What Is a Transformer? (arxiv.org)
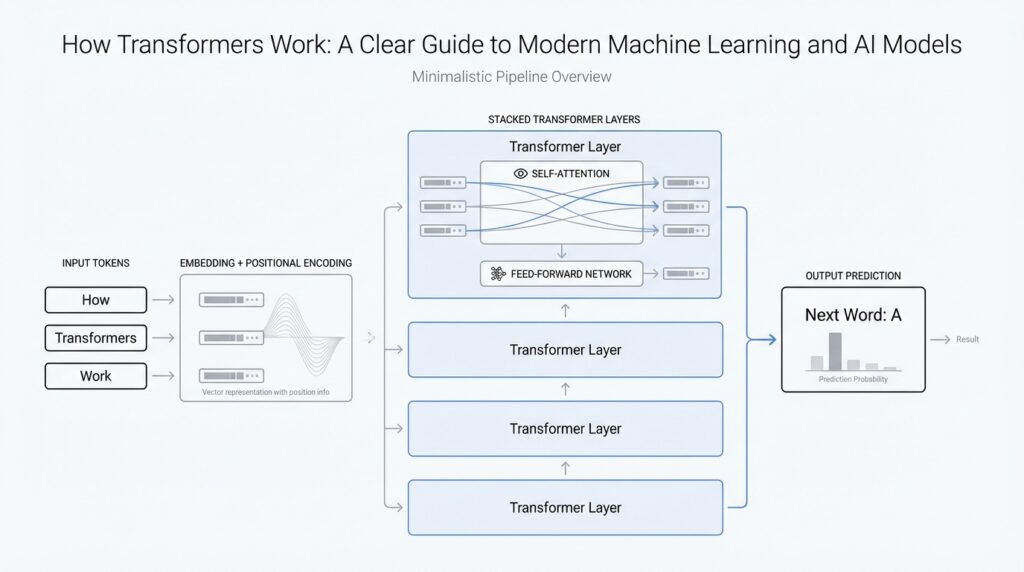
Building on that foundation, a transformer is a neural network architecture for sequence data, especially text, that learns relationships between tokens instead of reading them one by one. Earlier machine-learning systems often used recurrent neural networks or convolutional networks, which moved through a sentence in a more step-by-step way. The transformer takes a different path: it uses attention to let every token look at the others and decide what matters most. That shift is the reason the transformer model became such a turning point in modern AI.
How does a transformer make sense of a sentence without marching through it word by word? The answer is self-attention, which you can think of as a careful conversation inside the model. For each token, the model builds a query, a key, and a value: the query is what that token is looking for, the key is a kind of label for what each other token offers, and the value is the information to pull through. The model compares the query with all the keys, turns those comparisons into weights, and then blends the values into a new representation. In plain language, each token learns which other tokens deserve its attention.
This is where the transformer gets especially interesting: it does not rely on a single attention pattern. Instead, it uses multi-head attention, which means several attention mechanisms run in parallel. Think of it like looking at the same sentence through different pairs of glasses at once, where one head may track grammar, another may follow meaning, and another may notice long-distance connections. After each head produces its own view, the model combines them into one richer representation. That parallel design helps the transformer capture more than one kind of relationship at the same time.
There is one catch, though. If the model only uses attention, it still needs a way to know word order, because attention alone does not tell it whether a token came first or second. The paper solves this with positional encodings, which are extra signals added to the input embeddings at the bottom of the encoder and decoder stacks. You can picture them like seat numbers in a theater: the words are the people, and the positional encodings tell the model where each person sits. Without that numbering, “dog bites man” and “man bites dog” would look too similar.
The transformer itself is built from two main towers: an encoder and a decoder. The encoder reads the input sequence and turns it into a set of continuous representations, while the decoder generates the output one token at a time. Inside each encoder layer, the paper uses a multi-head self-attention sub-layer and a position-wise feed-forward network, with residual connections and layer normalization helping the information flow smoothly. In the decoder, masking prevents later positions from seeing future tokens, so the model cannot peek ahead while it is predicting. That masking is what makes the process auto-regressive, meaning it produces output step by step using earlier outputs as context.
The reason this architecture caught on is practical as well as elegant. In the original paper, the transformer matched or surpassed prior machine-translation systems while being more parallelizable and much faster to train. That matters because attention lets the model connect distant parts of a sequence with fewer sequential steps than older approaches needed. So when people ask what a transformer is, the shortest honest answer is that it is a model built to let tokens attend to one another directly, with structure added to preserve order and generate outputs cleanly. Once that picture clicks, we are ready to look at how the attention mechanism does the real work under the hood.
