What are LLMs?
Building on this foundation, we need to be explicit about what LLMs are and why they matter for natural language processing workflows. Large language models (LLMs) are neural networks trained at scale to model probability distributions over sequences of tokens; in practice, that means they predict the next token given context and thereby generate coherent text, translate, summarize, or answer questions. When we say “large,” we refer both to model capacity (parameters, layers) and to the breadth of pretraining data that covers diverse domains; these two axes drive capability and generalization. Understanding this core definition helps you reason about where LLMs fit into a system architecture and when they provide leverage over traditional NLP pipelines. Early clarity about purpose prevents misapplying them as catch-all tools for problems better solved by deterministic logic or domain-specific models.
At the architectural level, most modern LLMs are based on the transformer pattern, which centralizes self-attention to compute context-aware representations of tokens. Self-attention lets the model weigh relationships between any pair of tokens in a sequence, so it captures long-range dependencies that RNNs or bag-of-words models struggle with; embeddings convert discrete tokens into continuous vectors that the transformer processes. This design explains why transformers scale well with data and compute: adding layers and width typically improves representation quality and emergent behaviors. When engineering for production, you should treat tokenization, sequence length, and attention complexity as first-class constraints because they directly impact latency and memory. Choosing the right tokenizer and maximum context length often buys you more practical benefit than marginal parameter increases.
Training dynamics matter for capabilities and failure modes. LLMs are usually pretrained on unsupervised objectives like next-token prediction or masked-language modeling across web text, code, books, and technical docs; that broad pretraining yields broad linguistic competence and few-shot generalization. After pretraining, we often apply task-specific fine-tuning, instruction tuning, or reinforcement learning from human feedback (RLHF) to align behavior with human preferences and safety policies. These sequential stages—pretrain, tune, align—are why you see different behavior from base models versus instruction-following variants. Keep in mind that scale and data quality both contribute to emergent capabilities, but scale amplifies both strengths and weaknesses, so larger models can produce surprisingly creative answers and confidently wrong ones.
How do LLMs actually generate text, and what causes hallucinations? At inference, the model converts context into logits over the token vocabulary, then samples or selects tokens using strategies such as greedy decoding, beam search, or temperature-controlled sampling; these choices shape creativity versus determinism. Hallucinations occur when the model’s learned distribution over tokens prefers plausible-sounding continuations that are not grounded in factual sources—this is a statistical, not malicious, failure mode. To reduce hallucination in applications, we use grounding strategies: retrieval-augmented generation (RAG) to pull facts from trusted databases, constraint mechanisms to enforce structured outputs, and token-level calibration techniques during decoding. Monitoring generation quality with factuality metrics and human review loops is essential for deployed systems.
In practical engineering work, you’ll use LLMs for a predictable set of high-value tasks: summarization of long documents, question-answering over indexed corpora, code generation and transformation, and conversational assistants that orchestrate workflows. You’ll often combine an LLM with embeddings and a vector store to implement retrieval: compute embeddings for chunks, run nearest-neighbor search for relevant context, then pass those passes to the model for grounded responses. A minimal retrieval pattern looks like: ctx = retrieve(similarity(embed(query), store)); answer = model.generate(ctx + query)—that pattern dramatically improves accuracy for domain-specific knowledge. For code-heavy workflows, integrate static analysis or unit tests as post-filters to validate generated code before it reaches production.
Operational concerns determine whether you should deploy an LLM at all. Consider latency, cost per token, model size, and privacy obligations when choosing hosted versus self-hosted inference; implement throttling, caching, and prompt optimization to control expenses. We recommend end-to-end monitoring that tracks latency, token consumption, hallucination rate, and user satisfaction, and set up rollback paths when model updates degrade behavior. When you select between rule-based, smaller supervised models, and LLMs, let the decision be guided by data variability, need for generative fluency, and the importance of verifiable outputs. Next, we’ll take these ideas into a concrete implementation pattern so you can evaluate trade-offs for your own applications.
How LLMs Work
Building on this foundation, we should unpack the mechanics that turn statistical pattern matching into fluent, context-aware outputs. At a systems level, large language models are transformer-based networks that convert token sequences into a series of continuous representations and then map those representations back to probability distributions over the vocabulary. This conversion pipeline — tokenizer → embeddings → transformer layers → logits → decoding — is where engineering decisions (tokenizer choice, context length, decoding strategy) materially affect latency, cost, and output quality.
