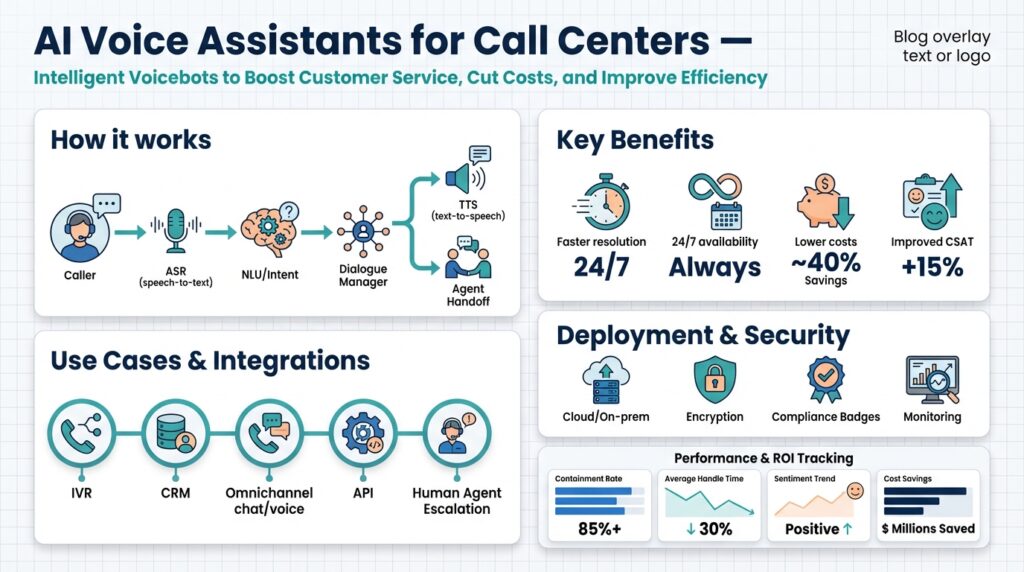
Why Voicebots for Call Centers
Voicebots deliver immediate scale for high-volume customer contact while preserving the conversational quality customers expect. In many contact centers the daily problems are predictable: long hold times, repetitive verification steps, and brittle IVR menus that funnel customers into queues. By inserting voicebots that perform natural-language routing, authentication, and common transactions, you reduce wait time and let human agents focus on exceptions and high-complexity work. Early placement of voicebots in the call flow increases containment rates and directly cuts cost-per-contact while improving throughput and availability.
Building on that operational case, voicebots bring technical advantages that make them attractive to engineering teams. Architecturally, a modern voicebot uses streaming ASR (automatic speech recognition) feeding a low-latency NLU (natural language understanding) pipeline and TTS (text-to-speech) for responses, which you can deploy as scalable microservices. For example, route logic can be as simple as if intent == "billing" -> fetchAccount(); else if intent == "transfer" -> startTransfer(); while observability captures ASR confidence, intent scores, and latency metrics for each turn. That pattern makes it straightforward to A/B test prompts, tune confirmations, and roll back models without touching telephony stacks.
From an integration and ops perspective, voicebots reduce friction across telephony, CRM, and workforce systems. You can connect the voicebot to your SIP gateway or WebRTC endpoint, publish events to your contact-center event bus, and push resolved-ticket data into the CRM to avoid duplicate work. This event-driven approach means the voicebot operates as an autonomous worker: it accepts calls, executes transactions against backend APIs, emits structured events for audit and billing, and hands off to human agents with full context when needed. The result is measurable: lower average handle time, higher first-contact resolution, and cleaner queue profiles that let you optimize staffing.
User experience and trust improve when voicebots carry context and reduce repetition. Customers hate repeating account numbers; the voicebot should capture identity tokens and attach a conversation ID so the agent receives a transcript, relevant intents, and the last actions attempted. How do you ensure a smooth handoff without making customers repeat themselves? Implement a deterministic handoff packet—{conversationId, intents[], confidence, transcript}—and surface it in the agent desktop so the human can take over immediately. That continuity raises CSAT and reduces escalations by eliminating redundant verification steps.
There are practical guardrails you must implement to make voicebots robust and compliant. Enforce data minimization and tokenization for PCI-sensitive inputs, log only hashed identifiers, and apply configurable confidence thresholds like if nlu.confidence < 0.6: confirm_or_route_to_agent() to avoid costly automation errors. Plan for latency budgets (speech-to-intent under ~300ms for natural turns), fallbacks to DTMF for noisy environments, and monitoring dashboards for containment rate, false-positive intent matches, and escalation reasons. These controls let you balance automation gains against risk while iterating on prompts and models.
