Database Types at a Glance
When you first hear people compare SQL, NoSQL, and NewSQL, it can feel like you’ve walked into a hardware store and been handed three very different toolboxes. That feeling is normal. Each database type solves a different kind of problem, and the fastest way to understand them is to picture the kind of work they’re built to do. If you’ve ever wondered, which database type should I use for my app?, this is the moment where the map starts to come into focus.
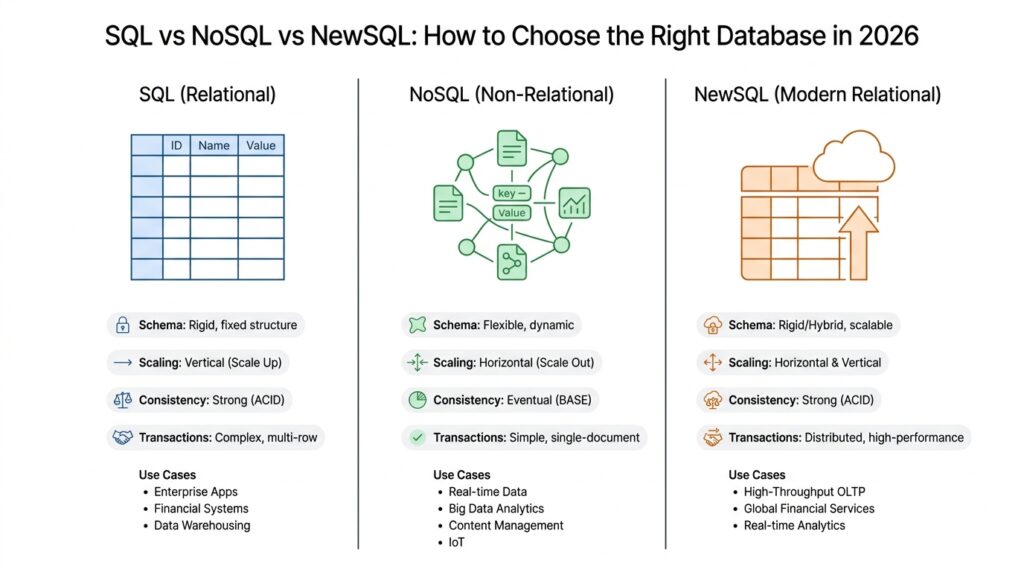
SQL databases are the familiar, carefully organized shelves in that store. SQL stands for Structured Query Language, the standard language used to ask for, store, and update data in relational databases, which keep information in tables with rows and columns. That structure makes SQL databases a strong fit when your data has clear relationships, like customers, orders, and payments that need to line up neatly. They shine when you want strong consistency, meaning the data stays accurate and synchronized across the system.
Now we step into the next aisle, where NoSQL databases live. NoSQL means not only SQL, and that name matters because it covers several database styles that don’t rely on rigid tables in the same way. Think of NoSQL as a set of flexible containers: one might store documents, another key-value pairs, another graphs, and another wide columns. This flexibility makes NoSQL useful when your data changes shape often, when you need to move fast, or when you’re dealing with huge volumes of information that don’t fit a tidy table very well.
So what does that look like in real life? Imagine building a shopping app. If every product, order, and invoice needs careful relationships and dependable transactions, SQL databases are usually the comfortable choice. If you’re storing user activity logs, social media posts, or profiles with many optional fields, NoSQL databases can feel far less restrictive. In other words, SQL gives you structure, NoSQL gives you freedom, and the right answer depends on how your data behaves day to day.
Then there is NewSQL, the newer name in the room. NewSQL databases aim to keep the classic strengths of SQL—structured data, familiar querying, and transactions—while also offering the scaling behavior people often associate with NoSQL. A transaction is a group of database steps treated as one unit, so either all of them succeed or none of them do. That matters when you cannot afford half-finished updates, such as in banking, bookings, or inventory systems. NewSQL tries to give teams both order and reach, which is why it often appears in systems that need strong correctness without giving up growth.
The easiest way to remember the difference is to ask what kind of tradeoff you are making. SQL databases favor structure and reliability. NoSQL databases favor flexibility and horizontal scaling, which means spreading work across many servers. NewSQL tries to keep SQL’s structure while borrowing scaling ideas from modern distributed systems, where data is stored and processed across multiple machines that work together. That makes NewSQL especially interesting when a product has outgrown a single traditional database but still needs precise, transaction-safe behavior.
