What Are Transformers?
Transformers are the architecture that changed modern natural language processing (NLP), the field where computers learn to work with human language. If you have ever wondered, what are transformers in NLP?, the shortest answer is that they are a neural network design built to understand words in context by paying attention to the other words around them. The original Transformer appeared in the 2017 paper Attention Is All You Need, and the authors described it as a new network based solely on attention mechanisms rather than older sequence-processing machinery.
To see why that mattered, it helps to remember the older way language models worked. Recurrent neural networks, or RNNs, read text one step at a time, while convolutional neural networks, or CNNs, combine nearby pieces of text but still struggle to connect far-apart words efficiently. That slow, step-by-step style makes it harder to use modern hardware well, because the model cannot look at all parts of a sentence at once. The Transformer was designed to change that rhythm: it uses a small, constant number of steps and can train much faster because it processes words in parallel.
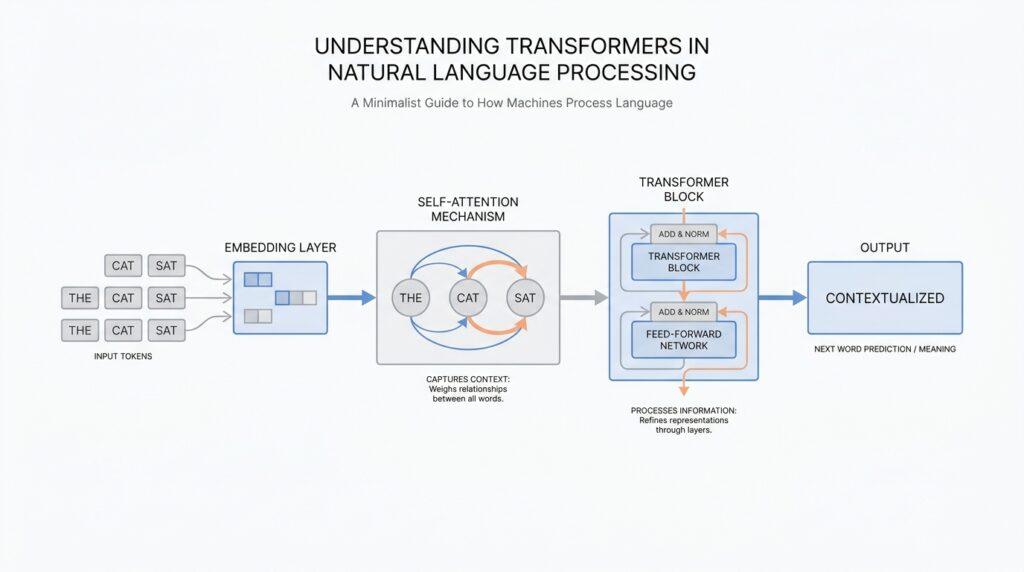
The heart of the idea is self-attention, which is a mechanism that lets each word look at every other word and decide which ones matter most. Imagine the word bank in a sentence: if the sentence also includes river, the model can give river more weight than it would in a sentence about money. The Google Research explanation says the model compares a word to every other word, assigns attention scores, and uses those scores to build a new representation that reflects the surrounding context. In plain language, self-attention is the model’s way of asking, which parts of this sentence should help me understand this word right now?
Once that idea clicks, the rest of the Transformer starts to feel less mysterious. The model begins by turning each word into an embedding, which is a learned numeric representation of meaning, and then it repeatedly refines those representations using self-attention. In machine translation, the architecture usually has an encoder, which reads the input sentence, and a decoder, which generates the output sentence one word at a time while consulting what the encoder learned. The key difference from older models is that the Transformer can update many word representations in parallel instead of dragging meaning forward through a long chain of steps.
That design was not only elegant; it was effective. In the original paper, the Transformer outperformed recurrent and convolutional models on translation benchmarks while requiring less computation and training time, and it also showed that it could generalize to other tasks like syntactic parsing. That is why transformers became such a big deal in NLP: they did not merely move language understanding a little forward, they gave researchers a faster, more flexible foundation for building models that handle context well.
So when we talk about transformers, we are talking about a way of letting a model read a sentence with a wider view, like a careful reader who keeps glancing back at the whole paragraph to catch the meaning of each line. That broad view is what makes Transformer models so powerful, and it is also what sets up the next question: how do layers, attention heads, and positional information help the model keep track of word order and nuance?
Self-Attention Explained
When we first meet self-attention, it helps to picture a sentence as a small room full of people who can all glance around before answering. In a Transformer, each token—a token is a word or a piece of a word—does not have to wait its turn the way an older recurrent model does. Instead, self-attention gives every token a way to look at the others and decide which neighbors matter most for understanding its meaning.