Taken together, voicebots are a pragmatic way to increase capacity, reduce costs, and improve customer experience in call centers without a radical overhaul of core systems. We get predictable automation lift when we focus on high-frequency tasks, instrument end-to-end observability, and design explicit handoffs to agents. Next, we’ll examine patterns for designing prompt flows, selecting intent taxonomies, and measuring the ROI of staged deployments so you can deploy voice automation with confidence.
Core Components: ASR, NLU, TTS
Building on this foundation, the speech pipeline is where your automation either feels natural or becomes a frustrating loop for callers, so get ASR, NLU, and TTS right up front. In production voicebots we treat ASR (automatic speech recognition), NLU (natural language understanding), and TTS (text-to-speech) as distinct, observable services with clear SLAs: low streaming latency, reliable intent extraction, and expressive, low-latency audio output. Front-loading these keywords—ASR, NLU, TTS, and speech-to-intent—helps you focus tests and telemetry where they matter most in the first 300ms–500ms of a turn. As we discussed earlier about latency budgets, this stacking determines whether a conversational turn feels instant or stalled.
ASR is the input gatekeeper: it converts analog speech into tokens and confidence scores that every downstream decision depends on. Choose a streaming ASR that supports domain adaptation, custom lexicons, and robust silence/endpoint detection so you can accurately capture account numbers, dates, and named entities without manual re-prompting. For digit-heavy flows (account numbers, PINs), favor dual-path handling: use ASR for natural language and DTMF or constrained grammars for verification to reduce error rates. Monitor word error rate (WER) and per-utterance confidence alongside audio-level signals (SNR, clipping) so you can map failure modes to noisy channels, speaker accents, or echo and then apply targeted mitigations like noise suppression, alternative models, or forced-turn timeouts.
NLU turns transcripts into actionable intents, slots, and dialog state; treat it as the orchestration brain rather than a black box. Implement a layered approach: a fast intent classifier (for routing) plus a slot-filling extractor and a lightweight rule engine for high-confidence business-critical checks. Use contextual NLU that carries conversation state across turns to avoid repetitive confirmations and to support multi-step transactions (for example, transfer -> confirm amount -> authenticate). How do you prevent costly false positives? Use conservative intent thresholds, apply intent ensembling (model + deterministic rules), and require slot-level confidence for high-risk actions; if nlu.confidence < 0.6 or critical_slot.confidence < 0.7, prompt for confirmation or route to an agent.
TTS is your brand’s audible face—its quality affects trust and clarity during transactions. Choose streaming TTS with SSML support so you can inject prosody, pauses, and emphasis for verification lines and multi-field reads; that makes numeric confirmations and multi-item summaries far easier to parse for customers. For utterances that must be perfect (legal disclosures, sensitive instructions), use pre-recorded audio snippets and stitch them with TTS for dynamic fields to guarantee compliance while maintaining naturalness elsewhere. Cache frequently used phrases, reuse voice personas across channels, and measure perceived latency separately from synthesis time because jitter in audio playback often feels worse than microsecond differences in synthesis.
Observability and feedback loops tie the three components into a dependable system: instrument at the turn level and aggregate across sessions. Capture ASR confidence, transcript text, intent and slot scores, TTS synthesis time, and end-to-end speech-to-intent latency in a single event stream so you can query containment rate and failure reasons quickly. Run automated A/B tests on prompts and model versions, rollout via canary and feature flags, and keep fallback policies auditable—for example, a deterministic handoff packet ({conversationId, intents[], confidence, transcript}) sent to the agent desktop whenever escalation occurs. These signals make it feasible to iterate on prompts, tune thresholds, and reduce unnecessary escalations without manual guesswork.
Taking this concept further, design model update paths and validation harnesses before you push new ASR or NLU models into production so you’re not troubleshooting in live traffic. We recommend synthetic test calls, targeted user cohorts, and progressive rollouts tied to your telemetry gates; that way you can measure intent accuracy, WER, and customer-facing latency under realistic load. Next, we’ll apply these component-level practices to prompt flow design and intent taxonomy selection so you can measure ROI and match automation to the highest-value call types.
