March 2026 market snapshot
Voice assistant adoption hit a practical inflection point in early 2026: buyers stopped choosing devices on price alone and started buying for platform longevity, on-device intelligence, and privacy guarantees. In the last 12–18 months the conversation shifted from “which speaker sounds better” to “which assistant can run core automations offline, keep data local, and receive guaranteed OS updates,” and that shift is driving premium replacement cycles and new upgrade models. This matters for you because product decisions now have to balance compute, latency, and lifecycle commitments rather than raw feature lists. (alibaba.com)
Market concentration tightened around a small set of platforms while software and services captured growing value. Leading vendors hold the majority of shipments and the conversation centers on ecosystem lock‑in (voice assistant APIs, smart‑home hubs, identity linking) and long‑term revenue from subscriptions and services. Analysts report double‑digit market expansion year‑over‑year and forecast multi‑billion dollar growth in voice assistant and smart speaker markets as software monetization outpaces hardware margins, so your go‑to‑market should emphasize recurring value and cross‑device continuity. (mordorintelligence.com)
On‑device multimodal inference and modular hardware are no longer academic experiments — they’re shipping differentiators. Vendors are embedding larger local models and sensor fusion pipelines so assistants can reason about ambient audio, presence, and user intent without an immediate cloud round trip; device announcements in 2026 highlight agentic features that run on-device for latency, reliability, and privacy-sensitive tasks. That trend changes engineering tradeoffs: you’ll evaluate model quantization, edge accelerators, and upgradeable compute modules alongside traditional metrics like DSP performance and microphone array geometry. (apnews.com)
Enterprise and vertical deployments are maturing into repeatable use cases beyond simple IVR and home automation. Retail kiosks, healthcare voice triage, and in‑car assistants now emphasize session continuity, identity-aware responses, and secure audit trails; organizations expect vendor SLAs for data residency and deterministic offline behaviors. If you’re building or integrating voice capabilities, ask: How do you evaluate when to offload inference to the cloud versus keeping intent resolution on device, and what telemetry will you expose to maintain observability without violating privacy constraints? Practical pilots that measure latency, failure modes, and error‑recovery semantics are the fastest path to production. (globalgrowthinsights.com)
Privacy and safety are the friction points that will determine who wins the next phase of scale. New benchmarks and research are explicitly testing interactional privacy — the ability of speech models to respect multi‑user contexts, secrets, and conditional silences — and results show substantial gaps in both open‑source and closed solutions. That means product teams must bake in speaker‑aware policies, selective logging, and auditable decision rules rather than treating privacy as a compliance add‑on. Investing in privacy‑first model evaluation and user control surfaces reduces regulatory risk and builds trust that drives longer device retention. (arxiv.org)
Taken together, March 2026’s market snapshot points to clear engineering priorities: design for on‑device resilience, architect services for long lifecycle support, and validate privacy properties under real multi‑user conditions. For teams shipping voice experiences, the immediate next step is to run short, high‑fidelity pilots that measure edge inference cost, end‑to‑end latency, and privacy failure modes; those metrics will separate tactical demos from deployable products. Building on this foundation, the next sections will deep‑dive into implementation patterns and toolchains that make those pilots repeatable and scalable.
Core technologies overview
Building on this foundation, the technical backbone of modern voice platforms centers on three intersecting vectors: robust audio front-ends, compact inference runtimes, and privacy-first telemetry. If you’re designing or evaluating a voice assistant today, prioritize how those vectors interplay rather than treating them as separate features. Edge AI and on-device inference aren’t optional add‑ons any more; they are primary architectural constraints that determine latency, resilience, and user trust. The choices you make here shape product lifetime, update strategies, and ultimately which customers keep your devices for years.
