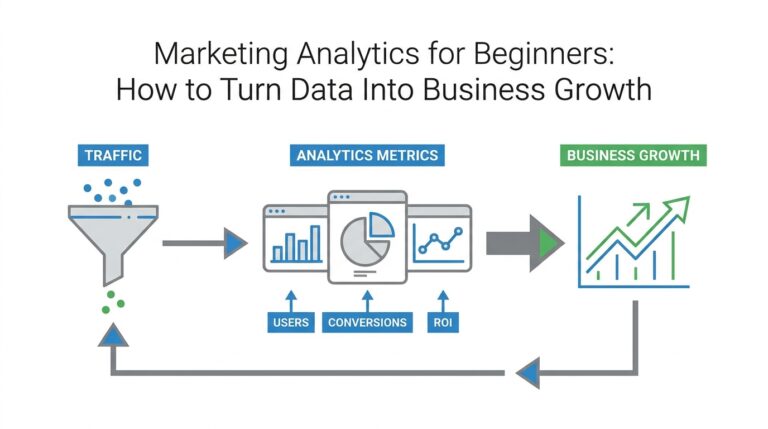
What Problem Attention Solves
Imagine trying to remember a long conversation after hearing only the last few words. That is the pressure older language models faced: they had to squeeze an entire input into one compact summary and hope nothing important disappeared along the way. The problem attention solves is that this summary often becomes a bottleneck, especially in tasks like translation, where one small detail near the start can change the meaning of a word near the end. In the early attention work, researchers showed that letting the model softly search the source sentence for the most relevant pieces was better than forcing everything through a single fixed-length vector.
Why do large language models need attention in the first place? Because long text is full of dependencies that do not stay neatly next to each other. A name may appear in the opening line, and the pronoun that refers to it may arrive many words later, after the model has already passed through a lot of other information. The attention mechanism gives the model a way to look back across the whole context and decide which tokens deserve more focus right now, instead of treating every earlier word as equally important. That shift is what makes attention feel less like a memory dump and more like a guided search.
The Transformer paper pushed this idea much further by building a network based solely on attention mechanisms, without recurrence or convolutions. That may sound like a small design choice, but it changed the workflow in a big way: the model no longer had to march through tokens one by one the way a reader follows a line of text from left to right. Instead, it could process relationships more directly, which made the system more parallelizable and reduced training time while improving translation quality. In other words, attention solved both a language problem and an engineering problem at the same time.
A good way to feel the benefit is to think about an ambiguous sentence like, “The trophy didn’t fit in the suitcase because it was too small.” When the model reaches the word “it,” it has to decide what “it” refers to, and that choice depends on earlier words. Attention helps by building a temporary spotlight around the useful parts of the sentence, so the model can lean toward the suitcase instead of the trophy. This is one of the core ways attention mechanisms help large language models: they preserve relationships, not just word order, which makes the model better at handling meaning over distance.
So the real problem attention solves is not “How do we read text?” but “How do we keep the right parts of a long context alive long enough to use them?” Once we see it that way, attention starts to look less like a fancy add-on and more like the part that lets the whole machine remember what matters. That is why attention mechanisms became so central to large language models: they help the model carry important clues forward, even when those clues were introduced pages earlier.
How Self-Attention Works
Imagine you are reading a sentence and one word suddenly feels slippery, like it in “the suitcase was too small.” Self-attention is the transformer’s way of pausing and asking every word to look around the whole sentence for clues. If you’re wondering, how does self-attention work in a transformer? the short answer is that each token builds a little spotlight, decides what matters nearby or far away, and then rewrites itself using that context. That is what lets large language models keep relationships alive instead of treating every word as isolated.