Why Attention Replaced RNNs (arxiv.org)
Imagine you are trying to follow a long conversation where each new sentence depends on something said much earlier. That is the exact kind of job sequence models face, and it is where recurrent neural networks, or RNNs, started to feel cramped. An RNN reads data one step at a time, carrying a hidden state forward like a notebook page that keeps getting rewritten. That design can work for short sequences, but as the sequence grows, the notebook starts to lose important details. Attention changed the story because it let the model look back at the whole sequence directly instead of relying on a fragile step-by-step memory.
The main problem with RNNs was not that they were wrong, but that they were slow and easily distracted by distance. Each word had to wait for the previous word to be processed before the model could move on, which made training feel like walking through a hallway one door at a time. Worse, information from the beginning of a sentence often faded by the time the model reached the end, so long-range dependencies became hard to preserve. If you have ever tried to remember the subject of a long sentence after several clauses, you already understand the basic challenge. How do you keep track of important earlier context when the path forward is so sequential?
Attention answered that question with a different idea: instead of compressing everything into one memory stream, let each token reach out and ask what matters. In a transformer, attention gives every token a chance to compare itself with every other token and assign importance where it belongs. That means the model does not have to wait for a chain of earlier steps to finish before learning a relationship. A pronoun can connect to the noun it refers to even if many words stand in between, because the connection is made directly through attention rather than through a long trail of hidden states. This is one of the biggest reasons attention replaced RNNs in modern sequence modeling.
Speed was another decisive factor. RNNs are naturally sequential, which makes it hard to process many tokens at the same time during training. Attention, by contrast, works in parallel, so the model can examine many relationships at once instead of marching through them one by one. That parallelism mattered enormously once machine learning systems started growing larger and training on bigger datasets. When people say transformers train faster than older recurrent neural networks, this is what they mean: the architecture lets the hardware do more useful work simultaneously. In practice, that made attention not just elegant, but also far more efficient.
There was also a representational advantage that mattered just as much. An RNN has to squeeze a whole history into a single evolving state, like trying to summarize a novel in one sentence and keep updating it as you read. Attention does not force that kind of bottleneck, because it can draw from many parts of the sequence as needed. This helps the model preserve nuance, compare distant words, and resolve ambiguity with more flexibility. In other words, transformers did not merely replace RNNs because they were newer; they replaced them because attention gave them a better way to remember, compare, and combine information.
That shift is why the transformer became such a turning point in AI. Once attention proved it could handle long-distance relationships and scale efficiently, researchers no longer had to accept the trade-off that came with recurrent neural networks. They could build models that were faster to train, better at capturing context, and easier to scale to large language tasks. So when you see attention in a transformer, think of it as the moment the model stops reading with tunnel vision and starts reading with the full page in view. From here, the next question is natural: once attention became the center of the design, how do its internal calculations decide what each token should focus on?
Self-Attention Explained (arxiv.org)
Building on that foundation, self-attention is the part of a transformer that lets every token look around the whole sentence and decide what matters most. Instead of carrying a single memory forward step by step, the model gives each token a query, a key, and a value: the query asks a question, the key acts like a label, and the value holds the information to pull through. So when you ask, “How does the model know what this word relates to?”, the answer is that it compares one token’s query against every other token’s key, then uses those matches to build a new representation for that token.
The actual math is surprisingly tidy once you see the shape of it. In scaled dot-product attention, the model takes the dot products between a query and all keys, divides by the square root of the key dimension, and passes the results through a softmax function, which turns the scores into weights that add up to one. Then it forms a weighted sum of the values, like mixing several paint colors but giving more paint to the shades that fit the scene best. The scaling step matters because it keeps large dot products from making the softmax too sharp, which helps training stay stable.
This is where self-attention starts to feel powerful in practice. If a sentence says something like “The animal crossed the road because it was hungry,” the token “it” does not have to wait for a long chain of hidden states to remember what it refers to; it can attend directly to the earlier noun that best explains it. In the encoder, each position can attend to all positions in the previous layer, so the model can gather context from anywhere in the sequence instead of depending on nearby words alone. That direct access is one reason transformer models handle long-range relationships so well.