How does self-attention know that river matters more than bank? It assigns an attention score, which is a number that says how relevant one token is to another in the current sentence. If we hear “I arrived at the bank after crossing the river,” the word bank needs help from river far more than from arrived or at, so the model gives river a larger weight when building the new meaning for bank. That is why self-attention feels less like word spotting and more like careful reading: the model is always asking, “Which parts of this sentence should I listen to right now?”
Under the hood, the mechanism is a weighted mix. The Transformer compares one token with every other token, turns those comparisons into scores, and uses the scores as weights for a weighted average of the other representations before sending the result through a small neural network. This new representation does not erase the original word; it refines it with context, the way a sentence in a conversation becomes clearer after you hear the full reply. In plain language, self-attention lets the model rebuild each word’s meaning after it has heard the rest of the sentence.
That repeat-and-refine pattern is what makes self-attention so useful across an entire sentence. The same idea runs in parallel for all tokens, and then later layers can look at the already-refined representations and sharpen them again. The Google Research team even showed attention patterns for tricky cases like coreference, where the model has to decide what it means when a word such as it points to different nouns in different contexts. A model that can revisit the whole sentence this way is much better at keeping track of meaning over distance than one that must push information through a long chain of steps.
Of course, this broad view comes with a cost. Full self-attention compares all pairs of positions in a sequence, so the work grows quadratically as the input gets longer, which is why long documents are much harder than short sentences. That trade-off is the price of giving every token a wide field of view, and it is one reason researchers keep inventing sparse attention methods for longer contexts.
So when we talk about self-attention in Transformers, we are really talking about a model learning to read like a patient person at a dinner table: first listening to everyone, then using the most relevant voices to shape its answer. Once that idea feels familiar, the next step is to see how Transformers keep word order intact while they do all that listening.
Multi-Head Attention
Multi-head attention is the part of the Transformer that keeps the model from thinking with only one narrow point of view. After self-attention gives each token a contextual update, multi-head attention lets several attention mechanisms work side by side, each one looking for a different pattern. Think of it like reading a sentence with a few different highlighters at once: one might mark grammar, another might mark meaning, and another might mark a long-distance link. That is why multi-head attention in Transformers feels so powerful—it gives the model several ways to understand the same text at the same time.
How does multi-head attention help a Transformer see more than one relationship at once? The idea is that each head learns its own version of attention by using different projections of the input, which are learned linear transformations that reshape the numbers before the model compares them. Those comparisons still rely on the same core pieces you met earlier: queries, which ask what a token is looking for; keys, which describe what each token offers; and values, which hold the information to pass along. Because each head works in a smaller space, it can specialize, and the full model can then combine those specialties into one richer result.
That specialization matters because language rarely gives us only one clue at a time. In a sentence like “The trophy didn’t fit in the suitcase because it was too small,” one head may focus on the size relationship, while another head tracks what “it” refers to. A single attention pattern can notice something useful, but multi-head attention gives the Transformer several chances to notice different useful things. In practice, this means the model can follow syntax, meaning, and distance-based relationships without forcing all of them through one bottleneck.
Once each head has done its work, the Transformer does something very practical: it brings the head outputs back together. This step is like gathering notes from several assistants and combining them into one report, except the report is still numeric and can keep flowing through the network. The model then mixes those combined results into a new representation, which becomes the input for later layers. This is one reason Transformers can stack so well—the next layer does not start from a single, flat view of the sentence, but from a blended set of perspectives.
There is another quiet problem hiding in the background: attention alone does not know word order. If we shuffled the words in a sentence and only looked at the relationships between tokens, the model would not naturally know which word came first. That is why Transformers add positional information, also called positional encoding or positional embeddings, which are signals that tell the model where each token sits in the sequence. You can imagine them as seat numbers in a theater; the people are the tokens, but the seat numbers help the model remember the order in which they appear.
When multi-head attention and positional information work together, the Transformer gets both breadth and structure. The heads let the model examine the sentence from several angles, while position tells it how those pieces line up in time or in text. That combination is what makes the Transformer so good at understanding language as a connected whole rather than as isolated words. So when we talk about multi-head attention, we are really talking about a model learning to compare, separate, and recombine several useful views of the same sentence before it moves on to the next layer.
Encoder-Decoder Layers
After self-attention and multi-head attention, the Transformer starts to feel less like a diagram and more like a working machine. The encoder-decoder layers are the bridge between reading and writing: the encoder turns the input sentence into a sequence of rich numeric representations, and the decoder uses those representations to produce the output one token at a time. What do encoder-decoder layers actually do? They let the model keep the meaning of the source text in view while it generates a new sequence, which is why this design became the heart of the original Transformer for tasks like translation.
The encoder is the part that listens first. In the original Transformer, it is built as a stack of identical layers, and each encoder layer has two sub-layers: multi-head self-attention and a position-wise feed-forward network, which is a small neural network applied independently to each token position. The feed-forward network uses two linear transformations with a ReLU, short for rectified linear unit, which keeps positive values and drops negative ones. Around each sub-layer, the model adds a residual connection, meaning it adds the input back in before normalization, so the information can flow forward without getting lost.
