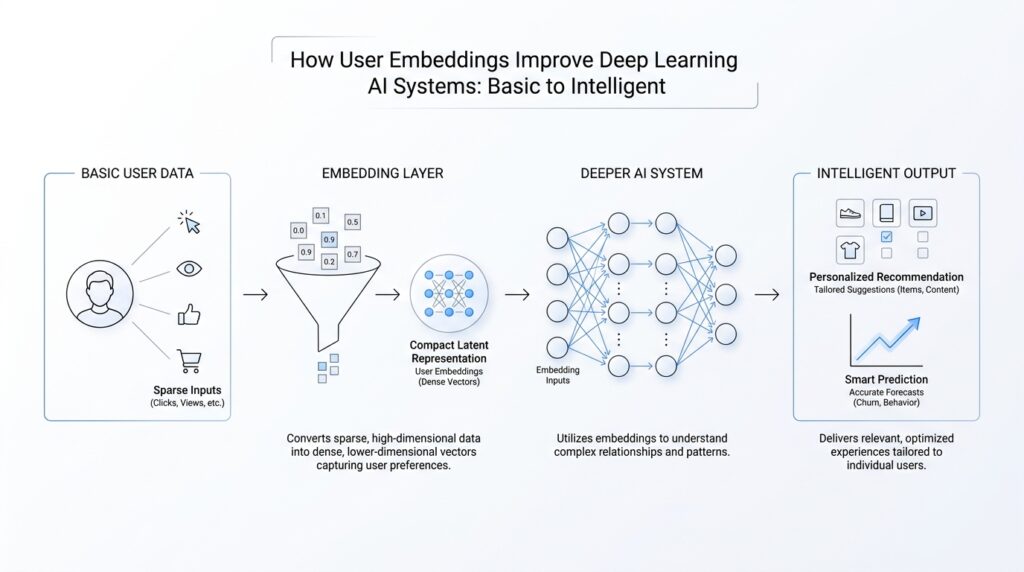
What User Embeddings Mean
When we talk about user embeddings, we are talking about giving each person in a system a compact numerical portrait. Instead of storing a user as a long list of clicks, likes, purchases, or searches, the model turns that history into a vector—a row of numbers that acts like a coordinate in a hidden map. If you have ever wondered, what is a user embedding in deep learning?, the simplest answer is that it is the model’s way of saying, “This user is similar to these users, and different from those others,” without spelling that out in words.
That idea matters because raw user data can feel messy and oversized, like trying to recognize a friend from a suitcase full of receipts. A deep learning model is a neural network, meaning a layered system that learns patterns from data by adjusting internal weights. A user embedding lets that network compress a person’s behavior into a shape it can work with quickly. The embedding does not describe the user in plain English; it describes the user in a form the model can compare, combine, and refine.
A helpful way to picture it is to imagine a large map where nearby points represent similar people. Someone who watches science videos, reads tech articles, and saves coding tutorials may land near other learners with similar habits. Someone else who shops for baby products and watches parenting content may appear in a very different region. These positions are not hand-drawn by humans. The model learns them during training, which means the user embedding becomes a data-driven summary of behavior rather than a fixed label like “beginner” or “expert.”
This is where user embeddings become powerful in deep learning AI systems. They help the model notice patterns that are hard to capture with simple rules. Two users may never share the same exact actions, yet their embeddings can still land close together if their behavior follows a similar rhythm. That similarity gives the system a smoother way to predict what each person might want next, whether that is a video, a product, a song, or a piece of content. In practice, the embedding becomes a shortcut to personalization.
The beauty of this approach is that it also handles change. A user embedding can shift as a person’s behavior shifts, much like a sketch that gets redrawn as we learn more about the subject. If you start exploring gardening, your embedding may slowly drift toward other gardening-focused users. If your habits broaden, the representation can widen too. This is one reason user embeddings improve deep learning systems: they let the model update its understanding of you over time instead of freezing you into a stale profile.
There is also an important difference between a user embedding and a simple category tag. A tag says, “This person likes sports.” An embedding says, “This person lives at this point in a learned space, where their mix of tastes, timing, and behavior relates to many other patterns.” That extra richness is what makes user embeddings useful in recommendation systems, ranking models, and prediction tasks. They give the network a more human-like sense of context, even though the system is still working entirely with numbers.
So when we say a system uses user embeddings, we mean it has learned a compact language for understanding people through behavior. The model is not memorizing a biography; it is building a useful map of relationships between users. And once we have that map, we can start asking the next question: how does the model turn those hidden coordinates into better predictions?