The capture and pre‑processing pipeline is where most user experience wins and losses happen. Start with microphone array geometry, beamforming, and wake‑word/voice‑activity detection that are tuned to real acoustic environments — these DSP stages reduce false wakes and shrink the workload for downstream models. From there, the pipeline splits: some systems stream audio to cloud ASR and NLU, while robust products push speech-to-text and intent resolution into local runtimes to reduce RTT and preserve privacy. Recent silicon and device announcements demonstrate meaningful gains in NPU throughput and power efficiency that make this hybrid on-device inference model viable for consumer hardware. (androidcentral.com)
Model design and deployment patterns now focus on compression, hybrid execution, and modular upgrades. You’ll use quantization-aware training, activation‑aware weight quantization (AWQ), and operator fusion to get large language or dialog models into memory‑constrained environments, then selectively offload heavier ops to the NPU or an FPGA-like accelerator when available. This hybrid strategy — small model on CPU for control flow, big model kernels on accelerator — reduces energy per inference and simplifies OTA update surfaces. Practical projects already show that careful model compression plus hardware acceleration lets you run complex dialog agents locally without prohibitive latency. (arxiv.org)
Multimodal sensing and sensor fusion are the features that move assistants from reactive to contextual. Combine audio VAD with presence detection (ultrasonic, IR, or BLE), short‑window ASR, and compact vision or IMU signals to make decisions locally: when to start a session, which persona to use, or whether to redact a response. This fusion reduces cloud round trips for routine automations and supports richer offline behaviors that users notice as reliability. Several device initiatives in 2025–26 explicitly prioritized on‑device multimodal agents and ambient intelligence, demonstrating the engineering pattern of co‑designing sensors, firmware, and model stacks. (androidcentral.com)
Privacy engineering must be baked into model, pipeline, and telemetry choices rather than bolted on afterward. Ask how your system enforces interactional privacy (speaker‑aware policies), which signals are logged, and whether anonymization preserves utility for intent detection. Benchmarks published in 2026 highlight widespread gaps in conditional privacy decisions by speech models and show clear paths to improvement through fine‑tuning and feature‑level protections; practical mitigations include selective logging, local redaction, and using privacy‑aware audio features that limit speaker attribute leakage. Treat these mechanisms as testable artifacts in your CI pipeline, with automated privacy regression tests. (arxiv.org)
How do you decide when to run models locally versus in the cloud? Use measurable thresholds: target end‑to‑end latency budgets for critical flows (for example, sub‑150ms for real‑time confirmations), cost per inference at expected scale, failure‑mode tolerance, and regulatory requirements for data residency. Instrument pilots to measure real traffic distributions, power profiles, and error recovery economics; then codify a hybrid policy that routes complex, non‑safety‑critical reasoning to cloud models while keeping low‑latency, privacy‑sensitive, and safety‑critical intents local. That policy — plus modular compute and a reliable OTA upgrade path — is what makes a voice product durable in 2026 and beyond.
On-device and multimodal advances
Building on this foundation, engineers are shifting from cloud-first voice architectures to designs that treat on-device intelligence and multimodal sensing as first-class citizens. The hard win today is reducing round-trip dependencies while preserving rich contextual reasoning — we do this by pushing more of the inference pipeline onto the device and by fusing lightweight visual, IMU, and proximity signals with short-window ASR. That combination improves latency, resilience, and privacy while forcing tradeoffs around memory, power, and upgradeability that you must quantify early. If you haven’t reevaluated your latency and power budgets for edge inference in 2026, you’re already behind the realistic product constraints your competitors are shipping against.
Sensor co-design is the practical step that converts theoretical multimodal gains into real user value. Start by defining which modality resolves a common failure mode: use an IR presence sensor or BLE beacon to gate wake-word confidence; use a low-resolution camera or optical flow for face-aware persona selection; and use a short-window ASR model to confirm intent before invoking heavier pipelines. Co-design means you tune firmware, DSP, and model inputs together rather than treating the sensor as an afterthought — beamforming parameters, VAD thresholds, and downsampled image encoders all change model behavior in predictable ways. This reduces false-positive sessions and keeps compute budgets focused on high-value inference.
Model engineering at the edge is now as much about compilation and execution topology as it is about architecture. We compress large models with quantization-aware training and activation-aware weight quantization, then split execution: a tiny control model runs on CPU for routing and safety checks, while NPU kernels execute heavy transformer blocks when available. Implement a simple runtime router like this pseudocode to decide execution path based on confidence, power state, and network availability:
if confidence_high and npu_available and battery_ok:
run_on_npu(heavy_model)
else:
run_on_cpu(control_model)
That pattern keeps safety-sensitive logic local and only uses accelerators or cloud resources when justified by measurable policy criteria.
