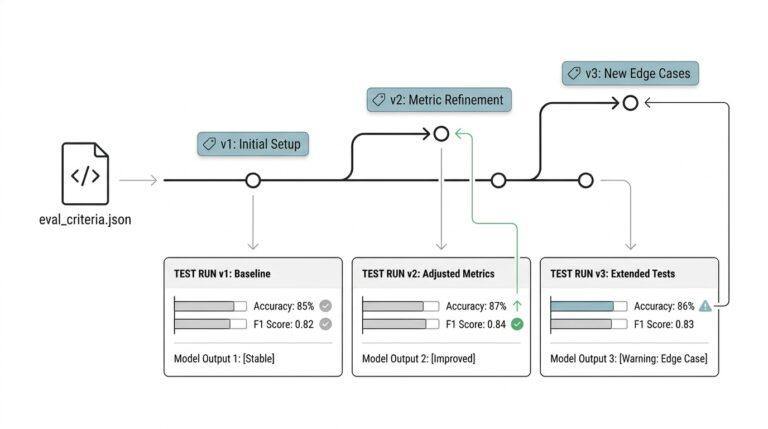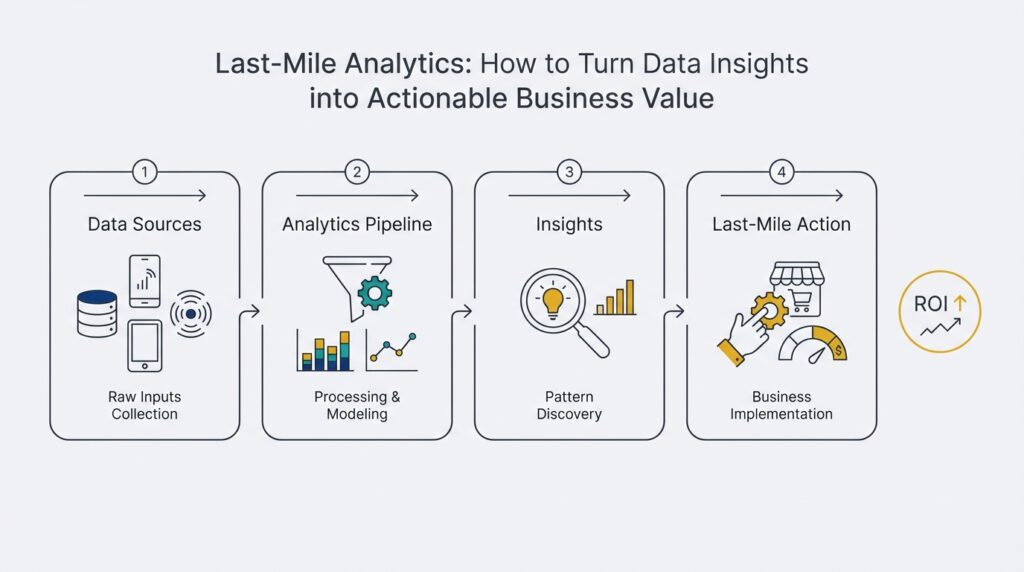
Clarify goals and success metrics
Building on this foundation, last-mile analytics only delivers if you translate insights into measurable business outcomes—and that starts with clear goals and success metrics. Decide up front what “actionable business value” looks like for the initiative: revenue lift, retention improvement, operational cost reduction, or time-to-decision. How do you define a successful analytics project when people ask, “How will we know this worked?”? Naming the business outcome in plain terms forces a tighter linkage between the analytics pipeline and the downstream decision that will change behavior or process.
Start by making goals specific, measurable, and time-bound so your team can instrument and evaluate them. Rather than “improve engagement,” define a goal like “increase seven-day retention for new users from 18% to 24% within 90 days.” This level of specificity tells you which events to capture, which cohorts to analyze, and which attribution window to use. Distinguish leading indicators (e.g., onboarding completion rate) from lagging outcomes (e.g., churn), because you’ll use leading indicators to iterate quickly and lagging metrics to validate long-term business value.
Assign metric ownership and a single source of truth so decisions don’t fragment across teams. Give a product manager or data owner responsibility for the definition, computation method, and tolerance for each metric, and register that definition in a metrics catalog. For example, if your North Star is “monthly active purchasers,” document the event definitions, deduplication rules, and time-zone handling so engineers, analysts, and marketers act on the same signal. This prevents local optimizations—sales teams optimizing for short-term conversion that harms lifetime value—because ownership enforces trade-offs and escalation paths.
