a place to check whether the model misread the source or overlooked a detail. That makes a combined RAG and CoT system easier to debug because you can inspect both the evidence and the thought process, instead of guessing where the failure began.
What causes this pairing to work so well in real applications? It is the division of labor. Retrieval answers the question, “What information should we trust?” and chain of thought answers, “How should we use it?” Once that clicks, you can design systems that feel more careful without becoming rigid. You can ask a support assistant to find the latest policy, compare relevant sections, and explain the outcome in plain language. You can ask a research assistant to gather source material, evaluate it step by step, and produce a response that is both grounded and thoughtful.
The practical takeaway is simple: do not treat retrieval and reasoning as separate tricks that compete for attention. When you combine RAG with chain of thought, you give the model a better starting point and a better working method. That pairing is what turns a fluent model into a more reliable helper, especially when the answer depends on both where the facts come from and how those facts fit together.