Shipping durable devices requires modular compute and predictable OTA model management. Treat each model as a versioned artifact with a manifest that lists quantization format, hardware target, and a rollout policy; design your updater to allow rollback to a prior model and to throttle activations for power spikes. When you separate model binary packaging from the firmware that interfaces with sensors, you enable replaceable compute modules and longer product lifecycles without retooling the entire device. This architecture also simplifies compliance audits because you can attest a deterministic offline behavior for a given model manifest — a requirement many enterprises and regulated verticals now demand.
Privacy and safety become active engineering constraints rather than checkbox items. How do you validate that on-device multimodal inference doesn’t leak speaker attributes or private context? We run adversarial attribute-inference tests, synthetic membership probes, and privacy-regression benchmarks during CI that treat leakage metrics as first-class failure conditions. Implement selective logging and local redaction: only log feature hashes, aggregated confidence distributions, or differentially private summaries for telemetry; keep raw waveforms and images local unless explicit user consent is recorded. These practices reduce regulatory risk and improve user trust, which directly influences retention for premium devices.
Observability for edge agents must balance debuggability with minimization of sensitive telemetry. Instrument latency, energy-per-inference, confidence scores, and error rates at the API boundary, but anonymize or aggregate traces before they leave the device. For incident debugging, implement an encrypted, user-consent workflow that permits temporary upload of redacted traces to a secure backend; ensure every upload is auditable and reversible. That approach gives you operational insight without compromising interactional privacy.
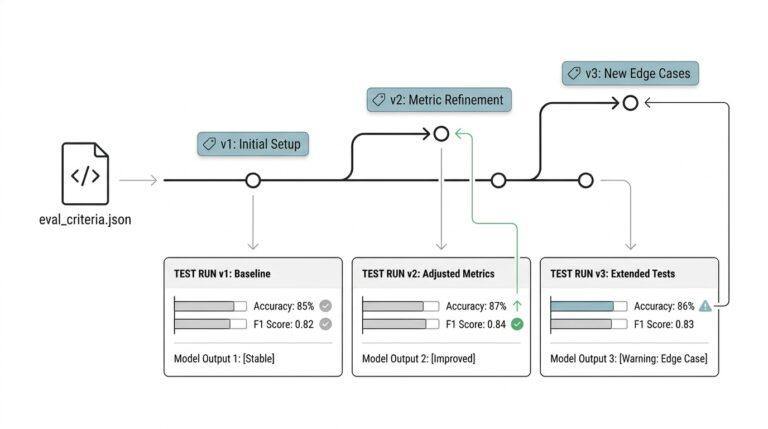
Pilot measurement is the shortest path from lab results to product-grade behavior. Run short, high-fidelity pilots that measure end-to-end latency, power draw at typical duty cycles, and privacy-failure modes across realistic noise and multi-user scenarios; use those metrics to codify hybrid routing policies and OTA rollouts. Taking this concept further, the next section will walk through toolchains and CI patterns that make those pilots repeatable, testable, and safe to scale.
Privacy, security, and compliance
Building on this foundation, product decisions in 2026 are decided as much by privacy as by latency — privacy, security, and compliance now shape architecture and go‑to‑market risk. You face buyers and enterprise customers who demand deterministic offline behavior, auditable decision trails, and provable data residency; those requirements force tradeoffs in model placement, telemetry design, and OTA policies. Start by treating privacy and security as first‑class constraints during design reviews, not as post‑hoc checkboxes, because that mindset change reduces rework and regulatory exposure down the line.
Interactional privacy is the operational problem you must solve: distinguishing who spoke, when to withhold a response, and what context is safe to share. We push short‑window ASR and intent resolution on‑device to keep sensitive payloads local, and we gate cloud calls with adaptive policies that check user consent, intent sensitivity, and network state. On‑device inference reduces round trips and attack surface, but it also requires you to harden local storage and to prove that models cannot be queried in ways that leak private attributes; design reviews should include adversarial attribute‑inference test cases as part of the acceptance criteria.
Concrete controls matter more than high‑level promises. Implement selective logging that stores only salted feature hashes, confidence distributions, and event counters instead of raw waveforms or images; pair that with local redaction primitives that drop or pseudonymize identifiers before anything leaves the device. Use differential privacy for aggregate telemetry to enable analytics without membership leakage, and record consent events as signed, versioned artifacts so you can recreate the consent state for any audit. What does this look like in practice? Build a small middleware layer between your audio pipeline and telemetry sink that enforces redaction rules and applies cryptographic salts before export.
