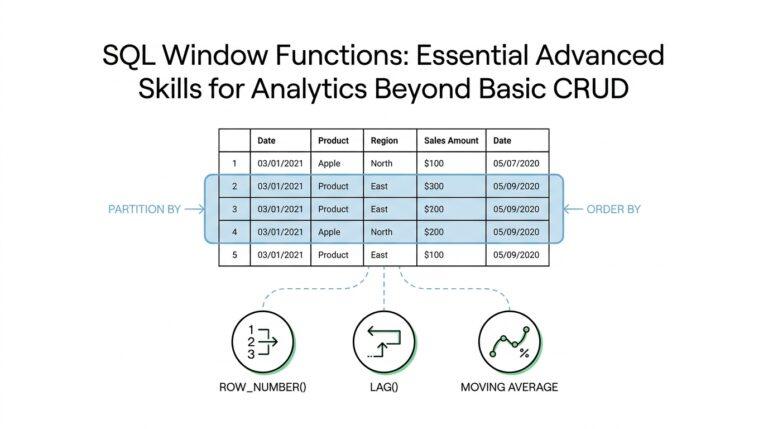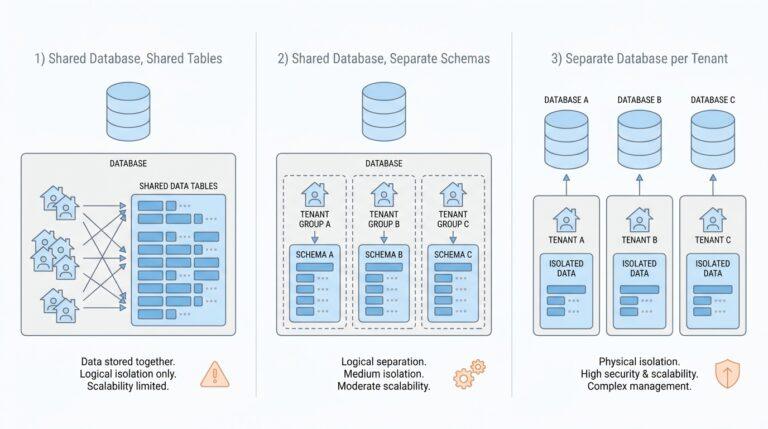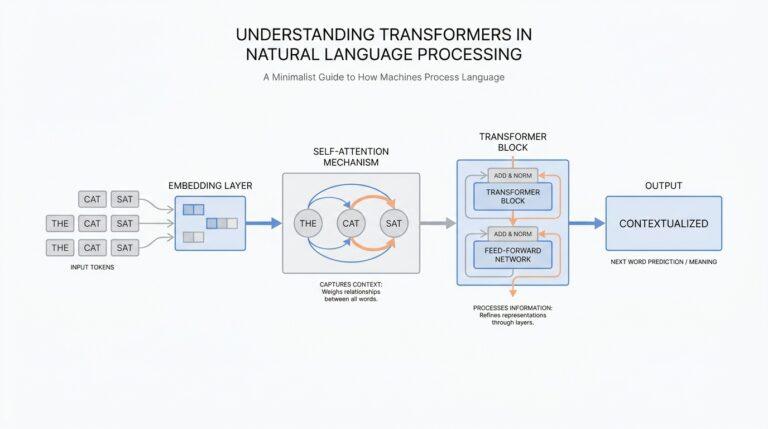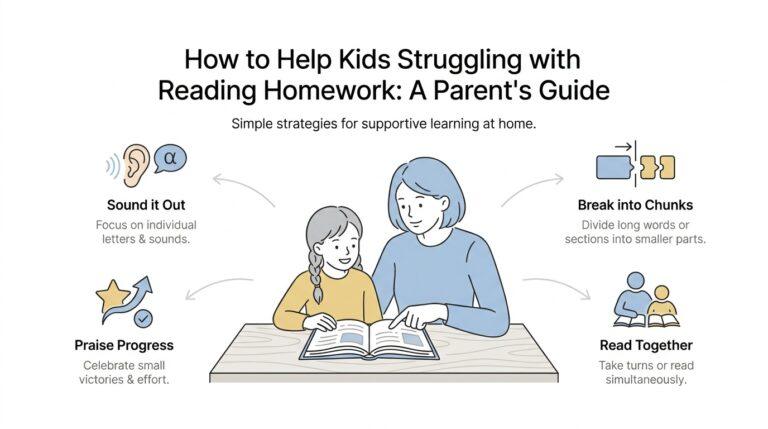
What AI Trust Actually Means
When we talk about AI trust, we are not talking about whether a model sounds confident or whether its answers feel polished. We are talking about whether you can rely on it in the messy real world, where a wrong output can waste time, mislead a decision, or create real harm. What does AI trust actually mean? It means the system behaves in ways that are dependable, understandable, and safe enough for the situation you are putting it in. That is why experts frame trustworthy AI as a mix of reliability, safety, security, transparency, and accountability—not as a warm feeling you get from a convincing chatbot.