The core computation inside the transformer is self-attention, implemented as query, key, and value projections followed by a scaled dot-product and softmax. Self-attention scores tell the model which tokens to weight for each output position, and multi-head attention lets the network attend to several relationship patterns in parallel; residual connections and layer normalization stabilize training across deep stacks. Positional encodings (sinusoidal or learned) inject order information so the model can distinguish “cat sits on mat” from “mat sits on cat,” and the feed-forward sublayers provide per-token nonlinearity that increases representational capacity.
Embeddings are the surface where discrete tokens meet continuous geometry: words, subwords, and code tokens become vectors whose distances and directions encode semantic relations and compositional structure. Those vectors let us do practical engineering tricks like nearest‑neighbor retrieval for context selection or clustering to detect topic drift in a conversation. Because tokenization alters the granularity of those embeddings, your choice of byte-pair, unigram, or byte-level tokenizer changes both memory use and the model’s handling of rare or domain-specific terms.
At inference time the transformer produces logits that we convert to probabilities with softmax and then choose tokens via greedy, beam, top-k, top-p, or temperature-controlled sampling. How do you control model creativity versus reliability? Lower temperature and constrained decoding favor repeatable, conservative answers; higher temperature and nucleus sampling increase diversity but also hallucination risk. For grounded accuracy in production, pair decoding choices with retrieval-augmented generation and constraint layers so the model writes from vetted context rather than inventing plausible facts.
The post‑pretrain stage shapes behavior as much as raw scale. Supervised fine-tuning teaches task-specific mappings, instruction tuning standardizes prompt-response behavior, and reinforcement learning from human feedback aligns outputs to human preferences via a learned reward model and policy optimization. When you need model updates without full tuning, parameter‑efficient techniques such as adapters, prompt tuning, or LoRA (low‑rank adaptation) let you inject domain knowledge with orders-of-magnitude less compute and storage, though with some tradeoffs in peak performance and robustness.
Serving considerations change how the model behaves in the real world. Attention has O(n^2) memory and compute in sequence length, so longer contexts increase cost nonlinearly; mitigations include sliding windows, chunking with retrieval, and sparse or linearized attention approximations. Practical inference optimizations—quantization to int8/4-bit, fused kernels, KV-caching for autoregressive generation, and optimized attention kernels—reduce latency and memory footprint. You should also batch requests where possible and implement cache invalidation and prompt compression to control token consumption.
For engineers building with these models, the immediate takeaway is to instrument and validate aggressively: add factuality checks, unit tests for generated code, and human-in-the-loop review where risk is high. We recommend building a small, reproducible prompt-test suite that exercises edge cases and integrates retrieval or static checks as part of the pipeline. These mechanics — how embeddings, attention, decoding, and tuning interact — determine whether a large language model delivers reliable automation or merely plausible-sounding prose; the next section will walk through a concrete retrieval-plus-inference pattern you can deploy and measure.
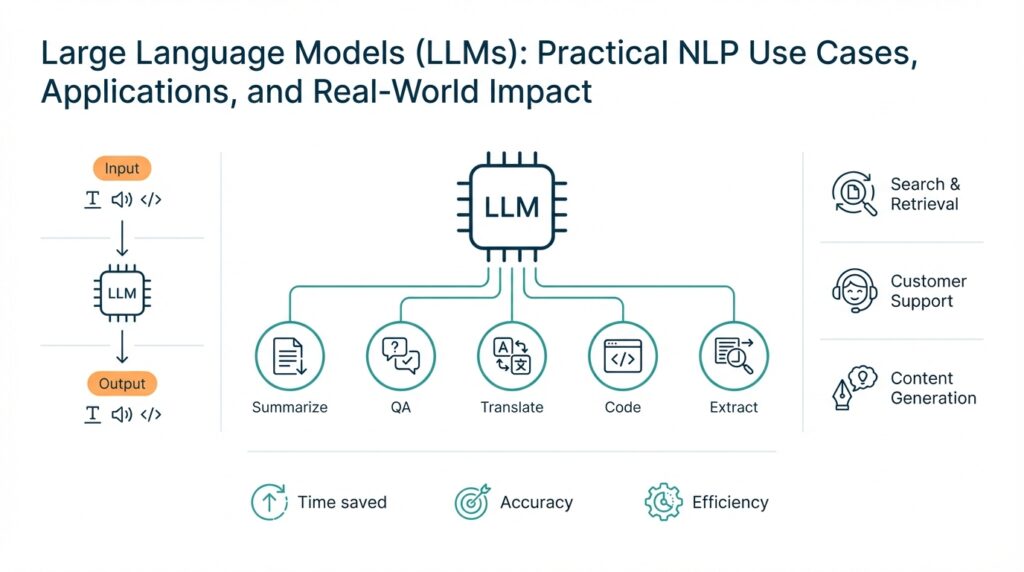
Practical Use Cases
Building on this foundation, think first about value: where do large language models deliver measurable ROI versus existing processes? In practice you reach for LLMs when a task needs generative fluency, cross-document synthesis, or conversational orchestration at scale—examples include multi-document summarization, developer-facing code transforms, and enterprise Q&A over siloed knowledge. How do you choose which use case should use an LLM versus a deterministic pipeline? Ask whether you need semantic generalization (for which LLMs and embeddings excel) or strict, verifiable outputs (for which rule-based systems remain better).