Turning Actions Into Vectors
Now that we have a compact portrait of a person, the next step is to teach the model how to read what that person does. In deep learning, turning actions into vectors means converting each click, view, pause, purchase, or search into numbers the model can compare and learn from. If you have ever asked, “How do actions become vectors in a recommender system?”, this is the bridge between messy behavior and a model’s hidden language. The goal is not to preserve every detail forever; it is to give each action a useful shape, so user embeddings can grow from real behavior instead of guesswork.
A good way to picture this is to think about a trail of footprints. One footprint by itself tells us little, but a sequence of them reveals direction, pace, and intent. A vector is a list of numbers that acts like a coordinate in a learned space, and each action gets its own coordinate before the model combines it with others. A click on a news story may point in one direction, while a long watch on a cooking video may point somewhere else. When we turn actions into vectors, we give the model a way to say, “this behavior feels like that behavior,” without hard-coding the meaning by hand.
That translation usually starts with the action’s basic details. The system may look at what item was clicked, what time the action happened, how long the user stayed, and what kind of content was involved. Each of those pieces becomes a feature, which is a measurable piece of information the model can use. The model then maps those features into a vector, much like packing a messy suitcase into a neatly labeled set of compartments. This is where action embeddings often appear: learned numerical representations of events or items that help the network treat similar actions as nearby in meaning.
The important part is that not all actions carry the same weight. A quick glance and a long, repeated interaction do not mean the same thing, even if they involve the same page or product. Deep learning systems learn to notice that difference by using the action vector along with context, such as recency, frequency, and sequence order. In other words, the model does not only ask what happened; it also asks when it happened and how strongly it seemed to matter. That context is what turns raw logs into useful signals for user embeddings and later predictions.
As the model watches more actions, it begins to build a rhythm. One action vector follows another, and together they form a pattern that looks less like a list and more like a story. A person who browses beginner tutorials, then intermediate guides, then advanced examples is not just collecting clicks; they are moving through a learning path. The system can learn that path because each action has been translated into numbers that line up with the rest of the sequence. That is why vectorizing actions matters so much: it lets the model recognize motion, not just snapshots.
This is also where the system starts becoming less brittle. A rule-based system might say, “people who clicked A also clicked B,” but deep learning can notice subtler relationships, like a user who often reads first and buys later, or someone whose tastes shift after a certain kind of search. By turning actions into vectors, the model can place different events on a shared map and discover which ones travel together. That shared map feeds back into the user representation, helping user embeddings stay flexible, current, and surprisingly personal.
So when we talk about turning actions into vectors, we are talking about giving behavior a machine-readable shape without flattening its meaning. The model is not memorizing isolated events; it is learning how those events relate, repeat, and evolve over time. That is the quiet machinery that lets deep learning systems move from raw activity to a richer understanding of people, one vector at a time.
Building Personalized Predictions
Now we reach the part where the map starts to feel useful. Once a model has a user embedding, it can begin making personalized predictions, which are forecasts tailored to one person instead of a crowd. Think of it like a shopkeeper who remembers not only what the store sells, but what each visitor tends to reach for next. That is the promise of user embeddings in deep learning AI systems: they help the model move from broad guesses to recommendations that feel surprisingly specific.
The basic idea is to place the user vector beside the item vector, where an item vector is the numerical representation of a video, product, song, or article. The model then compares those two sets of numbers and asks whether they fit together. If a person’s embedding sits near the embedding for a beginner tutorial, for example, the model can assign a higher score to that tutorial than to an advanced one. In practice, this is how personalized predictions begin: not with a hard rule, but with a learned sense of compatibility.
How do user embeddings improve deep learning AI systems when the system needs to predict the next best choice? They do it by giving the model context that single actions cannot provide on their own. A click tells us what happened once, but the embedding tells us what kind of pattern that click belongs to. If one reader often returns to long-form analysis and another prefers quick summaries, the model can separate those habits even if both people clicked the same article yesterday. That makes the prediction layer more like a thoughtful assistant and less like a blunt averaging machine.
This is where ranking comes in, meaning the process of ordering possible results from most relevant to least relevant. A ranking model does not only decide whether something is good or bad; it decides whether it should appear first, second, or much later. User embeddings help because they let the model score many options against the same person in a consistent way. One user may see a cooking video pushed to the top, while another sees a coding lesson, and both decisions come from the same learned system rather than separate hand-built rules.