This is where the conversation usually gets more interesting, because AI trust is bigger than accuracy. A model can be right often and still be a poor tool if it breaks under pressure, leaks private data, or hides the logic behind its answers. NIST, for example, describes the essential building blocks of AI trustworthiness as validity and reliability, safety, security and resiliency, accountability and transparency, explainability and interpretability, privacy, and fairness with mitigation of harmful bias. In plain language, that means we are asking not only, “Does it work?” but also, “Does it keep working, can we inspect it, and who is responsible when it fails?”
Think of it like trusting a bridge. You do not trust a bridge because it looks impressive from a distance; you trust it because it was built to hold weight, tested under stress, inspected over time, and designed with clear responsibility for maintenance. AI trust works the same way. A trustworthy AI system should behave consistently, stay robust in normal use and foreseeable misuse, and give people enough information to understand its capabilities and limits. The OECD AI Principles capture that idea by emphasizing transparency and explainability, robustness, security and safety, and accountability for the system’s proper functioning.
That is also why human oversight matters so much. In a trustworthy AI setup, the machine is not the final authority; it is a tool inside a larger decision process. The OECD says AI actors should provide meaningful information about how systems work, help people understand predictions or recommendations, and make it possible to challenge harmful outputs. In other words, AI trust is not blind obedience to a model. It is a working relationship in which people can question the system, interrupt it, and step in when the stakes are high.
If you are wondering, “Isn’t trust just another word for confidence in the technology?” the answer is no. Confidence comes from a single good result; trust comes from repeated evidence, clear limits, and a system of safeguards around the tool. NIST’s work on trustworthy and responsible AI makes this risk-based view explicit, describing AI governance as a way to maximize benefits while minimizing negative consequences. That framing matters because a system can be useful in one setting and dangerous in another, which means AI trust is always tied to context, not hype.
So when we use the phrase AI trust, we are really talking about a promise the system has to keep over time. It should be dependable enough to use, transparent enough to inspect, secure enough to resist misuse, and fair enough to avoid predictable harm. Once we see it that way, the real issue is no longer whether AI feels impressive; it is whether the people building and using it have earned the right to rely on it.
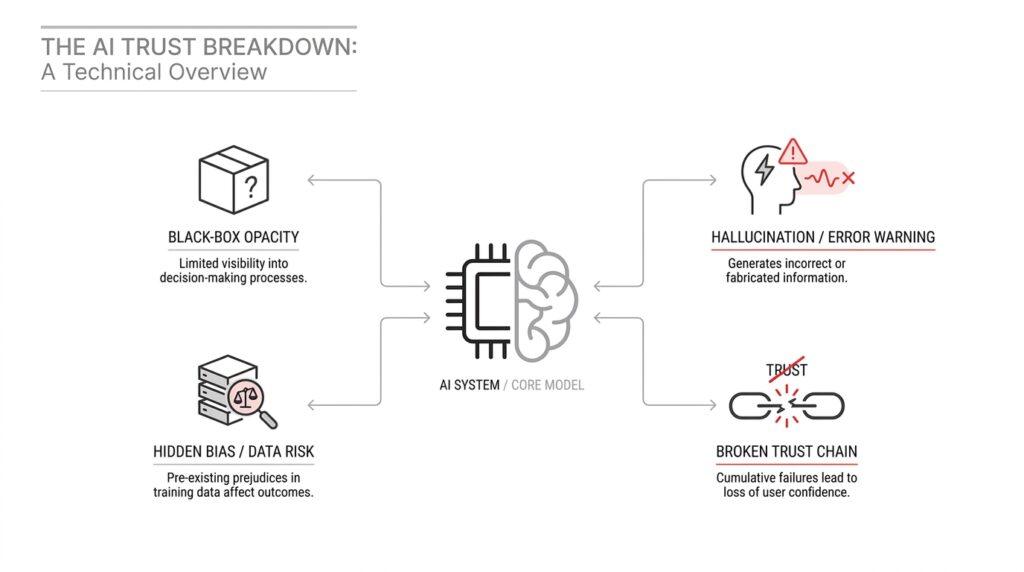
Hallucinations Break Basic Reliability
When you start depending on AI for real work, the first crack in trust usually appears in a very ordinary moment: you ask for an answer that looks polished, and only later do you realize it was invented. That is what people mean by a hallucination, which is a model producing something that sounds confident and complete but is actually false. Once that happens, AI trust stops being an abstract idea and becomes a practical problem, because reliability is only real when the output holds up under checking.