At this stage, you do not need to memorize every engine or vendor name. What matters is the bigger pattern: SQL, NoSQL, and NewSQL are less like rivals and more like different answers to different kinds of pressure. When we choose among them, we are really asking how much structure the data needs, how much flexibility the application demands, and how much scale the system must handle. With that picture in mind, we can move from broad labels to the practical question that matters most: which one fits your workload best?
Match Data Model First
Before you compare features, start with the shape of the information itself. That is the heart of database choice: the data model is the way your application naturally organizes facts, like a map of what exists, how pieces connect, and how often those pieces change. If you begin there, SQL, NoSQL, and NewSQL stop feeling like abstract labels and start looking like answers to a very practical question: what database is best for my data model? When we match the database to the shape of the data first, the rest of the decision becomes much clearer.
Think of a product catalog, an invoice system, or a payroll app. These usually have predictable records and strong relationships, so a relational model, the table-based structure used by SQL databases, often fits like a tailored jacket. The data has names, IDs, amounts, dates, and links that need to line up cleanly, and that regularity is exactly what SQL likes. When your information behaves this way, forcing it into a looser structure can create more confusion than freedom.
Now picture user profiles, app events, chat messages, or content feeds. These often arrive with uneven fields, changing shapes, or extra details that only appear sometimes, which is where NoSQL starts to make sense. A document model, one common NoSQL approach, stores related fields together in a flexible record, a bit like a folder that can hold different kinds of papers instead of one strict form. If your product keeps evolving and you do not want every small change to require a database redesign, that flexibility can be a real relief.
The next clue is not only what the data looks like, but how it moves. Some systems read one record at a time, some pull large groups of related items, and some constantly write new events as they happen. A graph model, for example, works well when relationships themselves are the main story, such as social connections or recommendation paths, while an event-driven model suits systems that record every action in order. In practice, the best database choice follows the pattern of your queries as much as the pattern of your storage.
This is also where NewSQL earns its place in the conversation. If your data model is relational but your traffic is growing past what a traditional single-node system can comfortably handle, NewSQL can preserve familiar table structure while supporting broader scale. That matters for applications like reservations, payments, or inventory, where you still want clean relationships and transaction safety, but you also need the system to grow without losing its footing. In other words, NewSQL often steps in when the data still wants order, but the workload wants reach.
So the early decision is not “Which database sounds modern?” It is “What shape does my data take, and what does my application ask of it every day?” If your world is tidy and highly connected, SQL usually feels natural. If your world is varied and fast-changing, NoSQL often fits better. If your world needs both structure and scale, NewSQL may be the bridge. Once you answer that question honestly, the database selection process becomes less like guessing and more like matching the right container to the thing you are carrying.
Compare Transactions and Consistency
When your app starts handling money, bookings, inventory, or any other update that must not drift out of sync, transactions and consistency stop feeling abstract and start feeling like safety rails. In SQL databases, a transaction is a group of database steps treated as one unit, so either the whole set finishes or nothing does, and PostgreSQL’s transaction rules show how a query sees only committed data rather than half-finished work from other sessions. That is why SQL vs NoSQL vs NewSQL often comes down to how much certainty you need every time you write or read data.
The next scene looks different in NoSQL. Instead of one fixed promise, many NoSQL systems let you choose how fresh the data must be before the database hands it back, and that flexibility is the big clue. Amazon DynamoDB, for example, uses eventually consistent reads by default, while strongly consistent reads are optional on tables and local secondary indexes; MongoDB, meanwhile, lets you tune read concern, which is the setting that controls how strictly the database checks freshness before returning data. MongoDB also keeps single-document operations atomic, which means one document update succeeds as a whole or not at all.
That difference matters because consistency is not one thing; it is a spectrum of promises. If your shopping cart count lags for a moment, eventual consistency may be perfectly acceptable, because the user can refresh and move on. If you are moving money or assigning the last seat on a flight, a stale read can create a real problem, so you need stronger guarantees and, often, broader transaction support across more than one record. The practical question is not whether NoSQL can support transactions, but whether its default behavior matches the kind of mistake your application can tolerate.
This is where NewSQL steps into the story. NewSQL databases try to keep the familiar SQL model while scaling like a distributed system, and CockroachDB is a clear example because it offers serializable isolation by default, which is the strongest standard SQL isolation level and stronger than snapshot isolation. In plain language, serializable isolation aims to make concurrent transactions behave as if they happened one at a time, which is exactly the kind of predictability you want when consistency has to survive growth across many machines.