Security engineering needs to cover the model lifecycle as well as the firmware stack. Require signed model manifests, secure boot, and hardware attestation so the device can reject tampered binaries or unapproved rollouts. Validate updates with a simple manifest verification pattern before activation:
manifest = download_manifest()
if verify_signature(manifest.signature, vendor_pubkey):
stage_model(manifest.uri)
else:
abort_update()
Enforce encrypted model storage and runtime protections (memory encryption, limited IPC surface) for models that handle sensitive intents; require remote attestation for any cloud‑offloaded execution and log attestations as part of the audit trail.
Compliance is operational, not theoretical. Map each data flow to a control objective (data residency, retention window, purpose limitation) and codify those objectives into deployable artifacts: model manifests that declare residency, telemetry policies tied to region, and retention counters that automatically purge older artifacts. For enterprise customers demand SLAs that include reproducible offline behavior and forensic access paths; these contractual artifacts make audits tractable and reduce the chance of expensive remediation later.
Observability without overexposure is a solvable engineering problem. How do you debug incidents when you can’t ship raw audio? Instrument API boundaries with high‑cardinality metadata (timestamps, hashed session IDs, confidence vectors, CPU/NPU load) and pair that with a reversible, consented upload workflow: the user or admin can authorize a time‑limited, encrypted upload of redacted traces for debugging, and every upload is logged and reversible. Treat debugging uploads as feature flags in your backend so you can revoke access and audit who viewed sensitive traces.
We make privacy testable by baking it into CI and pilots. Add privacy regression tests that run adversarial membership probes, attribute‑leakage checks, and selective logging validation on every model change; gate rollouts on violation thresholds. Run short, high‑fidelity pilots across realistic noise and multi‑user scenarios to measure false‑wake leakage and consent flow failures, then codify your hybrid routing policy from those metrics. Taking this approach makes privacy, security, and compliance measurable and repeatable—and sets up the toolchains you’ll need for scalable, auditable deployments in the next section.
Developer tools and SDKs
Building on this foundation, modern tooling has become the deciding factor between a prototype that stays in a lab and a voice assistant that survives messy real-world conditions. Developer tools and SDKs now determine whether you can run key flows on-device, validate privacy properties, and push safe OTA updates without bricking hardware. In practice, the right toolchain reduces latency and operational risk by giving you deterministic manifests, signed artifacts, and repeatable emulation for both CPU and NPU targets. We’ll show patterns you can apply directly to pilots and CI so your next rollout is measurable rather than hopeful.
Picking an SDK or runtime is not just about API ergonomics; it directly shapes latency, power, and regulatory posture. Evaluate SDKs for three technical constraints up front: supported hardware targets (arm cores, NPUs, accelerators), quantization formats and operator coverage, and the update/manifest model they require. Focus on whether the SDK exposes deterministic inference traces and confidence scores you can surface to on-device privacy tests, because those signals are what let you gate cloud calls and enforce selective logging. When an SDK lacks transparent runtime telemetry, you’re blind to most production failure modes.
How do you pick the right SDK for a constrained device? Start by profiling a representative inference on your target silicon and measure end-to-end latency, energy per inference, and memory high-water marks under realistic duty cycles. Prefer SDKs that publish or allow custom model manifests (declaring quantization, hardware targets, and rollout policies) and that implement secure model activation (signature checks and staged rollouts). Choose tooling that supports local emulation and hardware-in-the-loop (HIL) testing so you can reproduce field regressions before they reach customers. If you can’t reproduce a failure on a dev box, you can’t learn from it.
The practical developer tools you’ll use fall into three layers: model compilation and optimization, runtime integration, and CI/observability. Use compilers that support quantization-aware conversion and operator fusion so your model maps cleanly to the device runtime; prefer runtimes that expose per-operator timing and memory metrics. For integration, pick SDKs with clear sensor APIs and low-latency audio hooks so your beamforming, VAD, and short-window ASR can hand off structured features to the model runtime without copy overhead. These choices make it feasible to run meaningful on-device inference while keeping the cloud for heavy or privacy-tolerant reasoning.
Operationalizing toolchains means treating models like software packages and wiring them into CI/CD the same way you do firmware. Define a manifest format that lists runtime ABI, quantization format, cryptographic signature, and a rollback pointer; validate manifests in CI and run privacy regression tests (attribute leakage, membership probes) as gated checks. Implement canary rollouts that throttle activation of new model binaries to a subset of devices and require signed consent for debug trace uploads. Instrument anonymized telemetry (latency, confidence vectors, CPU/NPU load) at the API boundary so you can debug regressions without shipping raw audio.