This is where the danger gets sneaky. A hallucination is not the same as a typo or a clumsy sentence; it can be a fake citation, a made-up date, an incorrect legal claim, or a product detail that never existed. The words arrive with the same smooth rhythm as a correct answer, so your brain has to do extra work to notice the difference. If you have ever seen a map app send you down the wrong street with total confidence, you already understand the feeling: the problem is not just that the system is wrong, but that it is wrong in a way that still looks trustworthy.
For AI trust, that is devastating. A tool can be useful when you can assume its errors are rare, visible, and easy to catch, but hallucinations break that assumption. The model may get nine things right and then quietly invent the tenth, and that one invented detail can be the exact detail you needed. What is the point of a reliable assistant if you have to verify every sentence anyway? At that stage, the burden shifts back to you, and the promise of time-saving help starts to evaporate.
The deeper problem is that hallucinations do not announce themselves. They are not wrapped in warning labels, and they do not always happen in obviously risky moments; they can show up in a summary, a customer email, a research note, or a quick explanation you were using as a starting point. That means the model can feel dependable on a good day and still fail at the moment you least expect it. In other words, the failure mode is not only inaccuracy, but uncertainty disguised as confidence, which is exactly why hallucinations are so corrosive to AI reliability.
If we step back, we can see why this hurts trustworthy AI so much. Trustworthy systems should help us know what is grounded, what is uncertain, and where human review is needed, but hallucinations blur those lines. Instead of giving you a clean handoff, the model hands you a polished guess and leaves you to separate fact from fiction. That is especially frustrating for beginners, because the answer usually sounds more authoritative than their own instinct, which makes it harder to question.
And this is where many people quietly change their behavior. They stop treating AI as a source of answers and start treating it as a source of drafts, ideas, or rough guesses that must be checked line by line. That may still be useful, but it is a very different relationship from the one most tools promise at first glance. Once hallucinations enter the picture, AI trust becomes less about whether the model can speak fluently and more about whether it can stay tethered to reality when the stakes matter.
Bias Hides In Training Data
The next place AI trust starts to wobble is much quieter than a hallucination. Instead of a model inventing something out of thin air, it begins repeating patterns it learned long before you asked your question. That is where training data comes in, meaning the large collection of text, images, audio, or records used to teach the model how to respond. And that is where bias enters, meaning a systematic tilt that pushes the system toward certain people, ideas, or outcomes. If you have ever wondered, why does AI trust break when training data is biased? the answer is that the model is often learning from a world that was never neutral to begin with.
This part is easy to miss because bias rarely announces itself with a warning sign. It hides in what gets collected, what gets left out, and what gets labeled as normal. A dataset may contain more examples of some groups than others, more formal language than everyday language, or more Western perspectives than global ones. On the surface, the AI model looks like it is learning facts, but underneath it is also learning proportions, priorities, and blind spots. In other words, the model does not just absorb information; it absorbs the shape of the information it was given.
That is why biased training data can feel so convincing while still being untrustworthy. The system may speak fluently, but fluency is not the same as fairness. If an AI system has seen far more examples of men in leadership roles than women, or more light-skinned faces than dark-skinned faces, it can start treating those imbalances as if they were natural law. This is a serious AI trust problem because the output may look objective even when the underlying pattern is skewed. The model is not choosing prejudice on purpose, but it can still reproduce it at scale.
The hardest part is that bias often hides inside ordinary decisions made during data collection. A team might scrape huge amounts of internet text because it is convenient, or use old records because they are available, or rely on crowd workers whose judgments reflect their own assumptions. Each step sounds practical, and each step can quietly distort the result. The model then learns from those distortions the way a child might learn accents from a neighborhood: not as a rulebook, but as a repeated environment. That is why biased AI outputs can show up as subtle differences in job screening, medical triage, image generation, or customer support.