The decoder is where the story becomes more delicate. It also uses a stack of identical layers, but each decoder layer has a third sub-layer that looks at the encoder output; this is the cross-attention step, where the decoder asks, “Which parts of the source sentence matter for the word I am choosing right now?” That cross-attention is what makes Transformer encoder-decoder layers so useful for sequence-to-sequence work. The decoder still has its own self-attention, but now it must work under a rule: it can only look at earlier generated tokens, not future ones.
That restriction is the trick that keeps generation honest. During training and inference, the decoder uses masking, which blocks attention to later positions so the model cannot peek ahead and cheat. In other words, when the decoder predicts the next token, it can consult the encoder and the tokens it has already produced, but not the answer it is supposed to discover later. This masking preserves the autoregressive property, which means each new prediction depends only on what has come before. If you have ever wondered why decoder layers feel different from encoder layers, this is the reason: one side reads broadly, while the other side writes carefully, step by step.
Once you see the flow, the whole path makes sense. The encoder creates a memory of the input, the decoder consults that memory, and the cross-attention layer acts like a guide that points the decoder toward the most relevant source tokens at each step. Because both encoder and decoder use residual connections and layer normalization, the network can stack several layers without becoming unstable. Because the feed-forward network is applied to each position separately, the model can refine each token representation after attention has gathered the context it needs. That combination is what gives the Transformer encoder-decoder architecture its clean rhythm: listen, refine, consult, and speak.
So when we talk about encoder-decoder layers, we are really talking about a conversation inside the model. The encoder gathers the full message, the decoder answers one word at a time, and the cross-attention connection keeps both sides in touch. That is the quiet power of Transformer decoder layers and encoder layers working together: they let the model remember the source sentence while still moving forward in a controlled, human-like sequence.
Positional Encoding
Now that self-attention can look across an entire sentence, a new problem appears almost immediately: how does the model know which word came first? A Transformer reads tokens—small pieces of text such as words or word fragments—but attention by itself does not naturally carry order. Positional encoding is the answer the original Transformer used: it injects information about where each token sits in the sequence, so the model can treat language as a line of ordered meaning rather than a shuffled pile of words. In the paper, the authors add these signals directly to the input embeddings at the bottom of the encoder and decoder stacks.
The important detail is that positional encoding does not replace the word embedding, which is the learned numeric representation of a token’s meaning. Instead, the model adds the position signal to that embedding, and both vectors must have the same size so the sum makes sense. That design is a little like writing a name tag on a suitcase: the suitcase still holds the clothes, but the tag tells you where it belongs in the row. In Transformers in NLP, that small addition helps the network keep meaning and order together from the very first layer.
The original paper used a fixed sinusoidal scheme, which sounds more intimidating than it is. A sinusoid is just a smooth wave, and the model uses sine for even dimensions and cosine for odd dimensions, each with a different frequency. You can picture those waves like a set of rulers laid on top of one another: some mark tiny shifts, while others mark broader distances. Because each dimension follows a predictable pattern, the model can learn position relationships without needing a separate lookup table for every possible slot in the sentence.
Why choose waves instead of something more obvious? The authors said they expected the sinusoidal version to make it easier for the model to learn relative positions, meaning how far apart two tokens are from each other, not just their absolute slots. They also tested learned positional embeddings, which are position vectors the model learns during training, and found that the fixed and learned versions performed nearly the same in their experiments. They kept the sinusoidal version because it may help the model generalize to sequence lengths longer than the ones it saw during training.
This is the part that often clicks for beginners: without positional encoding, attention can notice relationships, but it cannot reliably tell whether “dog chased cat” and “cat chased dog” are different orders of the same words. The model needs the order signal to know who did what to whom. Once that signal is attached, the rest of the Transformer can do its real job, which is to compare words in context while still respecting the sentence’s structure. That is why positional encoding in Transformers is not a decorative extra; it is the thread that keeps the sentence from falling apart.
So when you see positional encoding in a Transformer, think of it as the model’s built-in sense of sequence. It gives each token a place to stand before attention starts asking questions, and that single step makes the whole architecture usable for language. Without it, the network would hear the words, but it would lose the story they are telling. With it, the model can read the sentence in order and still enjoy the wide, all-at-once view that makes Transformer models in NLP so powerful.
Training and Fine-Tuning
Once the architecture is in place, training and fine-tuning are where the Transformer learns its manners. A Transformer begins as a set of adjustable numbers called weights, and training is the process of nudging those weights until its guesses get better. In the original paper, the model learned translation faster than older recurrent systems and reached strong results while using much less training time, which showed that this architecture could absorb patterns efficiently before we ask it to do one specific job.
