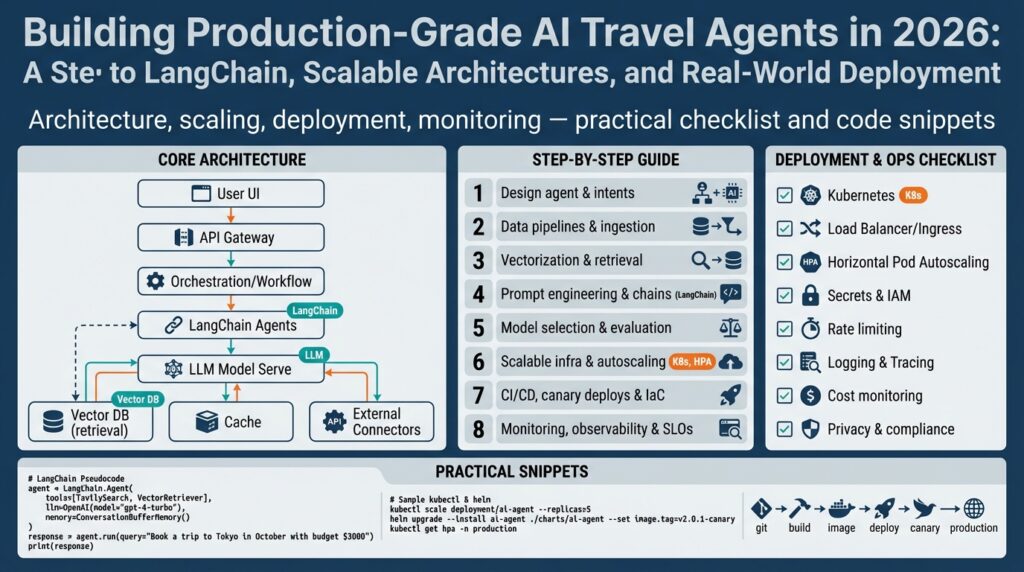
Define goals, scope, and requirements
Building on this foundation, the first thing we must make explicit are the measurable goals that will drive every architectural and product decision for AI travel agents, LangChain integrations, and scalable architectures in production-grade systems. Start by asking: what business outcomes matter most—higher conversion on bookings, reduced call-center volume, or faster itinerary generation? Translate those into concrete targets such as “reduce booking latency to <500ms for pre-check operations,” “support 1,000 concurrent conversational sessions,” or “achieve 99.95% uptime.” Front-loading these performance and reliability targets makes later trade-offs between model quality, cost, and latency unambiguous for engineering and product teams.
After goals, define scope with discipline: decide exactly which travel flows you will automate in the initial release and which you will defer. Specify channels (web chat, mobile, email, IVR) and integrations (payment gateway, airline GDS, hotel APIs, CRM) so you avoid scope creep during implementation. For example, an MVP might automate search, price-check, and draft itineraries while leaving ticketing and refunds as manual or semi-automated flows. How do you balance user experience and operational risk? Use that trade-off to set boundaries: which user intents are handled end-to-end by the agent and which require human handoff.
Next, enumerate functional requirements that map to those scoped flows. List capabilities like multi-leg itinerary synthesis, calendar-aware scheduling, fare rules validation, dynamic rebooking, and multi-locale natural language understanding. On the technical side, require deterministic connectors for external APIs, idempotent booking operations, and versioned policy logic for cancellation/refund rules. Specify the LangChain-style components you’ll use—retrieval-augmented generation (RAG) pipeline, vector store for embeddings, prompt templates—and define operational constraints such as model warm-up, batch vs. streaming responses, and cost-per-query budgeting.
Non-functional requirements will determine your runtime topology and tooling selection. Call out SLAs (p99 latency), throughput (queries per second), concurrency, resilience (circuit breakers, retries, backpressure), and scalability targets for vector DB and LLM endpoints. Demand observability: distributed tracing, request-level logs, and model-outputs auditing to measure hallucination rates and confidence calibration. For production-grade deployments, require container orchestration, horizontal autoscaling, and feature flags so you can canary new prompts or model versions safely without global user impact.
Security, privacy, and compliance requirements are deal-breakers for travel products. Specify how PII and payment data will be handled: tokenization or vaulting of payment instruments, redaction of sensitive fields in logs, and data residency constraints for regulated markets. Define consent flows, retention policies, and requirements for audit trails that show which prompt, retrieval context, and model produced a booking decision. Require encryption at rest and in transit, least-privilege service accounts, and periodic pen-testing and threat modeling informed by real-world attacker scenarios.