Of course, the model does not rely on a single spotlight. It uses multi-head attention, which means several attention operations run in parallel, each with its own learned projections of the queries, keys, and values. Think of it like a team of readers studying the same paragraph at once: one head may focus on grammar, another on meaning, and another on a distant dependency that would be easy to miss otherwise. The paper notes that this helps the model attend to different representation subspaces at different positions, while a single head can blur too much information together.
There is one subtle problem, though: attention by itself does not know word order. That is why the transformer adds positional encodings to the input embeddings at the bottom of the encoder and decoder stacks, giving the model a signal about where each token sits in the sequence. In the decoder, masking blocks later positions from seeing future tokens, which preserves the auto-regressive nature of generation, meaning the model predicts one token at a time using only what came before. This is the quiet rule that keeps the model from peeking ahead while it is writing.
Once you put those pieces together, the larger story becomes clear. Self-attention shortens the path between two distant words, so the model can learn long-range dependencies with fewer sequential steps than an RNN, or recurrent neural network, which must process tokens one after another. That also makes the transformer more parallelizable, because many attention calculations can happen at once during training. In the original paper, this design helped the transformer achieve strong translation results while training faster than earlier sequence models, and that speed was not a side effect; it was part of the breakthrough.
Positional Encoding Basics (arxiv.org)
Building on this foundation, the next problem feels small at first but turns out to be crucial: how does a transformer know which word came first? Self-attention lets tokens talk to one another, but attention on its own does not carry a built-in sense of order. If you shuffled a sentence like cards on a table, the model would see the same pile of words unless we gave it an extra clue. Positional encoding is that clue, and it is one of the quiet ideas that makes transformer models work at all.
To see why this matters, picture a sentence as a line of people standing in order. The word embeddings, which are numeric vectors that represent the meaning of each word, tell the model who each person is. Positional encodings tell the model where each person is standing. In practice, the transformer adds the positional encoding to the word embedding at the input, so every token arrives with both identity and location mixed together. That small addition gives the model the missing sense of sequence without forcing it to process words one at a time.
So how do positional encodings work in practice? The original transformer paper used sinusoidal positional encoding, which sounds technical but follows a simple idea: each position gets a pattern made from sine and cosine waves of different lengths. Think of it like a musical chord made from several notes at once. One note changes quickly, another changes slowly, and together they create a distinct fingerprint for each position in the sentence. Because nearby positions have related patterns, the model can learn not only absolute position, but also clues about distance between tokens.
This choice was clever for a reason. A fixed sinusoidal pattern is not just a label for “first,” “second,” or “third”; it gives the model a smooth numeric structure it can use to compare positions. That means the model can more easily notice that two words are close together, far apart, or in a certain order. In a phrase like “the cat sat on the mat,” those positions help the transformer keep “cat” near “sat” and not confuse the relationship with a later word. Without positional encoding, attention would know which words are related, but not how they are arranged in the sentence.
The beauty of this approach is that it stays lightweight. Instead of adding a separate order-tracking machine, the transformer folds position into the same vectors it already uses for meaning. You can think of it like writing a seat number on each ticket before everyone enters the theater: the ticket still identifies the person, but now the usher also knows where they belong. That blend of content and position is what lets the model read language as both a collection of ideas and an ordered sequence. What causes the words to feel like a sentence instead of a bag of tokens? Positional encoding answers that question.
There is also a subtle payoff that becomes clearer once you start thinking about long sequences. Because sinusoidal positional encoding follows a mathematical pattern rather than a learned list of labels, the model can extend the same logic to positions it did not see during training. In other words, the signal is not just a lookup table for a fixed sentence length; it is a reusable pattern that continues outward. That makes the transformer more flexible when it encounters longer inputs, which is especially useful in real-world language tasks where the length of text can vary a lot.
Once you understand positional encoding, the transformer becomes easier to picture as a whole. Attention decides what each token should look at, and positional encoding tells the model where each token belongs in the sequence. Together, they let the transformer read with both meaning and order in mind, which is exactly the balance language needs. From here, we can move naturally into the encoder stack and see how these position-aware token representations get transformed layer by layer.
Encoder and Decoder Layers (arxiv.org)
Building on this foundation, the encoder and decoder layers are where the transformer starts to feel like a working machine rather than a clever idea. Think of the encoder as the part that reads the full input and turns it into a rich internal summary, while the decoder uses that summary to write the output one token at a time. How do the transformer encoder and decoder layers share the workload without the old step-by-step bottleneck? The paper’s answer is a stacked design: repeated layers that process information in parallel, with attention handling the relationships and small feed-forward blocks refining each position.