Common Use Cases and ROI
Voicebots and AI voice assistants deliver the most tangible ROI when we match automation to repetitive, high-volume contact patterns in the call center. Start with the highest-frequency, lowest-risk interactions—balance inquiries, shipment status, simple password resets, and natural-language routing—and you immediately free agents for escalations that require human judgment. Because these tasks map cleanly to short dialog trees and backend API calls, you can contain a large share of traffic with modest ASR and NLU accuracy requirements and a clear fallback strategy.
A practical way to identify initial candidates is to look for calls that follow deterministic logic and have high per-call handling costs. For those flows we design voicebot actions as discrete transactions: if intent == "billing" -> fetchAccount(); else if intent == "payment" -> startPayment(); and we require slot-level confirmations for critical fields. Building on our discussion of confidence thresholds, implement if nlu.confidence < 0.6: confirm_or_route_to_agent() so you avoid automating risky paths. That pattern reduces repeats and preserves customer trust while keeping the automation surface safe.
How do you measure ROI for targeted automations? Use a simple, repeatable formula: estimate the number of avoidable agent-handled calls, multiply by your cost-per-contact delta (agent cost minus voicebot cost), subtract implementation and run-rate costs, and annualize the result. For example, if you handle 10,000 monthly calls and contain 30% via voicebots, that’s 3,000 avoided agent interactions; at a $5 agent cost and $0.50 per automated interaction, monthly savings are (5 – 0.5) * 3,000 = $13,500. Use that model as a planning tool: change containment rate, cost assumptions, or escalations to see payback periods and sensitivity to ASR/NLU improvements.
Voicebots also enable higher-value use cases beyond containment that compound ROI when instrumented correctly. Consider pre-authenticating a caller and attaching a deterministic handoff packet {conversationId, intents[], confidence, transcript} to the CRM so an agent can resolve a complex dispute in one touch. Or automate parts of bill-pay flows while gating the final authorization behind stronger verification—tokenize card numbers and use DTMF or multi-factor prompts for high-risk steps. These hybrid patterns reduce average handle time (AHT) for complex calls without increasing fraud or compliance exposure.
Operational ROI flows from observability and staged rollouts as much as from automation design. Instrument every turn with ASR confidence, transcript, intent scores, slot-level confidence, and end-to-end speech-to-intent latency so you can surface failure modes quickly. Run A/B tests on prompt wording, canary new NLU models to cohorts, and gate full rollouts on key telemetry (containment rate, false-positive intent matches, escalation reasons). Those practices accelerate iteration and prevent regressions that would erode customer satisfaction—and a stable containment rate is where recurring savings come from.
When you prioritize use cases that are high-volume, low-risk, and well-instrumented, voicebots become predictable cost-savers and experience enhancers. In the next section we’ll translate these choices into prompt-flow design and intent taxonomy decisions that maximize containment while keeping escalation friction low, so you can plan phased deployments with measurable KPIs and clear go/no-go criteria.
Design Conversational Flows
Building on this foundation, start by treating conversation design as a system-level optimization problem: your goal is to maximize containment, minimize cognitive load, and keep latency under your speech-to-intent budget. Frame prompts and turn structure around measurable signals—ASR confidence, NLU scores, and slot-level certainty—so you can make deterministic decisions instead of guessing when to escalate. Use the same observability primitives we discussed earlier (turn-level transcripts, confidence, conversationId) to instrument every variant of a flow. That telemetry-first mindset makes conversational flows evolvable instead of brittle when traffic patterns change.
Define clear turn archetypes before you write prompts: routing turns, transactional turns, verification turns, and escalation turns each have different constraints and acceptable latencies. For routing, favor short, open prompts that prioritize intent classification and fast resolution; for transactions, switch to directive, slot-oriented prompts that reduce ASR ambiguity. Structure verification as selective and context-aware: require re-confirmation only when critical_slot.confidence < 0.7 or when the action is high-risk. By categorizing turns up front we keep the dialog compact and predictable for both customers and downstream integrations.
Prompt wording and control flow determine whether a voicebot feels helpful or frustrating, so design for progressive disclosure: ask for the minimum data you need to proceed, then request more only when required. Use mixed-initiative patterns—let the user interrupt or provide multiple pieces of information in one utterance—and implement a short, deterministic slot-filling engine that can absorb multi-slot inputs. For example, accept “Pay my bill for $45 on account 12345” and map to {intent: pay_bill, amount: 45, account: 12345} with slot confidence checks, then run if nlu.confidence < 0.6 or critical_slot.confidence < 0.7: confirm_or_route_to_agent() to avoid accidental authorizations.