Define success metrics and an experimentation plan to validate the agent against the goals. Track business KPIs (conversion rate, bookings per active user), technical KPIs (latency p95/p99, error rate, cost per booking), and model KPIs (precision@k for retrieval hits, hallucination incidents per 10k responses). Instrument A/B and progressive rollouts so we can compare prompt strategies, retrieval window sizes, and LangChain pipeline variants. Make monitoring actionable by wiring alerts to runbooks and automating rollback criteria for any degradation in SLA or safety metrics.
These requirements form the input to design decisions—service boundaries, data flows, and deployment patterns—so capture them in a living product spec and traceability matrix. With clear goals, scoped functionality, and hardened requirements for reliability, privacy, and observability, we can translate needs into concrete architecture diagrams and implementation sprints. Next, we’ll turn this requirements baseline into a system blueprint that balances model latency, cost, and reliability for a production-grade AI travel agent.
Design scalable architecture and system components
Building on this foundation, the first architectural decision is to treat the agent as a set of composable runtime components rather than a single monolith; this framing makes a scalable architecture achievable and testable. Start by separating retrieval, orchestration, and execution responsibilities into independent services so you can scale the expensive pieces independently. For example, keep a lightweight front-end conversational API that handles session state and routing, a retrieval service that talks to the vector DB and knowledge layers, and an execution service that calls LLM endpoints and downstream booking APIs. This separation reduces blast radius and clarifies where to apply caching, rate-limits, and autoscaling.
Design service boundaries around latency and consistency requirements: retrieval can tolerate eventual consistency while bookings require strong idempotency and transactional guarantees. How do you partition services to keep critical latencies low? Put synchronous, latency-sensitive operations (price checks, fare validation) on vertically optimized paths with warm LLM endpoints and in-memory caches, and shift longer-running synthesis or itinerary generation to asynchronous workers with task queues. Use a dedicated vector DB cluster for embeddings and semantic search, and expose it through a retrieval API that the orchestration service calls—this lets you scale search independently of downstream compute.
Scale each component according to its load profile rather than cloning the entire stack. Stateless conversational front-ends and orchestration layers scale horizontally under container orchestration using pod autoscaling and health probes, while the vector DB and stateful stores require deliberate sharding, replication, and capacity provisioning. Warm small, cheaper LLM endpoints for intent detection and routing, then route complex generation to larger models; this tiered model routing reduces cost-per-query and keeps p95 latency predictable. Configure autoscaling policies that use custom metrics (embedding QPS, model concurrency, and queue depth) instead of CPU alone to avoid thrashing during traffic spikes.
Resilience is built from isolation and explicit failure-handling patterns: apply circuit breakers, bulkheads, and backpressure to protect booking flows and third-party integrations. Implement idempotent booking endpoints and a saga-style compensation mechanism so partial failures can be reversed without manual intervention. Instrument every request with distributed tracing that ties user session IDs through retrieval hits, prompt versions, and the LLM response used to make a decision; this observability is indispensable when debugging hallucinations or unexpected booking behavior. Record model inputs and outputs with redaction rules to enable audits while protecting PII.
Protecting sensitive data should be part of the runtime topology rather than an afterthought: place a redaction sidecar or middleware on ingress that strips or tokenizes PII before any logs, vector DB, or third-party call. Vault payment instruments and use ephemeral tokens for downstream APIs, applying least-privilege service identities for each integration. Define data residency and retention boundaries at the service level so vector embeddings and conversation histories live only where policy permits. Combine audit logs, tamper-evident event stores, and traceability metadata so you can answer regulatory inquiries about why an agent performed a particular booking.
Operationalize changes with progressive deployments and rigorous testing of LangChain-style pipelines and prompt versions before routing production traffic. Use canary or blue-green deploys and feature flags to validate new retrieval windows, prompt templates, or LLM endpoints against real traffic without a full rollout. Bake prompt and retrieval unit tests into CI so we can catch regressions in hallucination rates or intent mapping early; route failing canaries to fallbacks that use smaller models or human-in-the-loop handoffs. These patterns keep costs bounded, maintain availability, and make the system manageable as we map this blueprint into concrete diagrams and implementation sprints.