Be rigorous about measurement nuance: denominators, sampling, and attribution windows materially change outcomes. When you measure conversion, decide whether it’s per session, per user, or per purchase; choose an attribution window that matches the customer behavior you want to influence; and make sampling explicit in production dashboards. For instance, a mobile feature that drives immediate conversions may show strong session-level lift but no impact on 30-day retention, which means you’d iterate on feature stickiness instead of doubling down on acquisition spend. Flag metrics with confidence intervals and expected lag so stakeholders interpret fluctuations correctly.
Operationalize success metrics with contracts, monitoring, and experiment gating so insights become repeatable actions. Create metric contracts that include computation SQL, owners, acceptable variance, and rollback triggers; expose those contracts in dashboards and CI pipelines that run whenever instrumentation or ETL changes. Configure alerts for metric regressions—e.g., notify when conversion drops more than 10% versus a rolling baseline—and tie alerts to playbooks that specify who runs the remediation experiment. We avoid unscoped dashboards that produce noise by enforcing metric SLAs and automated checks at the end of each analytics pipeline.
Prioritize metrics by expected value and implementation cost so you can deliver actionable business value quickly. Rank candidates by business impact, confidence in data, and engineering effort; prefer metrics that unlock a single, testable decision (price change, onboarding tweak, routing rule) over vanity metrics that don’t map to action. Taking this concept further, the next step is to design experiments and control planes that tie each metric to a concrete decision and cadence for review, so measurement becomes part of product development rather than an afterthought.
Choose KPIs and data sources
Building on the foundation of clear goals and metric ownership, we start by aligning KPIs to the concrete decisions people will make; this is the core of last-mile analytics and determines whether insight becomes action. A KPI (key performance indicator) should be defined in business terms, have an exact computation, and map to a single decision: change onboarding flow, shift marketing spend, or reroute fulfillment. Front-load the signal and the decision in the definition so everyone understands what action a 1% change should trigger. This reduces analysis paralysis and keeps your measurement focused on business value rather than vanity metrics.
How do you pick KPIs that map to a single decision? Use a simple scorecard that rates each candidate metric on three dimensions: expected impact on the business outcome, data confidence (signal quality and provenance), and implementation cost (engineering and instrumentation effort). Metrics with high impact and high confidence but low cost should be prioritized because they enable rapid experiments and clear rollbacks. We recommend recording these ratings in your metrics catalog alongside the metric contract so prioritization stays visible and repeatable when new stakeholders join the project.
Selecting data sources requires trade-offs between freshness, accuracy, and stability. Instrumentation events from the product (client- or server-side event streams) give fast, behavior-level signals useful for leading indicators, while transactional systems and order/ledger databases provide authoritative financial truth for lagging outcomes. Telemetry and log streams capture operational context (errors, routing latency), and third-party APIs (ad platforms, payment gateways, shipping partners) often supply attribution or fulfillment state we cannot produce internally. Evaluate each source for schema stability, latency, cardinality limits, and access cost before committing it to a KPI’s computation.
We must be rigorous about taxonomy, identity, and provenance to avoid downstream confusion. Define event names and fields consistently (for example, user_signed_up, onboarding_step_completed, purchase_completed) and enforce identity resolution rules—explicitly choose whether you join on user_id, anonymous_id, or an idempotency key. Implement metric contracts that include the canonical SQL or transformation code, expected row counts, acceptable drift, and rollback triggers; surface these contracts in CI checks so changes to instrumentation or ETL fail fast. This provenance means analysts and engineers can trace any KPI back to a specific event stream and transformation step when a discrepancy appears.
Translate KPI-to-source mappings into concrete implementation patterns so teams can act. For onboarding completion rate, capture step timestamps in the event stream and compute a cohort-level funnel in the warehouse using windowed SQL; for revenue per user, join the orders fact table to user profiles and apply deduplication by order_id to prevent double-counting. For last-mile operational metrics like delivery routing efficiency, combine GPS telemetry, dispatch events, and the routing engine’s decision logs to compute time-to-first-attempt and reroute frequency; these feed alerts that trigger routing policy updates. When you describe the implementation in code, include the exact joins, time-windows, and dedup rules so the metric contract is executable, not aspirational.