The encoder layer is the simpler of the two, and that simplicity is part of its strength. Each encoder layer contains two sub-layers: multi-head self-attention, where every token can look at every other token in the same sequence, and a position-wise feed-forward network, which is a small fully connected network applied separately to each position. Around each sub-layer sits a residual connection, which is a shortcut path that adds the original input back in, followed by layer normalization, a stabilization step that keeps training smooth. In other words, the encoder layer first gathers context, then refines it, then passes it forward without losing the original signal.
That design matters because the encoder is not trying to predict anything yet; it is building a memory of the input. Each layer takes the previous layer’s output and lets every position update itself using the whole sentence as context. The paper also keeps the output dimension the same across sub-layers and embeddings so those residual connections fit cleanly, like matching puzzle pieces that snap together without friction. If you have wondered why the transformer encoder feels so good at understanding long text, this is a big reason: every layer keeps the full sequence in view while gradually sharpening the representation.
The decoder layer adds one more piece to the story, because writing is harder than reading. It contains the same self-attention and feed-forward sub-layers as the encoder, but it inserts a third sub-layer in between: multi-head attention over the encoder’s output. This is called encoder-decoder attention, and it lets the decoder ask, “Which parts of the input matter right now?” The queries come from the decoder, while the keys and values come from the encoder output, so the decoder can pull in the source-side context it needs for the next word.
There is one crucial guardrail in the decoder: masking. During training and generation, the decoder must not peek at future tokens, because that would be like reading the answer key while solving the puzzle. The transformer blocks those future positions inside self-attention, so each position can attend only to earlier positions and itself. Combined with the fact that output embeddings are shifted by one position, this makes the model auto-regressive, meaning it predicts one token at a time using only what it has already produced. That is the quiet rule that keeps transformer decoder layers honest.
When you put the encoder and decoder together, you can see the architecture as a conversation between memory and generation. The encoder listens first and builds a compact, context-rich representation of the input, while the decoder consults that representation while carefully stepping forward one token at a time. The feed-forward network in each layer then acts like a private workshop for each position, shaping the features after attention has gathered the relevant clues. This balance of shared context, local refinement, and careful masking is what gives the transformer encoder and decoder their practical power.
Transformer Uses in AI (research.google)
If you have watched a translation tool, a writing assistant, or a question-answering system work, you have already seen transformer uses in AI at the surface. The reason the architecture spread so quickly is that it handles context as a whole scene rather than one word at a time. Google introduced the Transformer for language understanding and showed that it beat older recurrent and convolutional systems on translation, while also pointing toward question answering and even future work with images and video.
The most immediate home for the model was machine translation, which means automatically converting text from one language into another. Translation is like carrying a thought across a bridge: you cannot move one word at a time and ignore what came before or after. The original paper reported stronger English-German and English-French results, and it also showed that the model trained much faster because it was far more parallelizable than recurrent networks. That is why transformer uses in AI first gained attention in systems that rewrite text from one language into another.
But translation was only the opening act. The same architecture also helps with language understanding tasks such as question answering, coreference resolution, and constituency parsing, where the model needs to decide what a word refers to or how a sentence is structured. Google’s release showed the Transformer handling a classic “it” example and performing well on parsing with little adaptation. In practice, that means the model can read a sentence like a careful editor, not just a fast typist.
Taking this concept further, transformers also became a strong fit for generation tasks, where the model must write one token after another while still staying anchored to the input. Google later noted that transformer architectures had been applied to generating fantasy fiction and writing musical harmonies, which is a nice reminder that the idea is not limited to textbook natural language processing. Those examples show how transformer uses in AI can move from understanding text to creating new sequences with the same underlying machinery.
The reach keeps widening because the core trick is general: represent relationships, then let the model learn which ones matter. The original Google post said the team was already applying the Transformer to images and video, which tells us the architecture was never meant to be a language-only tool. Once you see that pattern, the use cases feel less random: wherever a system needs to compare parts of a large input, transformers can help. That broader flexibility is one reason transformer uses in AI keep spreading into multimodal systems.
So when someone asks, “What are transformer uses in AI?”, the clearest answer is that they are context engines. They power translation, support language understanding, and provide a flexible backbone for generation and emerging multimodal work because they can process relationships directly and train efficiently on modern hardware. That combination of accuracy, speed, and adaptability is what turned the architecture from a research idea into a standard building block, and it sets us up to ask how pretraining gives these models their real-world strength.