Choose models, vector stores, and embeddings
Choosing the right models, vector store, and embeddings determines whether your travel agent feels fast and accurate or slow and flaky. In the first 100 words: focus on models with the right context window and latency profile, pick a vector store that scales with your document corpus and query QPS, and select embeddings that capture travel semantics (itineraries, fare rules, policies). These decisions directly trade off cost, latency, and hallucination risk—so treat them as product levers you can tune as you onboard real traffic for production-grade AI travel agents.
Start by tiering models according to task. Use small, low-cost models for intent classification, entity extraction, and routing to keep p95 latency low, and reserve larger, high-quality models for itinerary synthesis and policy-aware booking text generation where accuracy matters. For example, implement a two-stage call: intent = small_model(query) then response = large_model(prompt + retrieval_context) only when intent requires generation. This pattern reduces cost-per-session and lets us warm or cache heavyweight endpoints for high-value flows like bookings.
When selecting embeddings, evaluate semantic fidelity, dimensionality, and multilingual support. Higher-dimensional vectors sometimes yield better semantic separation but increase storage and ANN search time; conversely, compact embeddings cut cost and I/O. Choose embedding models that understand travel-specific language—flight classes, fare codes, refund windows—and measure performance with precision@k on a labeled set of FAQs and itinerary retrievals. Re-embed when your knowledge sources change materially and tag vectors with version metadata so you can roll back or A/B new embedding models safely.
Pick a vector store with production features, not just an open-source demo. Prioritize a store that supports efficient ANN indexes (HNSW or IVF/PQ depending on scale), metadata filtering for policy and user-residency constraints, strong replication and snapshotting, and predictable cold-start behavior. Whether you host Faiss/Milvus or run a managed option like Pinecone or Weaviate, validate how the store behaves under your expected QPS and vector size; run load tests that mimic 1,000 concurrent sessions and mixed read/write patterns to avoid surprises in production.
Operational patterns matter as much as raw technology. Implement an ingestion pipeline that normalizes documents, chunks long policy text into 500–1,500 token overlapping windows, embeds them, and upserts into the vector store with provenance metadata. Schedule incremental re-embedding jobs and keep a compact search index for recent changes to support low-latency reads. Monitor embedding drift and build a simple audit that links any booking outcome back to the retrievals and model version that produced it—this traceability is essential for debugging hallucinations and regulatory audits.
How do you balance retrieval depth against latency? Use dynamic retrieval windows driven by intent: quick intents (“flight status”) use top-3, low-latency retrievals; complex composition intents (multi-city itinerary) expand to top-20 and run generation asynchronously if needed. Combine semantic embeddings with sparse filters (price ranges, dates) for hybrid search so we reduce false positives and keep the RAG context tightly focused. Integrate this routing inside your LangChain-style orchestration so prompt templates, retrieval size, and model selection are parameters you can change without a deploy.
Finally, bake measurement into every decision. Track precision@k, recall, cosine-distance thresholds, p95 retrieval latency, model cost per booking, and hallucination incidents per 10k responses. Use these metrics to drive experiments: swap embedding models, change ANN parameters, or move workloads between managed and self-hosted vector stores until you hit your SLA and cost targets. With clear telemetry and versioned artifacts for models and embeddings, we can iterate quickly while keeping bookings reliable and auditable for production-grade AI travel agents.
Implement LangChain agents and tool integration
Building on this foundation, the next practical step is wiring your orchestration to real-world systems so the LangChain agent can take reliable actions. You want agents that do more than generate text: they must call booking APIs, validate fares, check calendars, and surface auditable decisions. That means treating tool integration as first-class infrastructure—secure credentials, idempotent wrappers, and explicit permission policies—so your travel flows remain deterministic and debuggable in production. Early decisions here directly affect latency, cost, and compliance.
Choose an agent architecture that matches operational needs instead of blindly copying an academic pattern. For high-stakes flows like ticketing, prefer a plan-and-execute model where a lightweight planner emits a deterministic step list and a hardened executor calls tools; for exploratory user help, a flexible ReAct-style agent may fit. We route cheap intent and slot-filling to small models, then invoke heavyweight generation or multi-step toolchains only when the planner decides a booking or policy-check is required. This split reduces cost and ensures sensitive operations run through controlled code paths.