Finally, treat KPI selection and source choice as iterative: instrument minimally, validate signal quality, then expand. Deploy smoke tests, metric SLA monitors, and data-quality alerts tied to owners so regressions surface before they influence decisions. Establish a review cadence that links metric changes to experiments and product reviews so metrics stay relevant as the product and data ecosystem evolve. Taking this approach ensures that the KPIs you track and the data sources you trust form a reliable, actionable bridge from analytics to operational decisions, and sets up the next phase where we design experiments and control planes to close the loop.
Ingest, integrate, and clean data
Building on this foundation, the reliability of your analytics depends on rigorous data ingestion, data integration, and data cleaning at the front of the pipeline — these are the gates that determine whether insights are actionable or noise. How do you ensure the data feeding your KPIs is trustworthy and timely? Start by choosing clear ingestion patterns (batch, streaming, or change-data-capture) that match the SLA of each metric: use event-stream ingestion for leading behavioral indicators and CDC or transactional extracts for authoritative financial truth. This decision directly affects downstream freshness, deduplication strategy, and the complexity of your data cleaning rules.
Design your data ingestion layer to be idempotent and observable from day one. The topic here is idempotency: ingest events so replays and retries don’t double-count. Implement source-level de-duplication using deterministic keys (for example, order_id for purchases) and a simple dedup rule in the warehouse like ROW_NUMBER() OVER (PARTITION BY order_id ORDER BY event_ts) = 1 to keep the first canonical record. For streaming sources, add a monotonic event sequence or event_ts watermark and persist an ingestion offset; for batch sources, keep manifest files and checksums so you can verify exactly what was landed.
When we talk about data integration, the core problem is identity and schema mapping — merging disparate feeds into a single, queryable reality. Resolve identity explicitly: decide whether user_id, anonymous_id, or a composite key is canonical and document the merge rules in the metric contract. Use deterministic upsert semantics to integrate profile changes: a MERGE into profiles keyed on user_id with last-write-wins for tolerant fields and conflict-resolution logic for economic attributes. Map schemas with transformation layers that are executable (SQL, dbt models, or transformation jobs) so the exact joins and dedup rules are part of the codebase, not buried in analysts’ notebooks.
Cleaning is not an afterthought; it’s a set of automated gates that protect decision-making. Implement validation checks that fail pipelines on schema drift, null-critical fields, or row-count regressions relative to baselines. Convert messy values into canonical forms at ingestion — timestamps normalized to UTC, monetary values stored in smallest currency unit, and categorical values mapped to an enumerated taxonomy. Add anomaly detectors for upstream spikes (a sudden 10x increase in purchase_completed events should trigger an investigation) and include lineage metadata so you can trace any KPI back to the originating ingestion batch and transformation step.
Operationalize recovery and correctness: build replayability, backfill procedures, and monitoring into the data pipeline. Design your transforms to be re-run deterministically by keeping transformations idempotent and parameterized by safe watermark windows; when late-arriving events occur, use event-time windows with an allowed-lateness policy so metrics converge rather than flip unexpectedly. Surface data-quality metrics (schema version, row counts, percent nulls, sample hashes) in dashboards and tie alerts to owners with runbooks that specify when to replay, patch, or rollback transformed datasets.
Finally, treat this work as a delivery mechanism for the experiments and metric contracts we discussed earlier: reliable data ingestion, integration, and data cleaning are prerequisites for gating product changes on experiment outcomes. When you instrument a cohort or measurement, include the exact ingestion source, transformation SQL, and SLA in the metric contract so reviewers can validate the signal before acting. This makes the difference between a dashboard that generates noise and a pipeline that consistently feeds business decisions — next, we’ll look at how to convert those validated signals into experiment gates and control planes that close the last mile.
Develop models and visual dashboards
Building on this foundation of metric contracts and reliable ingestion, the way we convert insight into repeatable action is by designing models and visual dashboards that map directly to decisions. Early in the workflow, name the decision your model enables and the dashboard alert that will trigger it; this front-loaded intent prevents analysis drift. How do you ensure models and dashboards drive action? By making every feature, model output, and visualization traceable back to the KPI contract and the downstream playbook that will run when a threshold is crossed.
Start with modeling that targets a single operational decision rather than an abstract score. If the goal is to reduce churn for at-risk cohorts, build a model that predicts short-term churn within a defined window and outputs an intervention label and confidence band—those two outputs map to a routing rule and an experiment gate. Prefer interpretable models early (logistic regression, decision trees, calibrated probability models) so product and ops teams understand trade-offs; we can iterate to more complex architectures only after the operational surface and playbooks are validated.