One high-impact pattern is document understanding and summarization for long-form content. Instead of feeding the entire file into a single prompt, we chunk documents, index embeddings for each chunk, and apply retrieval-augmented generation only with the top-k relevant passages; this limits hallucination and keeps token costs predictable. In production, enrich chunks with metadata (source, timestamp, confidence) and pass those alongside the query so the model can cite context. A pragmatic pipeline looks like: compute embeddings for chunks, perform neighbor search in the vector store, assemble cited context snippets, then prompt the model to synthesize a concise summary with explicit citation markers—this improves traceability and auditability for downstream users.
For code generation and transformation, LLMs are powerful assistants but they must be integrated with developer workflows and verification gates. We use LLMs to scaffold tests, refactor functions, or generate API clients, then run static analysis, type checks, and test suites as automated post-filters before merging. For example, generate a patch, run mypy and pytest in a sandbox, and reject or flag changes that fail checks; that enforces correctness and reduces review friction. When transforming large codebases, prefer iterative, small-change prompts and include the repository context that matters to avoid scope creep and brittle edits.
Conversational agents and orchestration expose another practical use case: LLMs as coordinators that call tools and APIs rather than owning every action. In this mode the model decides intent and delegates execution to deterministic services—calendar APIs, billing systems, or custom microservices—while the orchestration layer validates and logs each step. Implement function-calling semantics or a structured-output contract so the model emits a predictable JSON action the runtime can parse, execute, and confirm back to the user. This pattern keeps sensitive operations auditable, reduces hallucination risk, and separates language understanding from side-effectful operations.
Enterprise search and question-answering over internal knowledge is where embeddings and vector search unlock day-to-day productivity gains. Combine a lightweight lexical retriever (BM25) with semantic nearest-neighbor search to capture both exact matches and conceptual relevance; rerank candidates by relevance and freshness before generation. To maintain factuality, ground every generated answer with source snippets and surface provenance in the response: the model should return both the synthesized answer and a list of source IDs or excerpts. Monitoring here focuses on retrieval recall, hallucination rate, and user feedback loops so you can iteratively improve chunking strategies, encoder models, and refresh cadence in the vector store.
Across these practical cases, operational trade-offs decide success: latency, cost per token, privacy, and evaluation metrics. We recommend instrumenting pipelines to track end-to-end accuracy, token usage, and failure modes, and to build small prompt-test suites that exercise edge cases before broad rollout. Taking this concept further, the next practical step is implementing a compact retrieval-plus-inference pattern you can deploy and measure—there we’ll walk through concrete code patterns, cost controls, and monitoring hooks so you can move from prototype to production with confidence.
Data Preparation and Retrieval
Building on this foundation, robust data preparation and retrieval are what turn a capable model into a reliable system: if your embeddings and vector store are noisy or poorly organized, retrieval-augmented generation will only amplify errors. You should treat preprocessing, chunking, and indexing as engineering problems with measurable SLAs rather than ad-hoc steps. How do you choose chunk sizes, embedding models, and retrieval heuristics that balance recall, latency, and token cost? The short answer is to design for the model’s context window, instrument retrieval quality, and iterate with real queries rather than assumptions.
Start with disciplined chunking and canonicalization. Decide chunk size by your model’s context length—for an 8k-token model, create chunks roughly 800–2,000 tokens with 15–30% overlap so you preserve sentence and paragraph boundaries; for a 2k-token model, shrink chunks and increase overlap to prevent context breaks. Normalize text (Unicode NFKC), remove noise like duplicated headers or OCR artifacts, and preserve structural markers (headings, timestamps, code fences) as metadata so you can later bias retrieval by section. Use a deterministic splitter tied to document structure rather than blind character limits; that reduces fragmentation and improves retrieval precision.
Choose and version embedding models intentionally. Embeddings are your semantic keyspace, so evaluate models for domain alignment: general-purpose embeddings work well for broad web text, but domain-adapted models are often necessary for legal, medical, or code-heavy corpora. Keep embedding dimensionality and model versions in metadata and treat re-embedding as a planned operation—store a version tag so you can roll back or compare similarity changes. Deduplicate by hashing normalized chunk text and drop near-duplicates before indexing; this conserves storage and prevents the model from overcounting the same evidence.