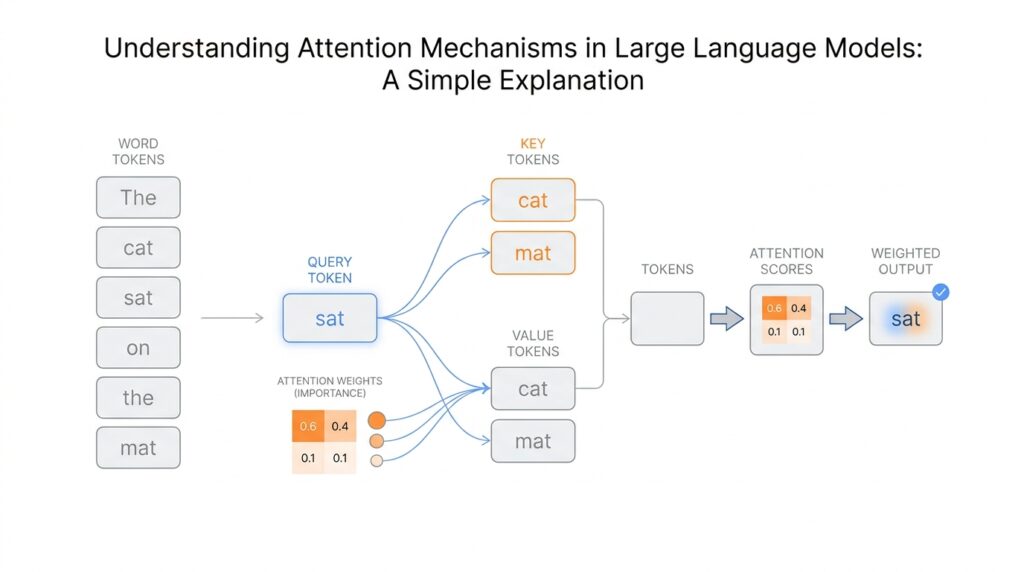
The first move is to give each token three different jobs: a query (what this token is looking for), a key (how other tokens advertise what they contain), and a value (the actual information to pass along). Self-attention works by comparing a token’s query with every other token’s key, so the model can estimate which words deserve attention right now. You can think of it like a room full of name tags and notes: the query asks, “Who here matches my need?” and the matching keys help point to the right values.
Once those comparisons happen, the model turns them into scores with scaled dot-product attention. A dot product is a simple way of measuring how well two vectors line up, and the transformer divides by the square root of the key size, then runs the result through softmax, a function that turns scores into weights that add up to 1. That means the model does not pick one word in a hard, brittle way; it gives several words different amounts of influence, then forms a weighted sum of their values. In the transformer paper, this is written as Attention(Q, K, V) = softmax(QK^T / sqrt(d_k))V, and that one line is the heart of self-attention.
The beautiful part is that every token gets its own updated representation at the same time. Instead of reading left to right like a chain, the model can compute attention for all positions in parallel, which is one reason transformers train efficiently on modern hardware. The paper also notes that self-attention connects all positions with only a constant number of sequential steps, while recurrent layers have to march through the sequence one step at a time. So self-attention is not only a language trick; it is also an engineering shortcut that makes long-context processing much more practical.
A single attention head can catch one kind of relationship, but several heads can catch several at once. That is what multi-head attention means: the model creates multiple versions of the same sentence, lets each one search in its own way, and then combines the results. The original paper says this helps the model attend to information from different representation subspaces at different positions, which is a formal way of saying that one head might track grammar while another tracks meaning or reference. In practice, this is why self-attention feels so flexible: it is not one spotlight, but a whole crew of them working together.
There is one more detail that keeps the whole system honest: order still matters. Because self-attention alone does not know which word came first, transformer models add positional encodings—extra signals that tell the network where each token sits in the sequence. In the decoder, the model also uses masking, which means it blocks future tokens so the prediction at position i cannot peek at position i + 1 or beyond. That is how self-attention stays useful for prediction: it can look widely, but only in the directions the task allows.
Query, Key, and Value
Now that we’ve seen self-attention at work, the next question is the one that makes the whole mechanism feel alive: what are these query, key, and value pieces actually doing? In a transformer, each token gets turned into three different vectors, which are just lists of numbers that carry different roles. One vector asks a question, one vector advertises what a token offers, and one vector holds the information the model may pass along. That split is the quiet trick behind attention mechanisms in large language models, because it lets the model search for meaning instead of staring at raw words.
A useful way to picture it is a library desk. The query is the note you bring to the librarian, the key is the label on each drawer, and the value is the book inside. The query says what you are looking for, the key says what kind of match a token represents, and the value carries the content you might want to use. When people ask, “What are query, key, and value in attention?” this is the simplest answer: they are three roles that help the transformer decide which words should influence the current one.
The neat part is that query and key do not have to match by exact wording; they match by learned similarity. The model converts each token into these vectors through learned linear layers, which are small trainable transformations that reshape information into the form attention needs. Then the query from one token is compared with the keys from all the others, and stronger matches get higher scores. This is why attention feels selective rather than blunt: the model is not averaging everything equally, but looking for the most relevant clues.