Wrap every external integration with a small, testable tool layer that enforces auth, timeouts, retries, idempotency keys, and redaction rules. For example, a Python Tool class should accept a structured input, acquire an ephemeral credential from a vault, set a short timeout, and return a strict JSON schema. Example pattern:
class BookingTool(Tool):
def call(self, payload):
token = vault.get('payment-token')
resp = http.post(url, json=payload, headers={'Authorization': f'Bearer {token}'}, timeout=5)
return parse_booking_response(resp)
Keeping logic out of prompts and inside these wrappers prevents accidental PII leakage and makes retries and compensations straightforward.
Define clear contracts for tool outputs and enforce them with output parsers and JSON schemas so the agent never acts on free-form text. Use schema validators to extract fields like booking_id, status, and fare_token, and reject or escalate responses that fail validation. How do you ensure tools are safe to call from an LLM? Require explicit “intent-to-call” tokens in the planner output and gate tool execution behind a policy service that checks user scope, session risk score, and rate limits before any side effect occurs.
Instrument every tool invocation with request-level metadata: prompt version, retrieval hits, embedding vector IDs, tool inputs (redacted), and tool outputs. Log these to an audit store that supports tamper-evident queries so you can reconstruct why the agent booked a specific flight. Add runtime observability—traces for cross-service latency, counters for tool error rates, and metrics for hallucination incidents tied to retrieval precision@k—so we can run safe canaries and roll back prompt or tool changes quickly.
Performance and reliability require operational patterns baked into tool integration: use async calls and background workers for long-running itinerary synthesis, queue critical booking operations with idempotency tokens and saga-style compensations, and cache deterministic lookups like fare rules with short TTLs. Protect external partners with circuit breakers and backpressure so spike traffic doesn’t cascade into failed bookings. Tie vector store retrieval parameters to the planner: compact top-3 for status checks, expanded top-20 for itinerary assembly, and always include provenance metadata so every generated suggestion can be traced to its source.
Taking these steps turns a research-style LangChain prototype into a production-capable agent: authenticated, auditable, and resilient tool integrations that you can test, monitor, and evolve. Next, we’ll map these runtime patterns into deployment strategies and CI practices so prompts, retrievals, and tool logic can be safely promoted through canaries and progressive rollouts.
Secure, test, and handle errors
Building on this foundation, our first priority is treating security and reliability as runtime features rather than post-deploy checkboxes. You should design service boundaries, credential vaults, and redaction middleware from day one so that every production-grade LangChain pipeline enforces least-privilege and protects PII before it reaches logs, vector stores, or LLM endpoints. We’ll apply the same discipline to testing and error handling: instrumented tests, canary rollouts, and observable failure modes that let us detect and contain problems before they affect bookings or payments. This upfront investment reduces blast radius and makes continuous deployment realistic.
Protecting sensitive flows requires concrete controls inside the runtime path, not just policy documents. Implement a redaction sidecar or middleware that tokenizes card numbers, masks traveler identifiers, and strips sensitive fields from model contexts; keep raw payment data in a vault and return ephemeral tokens to services. Enforce short-lived credentials and mutual TLS between orchestration, retrieval, and execution services so lateral movement is costly for an attacker. Example pattern (pseudo-code):
def redact_and_forward(payload):
payload['cc'] = vault.tokenize(payload.pop('cc'))
payload = redact_pii(payload)
return downstream.call(payload)
This pattern enforces security at the edge and ensures downstream analytics and vector stores never ingest raw PII.
Testing must cover models, retrieval, and tool integrations as first-class artifacts in CI. How do you test hallucination rates in a LangChain pipeline? Build unit tests that assert retrieval precision@k on labeled datasets, integration tests that validate tool output schemas, and synthetic prompt tests that exercise adversarial inputs and prompt-injection attempts. Run canary experiments that compare hallucination incidents per 10k responses, p95 latency, and booking error rates before a full rollout, and automate rollback when thresholds are breached. Treat prompts, retrieval windows, and model versions as versioned artifacts with their own test suites.
Error handling should be deterministic and auditable so retries and compensations don’t create duplicate bookings or irreversible side effects. Use idempotency keys on all booking API calls, implement saga-style compensating transactions for multi-step flows, and place circuit breakers around third-party partners so backpressure prevents cascading failures. Instrument every failure with a structured incident record that includes trace IDs, prompt version, retrieval IDs, and redacted inputs so you can replay and diagnose without exposing sensitive data. These measures make error handling predictable and safe under real traffic.