Design handoffs and context carryover as first-class artifacts: attach a deterministic handoff packet {conversationId, intents[], confidence, transcript, lastActions} to the CRM or agent desktop so the human has full context without re-verification. Maintain a short-lived conversation state store that survives agent transfer; that lets you reuse already-collected tokens (masked or tokenized for PCI) and continue the flow seamlessly. When you need to pivot—say, from balance inquiry to payment—use explicit state transitions and a compact state machine to avoid ambiguous prompts that lead to loops.
Anticipate failure modes and build targeted fallbacks rather than generic apologies. For noisy channels, switch to DTMF or constrained grammars for numeric fields; for low-confidence NLU, ask a single clarifying question rather than repeating the whole prompt. Instrument fallback paths so you can quantify how often DTMF or agent escalation occurs, and tune thresholds accordingly. How do you validate a new prompt version in production? Canary it against a small segment of traffic, gate on containment rate and false-positive intent matches, and roll forward only when telemetry meets your SLA criteria.
Iterate on flows with rigorous A/B testing and synthetic testbeds that replicate real-world audio, accents, and network jitter. Track a small set of leading indicators—containment rate, end-to-end speech-to-intent latency, WER, and escalation reasons—and tie them to business outcomes like AHT and cost-per-contact. Run scheduled reviews of edge-case transcripts and failure clusters so you can prioritize model and prompt fixes that move the needle. By treating conversational flows as product features with telemetry gates and progressive rollouts, we preserve CX while delivering measurable automation gains.
With these patterns in place, you can move from brittle scripts to resilient, observable conversation flows that scale. In the next section we’ll apply these design principles to selecting an intent taxonomy and mapping intents to backend transactions so you can prioritize automation by ROI and risk.
Integrate With Telephony and CRM
If you want your automation to reduce handle time and avoid agent friction, start by treating telephony and CRM as equal partners in the call flow. We often see teams wire a voicebot into a telephony gateway and stop there, which leaves agents without context and customers repeating themselves. Instead, design the integration so every call carries a persistent conversationId from the SIP or WebRTC ingress through to the CRM record and agent desktop. This front-loads context, reduces repeated verification, and makes the voicebot a first-class participant in the contact-center ecosystem.
Begin with the plumbing: connect the voicebot to your SIP gateway or a WebRTC endpoint and publish structured events to the contact-center event bus. Use a small set of well-defined events—call.accepted, speech.turn, intent.detected, action.executed, call.transferred—and include a correlation header such as X-Conversation-ID. For CRM synchronization, push a compact handoff payload like {conversationId, callerToken, intents[], confidence, transcript, lastActions} to a webhook or CTI adapter so the CRM can create or update a ticket atomically. That deterministic packet avoids ambiguous state and gives agents the exact inputs they need when they pick up.
Protecting sensitive data during these exchanges is non-negotiable: adopt tokenization for payment or identity tokens, hash identifiers in logs, and use ephemeral session tokens for agent lookups. We recommend dual-path verification for digit-heavy inputs—accept account numbers via DTMF and store only a tokenized reference in the CRM while keeping the raw digits out of logs. Apply configurable confidence gates in the voicebot: if nlu.confidence < 0.6: confirm_or_route_to_agent()—this pattern minimizes false automation while preserving throughput. Enforce role-based access in your CRM and agent desktop so that only authorized agents can request de-tokenization for high-risk steps.
Make the agent desktop the place where telephony signals and CRM state converge so agents see a coherent story at handoff. Surface the handoff packet, a time-stamped transcript (or excerpt), intent candidates with scores, and a short action history rather than raw audio. Implement a single RESTful endpoint on the agent UI that accepts the handoff packet and attaches it to the corresponding CRM record; for example: POST /crm/records/{id}/handoff {conversationId, summary, transcript, intents}. When agents can click through the exact transaction the voicebot attempted, average handle time drops because they don’t need to re-create context.
Observability must bridge telephony and CRM events to diagnose failures quickly and to validate automation ROI. Correlate telephony metrics (SIP response codes, jitter, packet loss) with speech-level signals (ASR confidence, WER) and CRM outcomes (ticket created, disposition). Instrument end-to-end traces using the same conversationId so you can query “show me all calls where nlu.confidence < 0.6 and CRM.ticket.created == false.” Those traces let us set realistic SLA gates for model rollouts and identify whether a problem is in the telephony layer, the NLU model, or the CRM sync.