The real strength of personalized predictions shows up when behavior changes. People are not static, and neither are their interests, which means the model has to keep reading the story as it unfolds. If you start exploring a new hobby, the user embedding can gradually move toward that new interest as fresh actions arrive. That shift matters because it keeps deep learning AI systems useful over time instead of locking you into an old version of yourself. A stale profile can feel like a misread conversation, while a living embedding can keep up with the next chapter.
There is also a practical reason this approach works so well at scale. A system may need to choose from thousands or even millions of items, and it cannot inspect each one with slow hand-crafted logic. User embeddings give the model a compact way to compare a person against many possibilities at once, which makes personalized predictions both faster and more flexible. The system is still learning from behavior, but now it can do that learning in a shared space where similar people and similar items naturally cluster together.
So the picture becomes clearer: the embedding is not the prediction itself, but the lens that helps the model make a better one. By turning a user’s history into a shape the network can compare with item vectors, deep learning systems can estimate what feels relevant, timely, and personal. That is why user embeddings matter so much in recommendation engines, search ranking, and next-step prediction. They give the model a way to see each person not as a number in a database, but as a pattern that can be understood, updated, and matched with care.
Adding Context Signals
When we start adding context signals, the picture gets sharper very quickly. A context signal is any clue about the situation around an action, such as the time of day, the device being used, the location, or the sequence of recent events, and these clues help user embeddings feel less like static portraits and more like living ones. If you have ever asked, How do user embeddings improve deep learning AI systems when the context keeps changing?, this is where the answer begins: the model stops reading behavior in isolation and starts reading it as part of a moment.
That matters because the same action can mean different things in different settings. A late-night click on a movie trailer may carry a very different signal from the same click on a weekday afternoon, and a mobile tap during a commute may suggest a different intent than a long desktop session at home. The model learns to treat those differences as meaningful, which means it can avoid flattening every choice into the same story. In other words, the embedding is no longer only describing who you are; it is also learning what situation you were in when you acted.
To make that possible, we give the model features from the surrounding world. A feature is a measurable piece of information, and in this case it might include whether the user is on a phone or laptop, whether the action happened this morning or this evening, or whether several related events occurred back to back. The model turns those details into numbers and blends them with the user vector, the item vector, and the action history we already discussed. That combination gives deep learning systems a richer lens, because now they can compare not only people and items, but also the moments in which those people and items meet.
This is where context signals start acting like stage lighting in a theater. The actors are the same, but the lighting changes how we understand the scene. A user who usually reads long articles might tap a short post only when they are on a phone and in a hurry, and the model can learn that pattern if it sees enough examples. Instead of assuming every tap means the same level of interest, it begins to separate casual browsing from serious intent, which makes user embeddings far more useful for prediction.
How do user embeddings improve deep learning AI systems once we add this extra layer? They help the model resolve ambiguity. A single action can be noisy, but a surrounding pattern of time, device, sequence, and session length can tell us whether that action was exploratory, habitual, or highly deliberate. That means the system can rank content with more care, recommend items that fit the moment, and respond to a user’s shifting attention without relying on blunt rules.
The most useful part is that context does not sit outside the embedding; it helps shape it. As the model learns from repeated situations, it starts to notice that some people behave one way at work and another way at home, or that interest grows gradually across a session rather than appearing all at once. This makes the representation more flexible and more human-like, because people rarely reveal their preferences in a single clean gesture. They move through context, and the embedding learns to move with them.
So adding context signals is really about teaching the model to read the whole scene, not just the main character. Once user embeddings can absorb the setting around each action, deep learning systems become better at telling the difference between a passing glance and a meaningful choice. That richer understanding is what lets the next layer of the system turn behavior into predictions that feel timely, relevant, and aware of the moment.
Solving Cold-Start Users
A new user arrives with an empty profile, and the system has almost nothing to work with. That is the cold-start problem, which means the model has to make a useful first guess before it has seen enough behavior to learn from. This is where user embeddings become especially valuable in deep learning AI systems, because they give us a way to start with structure instead of staring at blank space. If you have ever wondered, How do user embeddings help solve cold-start users?, the answer begins with the model learning to borrow strength from the signals that are available right away.
At the very beginning, we cannot rely on a long history of clicks or purchases, so we look for nearby clues. A user might sign up with an email domain, choose a region, pick a language, or answer a few onboarding questions, and each of those details becomes a small signal. The model turns those signals into a first-pass representation, which is a basic numerical summary built before much behavior exists. It is a little like meeting someone at the door and using their first few words, rather than their full life story, to start the conversation.
This first-pass representation matters because it gives the system a place to begin learning. Instead of treating the new person as a mystery box, the model can place them near other users with similar early traits and then make careful initial recommendations. For example, if a new reader chooses technology and beginner tutorials, the system can position that person closer to other first-time learners whose user embeddings already point in that direction. The result is not perfect certainty, but it is a much better starting point than random guessing.