Security-focused testing belongs alongside functional tests: include red-team prompt attacks, fuzzing of retrieval filters, and policy-enforcement checks for tool execution. Gate any side-effecting tool calls with a policy service that evaluates session risk, consent state, and rate limits before allowing the executor to run. We should also run periodic pen-tests and automated dependency scans against the orchestration and container management layers to keep the attack surface under control. Combining security testing with behavioral tests strengthens both runtime safety and user trust.
Finally, operationalize what you test and secure: ship runbooks that map common alerts to remediation steps, automate safe canaries and feature flags for prompt changes, and track the metrics that matter—hallucination incidents, booking error rate, p99 latency, and security policy violations. When an incident occurs, the audit trail we built earlier must let us reconstruct why the agent acted and which model, retrieval, or tool produced the decision. Taking these steps moves us from experimental prototypes to production-grade systems where security, testing, and robust error handling are integral to every deployment and release.
Deploy, monitor, and scale in production
Deploying a production AI travel agent forces hard trade-offs between latency, cost, and safety; get those trade-offs explicit before you push traffic. In the first deploys we treat observability as a feature: instrument prompts, retrieval IDs, model versions, and downstream tool calls so you can trace any booking from user utterance to API side effect. Make continuous deployment part of your pipeline so every prompt change, LangChain pipeline update, or model swap passes automated tests and a controlled rollout gate. When you plan to deploy, monitor, and scale in production, front-load deployment patterns and observability so incidents are diagnosable rather than mysterious.
Start deployments with progressive rollout patterns that limit blast radius: use canary or blue-green deployments combined with feature flags to route a percentage of sessions to new prompt versions or model endpoints. Automate CI to run prompt regression tests, retrieval precision@k checks, and schema validation for every tool integration before any traffic reaches production. Integrate container orchestration and orchestration tools so the conversational front-end, retrieval API, and execution workers deploy independently; this separation lets you push a new planner without touching booking executors. Keep deploys small and reversible: small, frequent changes make rollbacks and post-mortems tractable.
Observability must include not just infra metrics but model-centric telemetry—request latency, p95/p99, embedding QPS, hallucination incidents per 10k responses, and the top-k retrieval precision for each intent. How do you measure hallucinations in production? Instrument assertion checks and ground-truth validators for high-risk flows (fare rules, refunds), log model outputs with redaction, and run post-hoc sampling where human reviewers label drift and hallucination cases. Use distributed tracing that connects session IDs through retrieval hits, prompt version, and the LLM response so you can reconstruct the exact inputs that produced a bad booking. Push these traces into dashboards and link alerts to runbooks.
Scale components according to their load profile rather than cloning the whole stack: horizontally scale stateless conversational APIs on CPU/memory metrics while provisioning vector DB shards and replica sets for the retrieval layer. Route inexpensive tasks (intent classification, slot-filling) to warmed small models and reserve large, high-context endpoints for itinerary synthesis or booking confirmation text generation; this tiered model routing reduces cost and keeps p95 latency predictable. Use autoscaling that consumes custom metrics—embedding QPS, queue depth, and model concurrency—so scaling responds to application demand instead of noisy CPU spikes. Cache deterministic lookups like fare rules and calendar availability with short TTLs to reduce downstream QPS.
Protect booking flows with resilience primitives: add circuit breakers around third-party partners, enforce backpressure on queues, and apply idempotency keys on every side-effecting call (for example: HTTP header Idempotency-Key:
Operationalize monitoring with actionable alerts and automated rollbacks: tie alerts to specific thresholds like hallucination incidents per 10k, p99 latency, and booking error rate; connect each alert to a runbook that names the owner and remediation steps. Run canaries that compare new prompt or model variants against control traffic using the metrics that matter—conversion, safety incidents, and cost-per-booking—and fail the canary automatically when thresholds are breached. Use feature flags to progressively widen exposure and to quickly disable risky behaviors without a deploy.
Manage cost-quality trade-offs explicitly: measure cost per session and cost per booking and use that signal to decide when to warm endpoints, cache retrievals, or reroute to smaller models. Experiment with dynamic retrieval windows—top-3 for status checks, top-20 for complex itineraries—and A/B prompt templates to find the sweet spot between accuracy and latency. Treat model endpoints, embeddings, and vector stores as versioned artifacts that can be rolled back if cost or hallucination metrics regress.
Taking these operational patterns together makes production behavior predictable and auditable, and it sets the stage for safer continuous delivery of LangChain pipelines and prompt logic. Next, we’ll map these runtime controls into CI practices and deployment templates so we can promote prompt and retrieval changes through staged environments with confidence.