Once those scores are computed, the model uses them to blend the values. Here is where the value vector earns its name: it is the part that actually gets gathered up and combined into the new representation. If a key says, “I might be useful,” the value says, “Here is the information you can take from me.” That means query, key, and value work like a conversation among tokens, with the query asking, the key pointing, and the value answering. The result is a fresh version of the token that now carries context from the words that mattered most.
This is also why the three roles matter so much in self-attention. The same token can act as a query, a key, and a value at the same time, but in three different spaces. That separation gives the transformer room to learn patterns that are hard to capture with one shared representation alone. In practice, it helps the model notice that a pronoun depends on a noun, that a verb depends on its subject, or that one phrase should outweigh another because the sentence is leaning in that direction.
You can think of it like listening to a busy room and choosing which voices to follow. The query is your current question, the keys are the names on the people you are scanning, and the values are the stories they can tell. If you follow only one voice, you may miss the bigger picture; if you follow everyone equally, the room turns into noise. Query, key, and value give the transformer a middle path, which is why attention mechanisms can be both broad and precise at the same time.
And that is the heart of it: query, key, and value are not three separate mysteries, but three coordinated jobs inside the transformer. They let attention mechanisms compare, choose, and combine information in a way that feels almost conversational. Once we understand that flow, the math stops looking like a wall of symbols and starts looking like a very practical way to help a model decide what matters right now.
Why Positional Encoding Matters
Now that we have query, key, and value on the table, one quiet problem remains: self-attention does not know order by itself. It can tell which tokens relate to each other, but not which one came first unless we give it that clue. If you’re asking, “Why do transformer models need positional encoding?” the answer is that meaning often depends on sequence, and sequence is exactly what attention would otherwise blur.
Think about the sentence as a line of train cars. The words are the cars, but if we only look at the contents of each car, we still do not know where each one sits in the train. A transformer reads tokens more like a set of cards than a string of beads, so without extra help, “dog bites man” and “man bites dog” can look uncomfortably similar. Positional encoding is the extra tag that says, “This word came first, this one came second, and this one came after that.”
That matters because language is full of patterns that live in order, not just in vocabulary. A negation word like “not” can flip a sentence’s meaning, a modifier can attach to the wrong noun if the model loses track of placement, and a pronoun can point backward to the right person only if the model knows where the pieces sit. Positional encoding in transformers gives the model a sense of structure, almost like lane markers on a road, so the model can tell distance and direction, not only nearby neighbors.
Here is the deeper reason it belongs in the system: attention answers the question, “Which words matter to each other?” but positional information answers, “In what arrangement do they matter?” Those are related questions, yet they are not the same. A model might notice that “small” relates to “suitcase,” but it still needs position to understand whether “small” describes the suitcase or something else in the sentence. This is why positional encoding is not decoration; it is part of the grammar the model can actually use.
The original transformer added positional encoding by mixing a position signal into each token representation before attention begins. You can think of that signal as a faint coordinate system layered under the words themselves. Some models use fixed patterns, while others learn the positions during training, but the goal stays the same: give every token a location in the sequence. Once those locations are available, self-attention can keep its flexible search behavior without losing the order that language depends on.
This is also where the idea becomes especially practical for large language models. When a model generates text, it has to remember not only what has appeared, but where it appeared in relation to everything else. Positional encoding helps the transformer preserve sentence flow, paragraph flow, and even the rhythm of long prompts. Without that sense of placement, attention mechanisms would still be useful, but they would feel like a brilliant reader with no sense of page order.
And there is one more subtle benefit: positional information helps the model compare relative distance. Two words that are close together often interact differently from two words that are far apart, and that difference can change the model’s guess about meaning. So when we talk about attention mechanisms in large language models, positional encoding is the piece that keeps the whole system grounded in sequence. It lets attention look widely while still remembering the path that brought it there, which is why the model can follow both meaning and order at the same time.
Understanding Multi-Head Attention
Once you already understand how attention helps a model look back across a sentence, multi-head attention feels like the moment we hand it several pairs of glasses instead of one. What does multi-head attention do in a transformer? It takes the same query, key, and value information, sends each through different learned projections, runs attention in parallel, and then joins the results back together. In the original Transformer paper, this appears as several attention layers running side by side, with the smaller size of each head helping keep the total cost close to a single wider attention pass.