So the comparison looks like this in practice: SQL databases usually give you the most straightforward transaction story, NoSQL databases usually give you the most room to tune freshness and availability, and NewSQL tries to keep SQL’s correctness while spreading the workload across more infrastructure. That is why two systems can both be “good” and still feel completely different under pressure. If you need a database that protects every step of a multi-row update, SQL or NewSQL is often the calmer path; if you need to move fast with changing data and can accept a looser consistency model, NoSQL can be the better fit.
When you compare transactions and consistency, the question becomes wonderfully concrete: what is the cost of being wrong? If a brief mismatch is harmless, you can live with a softer consistency model and keep the system flexible. If a mismatch would break trust, money, or inventory, you want the tighter guarantees that SQL or NewSQL is built to provide. With that lens in place, we can now look at how these choices affect speed, scale, and day-to-day operations.
Assess Scale and Latency
When your app is still tiny, scale and latency can feel like plumbing you hope never to think about. Then traffic arrives, users open the app from farther away, and every extra hop starts to matter. Scale is the amount of load and data a database can absorb before it slows down; latency is the waiting time between the moment a request leaves your app and the moment a response comes back. If you are comparing SQL vs NoSQL vs NewSQL, this is where the debate becomes practical: how much growth do you expect, and how much delay can your users tolerate?
A helpful way to picture scale is vertical versus horizontal. Vertical scaling means giving one server more CPU, memory, or storage, while horizontal scaling means spreading the work across more machines. MongoDB’s docs describe both approaches and note that sharding is its built-in horizontal scaling path, designed for very large data sets and high-throughput workloads. In a relational world, PostgreSQL gives you table partitioning and read-only standby connections, which help a SQL system stretch without changing its basic shape.
Latency is where the story gets more personal, because users do not experience your database as a diagram; they experience it as a pause. Network distance, cross-region routing, and extra coordination between nodes all add time, and CockroachDB explicitly notes that cross-region queries increase latency because of geography. AWS also separates service-side request latency from client-side and network time in DynamoDB metrics, which is a useful reminder that the database was slow complaint often has more than one cause. When people ask why a database feels fast in testing but slow in production, this is usually the hidden reason.
This is why SQL and NoSQL often feel different under pressure. NoSQL systems such as MongoDB are built to spread data and load across shards, and MongoDB says that sharding helps large deployments handle huge data sets and high throughput. That can reduce the chance that one server becomes the choke point, especially when your traffic keeps growing or your write load spikes. The tradeoff is that you now care more about shard keys, routing, and how evenly your data lands across the cluster.
SQL systems can still scale well, but they usually ask you to be more deliberate about where the bottleneck lives. You might partition tables, add replicas, or tune indexes so hot queries stay close to the data they need. NewSQL sits between the two camps: CockroachDB describes itself as distributed SQL and says it aims to deliver predictable throughput and latency at all scales, with benchmark results that hold p50 and p99 latency steady as nodes are added. It is the option that makes sense when you want the SQL model and the comfort of transactions, but your workload no longer fits neatly on one machine.
The safest way to assess scale and latency is to trace one real request from start to finish. Count how many rows it touches, how many writes it triggers, where the data lives, and whether the user is reading nearby data or crossing regions. Then ask what happens at 10x traffic, because averages can hide painful tail latency, the slower slice of requests that users remember most. Once you can name your busiest path and your worst delay, SQL vs NoSQL vs NewSQL stops being a branding question and becomes a workload question.
Map Workloads to Strengths
Once we stop treating SQL vs NoSQL vs NewSQL like competing slogans and start treating them like workhorses, the choice gets much clearer. A relational database keeps data in rows and columns, while MongoDB’s document model can keep related fields together in a flexible schema, and CockroachDB is built as a distributed SQL database for global, scalable workloads. That means the real question is not “Which one is best?” but “Which one matches the pressure my app feels every day?”
If your workload is built around clean relationships, SQL usually feels like home. A product catalog, invoicing system, payroll app, or order tracker often needs many records to line up in predictable ways, and SQL databases are designed around tables, joins, and ACID properties, which means atomic, consistent, isolated, and durable transactions. In plain language, that gives you a sturdy place to manage updates that must stay correct when several tables depend on one another.