How do you guarantee a smooth handoff without repeating verification? Design a minimal verification surface: retain only what the agent critically needs (tokenized identifier, last successful authentication method, and a confidence score). If the voicebot authenticated a caller with OTP earlier in the session, attach the OTP token status and timestamp rather than replaying the OTP. Use explicit fallback rules—if important_slot.confidence < 0.7 then require re-authentication—so agents only step in when necessary and customers avoid redundant steps.
Taking these integration patterns together, we reduce friction at scale by making telephony, the voicebot, and the CRM act as a single conversation fabric rather than siloed systems. When integrations carry deterministic handoff packets, enforce tokenization, and expose correlated telemetry, you get predictable containment gains and measurable drops in AHT. Next, we’ll translate this operational foundation into prompt-flow patterns and intent taxonomies that prioritize high-ROI automations and low-risk handoffs.
Deploy, Monitor, and Measure
Deploying a production voicebot demands the same rigor you apply to any customer-facing service, but with tighter latency and observability constraints because speech flows are human-facing and time-sensitive. We front-load ASR and NLU health checks into the deploy pipeline so you don’t release a model that inflates false positives or increases speech-to-intent latency above your SLA. Start each release with synthetic end-to-end calls that exercise noisy channels, DTMF fallbacks, and tokenized authentication paths; if those tests fail the pipeline, abort the rollout. Embed feature flags and canary percentages so model changes hit a controlled segment before full production.
When you push new ASR or NLU models, gate the rollout on measurable telemetry rather than subjective QA alone. We recommend wiring automated gates that check containment rate, per-turn ASR confidence, slot-level accuracy, and agent-escalation rate before advancing a canary from 5% to 50% to 100%. Configure your CI/CD to emit a deterministic handoff packet ({conversationId, intents[], confidence, transcript}) for each synthetic call so you can validate the exact payload agents receive. Use immutable model tags and a quick rollback path—if nlu.confidence < 0.6 or containment_rate ↓ 10%: rollback()—so you can revert safely without redeploying telephony plumbing.
Monitoring needs to be both signal-rich and queryable: focus on leading indicators that warn you before customers complain. How do you set SLOs and alerts? Define SLOs for speech-to-intent latency, containment rate, end-to-end error budget, and WER; then create alerts for sustained deviations (for example, 5-minute windows where containment drops or ASR confidence falls below thresholds). Instrument turn-level telemetry—ASR confidence, transcript, intent score, slot confidences, TTS synthesis time—and aggregate into dashboards that support drill-downs to individual conversations by conversationId. Capture escalation reasons and agent feedback so you can close the loop between automated decisions and human outcomes.
Measuring business impact requires correlating your telemetry with contact-center KPIs so you can quantify ROI and prioritize fixes. We always tie the event stream to CRM outcomes and cost metrics: map containment events to avoided agent-handled calls, calculate delta in cost-per-contact, and attribute changes in average handle time (AHT) to specific dialog changes or model versions. Use trace queries like “show calls where nlu.confidence < 0.6 and CRM.ticket.created == false” to find cases where automation failed silently. That correlation gives you concrete levers—prompt rewrites, model retraining, or telephony fixes—that directly move the needle on cost and CSAT.
Operationalize incident response and continuous improvement with playbooks and scheduled audits that use both synthetic and real traffic. Run daily or weekly synthetic runs that mimic accented speech, packet loss, and low SNR so you surface regressions in ASR or TTS early; pair those with A/B testing of prompts and model ensembles to validate changes against containment rate and false-positive intent matches. Maintain a compact runbook: when escalation rate exceeds threshold, isolate by cohort, roll back the last model tag, open a postmortem, and queue transcript clusters for product and ML owners to prioritize. We find that disciplined telemetry gates and short feedback loops shorten mean time to mitigation and preserve customer trust.
Taking this concept further, treat deployments, monitoring, and measurement as a single feedback loop that feeds your intent taxonomy and prompt design work. As we iterate on intent granularity and dialog flows, feed the same conversationId-linked telemetry into your validation harness so you can prove automation lifts in production before expanding coverage. By connecting deploy controls, observability, and business metrics you make automation predictable: model changes become experiments with clear go/no-go criteria, and improvements in containment rate translate into measurable operational savings and better agent workflows.