A helpful way to picture a head is as one focused viewpoint, not a separate mind. Each head gets its own learned projection, which means it can look at the same sentence through a slightly different lens and notice different patterns. The paper describes this as attending to information from different representation subspaces at different positions, which is a formal way of saying that one head does not have to care about the exact same clues as another. That is why multi-head attention matters: it gives the model room to look at the same moment from several angles at once.
The mechanics are tidy once we slow them down. First, the model linearly projects the queries, keys, and values into smaller spaces, one set for each head. Then each head performs scaled dot-product attention on its own projected version, producing a separate output; after that, the outputs are concatenated and projected one more time to form the final result. If that sounds like a relay race, that is the right instinct: one head gathers one kind of evidence, the next head gathers another, and the last projection blends everything into a single representation the rest of the network can use.
So why not use one big attention map and be done with it? The issue is that a single head can blur things together when one relationship matters here and another matters somewhere else. Multi-head attention reduces that blur by letting different heads specialize in different patterns, even when those patterns overlap in the same sentence. The paper also notes that because each head works in a reduced dimension, the total computational cost stays similar to single-head attention, which is a neat trade: more views, but not a much heavier bill.
This design shows up in three places inside the Transformer, and each one serves a slightly different story beat. In encoder self-attention, the heads look across the input sequence together; in decoder self-attention, they do the same thing but with masking so the model cannot peek ahead; and in encoder-decoder attention, the decoder’s queries look back at the encoder’s output. In other words, multi-head attention is not a one-off trick tucked into a corner of the architecture. It is the shared mechanism that lets the model compare, gather, and route information wherever sequence relationships matter most.
If we keep the metaphor alive, multi-head attention is less like one bright spotlight and more like a small team of readers, each scanning the page for a different clue. One head may give weight to a nearby modifier, another may follow a distant reference, and a third may help the model preserve the overall shape of the sentence. The important idea is not that every head learns a human-named skill, but that together they build a richer picture than any single attention pass usually can. That richer picture is what makes multi-head attention such a central piece of modern language models.
Attention in Large Language Models
How does a large language model keep so much context in view? Attention is the piece that makes that feel possible. Instead of carrying a long prompt through a narrow bottleneck, the transformer lets each new token look back across the sequence and gather the clues it needs, which is why the model can stay sensitive to relationships that are far apart in the text. The original Transformer replaced recurrence and convolution with attention-driven processing, and that shift made the system both more parallelizable and faster to train.
What makes this work in practice is that attention is not a one-time trick; it appears again and again as the model moves through its layers. In the transformer, the encoder and decoder both use stacks of self-attention and feed-forward layers, with residual connections and layer normalization helping each layer refine the representation instead of starting over. That means the model is not rereading the prompt from scratch at every step; it is steadily sharpening what it already knows, one layer at a time.
The decoder has one especially important rule: it cannot peek into the future. During generation, the model predicts the next token one position at a time, so the self-attention inside the decoder uses masking to block access to later tokens. That keeps the process honest and preserves the auto-regressive setup, which is the standard “predict the next word from the words before it” rhythm used by large language models.
You can think of attention mechanisms as a flexible spotlight rather than a fixed camera. The model does not assign equal importance to every earlier word; instead, it computes weights and uses them to form a weighted sum of the values, so some tokens influence the current one much more than others. This is why self-attention feels so useful for language: it lets the model connect pronouns to names, modifiers to nouns, and clues near the end of a sentence back to ideas introduced much earlier.
Then multi-head attention makes that spotlight more versatile. Rather than relying on one attention pattern, the transformer runs several heads in parallel, each with its own learned projections, and then combines their outputs. The paper describes this as letting the model attend to information from different representation subspaces at different positions, which is a plain-language way of saying that one head can focus on one relationship while another tracks a different one at the same time.
There is still one quiet issue in the background: attention alone does not know order. Because of that, the transformer adds positional encodings to the input embeddings so the model can tell where each token sits in the sequence. Without those position signals, large language models would know which words are related, but not reliably which word came first, which came second, or how far apart they are.
So when we talk about attention in large language models, we are really talking about a system that keeps meaning in motion. It lets the model compare, choose, and combine context at each step, while layers, masks, multiple heads, and position signals keep that process organized. That is why attention is not just one component among many; it is the thread that ties the whole model’s memory together.