For a concrete example, imagine shipping an in‑car assistant that must confirm high-value intents with sub‑150ms latency while preserving driver privacy. Use a compiler-backed toolchain to condense the short-window ASR and intent model to the vehicle NPU, integrate a local sensor gating SDK to reduce false wakes, and enforce a manifest-driven OTA that can roll back a model if privacy regression tests fail. This approach turns developer tools and SDK choices into product levers: they control durability, observability, and compliance. Taking these patterns further, the next section will show how to embed privacy tests into CI pipelines and run high‑fidelity pilots that prove your hybrid routing policy at scale.
Enterprise and consumer use cases
Building on this foundation, the commercial split between enterprise and consumer deployments is no longer academic — it’s where engineering tradeoffs turn into contracts, device SKUs, and retention curves. Enterprises prioritize determinism: auditable decision trails, data residency, and SLAs that promise reproducible offline behavior. Consumers prize seamlessness and trust: fast local automations, consistent cross‑device continuity, and clear privacy controls. These differing priorities force distinct architectures, rollout policies, and observability designs for any modern voice assistant product.
Enterprise projects demand identity‑aware sessions and forensic-grade logs without sacrificing privacy. In practice, that means we design a layered control plane: local short‑window intent resolution for safety‑critical or privacy‑sensitive intents, and a gated cloud path for complex reasoning or analytics. Instrumentation must expose latency, confidence vectors, and CPU/NPU load while logging only salted hashes or aggregated metrics to meet compliance. For regulated verticals like healthcare or finance, you should require signed model manifests, secure boot, and auditable attestations as contractual features — customers will treat those as table stakes rather than optional enhancements.
Consumer experiences emphasize low friction, long device lifecycles, and user‑centric privacy. Optimize for on‑device responsiveness: push wake‑word, VAD, and short‑window ASR locally so common automations finish within perceptual latency budgets. Combine that local pipeline with consented cloud enhancements for personalization or heavy LLM reasoning, and give users transparent controls to toggle what’s stored or uploaded. Premium replacement cycles now favor products that guarantee OS and model updates for years, so architect OTA manifests and modular compute so you can extend device value instead of forcing replacements.
When should you offload intent resolution to the cloud versus keeping it on‑device? Use measurable thresholds: route to cloud when model confidence drops below a defined threshold (for example, confidence < 0.7 for non‑safety intents), when the task requires long‑context reasoning beyond the device’s memory envelope, or when a user has explicitly opted into cloud personalization. Conversely, keep confirmation flows, authentication prompts, and safety checks local to meet sub‑150ms budgets and to reduce attack surface. Codify these policies in a runtime router that factors in confidence, battery, network state, and regulatory region so behavior is deterministic and testable.
Multimodal sensing is a differentiator for both markets but the gating logic differs. For enterprise kiosks and in‑vehicle systems we fuse camera or IMU signals with audio to enable identity‑aware responses and session continuity; but we expose only derived features (presence, hashed session IDs, persona token) into telemetry. For consumers, multimodal inputs reduce false wakes and improve automation reliability — a BLE beacon or IR presence sensor can gate sensitive replies so you avoid embarrassing or risky disclosures. Design sensor fusion pipelines to fail gracefully: if a modality is absent, fall back to audio‑only heuristics rather than blocking the user.
Operationalizing these use cases requires pilot metrics that map directly to product KPIs. Run short, high‑fidelity pilots that measure end‑to‑end latency distributions, power consumption under expected duty cycles, and privacy failure modes such as false attribution or unintended uploads. Use canary rollouts with staged model activation and reversible manifests so you can roll back if privacy regression tests or telemetry spikes occur. For enterprise customers, include forensic access flows and time‑limited consented debug uploads as part of the SLA so you can troubleshoot incidents without broad data exposure.
Taking this concept further, your go‑to‑market should package these technical guarantees as features: deterministic offline behavior, signed manifests, modular compute pathways, and auditable telemetry policies. These are the levers that convert engineering tradeoffs into commercial differentiation for both enterprise deployments and consumer retention. In the next section we’ll dig into CI patterns and toolchains that make those pilots repeatable and safe to scale.