Design a hybrid retrieval pipeline rather than relying on a single signal. Combine a fast lexical retriever (BM25 or simple inverted index) with vector nearest-neighbor search to capture both exact matches and semantic relevance; retrieve a broad candidate set (e.g., top‑50) via vector search, then rerank the top 5–10 using a cross-encoder or a learned relevance model for higher precision. Apply MMR (maximal marginal relevance) when you want diverse coverage instead of clustered repeats. A practical pattern is: retrieveCandidates = vector.search(query, k=50); ranked = crossEncoder.rerank(retrieveCandidates, query, topK=5); assemble(ranked).
Operationalize freshness and incremental updates. Implement upsert semantics so you can add or update individual chunks without full reindexing; tag vectors with timestamps and shard by document or namespace for fast removal. Define a refresh cadence based on content volatility—daily for news, weekly for docs, or event-driven for CI/CD artifacts—and measure embedding drift by sampling recall over known queries after each re-embed. Track recall@k and MRR on a held-out query set, and add latency and cost budgets as first-class metrics so retrieval quality improvements don’t blow your production constraints.
Assemble context for the model with rigor: limit token budget by trimming and compressing snippets, include provenance (source id, offset, score), and order evidence by combined relevance and recency. Use contextual compression (short summaries of chunks) when raw snippets exceed budget, and include explicit instructions in prompts to cite source IDs and not hallucinate beyond provided passages. This makes downstream outputs auditable and simplifies debugging when the model attributes incorrect facts.
Test retrieval like you test code. Build a small suite of synthetic, adversarial, and high‑value queries that exercise edge cases—ambiguous queries, partial matches, and requests requiring multi‑chunk synthesis—and run them as part of CI to catch regressions after model or data changes. Log query traces, retrieved IDs, and reranker scores so you can reproduce failures; add caching for hot queries and conservative TTLs to keep costs predictable. Taking these steps prepares you to implement a retrieval-plus-inference pattern that is measurable, maintainable, and ready for production.
Prompt Engineering Techniques
Building on this foundation, effective prompt engineering is less about clever wording and more about architecting reliable interfaces between humans, retrieval, and LLMs. Prompt engineering—designing the input you give a language model so its outputs are predictable and useful—becomes a systems problem when you combine context windows, retrieval-augmented generation, and decoding choices. Early in the prompt we should set role, constraints, and desired structure; for example start with a compact system role like: “You are a strict summarizer. Return JSON with keys title, summary, sources.” That front-loads intent and makes downstream parsing deterministic, which is critical when you must enforce provenance or run automated post-filters.
When you craft few-shot examples, treat them as executable tests rather than decorative samples. Include 2–4 curated examples that mirror edge cases in your corpus and label them with input, expected output, and failure mode; this nudges an instruction-tuned LLM toward the behavior you want without additional fine-tuning. For code or structured outputs, show both correct and incorrect examples and explicitly annotate why one is wrong; models generalize from contrastive examples. How do you structure prompts to reduce hallucinations? Combine concise examples with a retrieval context that contains short, high‑precision snippets and an explicit instruction: “Cite only provided sources; if none suffice, answer ‘Insufficient context.’”
Use templates and programmatic composition to keep prompts maintainable and testable. Parameterize variable parts—user query, top-k retrieved snippets, timestamp, and token budget—and assemble the final prompt from a template that enforces length limits. Implement prompt compression: replace long snippets with one-sentence summaries generated by a smaller model or your own summarizer before sending them to the main LLM. This reduces attention cost and keeps the model focused on the most relevant evidence while preserving traceability for audits.
Tune decoding and sampling settings in tandem with prompt structure. Lower temperature, top-p clipping, and constrained decoding are appropriate when you require verifiable outputs or JSON schemas; higher temperature can be useful for brainstorming stages where creativity matters. When you demand structured fields, add a deterministic parsing step: request JSON output and validate against a schema, then rerun the prompt with a corrective instruction if parsing fails. Pairing prompt-level constraints with token-level filters (forbidden tokens, regex checks) closes the loop between generation and enforcement.
Leverage programmatic tools to evaluate prompts like you evaluate code. Build a small prompt-test suite that runs synthetic, adversarial, and high-value queries against your prompt templates and measures pass/fail rates against golden outputs. Record metadata: prompt version, retrieval hits, reranker scores, and decoding settings so you can correlate regressions to upstream changes. Automate rollback by versioning prompt templates alongside model and embedding versions; when behavior drifts, you can revert to a known-good prompt rather than changing model weights.