Feature engineering should live in the same codebase as your transforms and metric definitions to preserve provenance and reproducibility. Create deterministic, timestamped features in the warehouse using windowed SQL (for example: ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY event_ts) to deduplicate, or SUM(amount) FILTER (WHERE event_ts BETWEEN start AND end) to compute recency features), and persist them as materialized feature views or in a feature store. This keeps feature computation idempotent, enables offline training against the exact production logic, and lets you trace model drift back to specific upstream schema changes.
Train, validate, and deploy with experiment gating and automated checks. Use holdout windows aligned to the business cadence (e.g., weekly cohorts) and validate calibration as well as ranking—if predicted probabilities are poorly calibrated, your playbook may misallocate interventions. Deploy models behind a feature-flagged control plane so you can A/B test rollback logic; instrument model metrics (prediction rate, input nulls, population shifts, decision outcomes) in the same monitoring stack as your KPIs so experiment results and model health share a single source of truth.
Design dashboards to make the decision obvious: front-load the action and the signal. Replace a single “model score” tile with three panes—a contextual KPI (e.g., seven-day retention), a model-driven segmentation (high/medium/low risk), and an actionability panel showing expected lift and cost per intervention. Use retention curves, funnel conversion by cohort, and lift charts where appropriate; these visual elements answer the questions stakeholders ask: Who will we act on? What is the expected impact? When should we trigger the playbook?
Implement dashboards as layered artifacts: fast, denormalized materialized views for near-real-time monitoring and slower, authoritative SQL for investigative analysis. For low-latency operational tiles use CDC or streaming ingestion into OLAP tables with refresh policies (for example, 1–5 minute windows), and back them with caching in the dashboard layer to control query cost. Include links to the underlying metric contract and the model version used for each tile so analysts can drill from a visual anomaly to the exact transformation and model that produced it.
Operationalize the loop: automate alerting on both KPI regressions and model-data drift, tie alerts to runbooks, and gate downstream product changes on experimented model outcomes. When an alert lands, your team should be able to answer who owns the metric, which model version produced the signal, and what the rollback or remediation path is. Taking this approach turns models and visual dashboards from passive reporting artifacts into a controlled decision system that executes the last mile of analytics and hands operators a clear, tested next step.
Turn insights into automated actions
Building on this foundation of metric contracts and reliable pipelines, the real payoff comes when validated signals automatically trigger the decisions you already defined. Last-mile analytics only scales when insights become automated actions that execute playbooks without human bottlenecks. We want automation to be auditable, reversible, and tied to the exact metric contracts you already documented so every automated change maps to measurable business outcomes and actionable business value.
Start by asking a simple question: what decision should the system make when a KPI crosses a threshold? That question forces you to write the control logic before you write any code. Define an experiment gate for each decision: the gate evaluates signal quality, statistical significance, and model health before allowing a downstream change. How do you prevent a transient spike from flipping production behavior? The gate must require stable signal for N periods and pass data-quality checks from the ingestion layer before it opens.
Implement the control plane as three coordinated layers: signal validation, decision logic, and execution. Signal validation re-runs the metric contract SQL and asserts row counts, null rates, and confidence intervals. Decision logic encodes the business rule—for example, IF seven_day_retention_cohort_lift > 0.06 AND p_value < 0.05 THEN enable_intervention. Execution maps the decision to an idempotent action (feature flag rollout, pricing change, routing update) and increments a ledger so you can audit who or what changed system state. Here’s a compact example of the decision logic in SQL and pseudocode:
-- materialized view: cohort_lift
SELECT cohort_date, lift, p_value
FROM cohort_results
WHERE cohort_date = current_date - 1;
# control rule (pseudo)
when:
- cohort_lift.lift > 0.06
- cohort_lift.p_value < 0.05
then:
- update_feature_flag: onboarding_intervention -> gradual_rollout(10%)
- create_experiment: id=onboard_incentive_ab_test
Make the execution layer resilient and observable. Use feature flags or API-driven configuration as the canonical mechanism for changes so rollbacks are instantaneous and versioned. For model-backed decisions, tie every execution to a model_version tag and a model_input_hash so you can trace a failed action back to the exact feature computation. Ensure idempotency by implementing safe-update semantics (PATCH or MERGE operations keyed by deterministic IDs) so retries or replayed events do not apply changes twice.