The first stage is usually called pre-training, and it is the model’s broad education. Why does that matter? Because the Transformer can study huge amounts of text before it ever faces a narrow task, which helps it pick up grammar, phrasing, and long-range relationships. BERT made that idea very clear by pre-training deep bidirectional representations from unlabeled text, and T5 described transfer learning the same way: first pre-train on a data-rich task, then fine-tune on a downstream task.
Fine-tuning is the smaller, more personal lesson that comes next. Here, we take the pre-trained model and adapt it to one task, such as question answering, sentiment classification, or translation. BERT’s paper is the classic example: it says the pre-trained model can be fine-tuned with just one additional output layer, which is like keeping the same trained reader but changing the final form they use to answer a new question. That is why fine-tuning feels so powerful; you are not starting over, you are redirecting a model that already understands language.
In practice, fine-tuning means showing the model labeled examples, where each input comes with the correct answer, and then letting training adjust the weights so the predictions move closer to that answer. The model keeps the general knowledge it learned during pre-training, but the new examples teach it the style and goal of the current task. If pre-training is like learning the rules of a language, fine-tuning is like learning how to use those rules in one particular setting, whether that is customer support, search, or a classroom quiz.
That is also why fine-tuning works well when labeled data is limited. The model already knows how language behaves in general, so the second stage mainly teaches it what matters for this domain and this output format. In the original Transformer paper, the same architecture also generalized to another task after training, and later transfer-learning work made the pattern explicit: reuse a broad language foundation first, then specialize it instead of designing a brand-new model from scratch.
Seen this way, training and fine-tuning are two parts of one journey: first the Transformer learns to read broadly, and then it learns to answer locally. That is the quiet strength behind transformer models in NLP, because they do not memorize one job at a time; they build a flexible language core and then adapt it to whatever question we hand them next. So when we talk about how to fine-tune a Transformer for a new task, we are really talking about teaching a well-read student a new exam.
NLP Applications
Once the architecture was in place, the real question became: what do Transformer models in NLP actually do for us? The answer is that they turned language work into a flexible toolkit for real jobs like translation, question answering, summarization, and text classification. Instead of building a brand-new model for each task, we can start with one language engine and teach it how to wear different uniforms. That shift is what made NLP applications feel much broader and more practical.
The clearest place to start is translation, because that was the original Transformer’s home field. In the 2017 paper, the model beat strong machine translation systems and also generalized to English constituency parsing, which is a task where the model breaks a sentence into grammatical structure. Why does that matter? Because it shows the same core design can move from one sequence of words to another sequence of words, which is exactly what encoder-decoder systems are built to do. If your input and output are both text, the Transformer already knows how to make that journey.
But Transformer models in NLP did not stop at translation. BERT showed that a bidirectional encoder, meaning a model that reads left and right context at the same time, can be fine-tuned with just one extra output layer for tasks like question answering and language inference. Natural language inference is the task of deciding whether one sentence supports, contradicts, or says nothing about another sentence, so it is a compact way to test understanding. What does that look like in practice? The model reads a passage and a question together, then learns which span of text answers the question.
That is where the idea of text classification enters the story. Text classification is the act of sorting a piece of text into a label, such as a topic, intent, or sentiment, and the T5 paper makes this feel beautifully ordinary by turning every text problem into text-to-text form. In that setup, the input is still plain text, and the output is also plain text, even when the target is a label or a short answer. So instead of asking the model to solve different tasks in different ways, we ask it to speak one language consistently. That is a powerful pattern for NLP applications because it lowers the number of special cases we have to manage.
This is also why the same family of models works so well for summarization and question answering. T5 reports strong results on many benchmarks, including summarization, question answering, and text classification, by treating all of them as text-to-text problems. In plain language, the model learns to compress a long article into a shorter one when we want a summary, or to extract a precise reply when we want an answer. If you have ever wondered how a transformer can switch from reading to writing so smoothly, this is the trick: the task changes, but the underlying format stays familiar.
A useful rule of thumb is that encoder-only models are often a good fit for understanding tasks, while encoder-decoder models shine when the output needs to be generated. That is not a rigid law, but it matches the way the original Transformer and later models like BERT and T5 were used in their papers. The original Transformer handled translation and parsing, BERT excelled at understanding tasks like question answering and language inference, and T5 unified many NLP applications under one text-to-text frame. Seen together, they show a simple lesson: the best model is often the one whose output shape matches the job we want done.
So when we talk about Transformer models in NLP, we are really talking about a single idea that keeps finding new places to land. One day it turns into a translator, the next day a question-answering assistant, and the day after that a summarizer or classifier. The common thread is not the task itself, but the model’s ability to read context richly, then reshape that context into the form the application needs. That is what makes transformers such a useful foundation for so many NLP applications.