Bias in training data also creates a trust gap because it is so hard to spot from the outside. You can test a model on one set of prompts and see polished, helpful answers, then watch it fail badly when the person, dialect, or situation changes. The model may perform well for the majority case and poorly for everyone else, which makes it look reliable until you look more closely. That is not a small technical flaw; it is a warning that AI trust cannot rest on average performance alone. If the training data is narrow, the model’s confidence can be built on a very uneven foundation.
So what should we take from this? We should treat the source material as part of the behavior, not as a hidden background detail. A trustworthy AI system needs more than scale; it needs diverse training data, careful labeling, and testing that checks whether the model treats people differently when it should not. As users, we can also ask sharper questions: what kinds of examples shaped this model, whose perspectives are missing, and where might the system be quietly overgeneralizing? Those questions do not solve everything, but they move us from blind acceptance toward real AI trust, which is built by inspection, not assumption.
Black Boxes Limit Transparency
After hallucinations and bias, there is another reason AI trust starts to slip: the system can give you an answer while hiding the path it took to get there. That is the black box problem. In a black box AI system, you can see the input and the output, but the middle stays murky, which makes it hard to tell whether the model is following evidence, pattern matching, or a lucky guess. NIST treats explainability as a key part of trustworthy AI, and OECD guidance says black box systems make it difficult to describe how an output was produced.
Why does that matter so much for AI trust? Because trust grows when you can inspect what a system is doing, not when you are asked to admire its confidence. The OECD says AI actors should provide meaningful information about a system’s capabilities, limitations, data sources, and the factors or logic behind a prediction or decision. That gives people a chance to understand the result instead of just accepting it, which is especially important when the system is helping with work, advice, or decisions that affect real people.
The trouble is that black boxes do not only hide mistakes; they also hide the reasons a mistake happened. If a model gives you a bad answer, you may not know whether the problem came from missing data, a strange prompt, a flawed training pattern, or a deeper design issue. OECD notes that opaque systems make it harder to detect and mitigate harmful outcomes and harder to assign accountability when something goes wrong. In practice, that means the burden shifts back to you: instead of the model carrying part of the thinking, you have to become the inspector.
That is where transparency and interpretability begin to feel less like technical terms and more like survival tools. NIST distinguishes explainability as the mechanisms behind a system’s operation and interpretability as the meaning of its output in context, which is a helpful way to think about the gap. A system can be impressive at generating answers and still leave you unable to answer a very simple question: why this output, right now, for this case? When that question stays unanswered, AI trust becomes fragile, because you are relying on behavior you cannot really examine.
This is also why black boxes create a very specific kind of discomfort: they ask us to outsource judgment without giving us enough visibility to judge the outsourcing itself. In a narrow, low-stakes task, that may feel acceptable. But once the output starts shaping hiring, health, finance, safety, or public decisions, opacity stops being a minor inconvenience and starts looking like a design flaw. The more important the decision, the more AI trust depends on being able to ask hard questions about what the model saw, what it weighed, and what it ignored.
So the real lesson is not that every model must reveal every internal detail, but that we should never confuse a polished answer with a trustworthy process. A system can sound fluent and still be hard to inspect, and that gap is exactly where caution belongs. If we want AI trust to mean anything practical, we have to keep asking whether the model is not only useful, but also open enough to question and clear enough to supervise before we rely on it.
Overreliance Turns Errors Harmful
The real danger is not the model making a mistake; it is the moment we stop treating its answer as something to question. Researchers call that automation bias, or over-reliance on automation: the tendency to follow a machine’s advice even when other clues say we should pause and check. In AI trust terms, this is where a small error stops being a small error and starts wearing a human seal of approval. The model has not only answered; it has quietly taken the wheel.
You can see the pattern in ordinary work, and that is what makes it so tricky. A polished response arrives, we copy it into a report, an email, or a decision memo, and suddenly the output is no longer a draft but part of the real world. NIST’s human-AI guidance stresses that roles and responsibilities need to be clearly defined because AI systems can defer decisions to humans, be used as an extra opinion, or require human oversight depending on the setting. That distinction matters, because once we stop checking, an error can travel farther than the model ever intended.