Automation must be gated by experiment and safety checks. Before an automated rollout, create a staged experiment: canary a 1% cohort, validate lift and monitor secondary metrics (fraud rate, latency, cost per action) for a predefined window, then escalate to larger cohorts only if all gates pass. Programmatically require both significance on the primary metric and no material regressions on guardrail metrics; codify these as automated test assertions that fail the pipeline if conditions aren’t met. This prevents optimizations that increase short-term conversions while harming long-term retention.
Operationalize ownership, runbooks, and throttles so automation becomes institutional rather than artisanal. Assign an owner to each automated rule, publish the playbook that describes remediation steps, and attach SLAs for investigation and rollback. Add rate limits and cost quotas to execution channels (email sends, push notifications, price updates) to control operational expense and avoid runaway automation when a bug slips through.
Taking this approach turns dashboards and models into an active control system rather than passive reports. By composing metric contracts, validation gates, experiment control, and idempotent execution, we close the loop: validated signals become automated actions that are auditable, reversible, and aligned to the business outcomes you defined earlier. In the next section we’ll build the experiment planes and orchestration patterns that let you test, iterate, and scale those automated playbooks across products and markets.
Pilot, measure impact, iterate rapidly
Building on this foundation, the fastest path from insight to impact is to run tightly scoped pilots that prove value before you scale. In last-mile analytics we prioritize experiments that map a single metric to a single decision so you can measure actionable business value quickly; that framing forces crisp hypotheses, cohorts, and time windows. Start each pilot by writing the decision logic, the metric contract, and the rollback criteria before you touch product code so measurement is non-negotiable. This discipline prevents hindsight-driven changes and keeps stakeholders aligned on what “success” looks like for the pilot.
Treat every pilot as an experiment with a prespecified analysis plan rather than an exploratory report. How do you run a pilot that proves value without a large investment? Define the target cohort size, canary percentage (for example, 1–5% initially), primary KPI, and at least two guardrail metrics up front, then instrument both production and control surfaces. Use leading indicators to get early signal—onboarding completion, feature engagement, or error rates—while reserving lagging metrics like revenue lift or retention for validation. We recommend recording stopping rules and minimum detectable effect so you don’t chase noise or stop too early.
Measurement rigor matters more than flashy dashboards: pre-register your metric computations and test your instrumentation with replayable smoke tests. Re-run the metric contract SQL against a snapshot of production data to validate row counts, null rates, and identity joins before you analyze results, and report confidence intervals and p-values alongside point estimates. For small pilots, prefer Bayesian credible intervals or sequential testing designs that let you make decisions without inflating Type I error from repeated peeks. Encoding these checks into CI for your ETL and model pipelines shortens the feedback loop and gives you repeatable, auditable measurements for every experiment.
Observability and lineage are the infrastructure of rapid iteration—if you can’t trace a lift back to an event and transform, you can’t act confidently. Surface data-quality metrics in the operational dashboard (schema version, ingestion lag, sample hashes) and link each KPI tile to its metric contract and source-views so analysts can drill into anomalies immediately. Make the instrumentation idempotent and the dashboards refresh at a cadence aligned with the KPI’s SLA; for operational decisions that means near-real-time tiles, for strategic validation daily or weekly aggregates are fine. Assign metric owners who are responsible for triage playbooks when an alert fires so iteration isn’t blocked by ambiguity.
Iterate with short cycles and safe rollouts: use feature flags for reversible changes, run canary cohorts, and measure guardrail metrics automatically. When an experiment shows promising leading-indicator lift, escalate to a staged rollout (1% → 5% → 20%) with automated gates that check significance, model health, and secondary impacts before each increase; if any gate fails, the flag rolls back. For example, when we tested an onboarding rearrangement, we used a 3-week progression keyed to seven-day activation and one-month retention, rolling back immediately when an unexpected churn signal appeared in a secondary cohort. These patterns let you move fast while protecting long-term value.
Operationalize learnings by converting successful pilots into control-plane rules and playbooks that execute deterministically. Tie each automated action to the metric contract, model_version, and a small audit ledger so every change is reversible and attributable; attach SLAs and runbooks to the owner so remediation is immediate when regressions appear. Taking this approach turns one-off experiments into repeatable decision primitives you can push across products and markets, and sets up the next step where we build the experiment orchestration and control-plane tooling necessary to scale these patterns reliably.