If your data changes shape often, NoSQL starts to look less like a compromise and more like a relief. MongoDB’s docs describe a flexible schema where documents in the same collection do not need identical fields, which fits user profiles, event streams, chat messages, and content feeds that evolve over time. MongoDB also notes that single-document writes are atomic and that sharding spreads data and workload across multiple machines for very large datasets and high-throughput operations, so the model fits teams that value flexibility and horizontal scale. What database fits a customer profile service that keeps gaining new fields every month? That question often points straight toward NoSQL.
If your workload still wants relational structure but has outgrown a traditional single-node setup, NewSQL is the bridge worth paying attention to. CockroachDB describes itself as distributed SQL built for global OLTP, short for online transaction processing, while still maintaining strong consistency and a standard SQL interface; its docs also say transactions span arbitrary tables and rows with serializable isolation by default. In practice, that makes NewSQL attractive for reservations, payments, and inventory systems where you need familiar SQL behavior and distributed scale without giving up correctness.
The easiest way to map workloads to strengths is to follow the dominant risk, not the loudest trend. If the biggest risk is bad joins or messy relationships, SQL is usually the calmest fit. If the biggest risk is rigid structure slowing down fast-changing data, NoSQL gives you more breathing room. And if the biggest risk is outgrowing a traditional relational database while still needing strong transactions, NewSQL becomes the practical middle path. When you frame SQL vs NoSQL vs NewSQL around the shape of the workload, the answer stops feeling mysterious and starts feeling obvious in the best possible way.
Factor Cost and Operations
When you reach the cost and operations stage, the database decision gets less about elegance and more about what your team can carry month after month. If you are asking, “How much does a SQL database cost to run once traffic grows?”, you are really asking two questions at once: what do we pay the vendor, and what do we pay in time, attention, and sleepless nights? PostgreSQL is released under a free and open source license, which removes software licensing fees from the equation, but the day-to-day work of backups, replication, and recovery still has to be handled by someone.
That distinction matters because a low sticker price can hide a busy operations story. With PostgreSQL, backups are typically handled through tools like pg_dump, which backs up a single database, while cluster-wide backups require additional steps such as pg_dumpall; replication also introduces the idea of primary and standby servers. In plain language, SQL can be affordable on software cost, but the operational bill often shows up as engineering time, monitoring, and careful planning. That is one reason SQL vs NoSQL vs NewSQL is never only a technical comparison; it is also a staffing comparison.
NoSQL often looks appealing when you want the database service to absorb more of that operational burden. Amazon DynamoDB, for example, offers on-demand pricing with automatic scaling, so you do not have to forecast capacity in advance, and it charges for reads, writes, storage, and optional features instead of a fixed server size. MongoDB Atlas shows a similar pattern: billing is broken into services such as clusters, backup, and data transfer, which makes the invoice feel more like a usage report than a flat rent payment. The upside is convenience; the tradeoff is that convenience becomes part of the price.
That is also where the hidden operational costs begin to surface. MongoDB Atlas charges per data-bearing node, and if you enable sharding, it adds three config servers on top of the data nodes, which means horizontal scale is not just a design choice but a real line item. MongoDB’s sharding docs also explain that shards spread data across multiple servers for horizontal scaling, so the system becomes easier to grow but more complex to provision, balance, and observe. In other words, NoSQL can reduce schema friction, but it can increase cluster-management work as the system gets larger.
NewSQL usually enters the conversation when you want the cleaner operational story of SQL but with distributed scale that behaves more like NoSQL. CockroachDB describes itself as distributed SQL, and its cloud pricing includes dedicated resources, storage, and cross-region data transfer, which tells you something important: distributed correctness is not free, especially when data moves between regions. That extra geography can also add latency, so the operational cost is not only in dollars but in the extra coordination your users feel.
The practical lesson is that cost and operations travel together. A system that saves you schema redesign may ask you to pay for sharding, backup tiers, or data transfer; a system that gives you free software may ask your team to own failover, patching, and recovery. That is why managed services matter so much in SQL vs NoSQL vs NewSQL choices: they trade some control for fewer moving parts, and fewer moving parts often means fewer midnight surprises. The trick is to notice whether your biggest expense is infrastructure, labor, or the cost of being wrong during an outage.
A good rule of thumb is to choose the database that makes your operating model boring in the right places. If your team is small and wants predictable administration, a managed SQL or managed NoSQL service can be worth more than the raw storage bill. If your workload spans regions or demands continuous scale, NewSQL may justify its added infrastructure cost by reducing the amount of custom engineering you have to build around it. And if you are still unsure, follow the money and the on-call load together, because the cheaper database on paper is not always the cheaper one to live with.