Consider parameter-efficient adaptation when templates and examples aren’t enough. Prompt tuning and adapters let you inject domain-specific behavior with minimal compute: prompt tuning learns a small continuous prompt that sits in embedding space, while LoRA or adapters modify a few weight matrices to bias outputs. Use these techniques when repeated, high-volume tasks need consistent style or when regulatory requirements demand predictable phrasing; otherwise prefer explicit templates and retrieval to keep behavior auditable.
Finally, treat prompt engineering as an iterative operational discipline rather than a one-off craft. Instrument production with metrics for hallucination rate, parse failures, token cost, and user satisfaction, run A/B tests on prompt variants, and fold learnings back into your test suite. Taking this approach bridges model capability and application reliability and prepares you for the next implementation step: integrating structured function-calling and operational orchestration so the model drives actions you can verify and audit.
Deployment, Monitoring, and Safety
Shipping an LLM into production changes the game from prototype to operational responsibility: deployment, monitoring, and safety become the primary engineering constraints rather than model architecture alone. We need to treat a model release like any other service release—versioned, staged, and measurable—because model changes can silently alter user-facing behavior and cost. How do you detect drift or a sudden spike in hallucinations before customers experience harm? Instrumentation, staged rollout patterns, and safety gates are the practical answers you should adopt from day one.
Start your deployment strategy by making versioning and rollbacks first-class citizens in your CI/CD pipeline. Deploy models and prompt templates as immutable artifacts: tag model binaries, embedding versions, and prompt templates together so you can roll an entire configuration back if behavior regresses. Use canary or shadow deployments to route a small percentage of production traffic to a new model and compare key metrics—latency, token cost, hallucination rate—against the baseline before promoting to full traffic. For frequent, low-cost behavioral updates, prefer parameter‑efficient methods (LoRA, adapters, or prompt tuning) that let you iterate without retraining a full model.
Optimize the inference stack around predictable latency and cost targets rather than peak theoretical throughput. Batch requests where latency budgets allow, enable KV‑cache for autoregressive sessions, and apply quantization (INT8/4) when you can tolerate small accuracy tradeoffs to reduce memory and cost. Cache deterministic responses for hot queries and compress prompts or use a lightweight summarizer to shrink context windows before calling the expensive model. In practice you might serve a quantized 13B model on an optimized GPU instance for conversational latency and fall back to a larger hosted model for complex generative tasks.
Visibility is nonnegotiable: monitoring must surface both system health and semantic correctness. Track standard SRE metrics—p95/p999 latency, CPU/GPU utilization, and request rate—alongside model-specific signals: token consumption per session, retrieval recall@k, reranker MRR, parse-failure rate for structured outputs, and a running hallucination metric derived from human labels or automated fact-checkers. Log the retrieval trace (retrieved IDs, scores, and snippets) with each query so you can reproduce failures; correlate those traces with downstream errors and alerts. Configure alerts not only for infrastructure anomalies but for behavioral thresholds, for example an increase in hallucination rate or a drop in citation coverage within a rolling window.
Build safety controls into both the runtime and the decision flow so the model cannot cause irreversible harm. Enforce structured-output contracts and validate them server-side; reject or quarantine responses that fail JSON schema or contain forbidden tokens. For actions with side effects—billing, deployments, or access changes—require a deterministic authorization layer and human approval, and implement function-calling semantics that emit explicit, auditable actions rather than freeform text. For code generation workflows, run static analysis and execute unit tests in an isolated sandbox and only promote patches that pass those checks.
Close the loop with continuous evaluation and human feedback. Integrate a prompt-test suite into CI that exercises adversarial, edge-case, and golden-path queries so changes to prompts, embeddings, or models surface regressions before deployment. A/B test model variants and prompts to measure user satisfaction and task success, and automate rollback criteria into your deployment pipeline so poor-performing variants are removed without manual intervention. Periodically re-embed and reindex documents on a cadence matched to content volatility, and treat embedding versioning like schema migrations.
Operational safety extends to data governance and access control: encrypt data in transit and at rest, separate namespaces for sensitive corpora, and apply token redaction at the edge. Limit which services can call models that access PII and log anonymized traces for debugging. Define SLAs and compliance checklists for any model that touches regulated data and include auditing hooks that expose provenance, model version, and prompt template for each output.
Taking these steps prepares you to scale a retrieval‑plus‑inference pattern reliably: deploy with safe rollouts, monitor both system and semantic signals, and enforce verification layers where risk is high. Next, we’ll examine concrete implementation patterns and monitoring dashboards you can wire into your existing observability stack to make these practices repeatable and auditable.