This is where convenience starts to work against us. Studies of over-reliance on technology describe how automation bias and complacency can pull people toward the system’s answer instead of a fuller review of the evidence, especially when the tool feels familiar, fast, or authoritative. In other words, the smoother the interaction feels, the easier it becomes to skip the extra glance that would have caught the mistake. What happens when you trust AI too much? Often, you stop hunting for the missing detail, and that missing detail is exactly where the harm lives.
The harm grows because AI errors rarely stay inside the chat window. A wrong suggestion can become a wrong summary, then a wrong recommendation, then a wrong action taken by a person who believed the system had already done the hard thinking. That is why trustworthy AI is not just about being accurate on average; it is also about whether people know when to slow down, verify, and override. OECD guidance says AI actors should support human agency and oversight, provide meaningful information about capabilities and limits, and give affected people a way to challenge outputs. Without those safeguards, AI trust turns into a habit of obedience instead of a process of judgment.
The most unsettling part is that overreliance does not need a dramatic failure to cause damage. It only needs a small mistake, a confident tone, and a tired user who decides not to verify one more detail. That is why automation bias shows up so often in decision-support settings: the system does not have to be perfect to be persuasive, and persuasion is enough to make a bad answer spread. Once we start depending on AI this way, we are no longer asking whether the tool can generate text, but whether it can do so without making us hand over our own caution along with it.
So the practical lesson is not to banish AI from the room; it is to keep it in the right seat. We can let it draft, suggest, summarize, and speed up the first pass, but we should not let it become the final authority when the outcome matters. That is the heart of AI trust: not blind confidence, but disciplined use, where human judgment stays awake, alert, and ready to interrupt the machine when reality says no.
Verify Outputs Before Trusting
The moment we stop and check an AI answer is the moment AI trust becomes real. After all the talk about hallucinations, bias, black boxes, and overreliance, the next step is not panic; it is verification. When you use AI as a first pass, you are treating it like a fast assistant, not a final authority, and that distinction matters more than most people realize. If you are wondering, how do you verify AI outputs before trusting them? the answer starts with a simple habit: assume the answer is useful only until it has been checked against something firmer.
That “something firmer” is usually the source material, meaning the original document, record, article, dataset, or expert note the AI should have been working from. Think of it like hearing a story from a friend and then asking to see the photo, receipt, or message thread that proves the detail. AI trust grows when the model’s words line up with evidence you can inspect yourself. Without that step, a polished response can slip past you looking far more certain than it really is.
This is why the safest approach is to verify the parts that matter most, not just skim the whole answer and hope for the best. Names, dates, statistics, quotations, prices, legal claims, medical details, and technical instructions deserve a second look because they are the easiest places for an AI model to go wrong. If an output says a company launched in one year but the official site says another, trust the source, not the phrasing. The model may sound fluent, but fluency is not the same as correctness, and AI trust depends on catching that difference early.
A helpful way to think about verification is to ask, “What would I need to be true before I could use this?” That question slows you down in a good way. Instead of accepting the whole response as one blob of confidence, you start breaking it into claims and checking each one against evidence. For work that affects other people, this can mean opening the original report, the policy document, the code, or the research paper and matching the answer line by line. It is not glamorous, but it is how we turn AI trust from a feeling into a process.
The next layer is to look for uncertainty inside the answer itself. A trustworthy AI system should help you see where it is solid and where it is guessing, but many outputs blur that line. When that happens, you can prompt the model to separate facts from inferences, list assumptions, or point out anything it is unsure about. That does not make the system perfect, but it does make its limits easier to see, and limits are part of honest AI trust. A tool that admits what it cannot prove is far safer than one that hides behind a smooth tone.
Verification also means using more than one lens when the stakes are high. One source can be wrong, one summary can miss context, and one model can repeat a pattern without understanding it. Cross-checking with a second source, a human expert, or the original data gives you a better shot at catching errors before they spread. That extra minute can save you from sending a bad report, repeating a false claim, or building a decision on sand. In practice, that is what responsible AI trust looks like: not blind reliance, but disciplined confirmation.
The real shift happens when you stop asking AI to prove itself with confidence and start asking it to earn your confidence with evidence. That is a very different relationship, and it is the one beginners often need most. The output can still be useful, fast, and even brilliant, but it should remain a draft until you have checked the claims that matter. Once you build that reflex, AI trust stops feeling like a leap of faith and starts feeling like a habit of careful reading, and that habit carries us naturally into the next question: what do we do when the answer is not just wrong, but misleading in a way the system never explains?