The model also learns quickly from the first few actions, and those early actions carry extra weight. A single search, save, or completed view can tell us far more for a new user than it would for someone with months of history, because there is so little else to balance it against. Deep learning systems can update the embedding after each event, which means the representation grows from a rough sketch into a clearer portrait almost in real time. That is one reason cold-start users stop feeling invisible once the system begins to listen.
Another helpful trick is to lean on item and cohort patterns while the new user is still revealing themselves. A cohort is a group of people who share something in common, such as signup time, device type, or onboarding path, and the model can use those shared patterns to shape early predictions. If many users with similar starting signals tend to like the same items, the system can use that pattern as a guide until the individual user’s behavior becomes clearer. In deep learning AI systems, this shared structure helps avoid the awkward pause where the model has too little information to act.
So how do user embeddings improve deep learning AI systems when the user is brand new? They let the model combine sparse personal data with broader learned patterns, which gives personalization a head start. The embedding acts like a temporary bridge: it carries the system across the gap between no history and meaningful history. As soon as more actions arrive, that bridge can be replaced by a stronger, more personal route built from the user’s own behavior.
This is why cold-start handling is not only about solving a startup problem; it is about keeping the entire experience from feeling empty at the beginning. A new user should not have to wait for the system to become useful, and user embeddings make that possible by turning early hints into a usable shape. In practice, the model learns to begin with context, adjust with each signal, and steadily sharpen its understanding until the new person no longer feels new at all.
Measuring Model Impact
After we build user embeddings and watch them shape predictions, the next question is the one that keeps the whole system honest: how do we know they are actually helping? Measuring model impact means checking whether the model improves real outcomes, not just whether it feels clever on paper. In deep learning AI systems, that usually means comparing the new version against a simpler baseline, then watching whether it recommends better items, ranks them more accurately, and supports the experience more smoothly for real users.
The easiest place to start is with offline evaluation, which means testing the model on data it has already seen in hindsight. Think of it like practicing for a play in an empty theater before opening night. We measure things such as accuracy, ranking quality, and loss, which is a number that tells us how far the model’s predictions are from the truth. These early checks matter because user embeddings should not only look useful inside the model; they should also improve measurable behavior when we compare them with a version that does not use them.
But offline scores only tell part of the story. A model can look strong in a test set and still disappoint real people, which is why online evaluation matters so much. In practice, teams often use A/B testing, meaning they show one group the old model and another group the new model, then compare results like clicks, purchases, watch time, or retention, which is how often users keep coming back. If you have ever wondered, “Did the user embeddings really change anything?” this is the place where we get the clearest answer.
That comparison works best when we measure lift, which is the improvement the new model creates over the old one. Lift can sound abstract, so imagine two gardens: one gets ordinary care, and the other gets the same care plus better soil. If the second garden grows more healthy plants, the extra growth is the lift. In the same way, when user embeddings improve deep learning AI systems, we want to see more relevant recommendations, fewer wasted impressions, and stronger engagement without making the experience feel noisy or forced.
Still, raw totals can hide important details, so we also look at how the model behaves across different groups and situations. A model may work well for frequent users but struggle for newcomers, or it may perform well on desktop and less well on mobile. Measuring model impact means checking those slices carefully, because a system that helps one group while ignoring another can create a false sense of success. This is especially important for user embeddings, since their value often depends on how well they adapt to different patterns of behavior, not just the average result.
We also pay attention to calibration, which means checking whether the model’s confidence matches reality. If a system says something has an 80% chance of being useful, we want that prediction to behave like an 80% chance in practice, not a much lower one. Calibration matters because deep learning AI systems often make many small decisions, and those decisions add up over time. A model that is slightly overconfident in the wrong places can steer users away from good content even when its overall accuracy looks fine.
Another useful sign of impact is stability over time. A model that improves this week but decays next month is not truly helping, because user behavior, content inventory, and trends all keep moving. That is why teams track performance across time windows, retraining cycles, and changing user cohorts to make sure the gains from user embeddings hold up as the system evolves. In a living product, the real test is not whether the model wins once, but whether it keeps winning as the audience changes.
So measuring model impact is really about building trust in the system’s value. We start with offline checks, move to live experiments, compare against baselines, and watch for lift, calibration, and stability in the wild. When those pieces line up, we know the user embeddings are not just compressing behavior into neat vectors; they are helping deep learning AI systems make better decisions for real people, in real time, across real sessions.



